
[컨퍼런스 링크 - NHN Foward Redis 야무지게 사용하기]
위의 영상을 보고 정리한 포스트

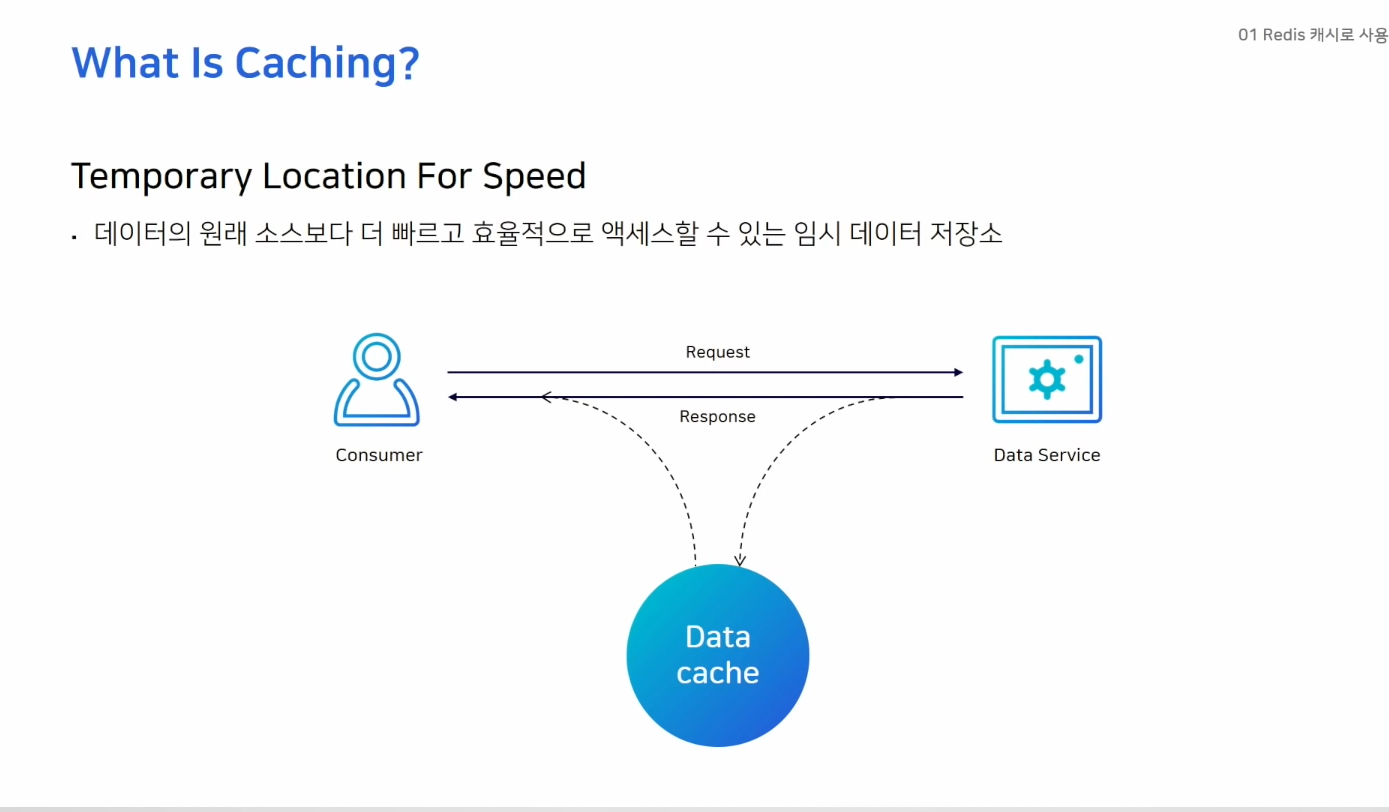
캐시는 언제 사용해야 좋을까?
- 동일한 데이터에 대해 반복적으로 엑세스하는 경우가 많을 때
- 잘 변하지 않는 데이터일 경우 더 효율적

캐싱 전략
- 어떻게 배치하느냐에 따라 성능에 영향을 끼친다.
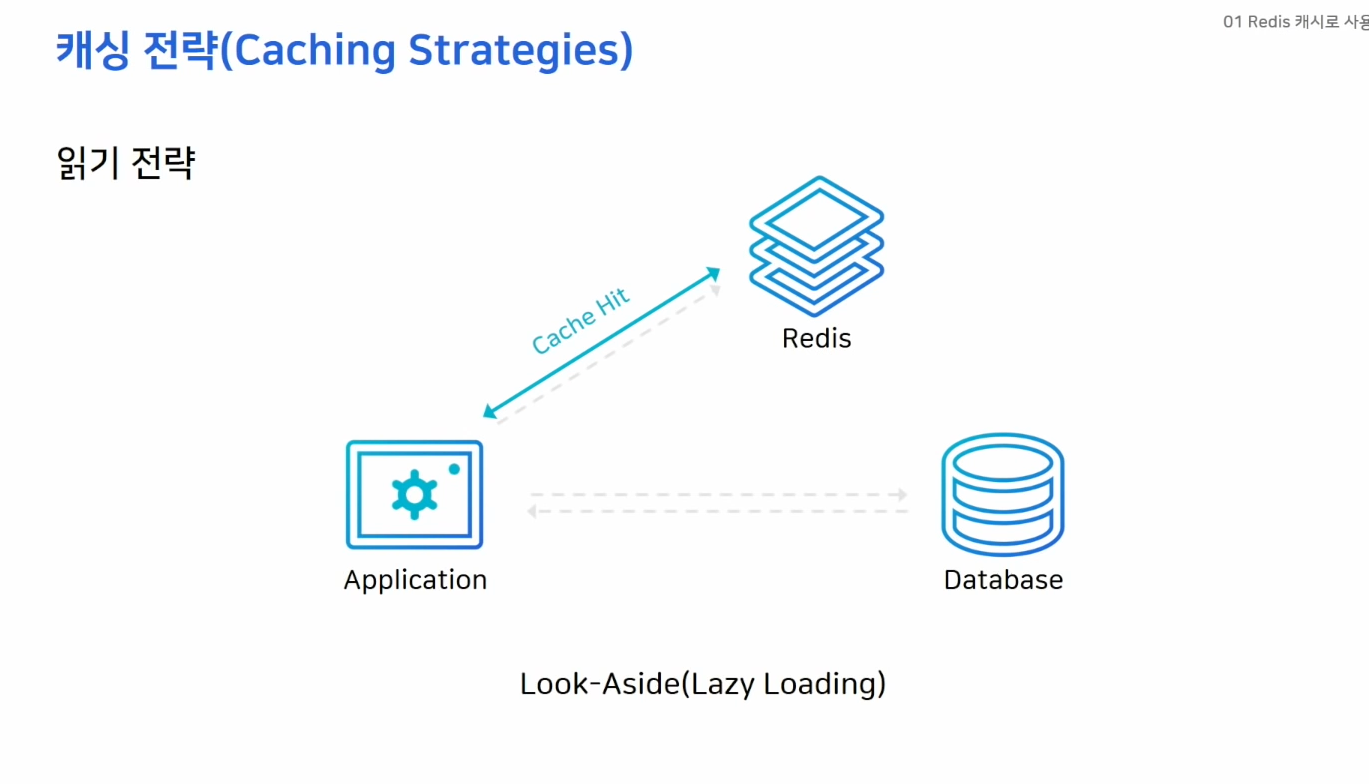
- 어플리케이션에서 데이터를 읽는 작업이 많을때
- 레디스를 캐시로 이용할때 가장 많이 사용하는 구조
- 레디스에 찾는 데이터가 없을때 DB에서 데이터를 가져와서 레디스에 저장
- 캐시로 붙어있던 커넥션이 많았다면 해당 커넥션이 모두 DB로 오기 때문에 DB에 갑자기 부하가 올 수 있음 -> 성능저하 가능성이 있음
- 미리 DB에서 캐시로 데이터를 밀어주는 작업으로 대비 가능 (Cache Warming)
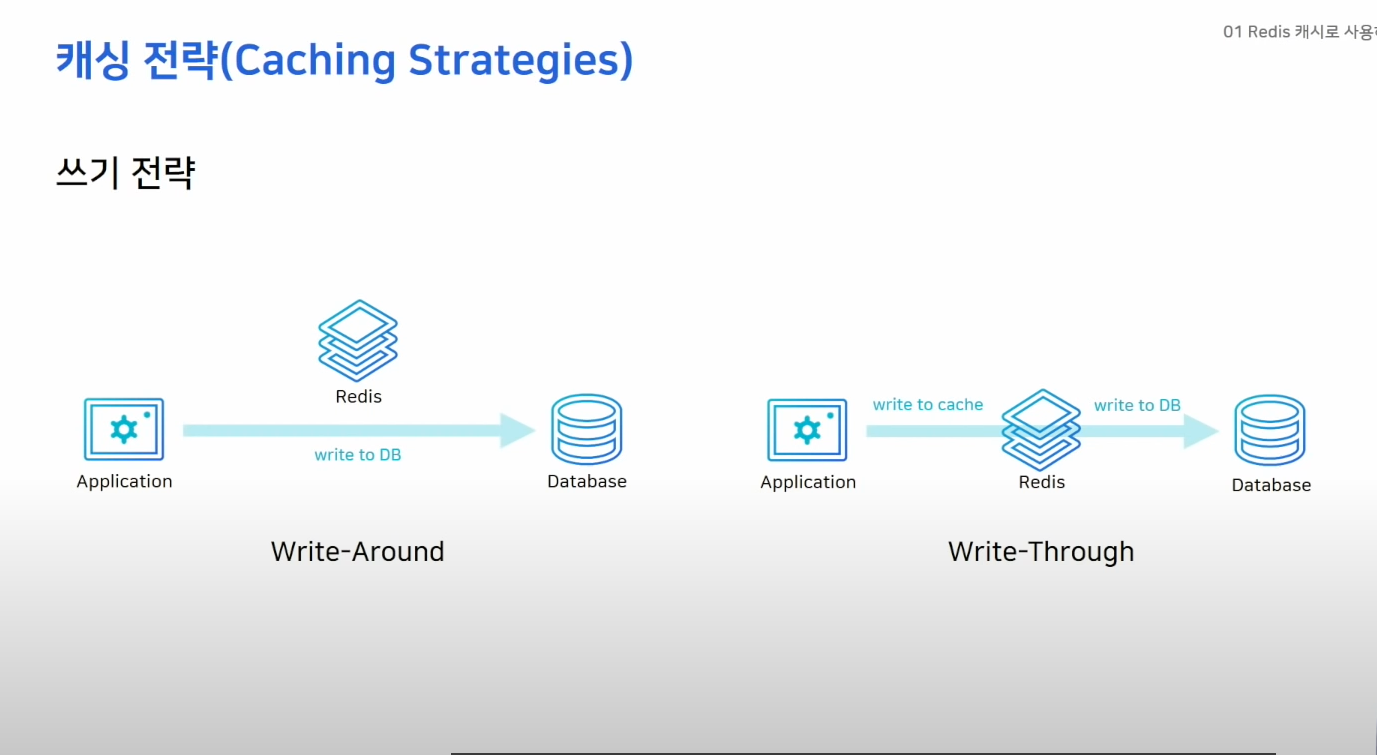
Write-Around
- DB에만 데이터 저장
- 캐시미스 발생시 캐시에 데이터를 끌어옴
- 캐시와 DB의 정보가 다르다.
Write-Through
- DB에 데이터를 저장할 때 캐시에도 저장
- 캐시에 항상 최신데이터 유지
- 두 스텝을 지나기 때문에 성능적으로 불리
- 사용하지 않는 데이터도 저장하기 때문에 리소스 낭비 -> expire time 설정하는게 좋음
데이터 타입 야무지게 활용하기
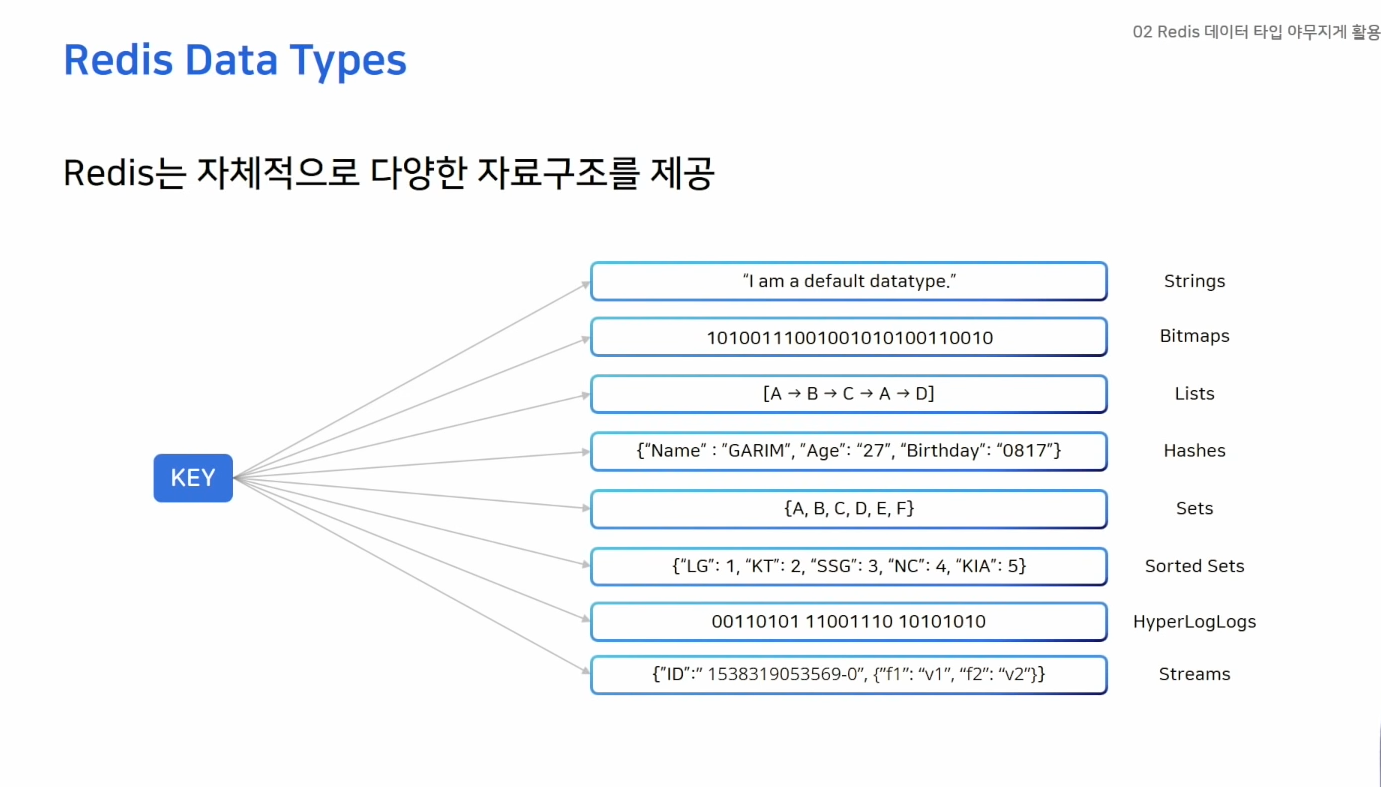
String: 가장 기본적인 데이터 타입Bitmaps: String의 변형 Bit연산 가능Lists: 리스트 -> 큐로 사용적절Hashes: 하나의 키안에 다시 여러개의 키밸류 저장Sets: 중복되지 않는 값Sorted Sets: score 값으로 정렬되어 저장됨HyperLogLogs: 많은 데이터를 다룰때 사용 중복되지 않는 데이터값을 카운트할때Streams: 로그를 저장하기 좋은 자료구조
다양한 카운팅 방법
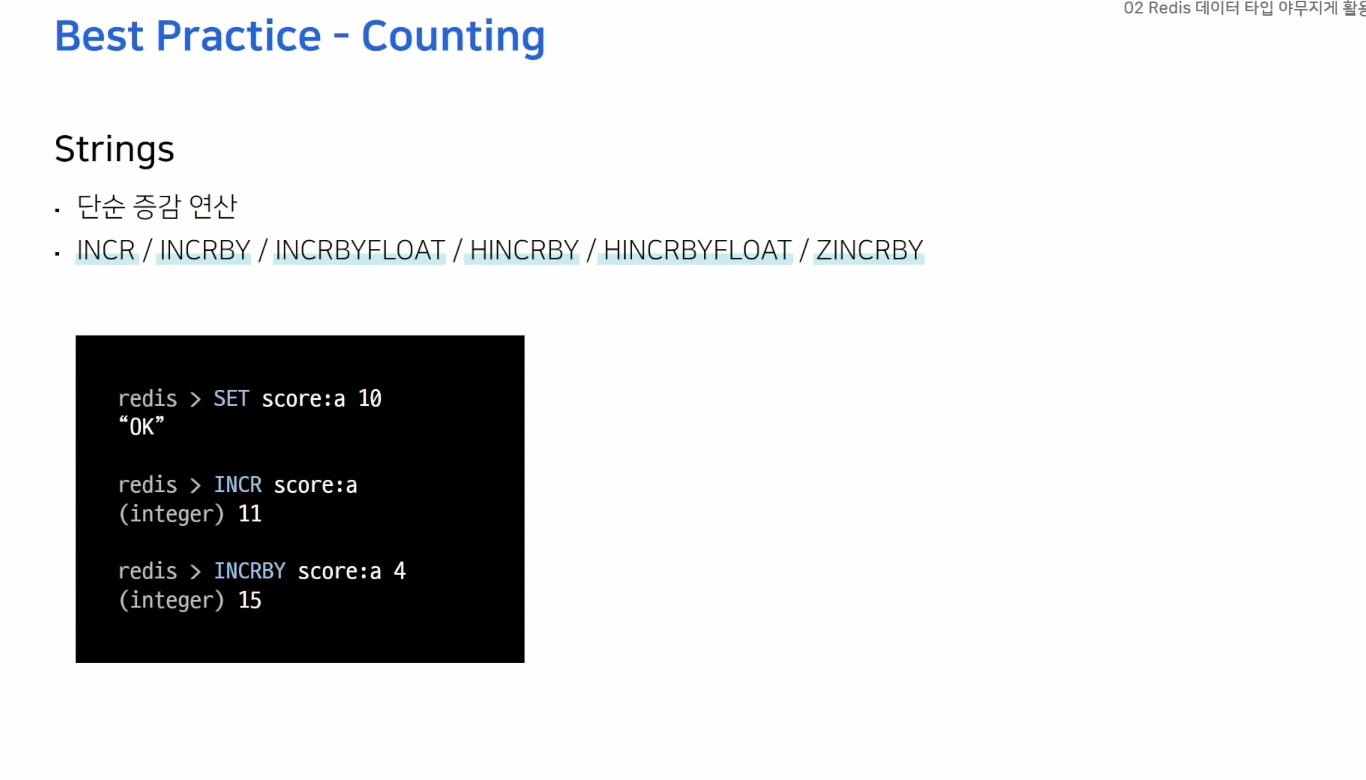
- 간단한 증감 연산 사용
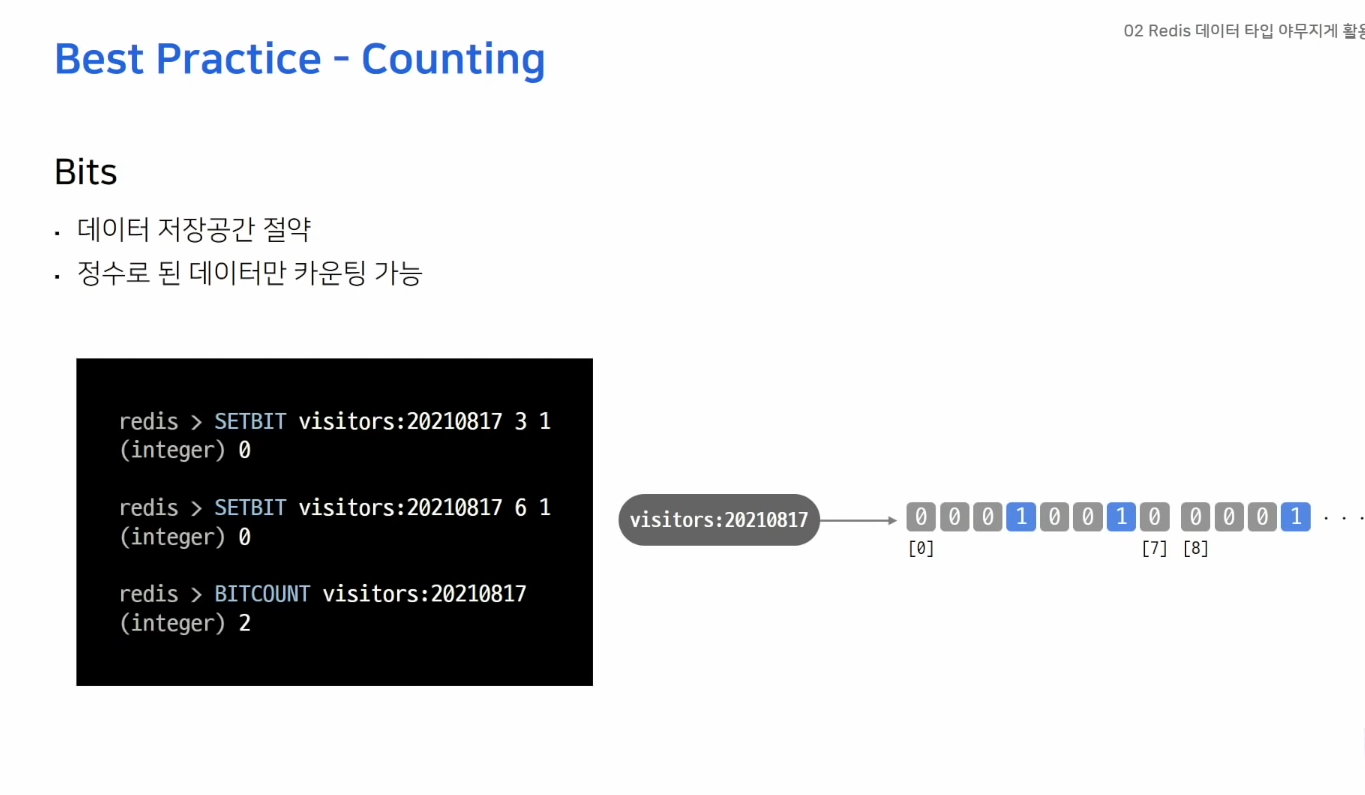
- ex) 오늘 접속한 유저 수를 세고 싶다.
- 날짜 키를 생성하고 유저id에 해당하는 비트를 1로 올려준다.
- 한 개의 비트가 한 명을 의미
- 천만명은 천만개의 비트 -> 약 1.2MB
- 공간절약 굳
- 모든 데이터를 정수로 표현할 수 있어야함 (USERID가 정수여야한다.)

- 모든 String 데이터값을 유니크하게 구분 가능
- 저장되는 데이터 개수에 상관없이 모두 12KB로 고정
- 저장된 데이터 확인 불가 -> 데이터 보호
- ex) 우리 웹사이트에 방문한 IP 몇개?
- 크롤링한 URL 몇개?
- 검색엔진에서 검색된 유니크한 단어가 몇개?
- 크고 유니크한 값을 계산할때 적절하다.
메시징
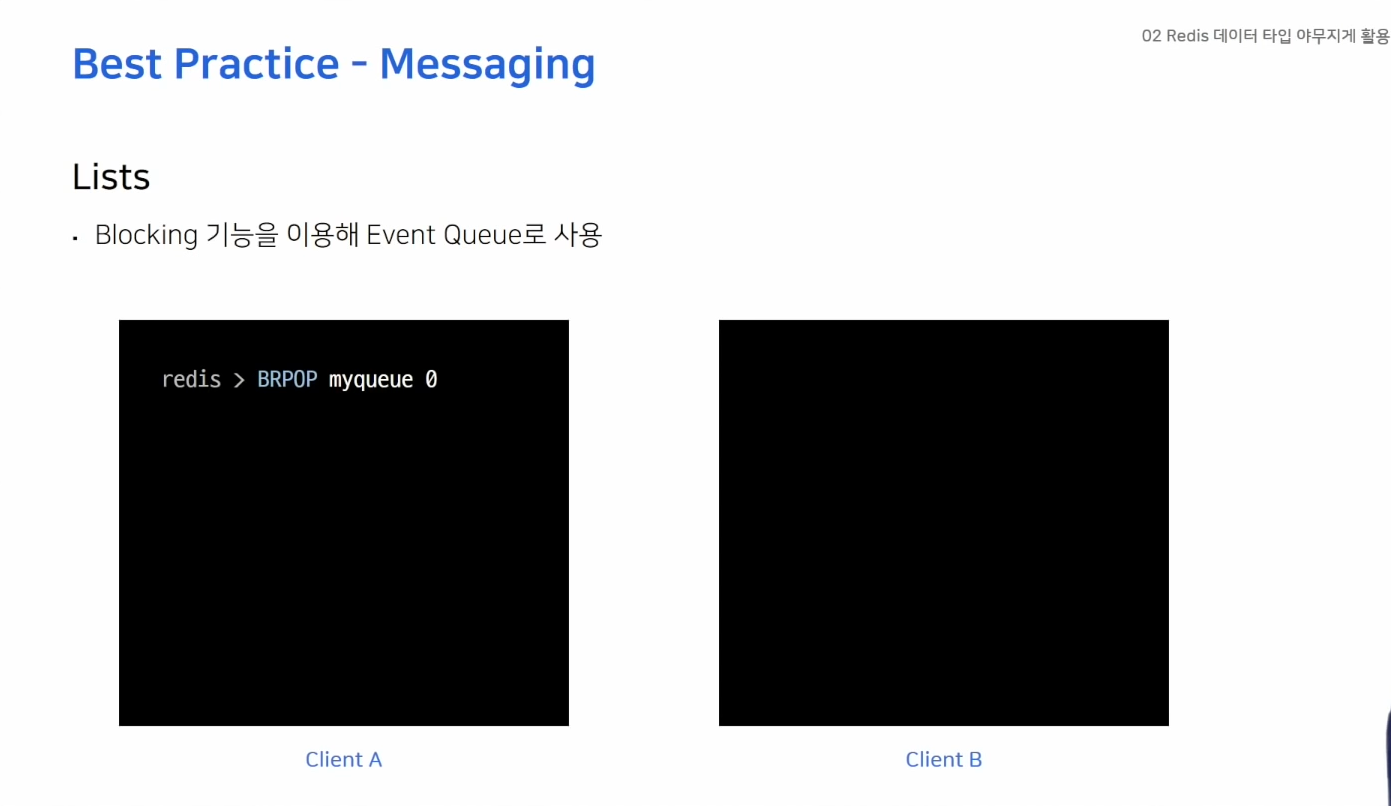
- BRPOP 커맨드 통해 myqueue에서 데이터를 꺼내오려 하는데 리스트 않에 데이터가 없음

- 클라이언트 B가 메시지를 넣으면 확인 가능
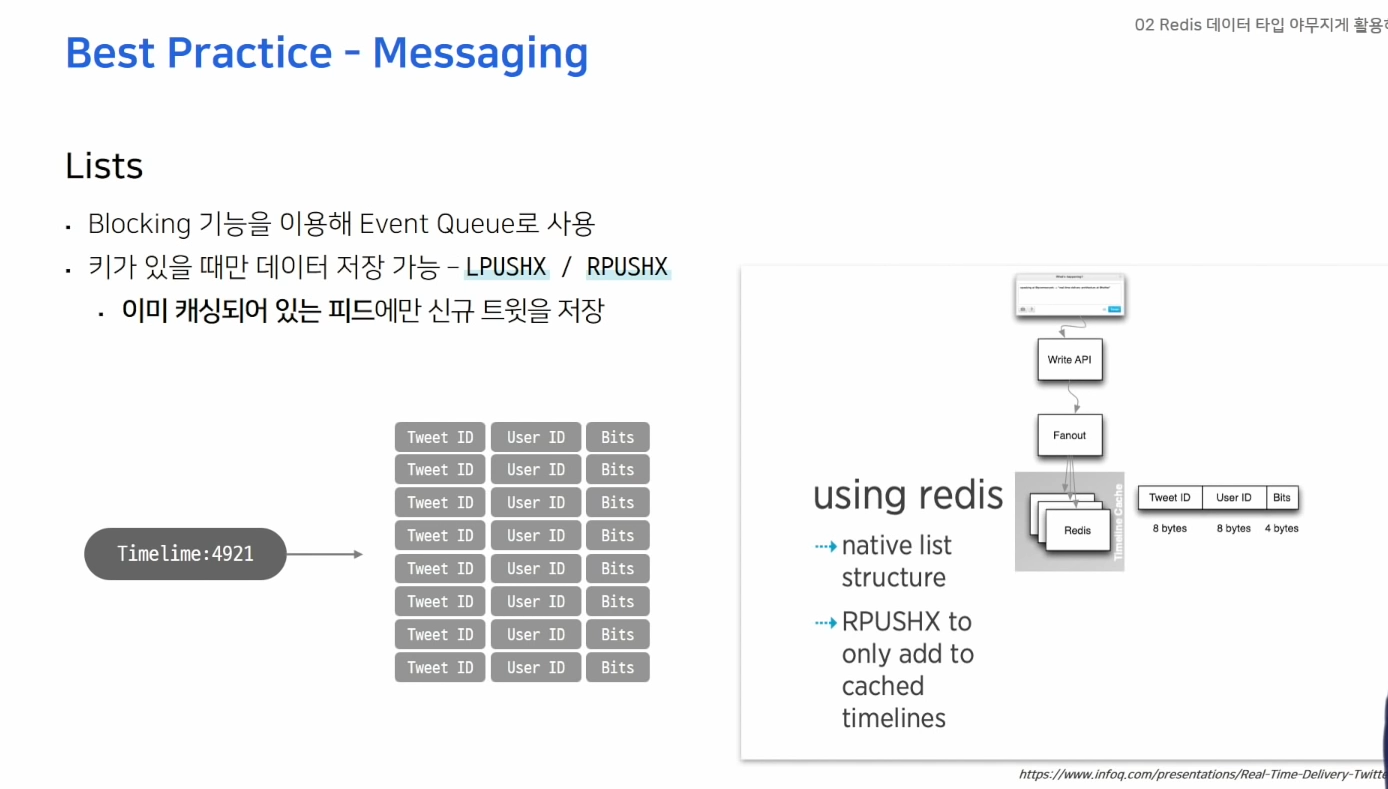
- LPUSHX, RPUSHX 키가 있을때만 데이터를 추가 -> 불필요한 데이터 이동을 방지
- 키가 있다는건 예전에 사용했던 큐 -> 사용했던 큐에만 메시지를 넣어 줄 수 있기 때문에 효율적
- 인스타, 트위터 -> 타임라인에 보여줄 데이터를 캐싱하기 위해 Redis Lists 사용(RPUSHX) 트위터를 자주 사용하는 유저들의 새로운 데이터를 미리 캐시, 자주 사용하지 않는 유저는 캐시하지 않아 불필요한 데이터 흐름 방지

- 중간에 데이터가 바뀌지 않는다.
- *로 ID를 자동 저장
- 반환된 ID값 = 데이터가 저장된 시간
데이터를 읽어오는방법
- id를 활용한 시간대역대
- 새로들어온 데이터만
- 카프카처럼 소비자 그룹이 존재, 원하는 소비자만 특정 데이터 읽기 가능
- Streams -> 메시징 브로커가 필요할때 카프카를 대신해 간단히 사용할 수 있는 자료구조다 (공식문서)
데이터 영구 저장하기

- 두가지 방법이 있다
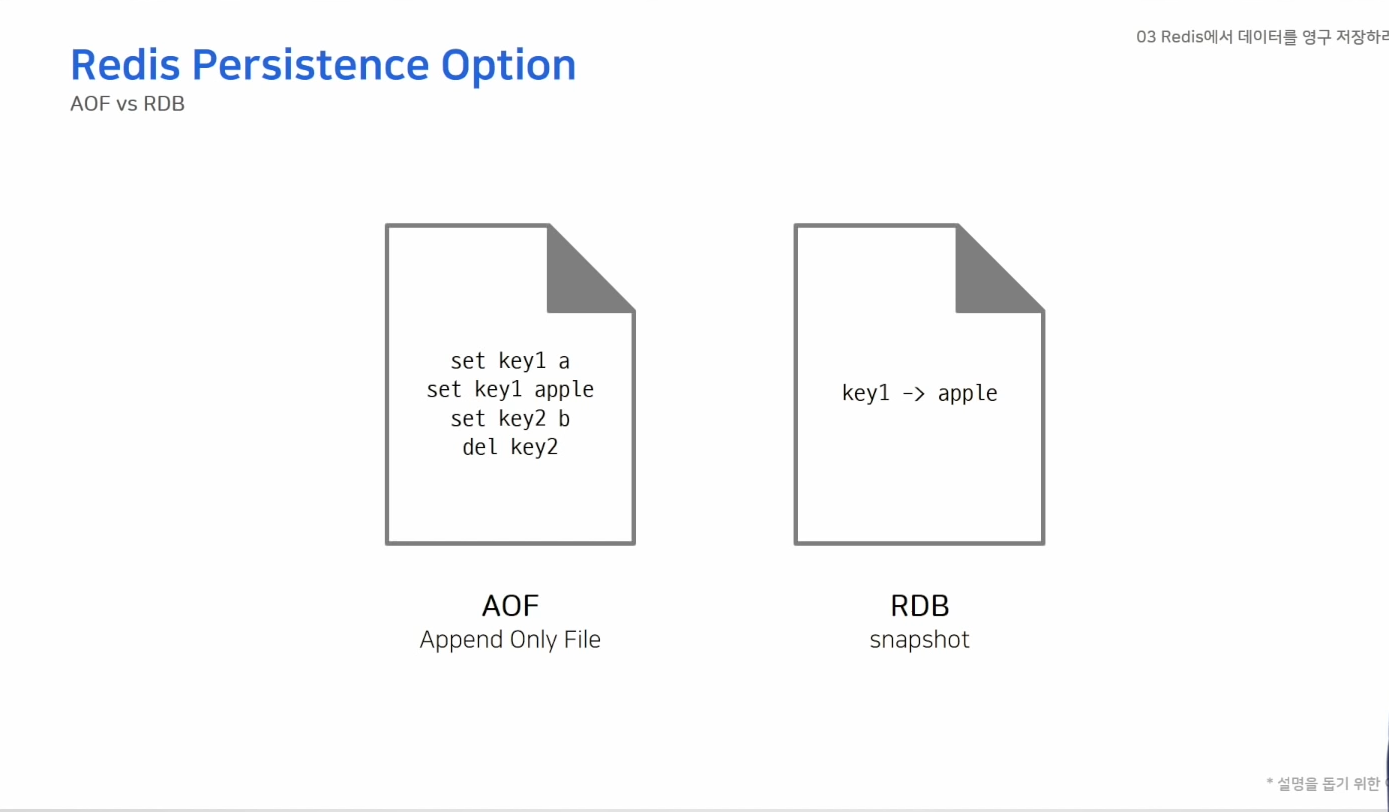
- AOF - 데이터를 변경하는 커맨드가 들어오면 커맨드를 그대로 모두 저장
- RDB보다 파일 크기가 커지기 때문에 주기적으로 압축 필요
- 레디스 프로토콜 형태로 저장
- RDB - 스냅샷 방식으로 동작 저장 당시 메모리 그대로를 파일로 저장
- 바이너리 파일 형태로 저장


- 레디스를 캐시로만 사용할 경우 백업 필요없음
SAVE 900 1: 900초 동안 한 개 이상의 키가 변경되었을때 RDB 파일 재작성
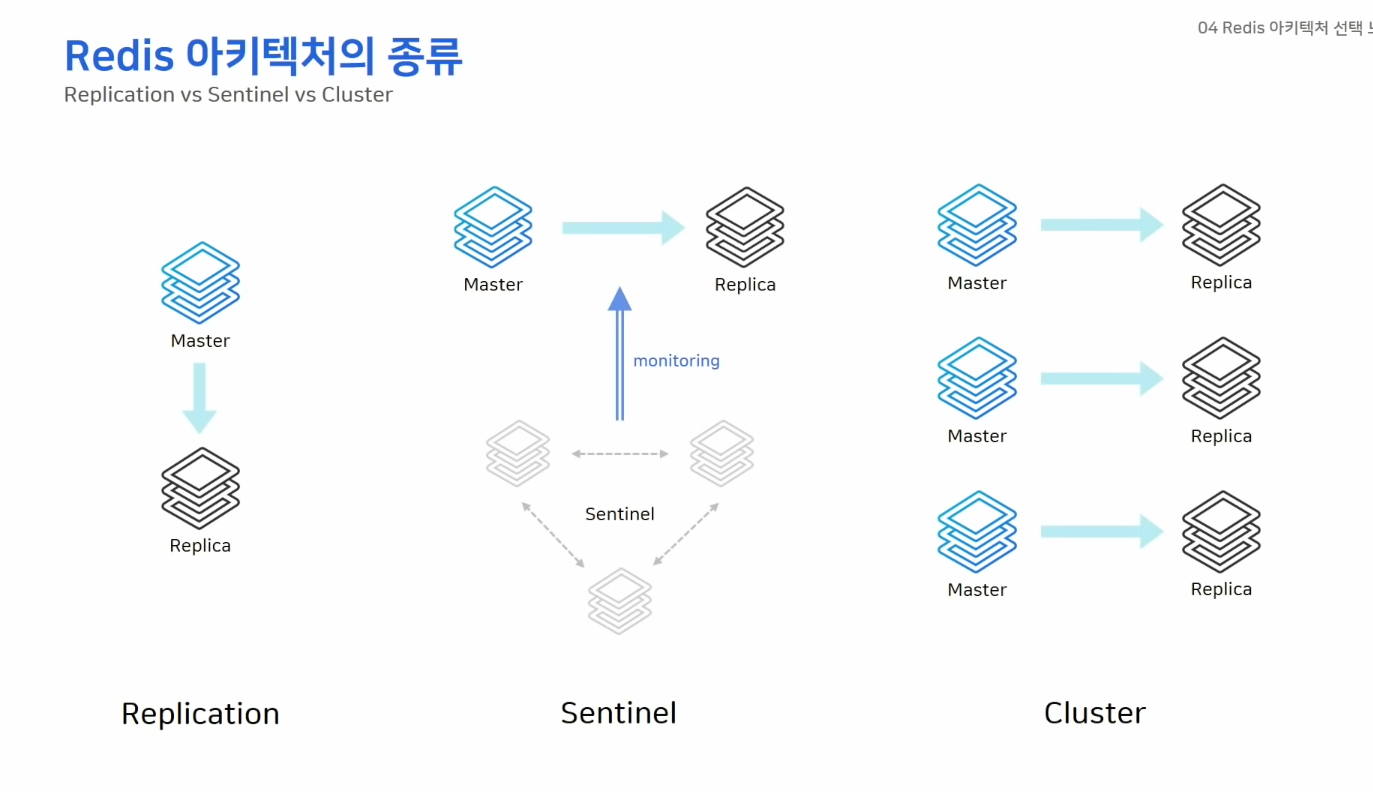
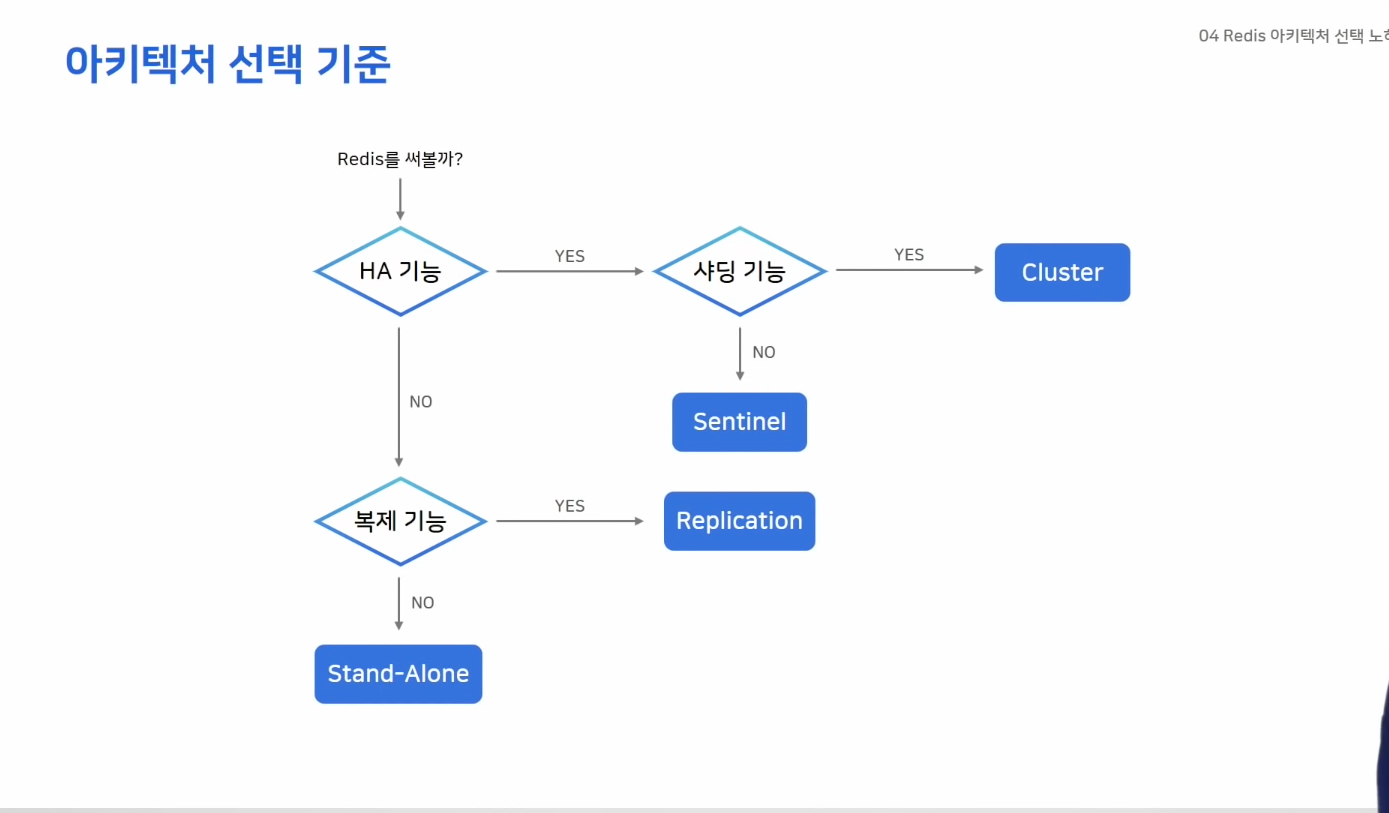
아키텍처 선택 노하우
- Replication
- Sentinal
- Cluster

- HA 기능?



운영 꿀팁과 장애 포인트

- 싱글 스레드인 Redis에서 keys * 커맨드는 사용하지말자 scan을 사용하면 재귀적으로 호출해서 성능이 빠르다.

- 모니터링을 하고있다면 SWOBE를 꺼두자
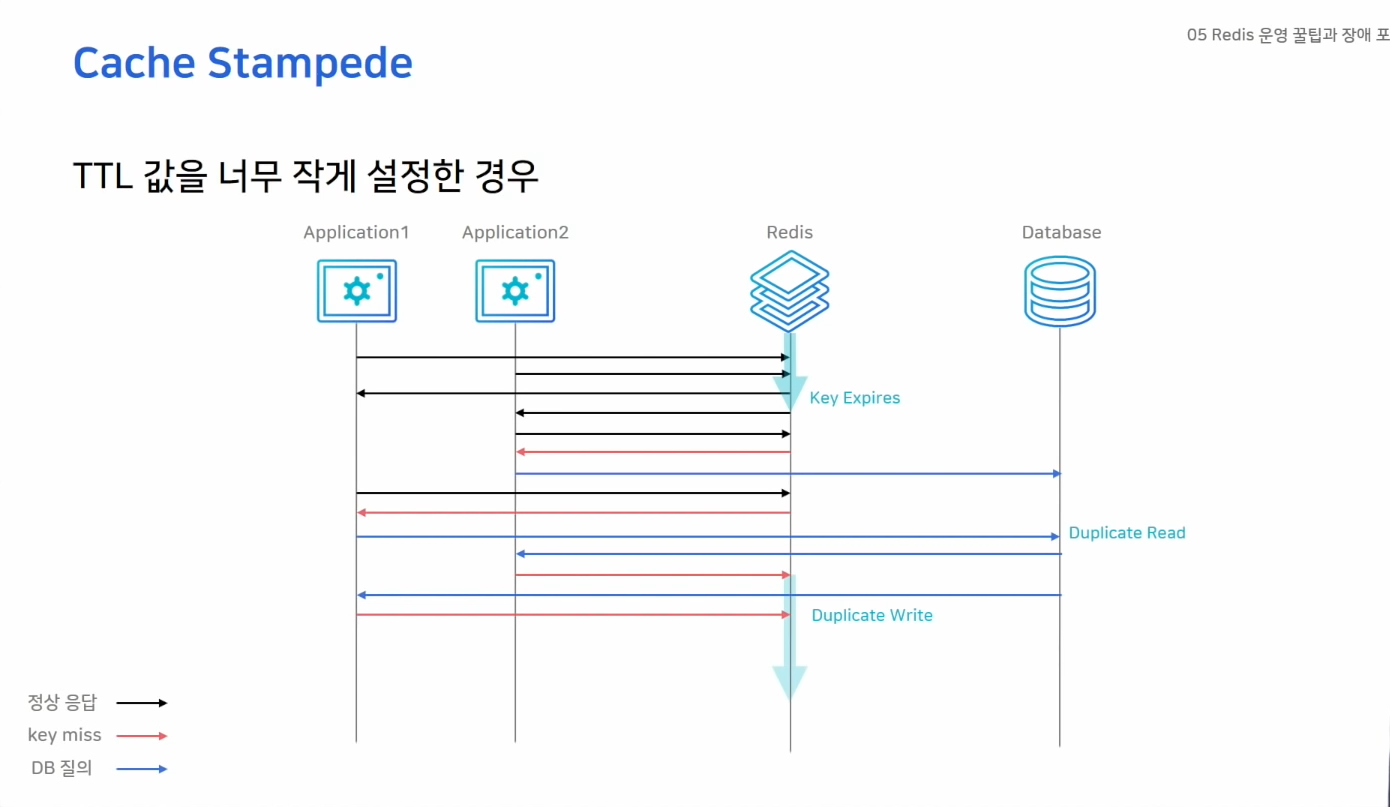
- 대규모 트래픽 환경에서 TTL을 너무 작게 설정할 경우 발생
- 여러 노드가 같은키를 바라보고 있을 경우 Expire Time이 만료되면 여러 노드가 동시에 DB 데이터를 읽게 되고 동시에 Cache Write를 하게되는 문제가 발생한다 -> 처리량이 느려지고 불필요한 작업을 수행하게됨. -> 장애발생 가능
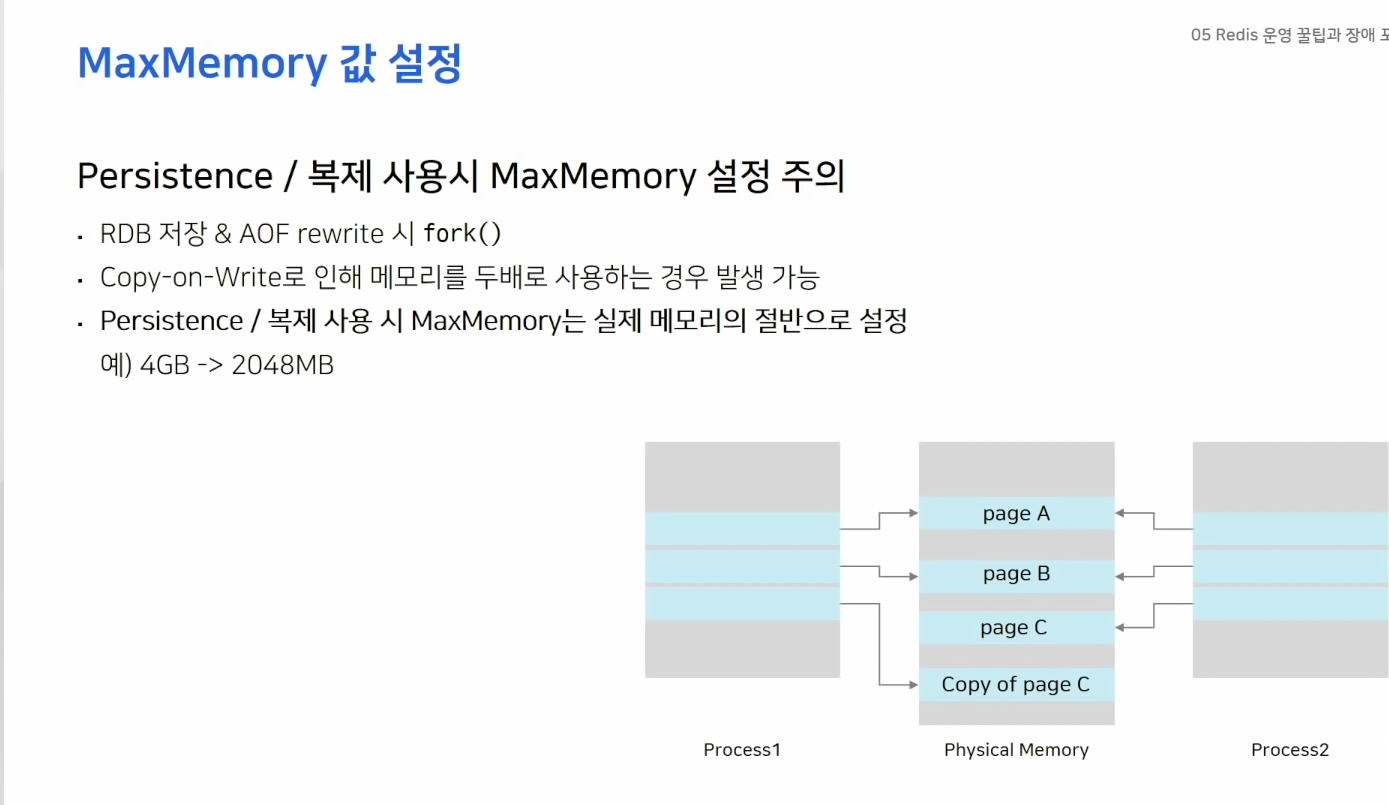
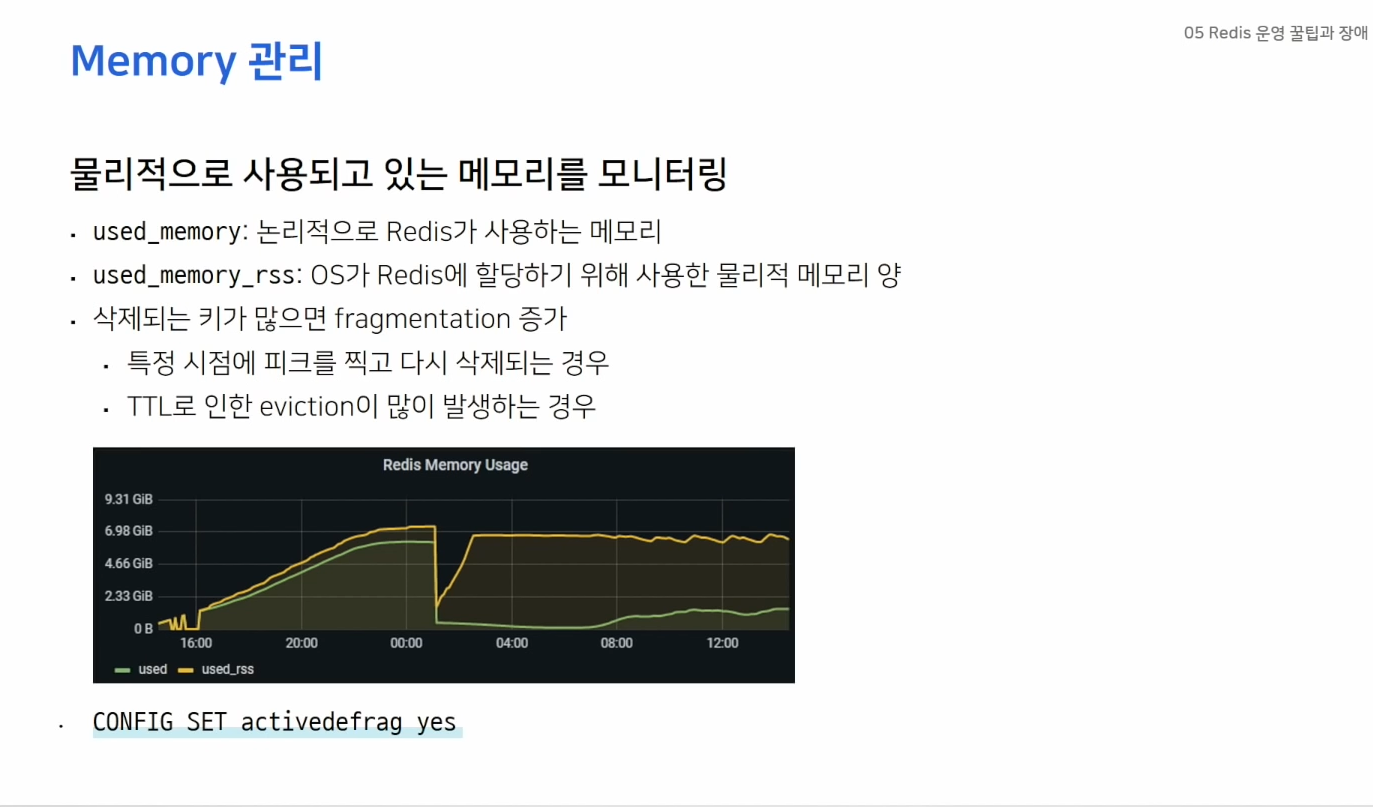
- used_memort_rss를 주의깊게 봐야한다.
- fragmentation : 실제 사용하는 메모리는 적은데 RSS가 크게 설정될 경우 -> fragmentation이 크다.
-> 단편화가 많이 발생시 activedefrag 옵션을 활용하자.

몰라요