
최근에 AI를 활용해서 학습을 시키는 프로젝트를 하나 진행하고 있었다.
센서에서 들어오는 데이터를 원하는 값으로 매칭시키는, 일종의 회귀 문제였다.
원하는 로직과 방식을 정리해서 AI에게 넘겨줬더니,
1D ResNet을 추천받았고 전처리부터 학습까지 전 과정을 뚝딱 수행해주었다.
겉보기에 결과도 꽤 잘 나왔다.
그렇게 전체적인 흐름을 대강 공부하고, 검토를 받기 위해 보고를 했는데.
"ResNet 오래된 건데 왜 썼어요? 전체적인 모델 디자인은 어떻게 짜여진 거예요?"

정확한 표현은 기억나지 않지만, 대충 그런 맥락이었다.
사실 어떤 데이터가 어디서 나뉘고, 어떤 순서로 흘러가는지는 알고 있었다.
그런데 왜 이 구조인지, 왜 이 레이어인지와 같은
그런 설계 근거에 대한 공부는 되어있지 않았다.
식은땀이 났다.
그렇게 따로 공부를 하며,
머릿속을 정리하기 위해 글을 작성하기로 했다.

왜 아직도 ResNet인데
딥러닝은 레이어를 깊게 쌓을수록 더 복잡한 걸 배울 수 있다.
그래서 자연스럽게 "더 깊게 쌓자"는 방향으로 갔는데,
일정 수준을 넘으니까 오히려 성능이 떨어지기 시작했다.
이걸 Degradation Problem이라고 부른다고 한다.
2015년에 나온 ResNet은 이 문제를 아주 단순하게 해결했다.
각 레이어가 정답을 처음부터 만들어내는 대신, 입력에서 얼마나 바꿔야 하는지만 학습하게 한 것이다.
바꿀 게 없으면 그냥 통과시키면 된다.
이걸 가능하게 하는 게 Skip Connection이다.
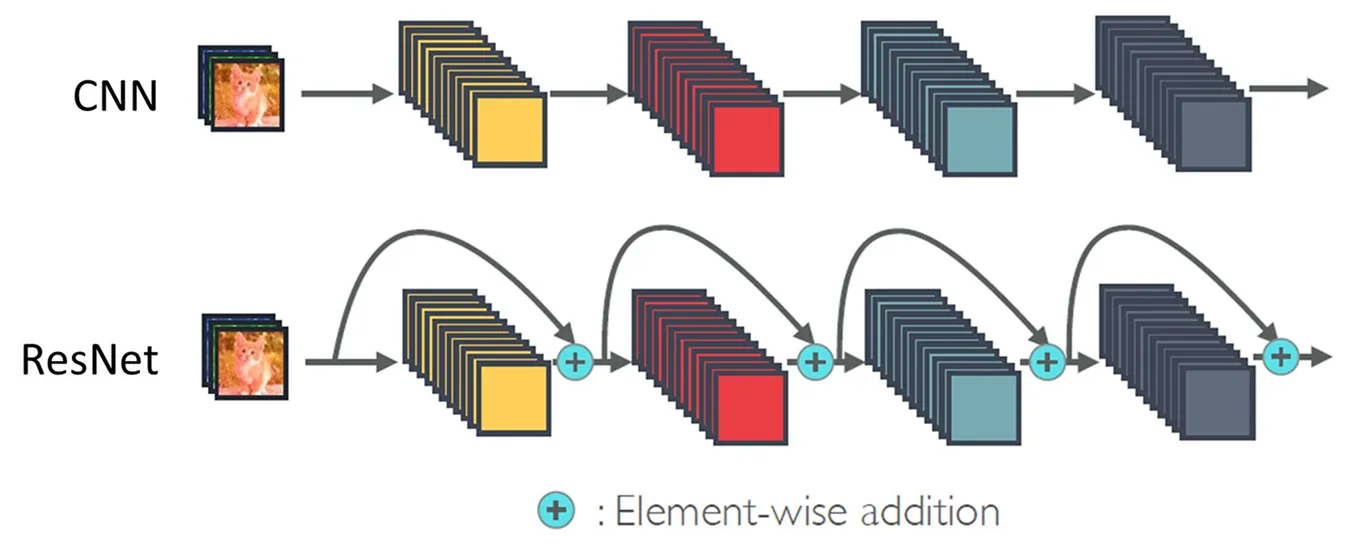
입력을 레이어를 건너뛰어 출력에 직접 더해주는 구조다.
이렇게 우회로를 뚫어주면, 레이어가 깊어져도 학습 오차가 사라지는 현상(기울기 소실)을 막을 수 있다.
입력 ──→ [연산] ──→ (+) ──→ 출력
│ ↑
└── (그대로 넘김) ──┘뭔가 제어시스템설계에서 블록다이어그램 그리던 거랑 묘하게 닮은 느낌.
아무튼 이 구조 하나로 152개 레이어를 쌓아도 학습이 안정적으로 돌아갔고, 당시 세계 최고 성능을 찍었다.
1D ResNet은 뭐가 다른데
원조 ResNet은 이미지(2D)용이다.
하지만 센서 프로파일 같은 1차원 데이터에도 똑같은 원리를 쓸 수 있다.
2D 연산을 1D로 바꿔 끼우기만 하면 된다.
그런데 "1D면 아무 1D 모델이나 쓰면 되지 않나?"라는 질문이 남는다.
실제로 선택지는 여러 개였다.
단순 MLP는 입력 전체를 한 번에 본다.
각 포인트들을 그냥 쭉 펼쳐서 넣는 셈이다.
문제는 센서 프로파일에서 의미 있는 건 전체 모양이 아니라,
특정 구간에서 나타나는 국소적인 패턴이라는 점이다.

곡률이 꺾이는 지점, 피크가 나타나는 위치, 그런 것들인데
MLP는 이런 국소 패턴을 잡아내는 데 구조적으로 불리하다.
RNN이나 LSTM도 생각할 수 있지만
내 데이터는 시간에 따라 흘러가는 시계열이 아니고,
한 시점에 찍힌 공간 프로파일이다.
순서가 있긴 하지만 앞 값이 뒤 값의 "원인"인 건 아니다.
시계열의 인과적 의존성을 모델링하는 RNN 계열은 여기선 과한 가정이다.
결국 1D convolution이 자연스러웠다.
커널이 프로파일 위를 슬라이딩하면서 국소 패턴을 잡아내고,
레이어를 쌓으면 더 넓은 범위의 패턴까지 볼 수 있다.
그리고 그 "레이어를 깊게 쌓는" 과정에서 학습이 무너지지 않게 해주는 게 ResNet의 Skip Connection이다.
지금이야 이렇게 적고 있지만, 사실 이것도 AI와 대화하며 뒤늦게 정리한 내용이라 아직 깊다고 하긴 어렵다.
그래서 모델 디자인은?
이번에 식은땀 흘린 지점이 여기다.
모델을 갖다 쓰는 건 어렵지 않다.
문제는 "왜 이렇게 만들었는가"에 대한 답.

결국 몇 가지 질문이다.
입력이 뭔지, 얼마나 깊게 쌓을 건지, 채널은 어떻게 가져갈 건지, 출력은 뭔지,
코드를 짜는 건 구현이고, 왜 그렇게 짰는지 설명할 수 있는 게 설계라고 볼 수 있다.
예를 들면 이런 것들이다.
-
커널 크기를 왜 그렇게 잡았는지: 센서 포인트 간격 대비 패턴의 폭이 어느 정도인지에 따라 달라진다.
너무 좁으면 노이즈에 반응하고, 너무 넓으면 디테일을 놓친다. -
마지막에 activation 함수를 왜 안 넣었는지: 회귀 문제니까 출력 범위를 제한하면 안 되기 때문이다.
각도 예측인데 ReLU를 걸면 음수 각도를 아예 표현 못 한다. -
손실 함수를 MSE로 할지 Huber로 할지: 이상치에 얼마나 민감해도 되는지에 따라 갈린다.
센서 데이터에 노이즈가 있다면 이상치에 둔감한 Huber 쪽이 안정적일 수 있다.
이런 질문들에 하나하나 답할 수 있어야 "설계했다"고 말할 수 있다.
(그리고 그 답을 못 해서 식은땀을 흘린 것이다.)
근데 AI가 다 해줬잖아
결과도 잘 나왔고,
AI가 추천해준 구조도 맞았고,
학습도 잘 돌아갔다.
그러면 된 거 아닌가.
근데 보고하는 자리에서 질문 하나에 아무 말도 못 했다.
내가 만든 건 맞는데,
내가 만든 게 아닌 느낌이 들었다.
구조를 모르면 뭘 바꿔야 하는지도 모른다.
성능이 안 나올 때 커널 크기를 손봐야 하는 건지, 레이어를 더 쌓아야 하는 건지, 아예 모델을 바꿔야 하는 건지.
판단 기준이 없으면 결국 다시 AI한테 물어보는 수밖에 없다.
그건 도구를 쓰는 게 아니라 도구에 끌려가는 거다.
(그래서 도메인 공부는 지속해야 한다.)

마무리
ResNet은 2015년 논문이다.
요즘 10년이면 거의 고대 유물 취급인데,
아직도 쓰이는 이유는 단순하다.
Skip Connection이라는 구조가 너무 잘 작동하기 때문이다.
이후에 나온 수많은 모델들도 이 구조를 기반으로 변형한 것들이 많고,
이는 1D든 2D든 도메인을 가리지 않는다.
오래 공부되고 있다는 건 검증됐다는 뜻이기도 하다.
새로운 모델이 매달 쏟아지는 시대에,
AI가 아직도 이런 모델을 선정한 이유가 있다.
이 글에서는 "왜 ResNet인지, 어떻게 돌아가는지"까지만 정리했다.
여러 삽질기도 적어보고 싶지만, 그건 업무 중 얻은 지식이니까 적긴 힘들 것 같다.

아무튼 결국 내 것이 되는 건,
AI가 짜준 구조를 그대로 쓰는 순간이 아니라 그것을 설명할 수 있게 되는 순간인 것 같다.

ai 개발하는 옆팀 채용에 면접관으로 들어 갔을 때 여러 지원자에게 왜 모델의 인풋과 아웃풋을 이 포맷으로 정했냐고 물어봤을 때 대답을 제대로 하는 분이 거의 없더라구요..
"왜 이렇게 했냐?" 에 대한 답변을 할 수 있도록 늘 준비해야겠다는 생각이 들었습니다