- 위 컨퍼런스를 보고 정리한 포스트
1. 연관 관계 매핑
1. Mapping



보통의 가이드
1. 우선 단방향 매핑을 설정하고
2. 반대 방향으로 객체 그래프 탐색이 필요할때 양방향 고려
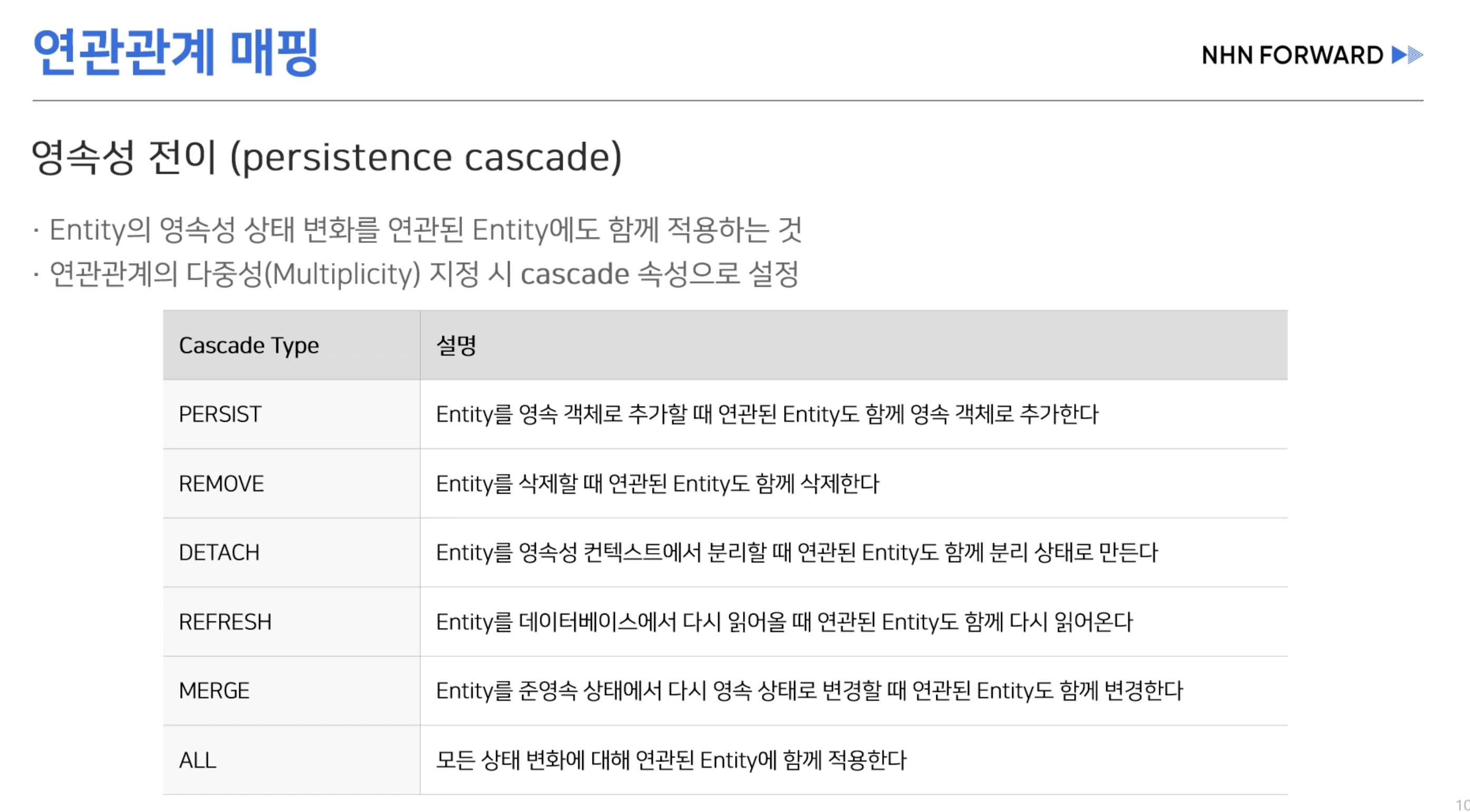
cascade?
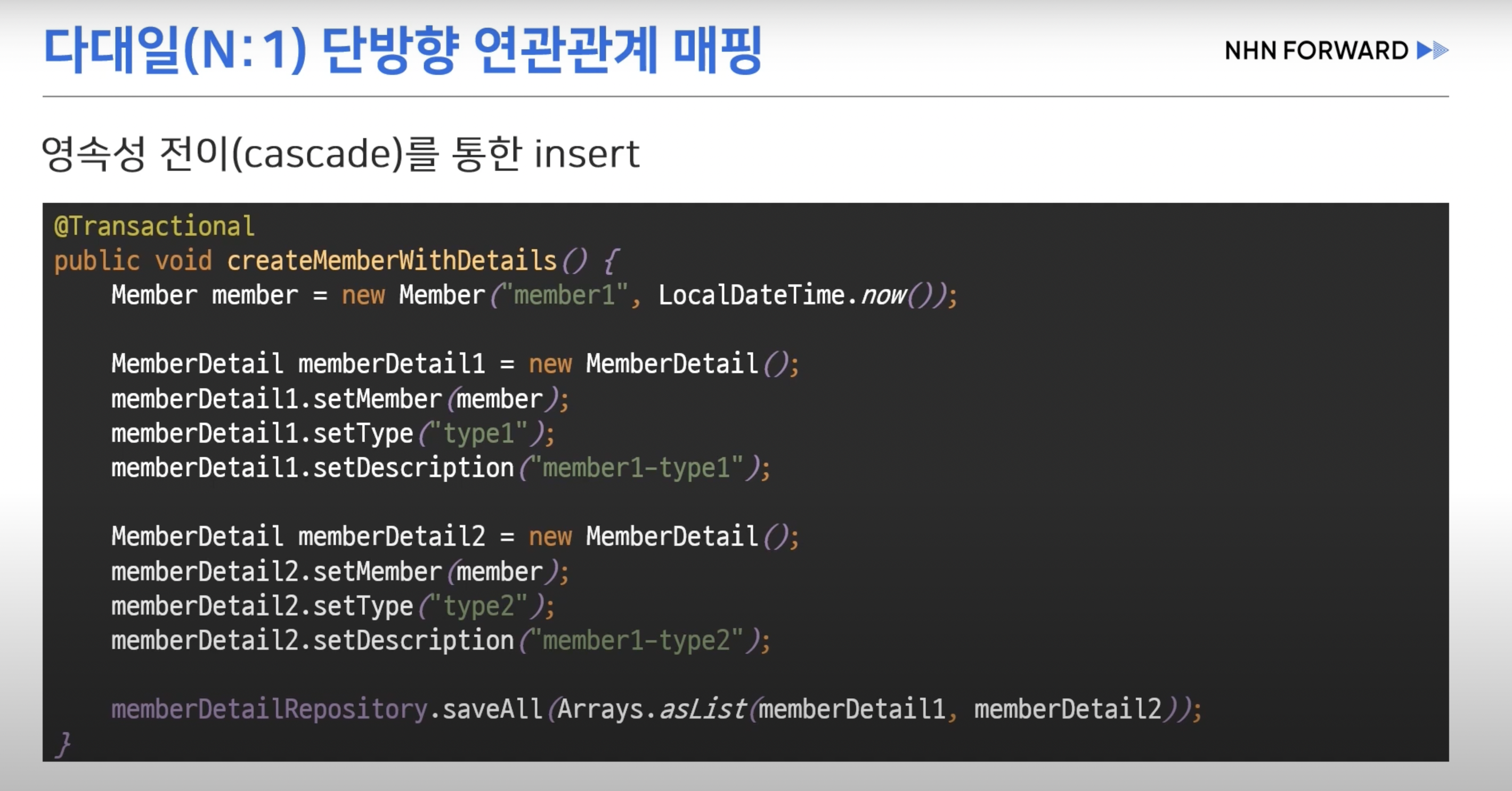
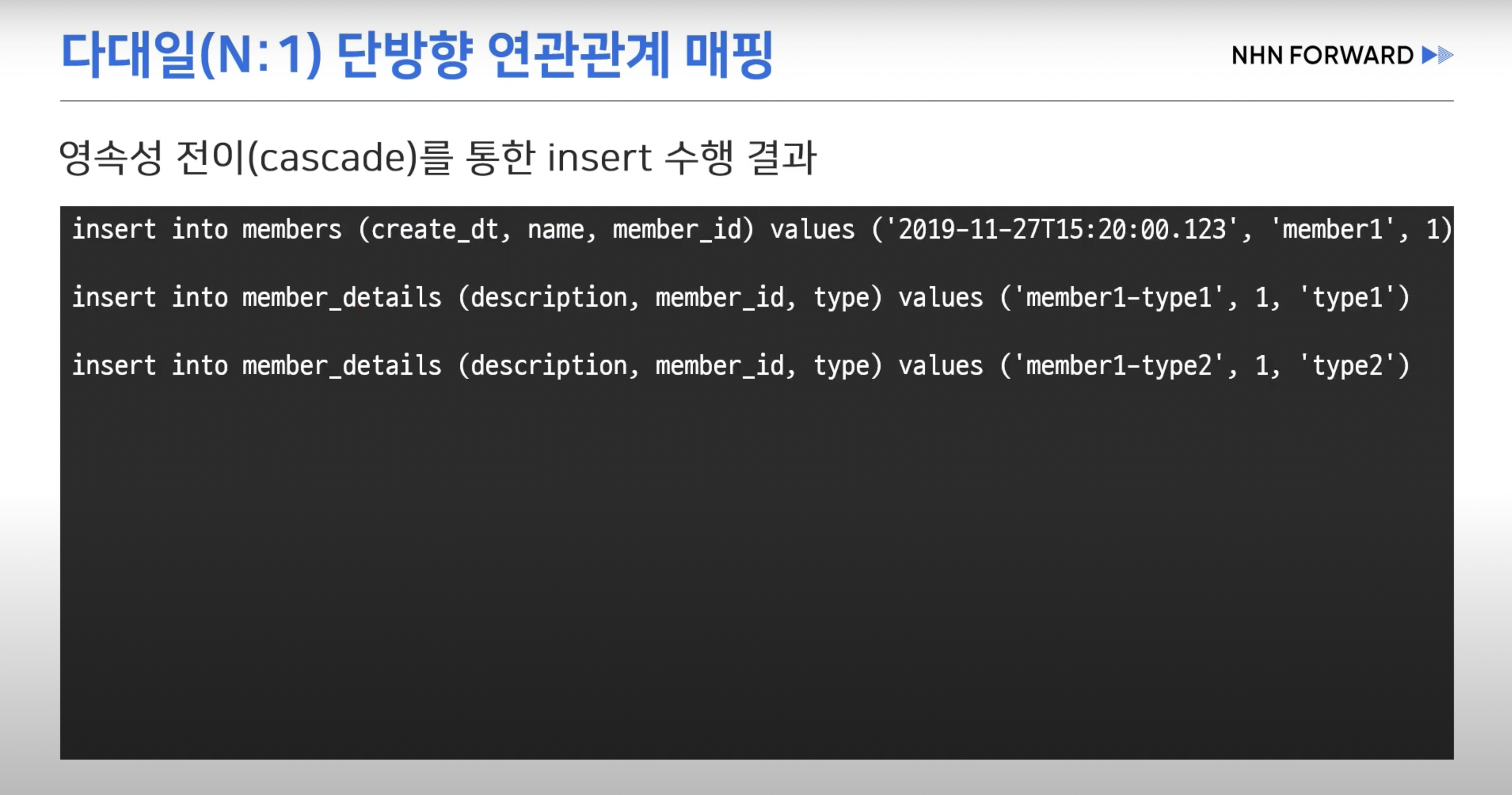
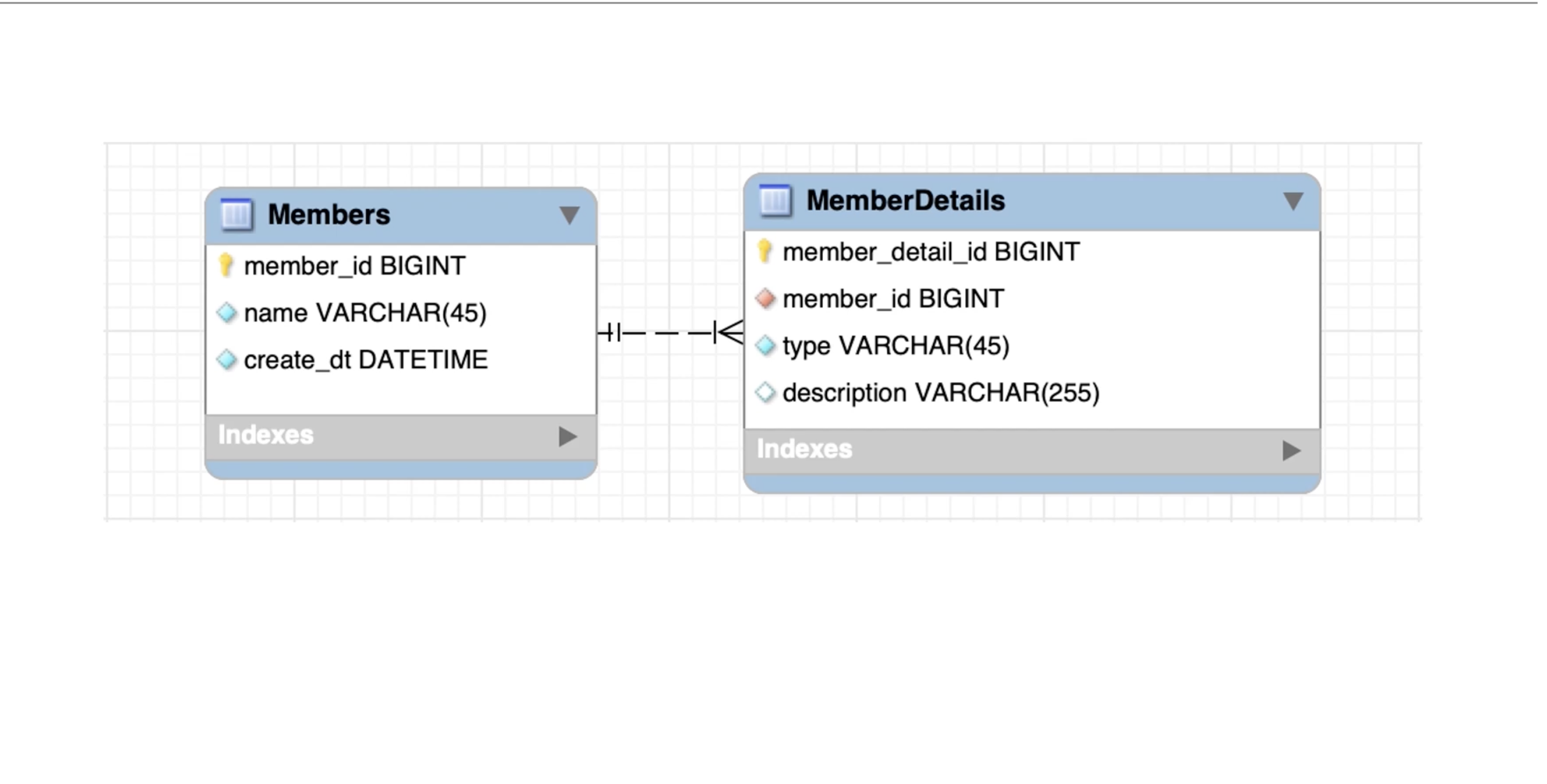
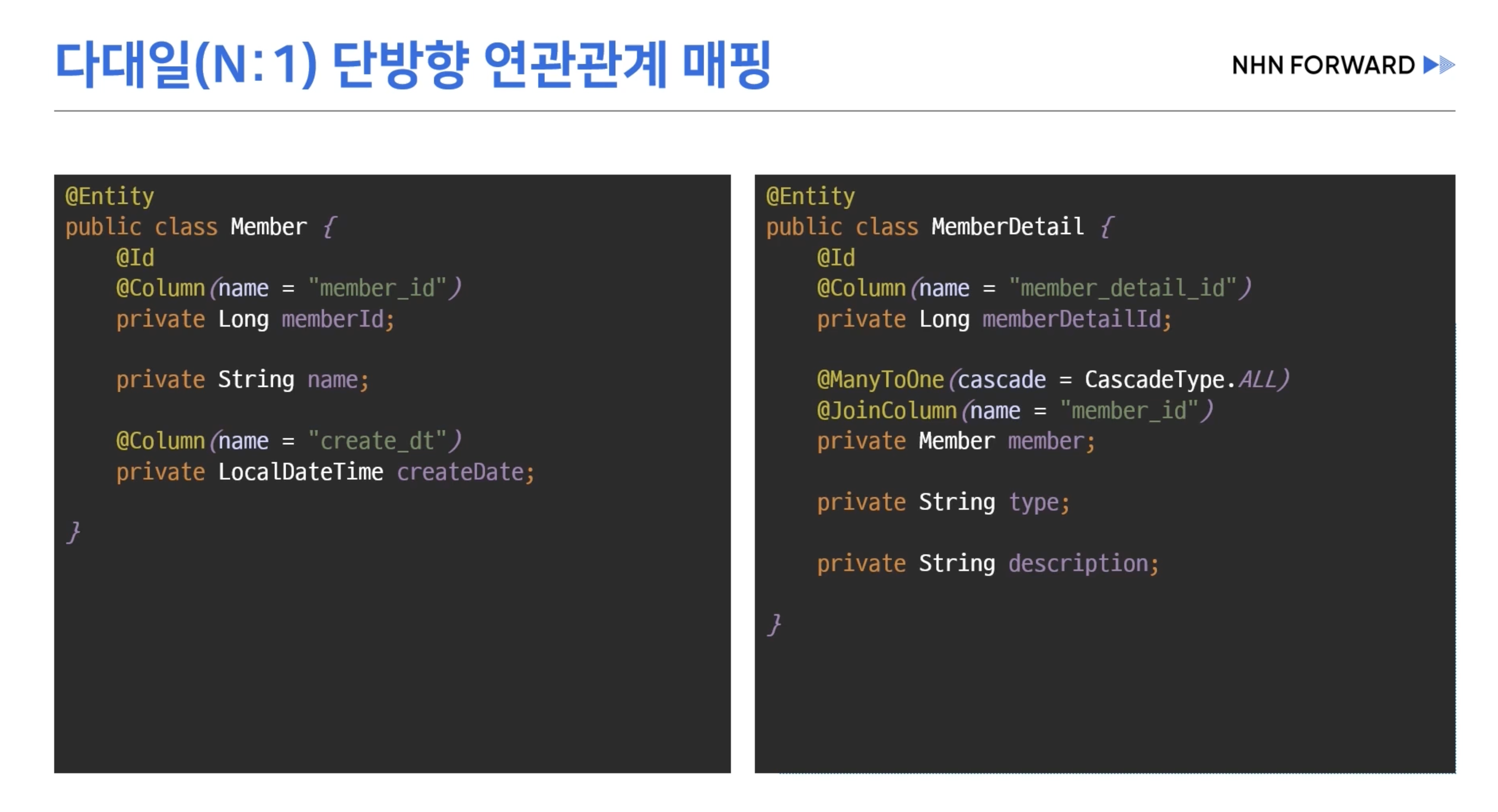
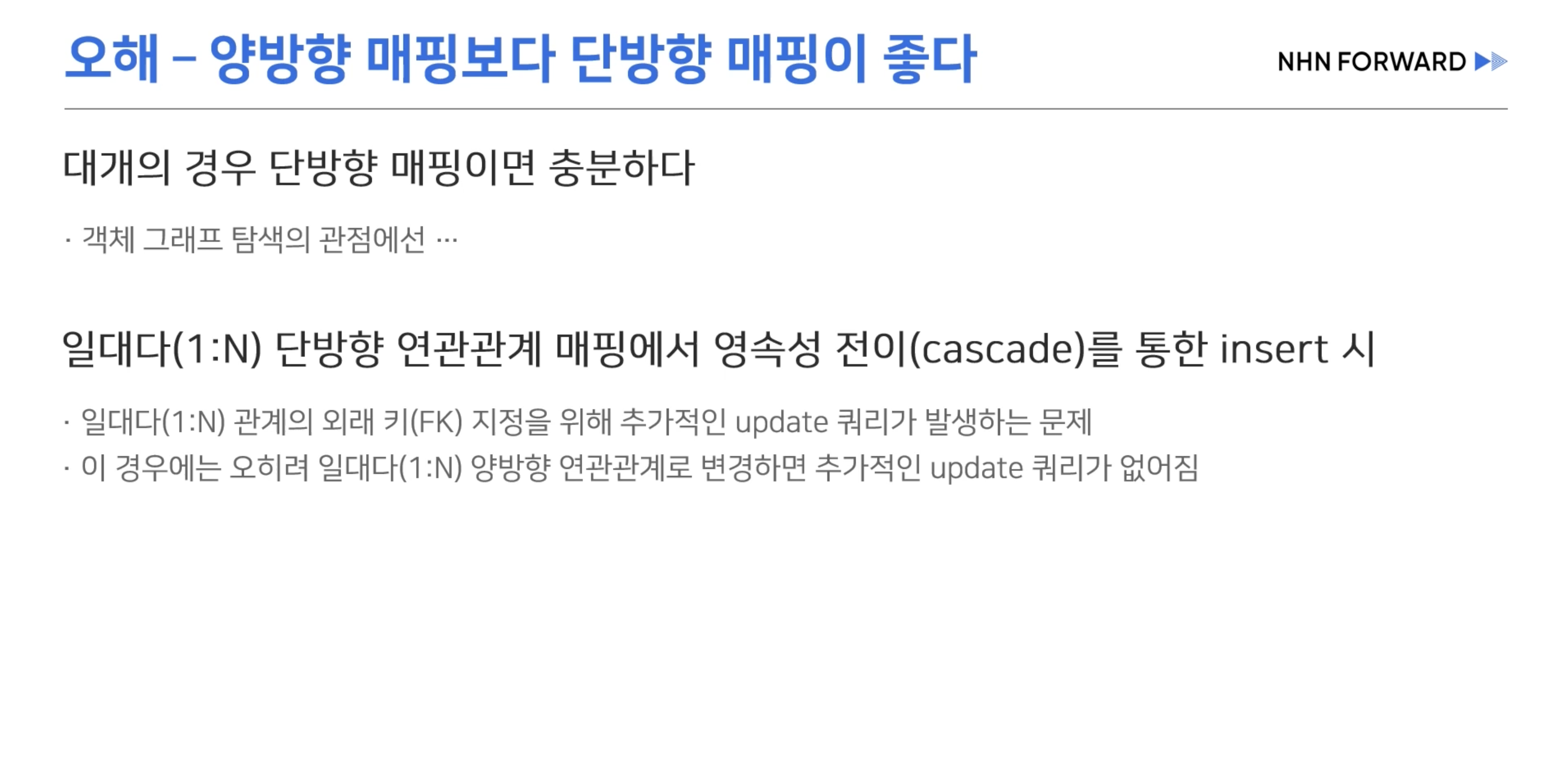
- @ManyToOne을 통한 단방향 연관관계 매핑시 예상한 3개의 쿼리가 나간다.
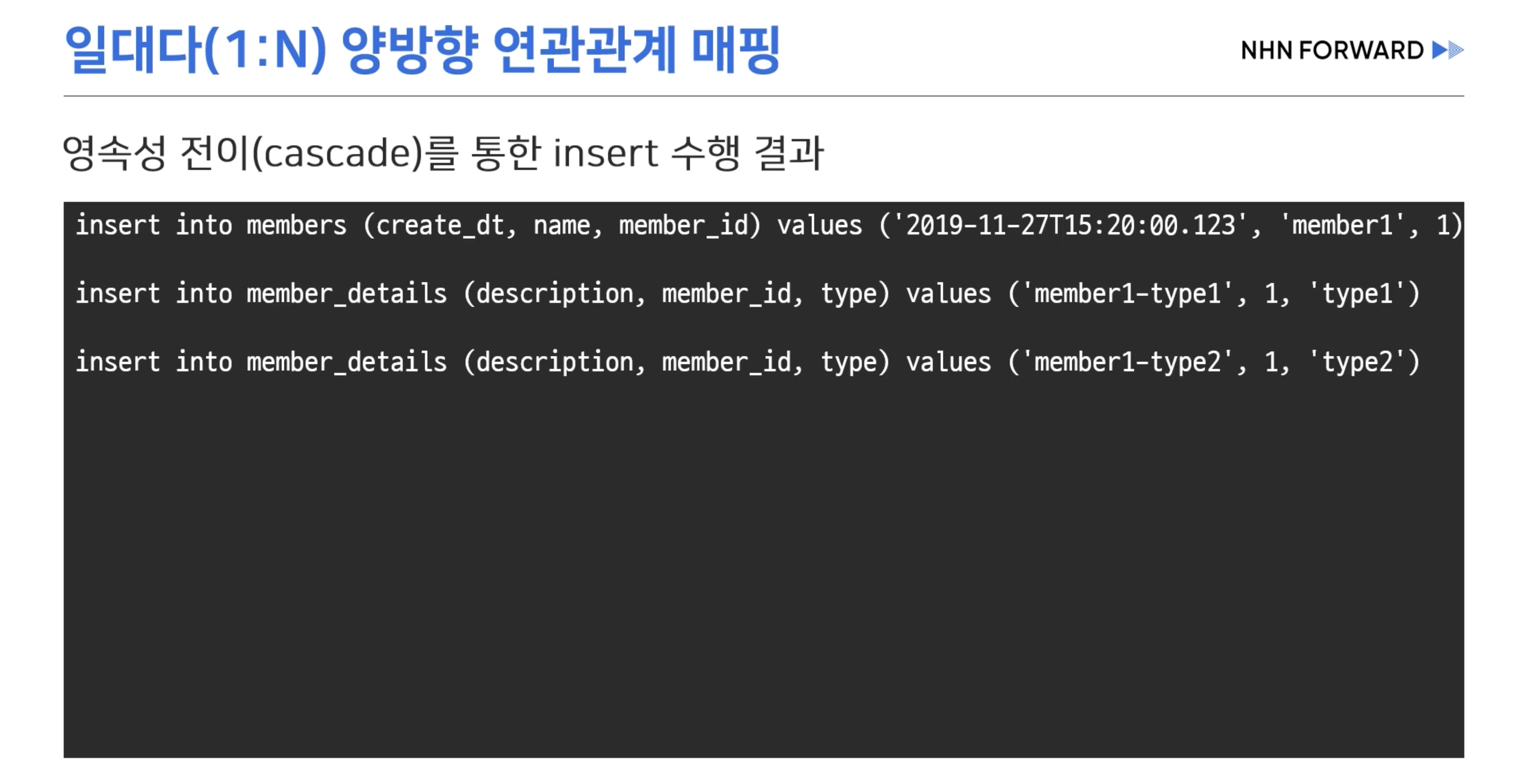
- 하지만 Member쪽에서 객체 그래프 탐색이 필요할 경우 일대다 매핑을 단방향으로 연관관계 설정을 했을때
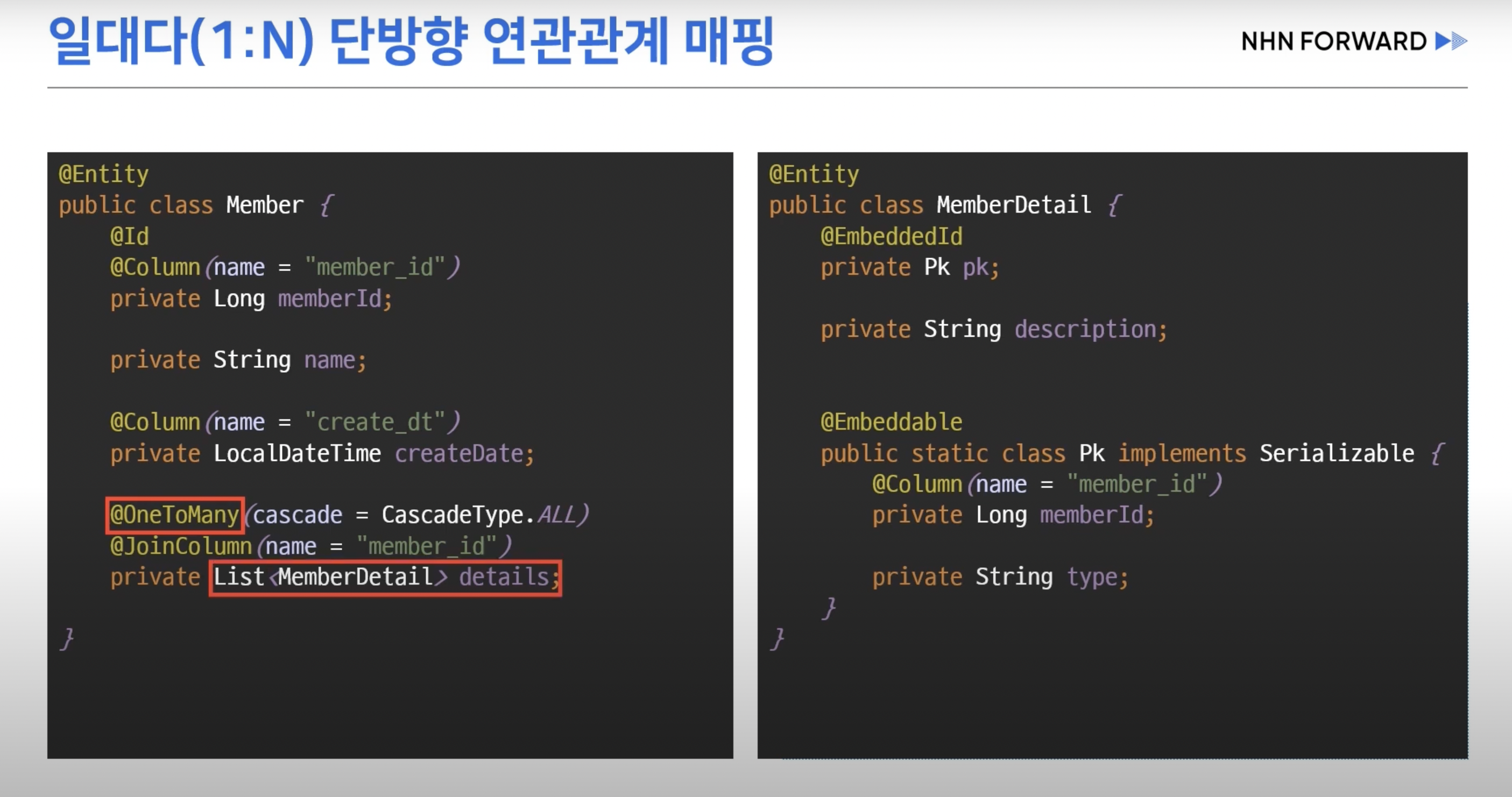
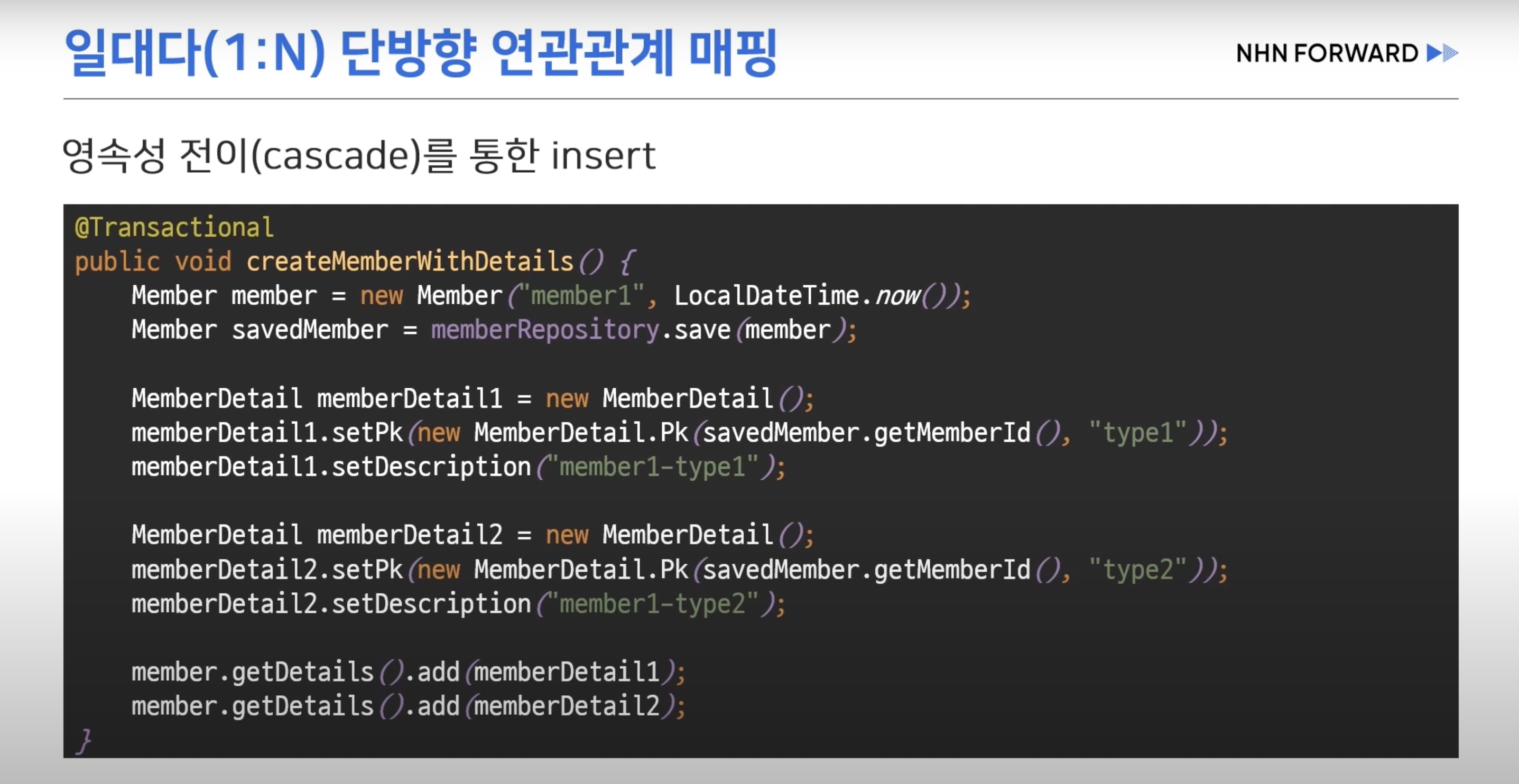
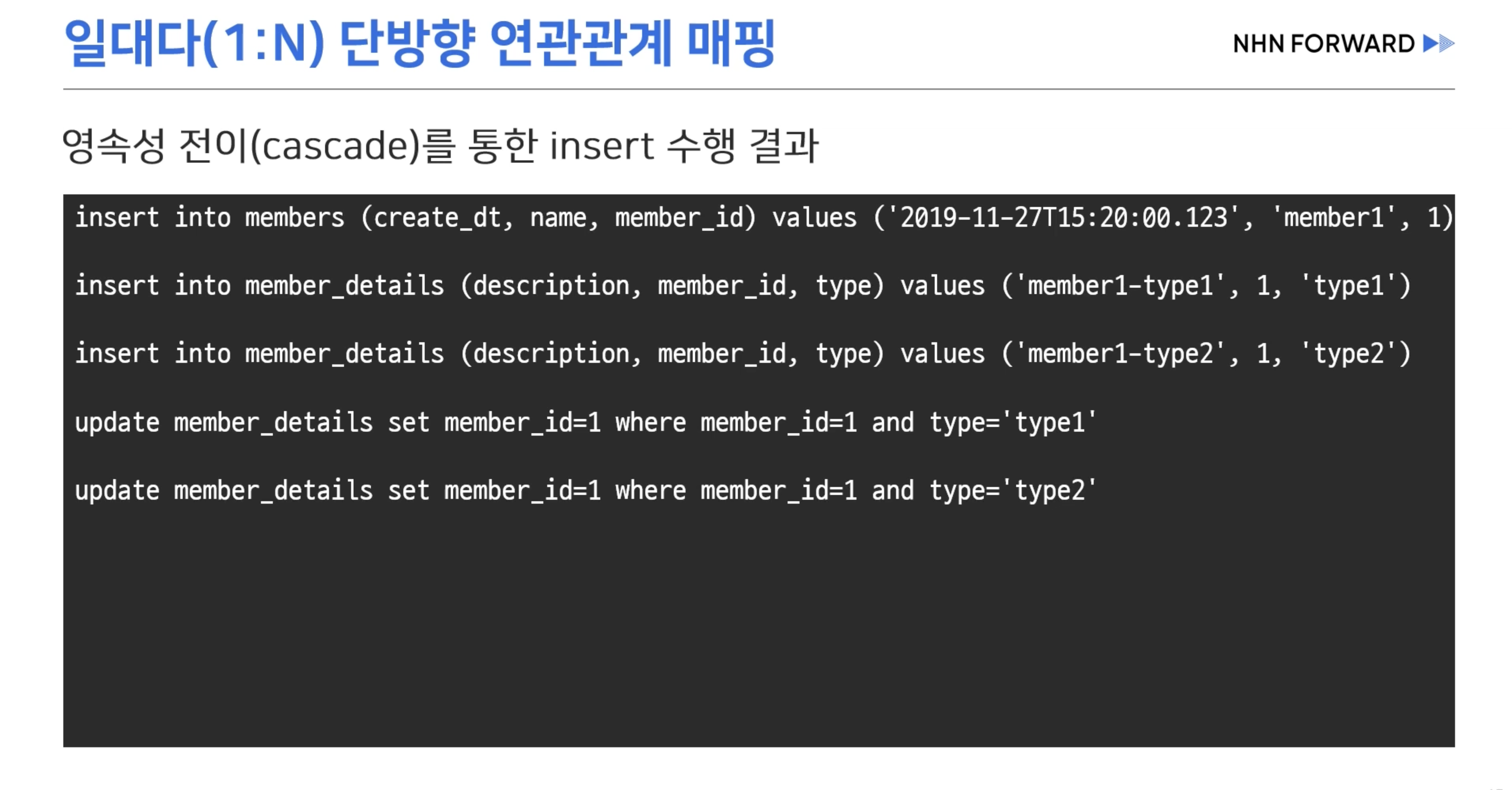
- 외래키 설정을 위한 두 개의 Update 쿼리가 추가적으로 입력된다.
- 위와 같은 경우는 양방향 매핑이 오히려 좋을 수 있다.

- 복합키를 사용 하는 경우 @MapsId 어노테이션을 통해 기본키로 매핑된 MemberId 필드가 외래키로도 참조 가능
- mappedBy를 통해 연관관계의 주인을 명시
- 반드시 단방향 매핑이 좋다고 볼 수는 없다.
2. Loading

Fetch 전략이 즉시 로딩인 경우
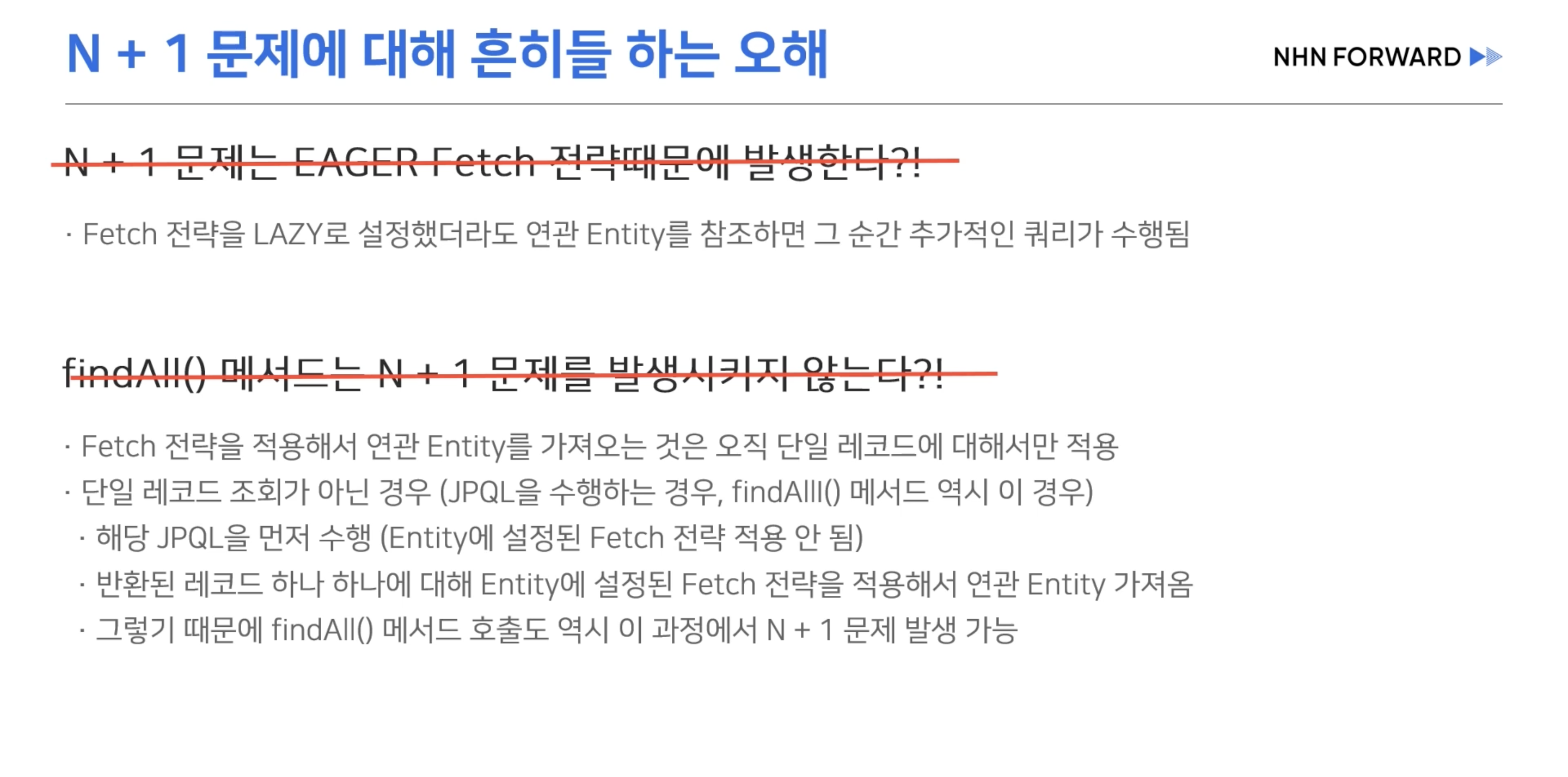
- findAll()을 한 순간 select t from Team t 이라는 JPQL 구문이 생성되고 해당 구문을 분석한 select * from team 이라는 SQL이 생성되어 실행된다. ( SQL 로그 중 Hibernate: select team0.id as id1_0, team0.name as name2_0 from team team0_ 부분 )
- DB의 결과를 받아 team 엔티티의 인스턴스들을 생성한다.
- team과 연관되어 있는 user 도 로딩을 해야 한다.
- 영속성 컨텍스트에서 연관된 user가 있는지 확인한다.
- 영속성 컨텍스트에 없다면 2에서 만들어진 team 인스턴스들 개수에 맞게 select * from user where team_id = ? 이라는 SQL 구문이 생성된다. ( N+1 발생 )
Fetch 전략이 지연 로딩인 경우
- findAll()을 한 순간 select t from Team t 이라는 JPQL 구문이 생성되고 해당 구문을 분석한 select * from team 이라는 SQL이 생성되어 실행된다. ( SQL 로그 중 Hibernate: select team0.id as id1_0, team0.name as name2_0 from team team0_ 부분 )
- DB의 결과를 받아 team 엔티티의 인스턴스들을 생성한다.
- 코드 중에서 team 의 user 객체를 사용하려고 하는 시점에 영속성 컨텍스트에서 연관된 user가 있는지 확인한다
- 영속성 컨텍스트에 없다면 2에서 만들어진 team 인스턴스들 개수에 맞게 select * from user where team_id = ? 이라는 SQL 구문이 생성된다. ( N+1 발생 )

2. Spring Data JPA Repository


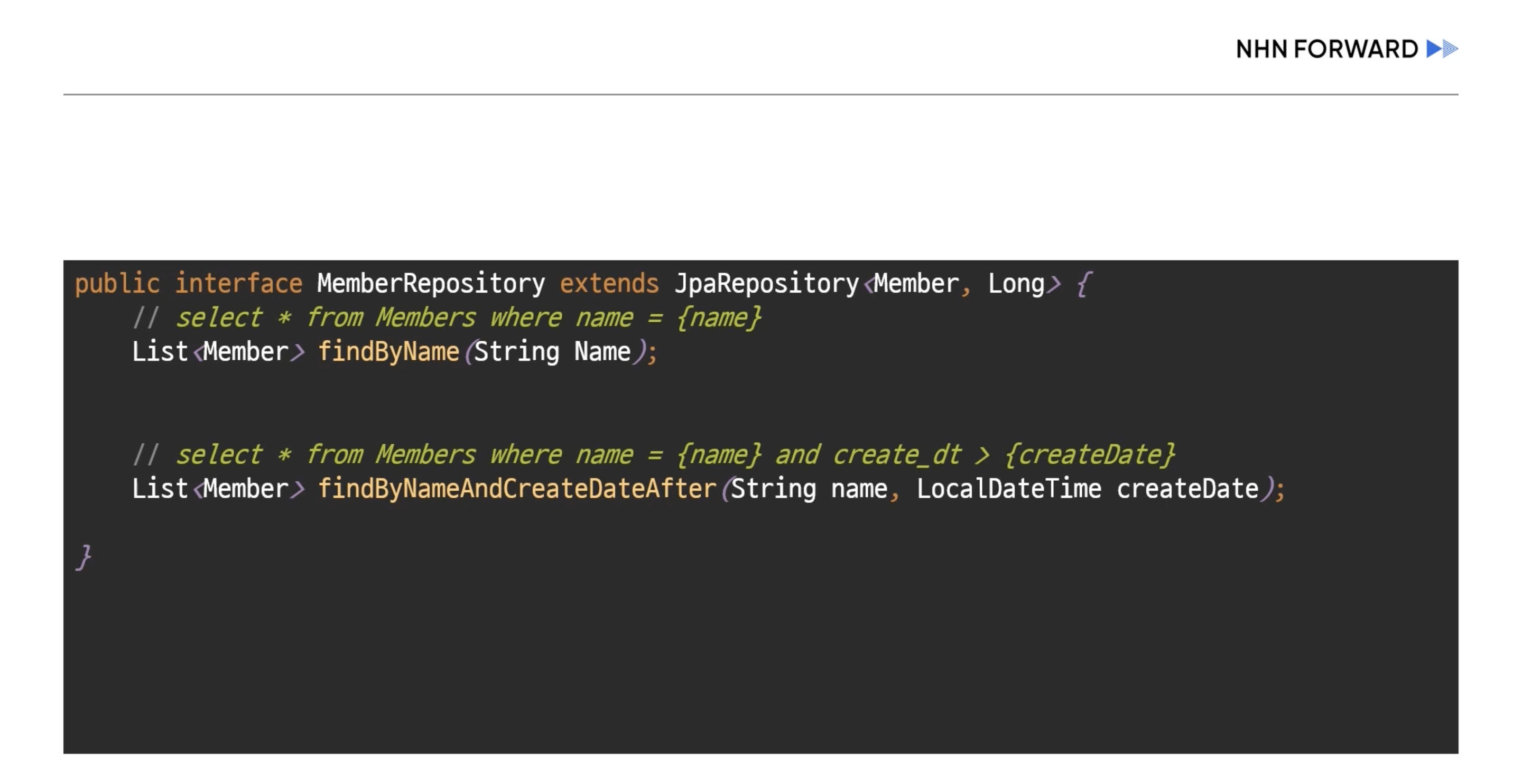
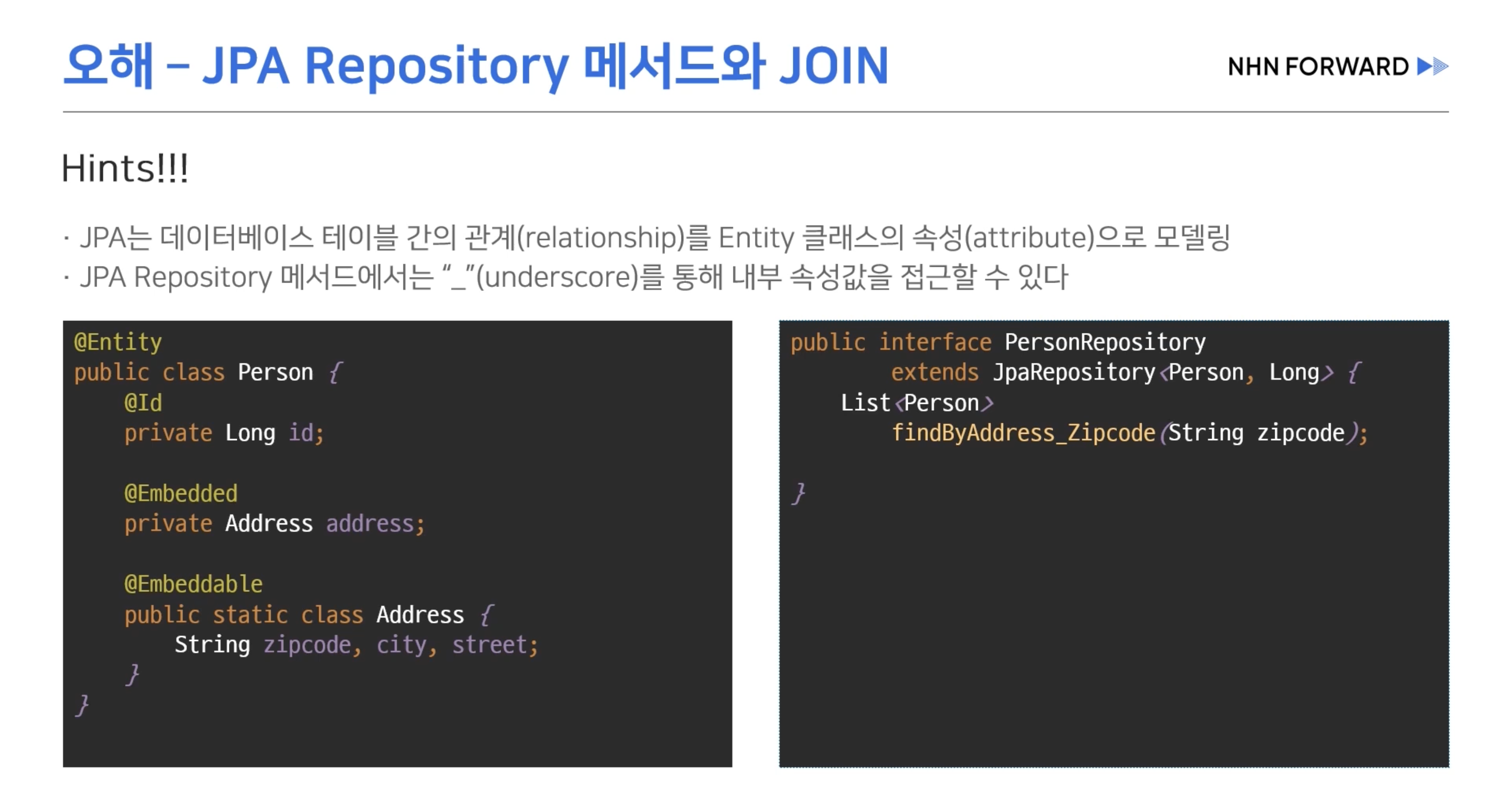
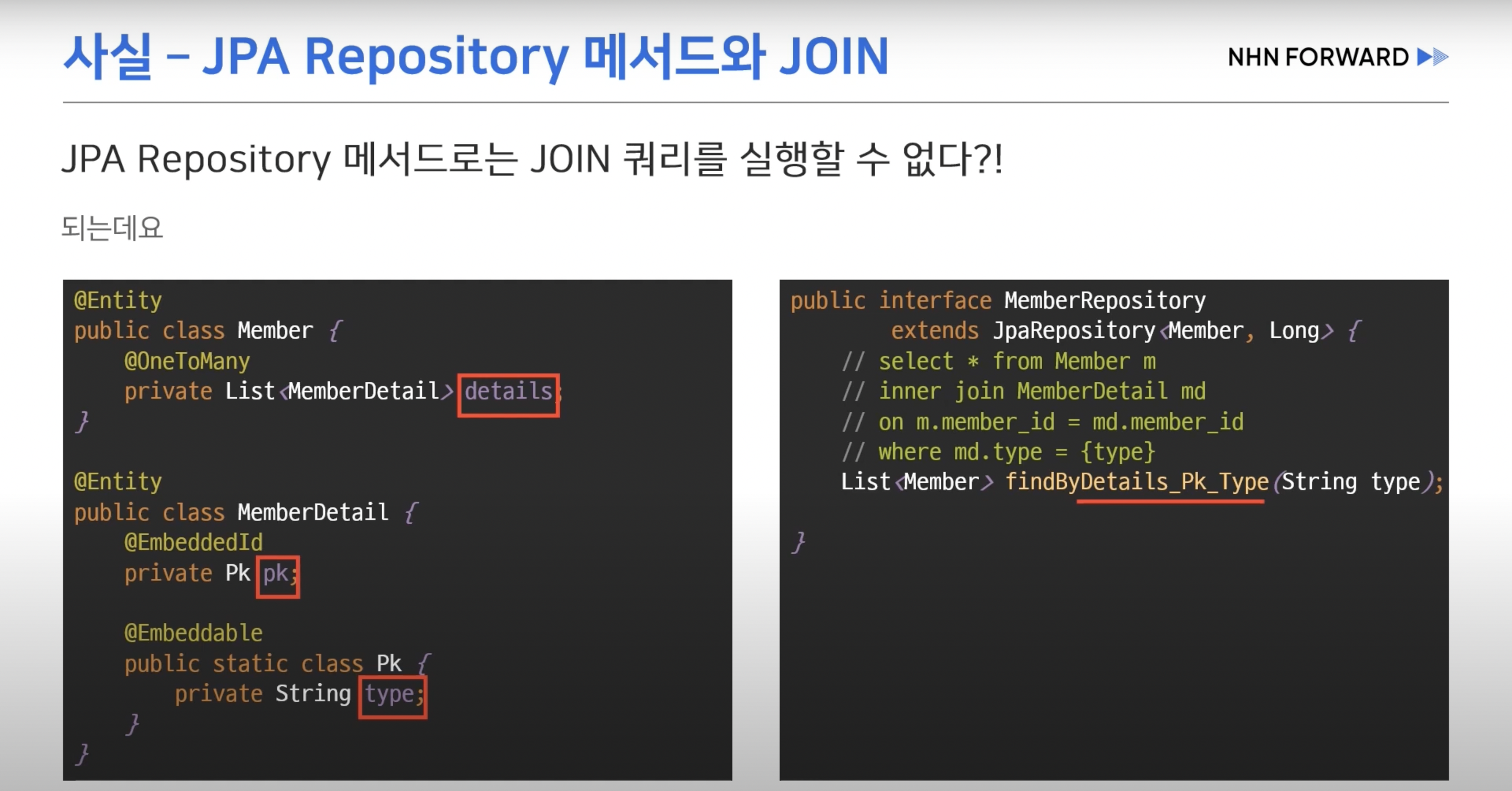
- 기본적인 CRUD는 메서드 이름 규칙으로 실행이 가능하다 Join 이 필요할 경우 보통 커스텀 레파지토리를 통해 쿼리를 생성한다.
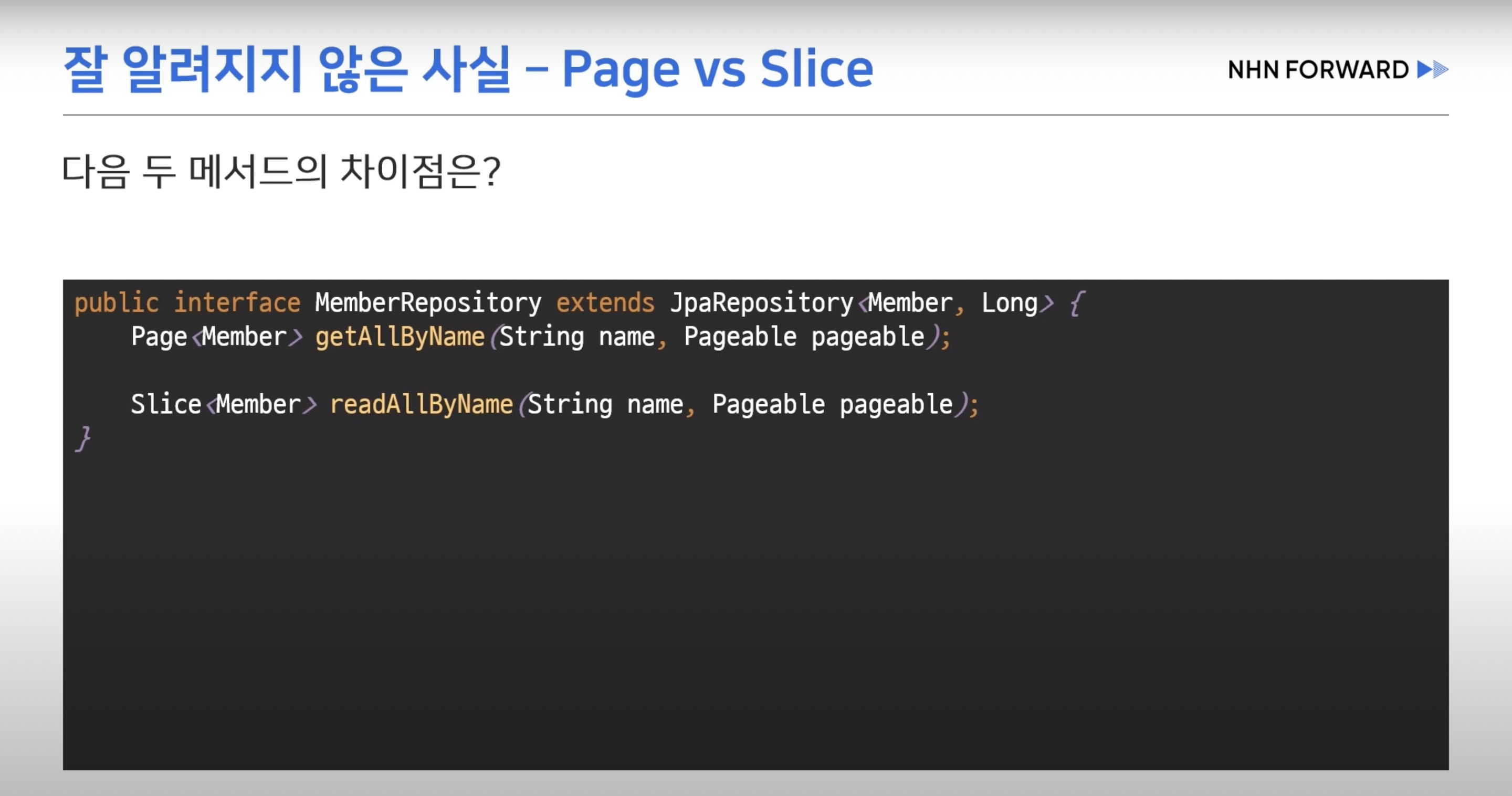
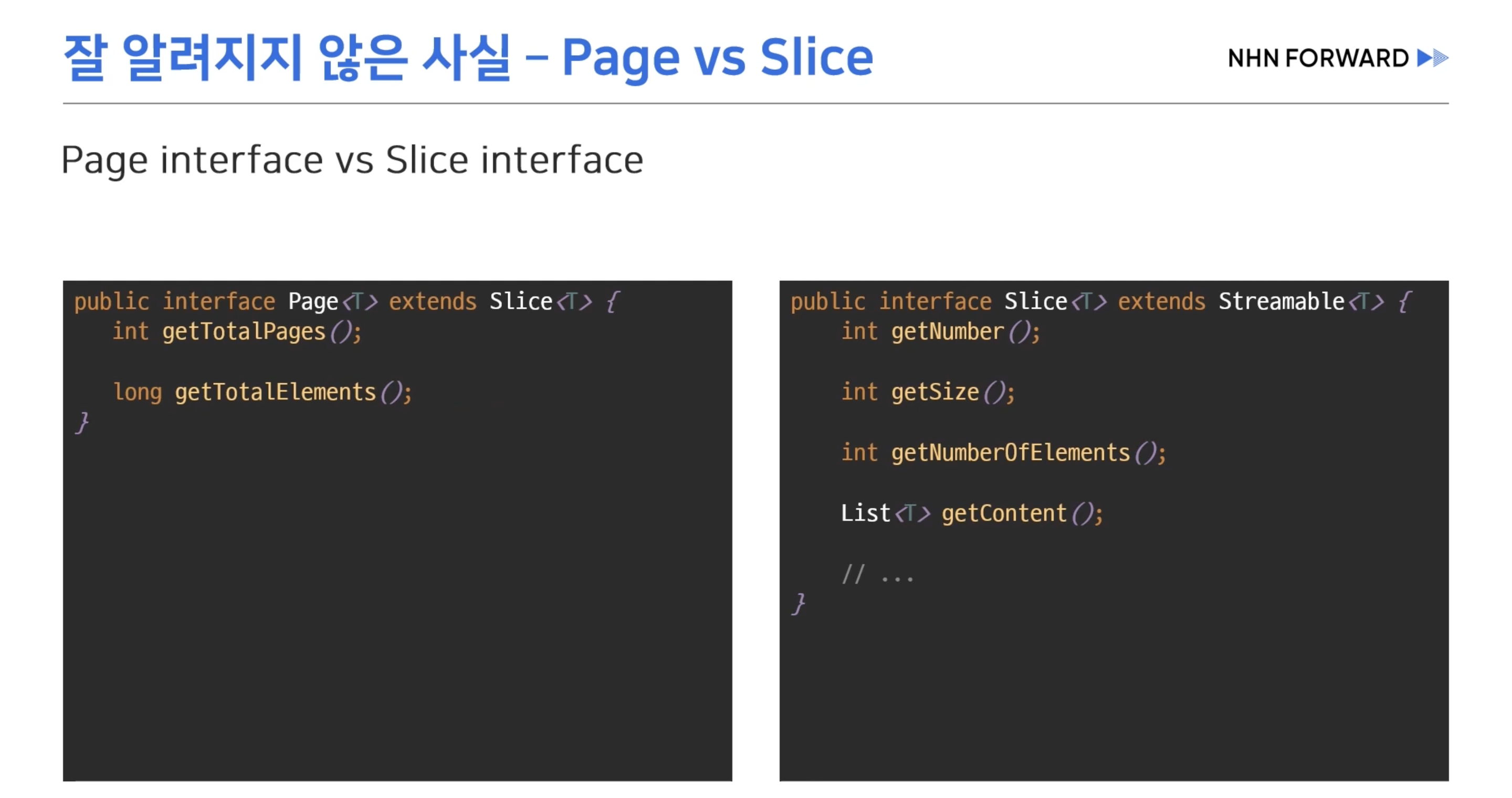
- interface Page : 전체 페이지 수, 전체 엘리면트 수
- interface Slice : 페이지 넘버나 사이즈 , 엘리먼트 개수 메서드
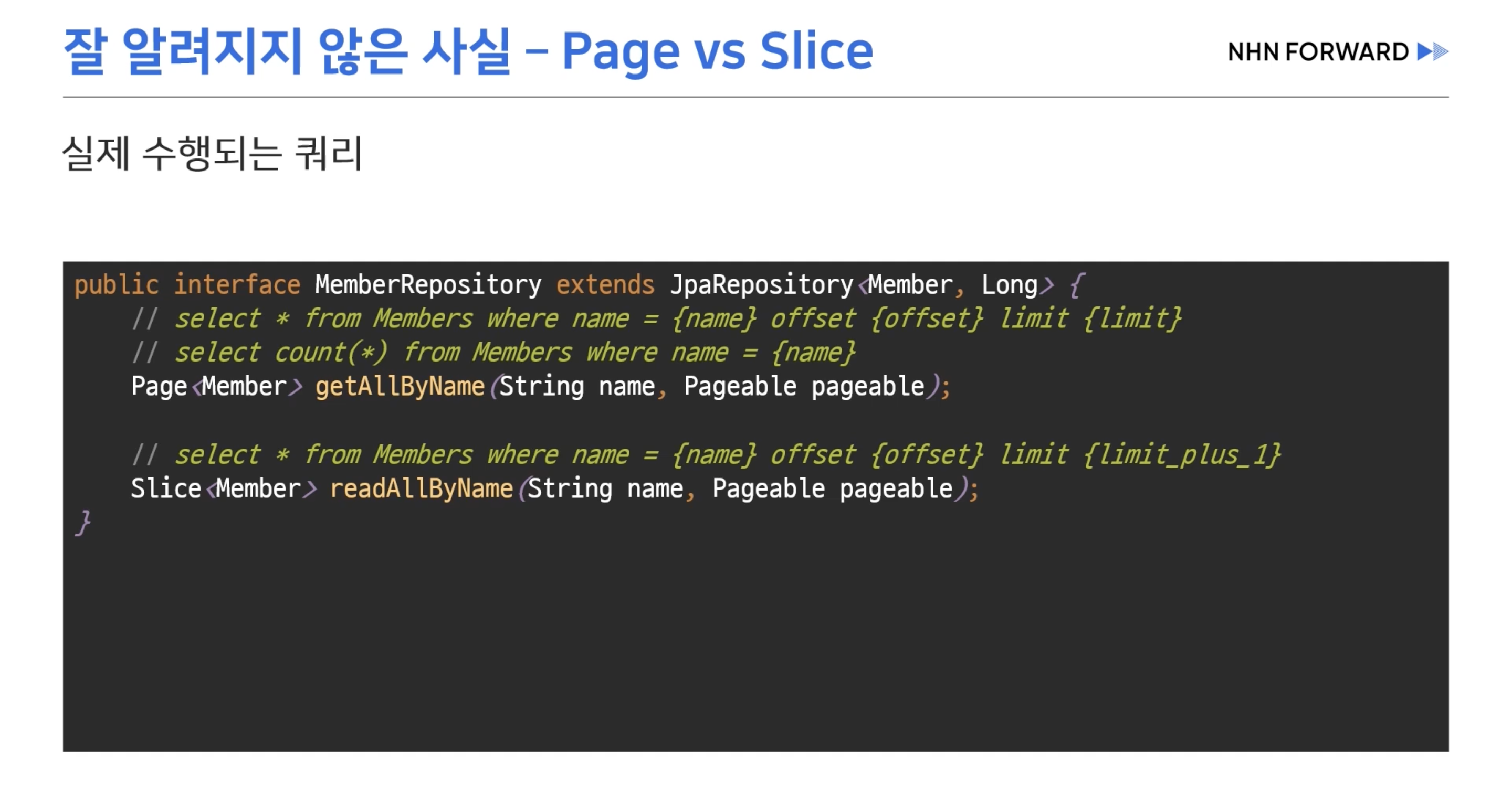
- Page 타입의 경우 집계 쿼리가 하나 더 입력된다.
- Slice는 어떻게 다음 페이지가 있는지 알 수 있을까? -> limit 보다 1개 더 레코드를 가져오고 다음 페이지가 있는지 없는지 확인한다.
- Slice타입을 쓰면 성능상 이점을 얻을 수 있다.
- Page도 집계 쿼리가 나가지 않는 경우가 있다. -> Limit보다 적은 레코드를 가져올 경우
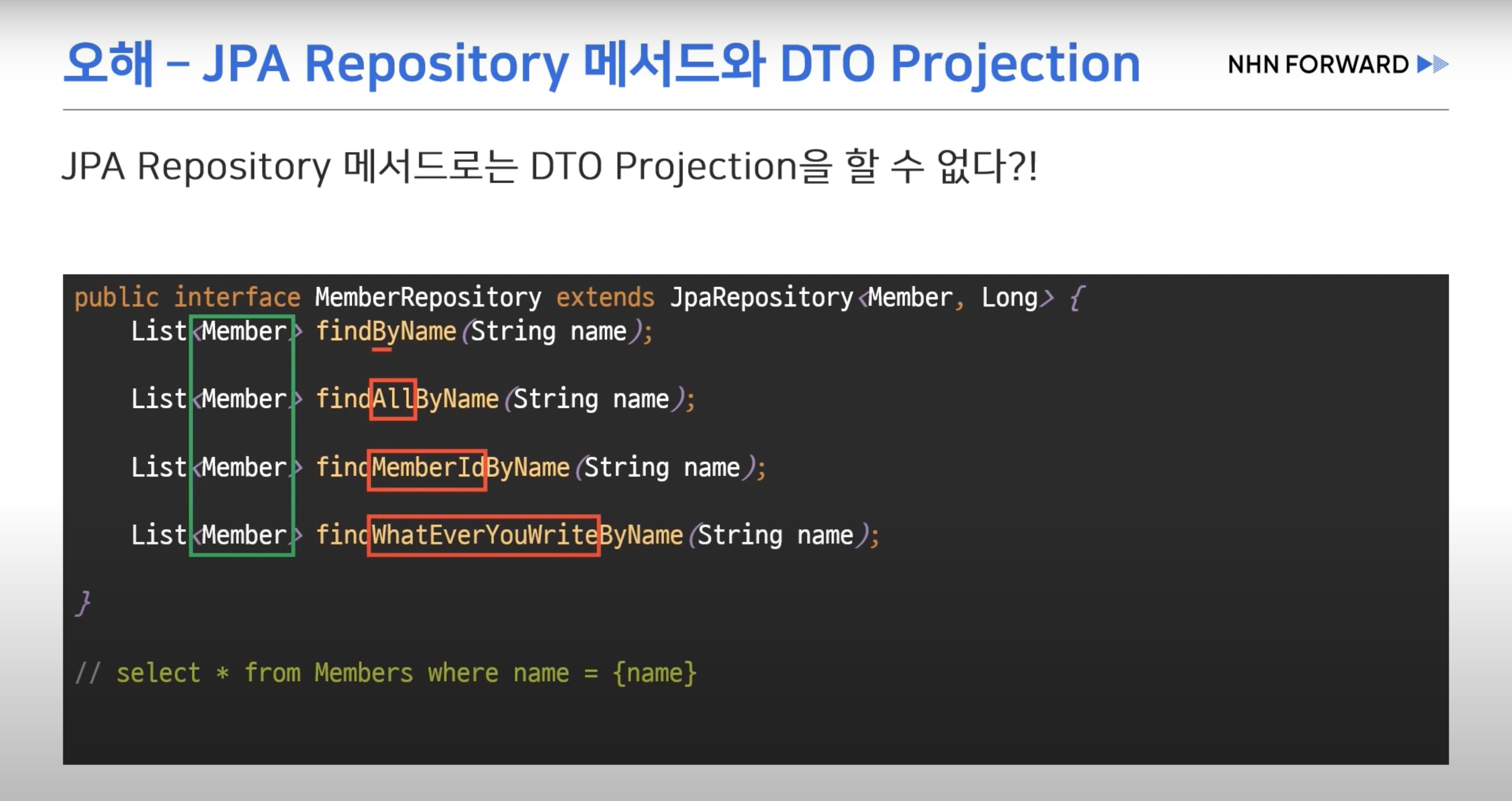
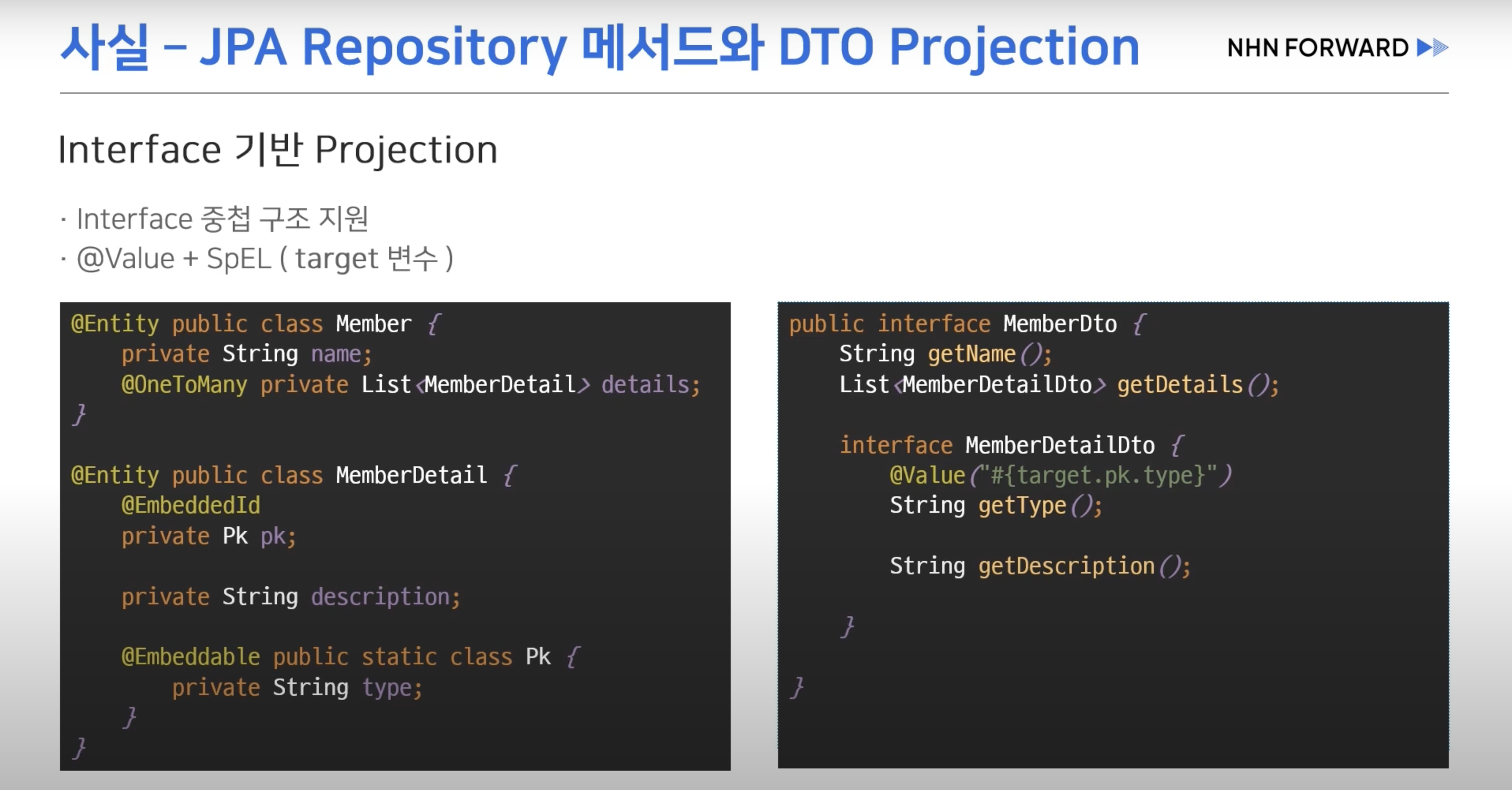
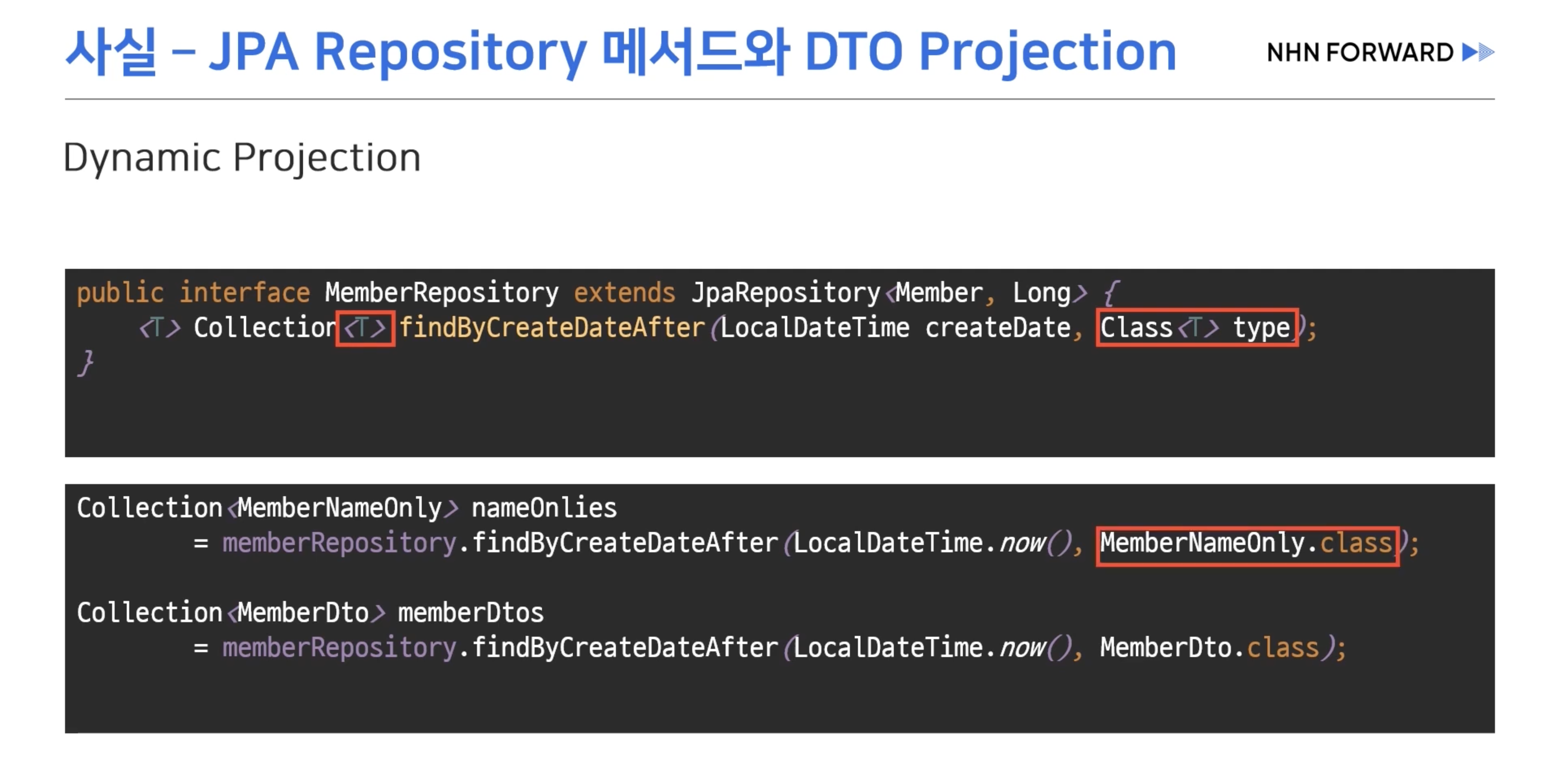
- DTO Projection

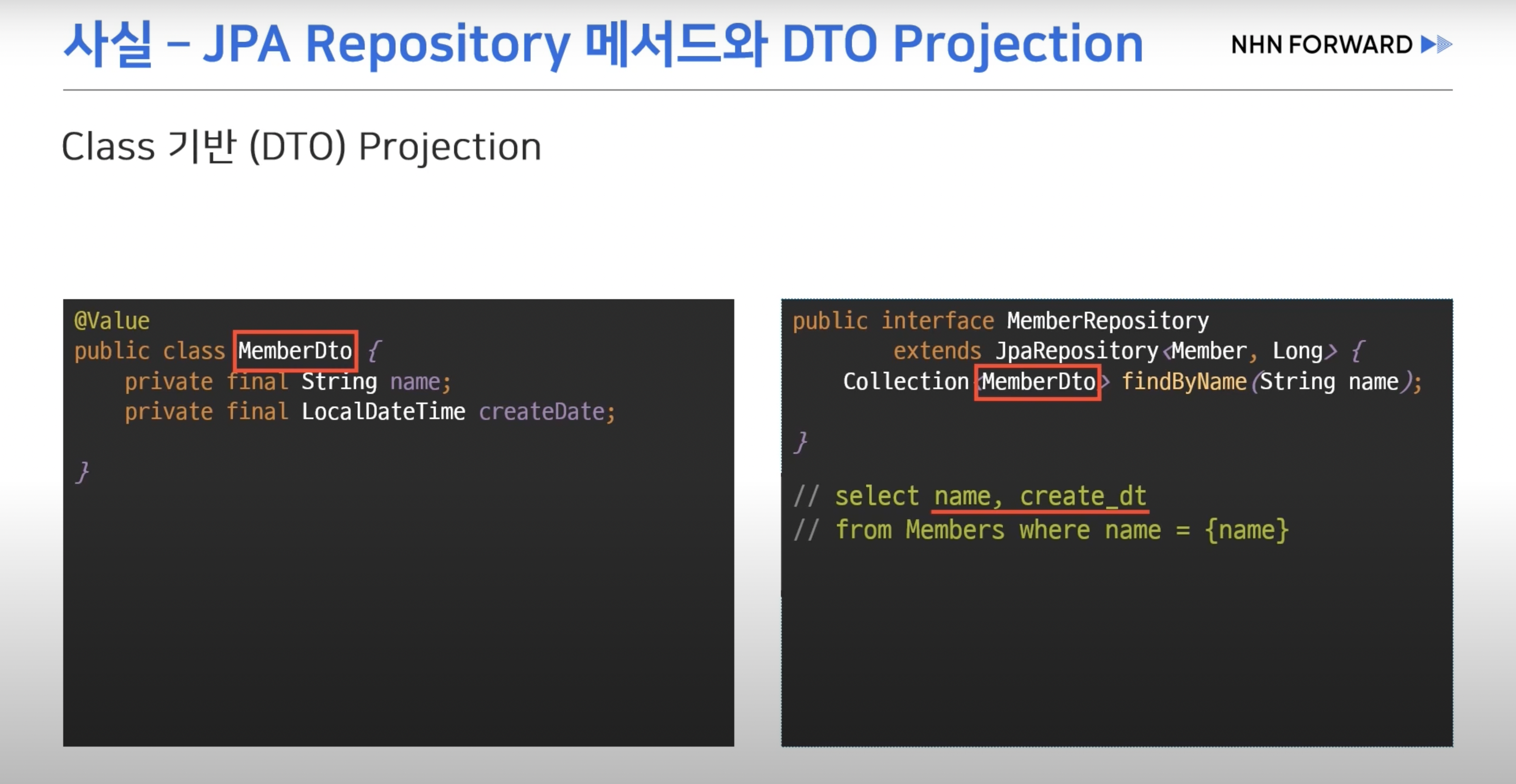

- 인터페이스만 생성해두면 JPA가 프록시 객체를 통해 쿼리를 수행한다.

Reference

몰라요