
위 영상을 보고 정리한 내용
카카오톡 메시징 시스템

일평균 초당 50만
평균 연결 세션 수 4천만
최고 트래픽 (국제 행사 등) 초당 600만
위 프로젝트 이후로 부터 위에 언급한 대용량 트래픽을 감당할 수 있게되었음
메시징 시스템 (루비 -> C++, Java)
모바일 환경에서 빠르게 통신하기 힘든 HTTP -> 패킷사이즈 경량화, 빠르게 통신 가능한 자체프로토콜 개발
왜 모바일 환경에서 HTTP로 빠르게 통신하기 힘들었나?
-
헤더 오버헤드: HTTP는 헤더를 포함한 메타데이터를 사용하여 요청과 응답을 전송합니다. 모바일 환경에서는 헤더 오버헤드가 상대적으로 큰 비중을 차지할 수 있어, 데이터 양이 적은 작은 요청이나 응답도 불필요한 헤더 정보가 포함되어 전송되어 효율이 떨어질 수 있습니다.
-
연결 설정 비용: HTTP는 요청마다 새로운 연결을 설정하고 해제하는 방식으로 동작합니다. 모바일 환경에서는 이러한 연결 설정과 해제 비용이 높을 수 있어, 짧은 시간 동안 여러 번의 요청과 응답이 이루어지는 경우에는 비효율적일 수 있습니다.
-
순차적 요청/응답: HTTP는 요청과 응답이 순차적으로 이루어지는 방식으로 동작합니다. 모바일 환경에서는 요청과 응답이 번갈아가며 이루어지는 경우에는 통신 속도가 저하될 수 있습니다. 예를 들어, 하나의 요청에 대한 응답이 늦어지면 이후의 요청들도 늦어질 수 있어 전체적인 통신 시간이 증가할 수 있습니다.
-
대기 시간: 모바일 환경에서는 이동통신망의 무선 환경이나 신호 강도에 따라 대기 시간이 늘어날 수 있습니다. HTTP 통신에서는 대기 시간이 증가하면 전체적인 응답 시간이 늦어지게 됩니다.
-
대역폭 제한: 모바일 환경에서는 대역폭이 제한적일 수 있습니다. HTTP는 요청과 응답의 데이터 양이 많을 수 있어, 대역폭이 제한된 환경에서는 통신 속도가 저하될 수 있습니다.
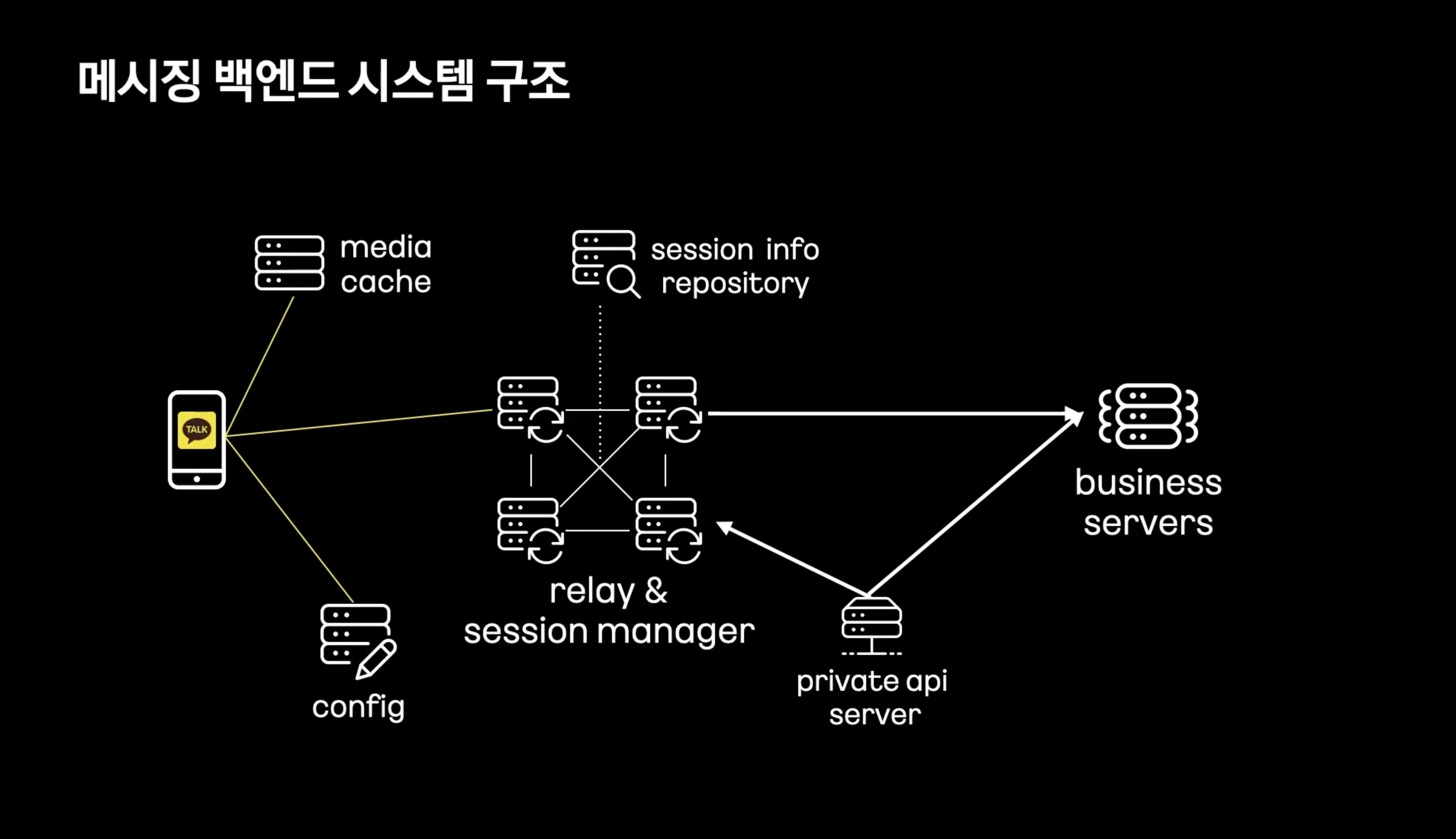
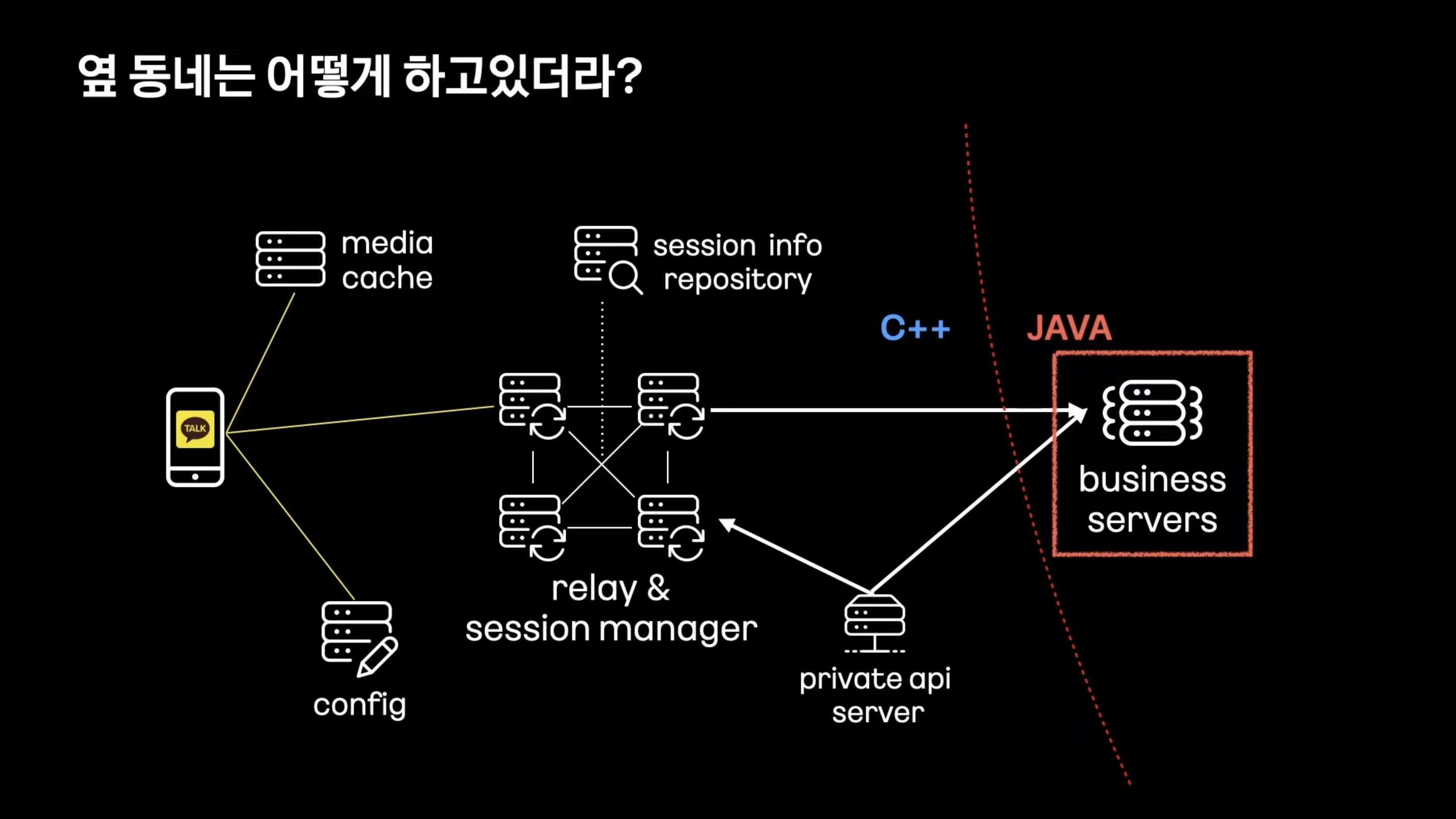
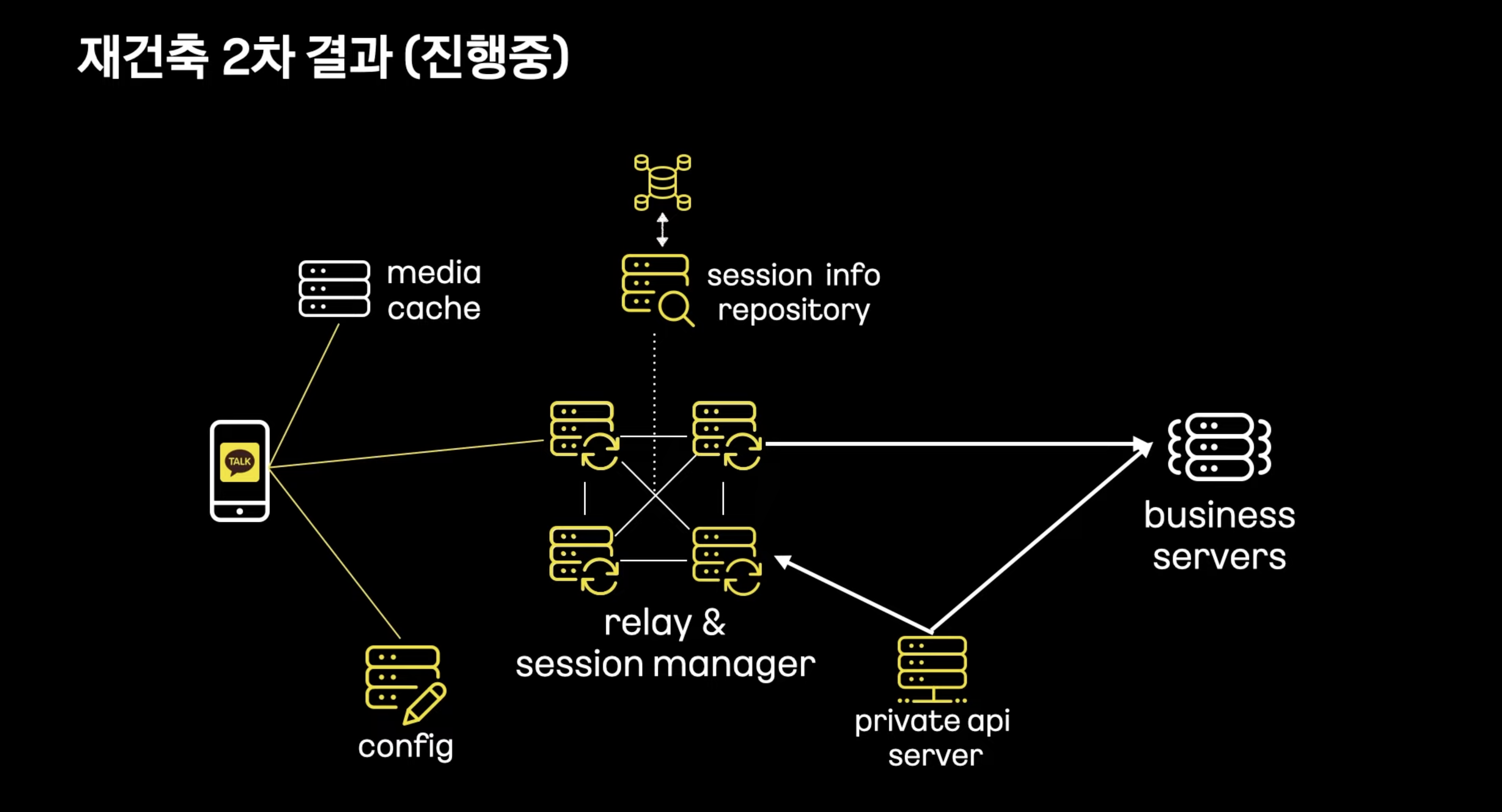
Config Server : 연결 설정등을 받아옴
Relay Server : 메시지 수신, 발신을 위한 Full Mesh 구조의 서버
Upload Cache : 사진, 동영상 저장
Business Server : 메시지 저장, 채팅방 관리
** 메시지 릴레이 ( 메시지 전송과정 중간에 메시지를 전달하거나 중계하는 역할을 수행하는 노드 )
Full Mesh?
- 컴퓨터 네트워크 토폴로지중 하나로, 모든 노드들이 서로에게 직접 연결된 형태
- 높은 가용성과 빠른 통신을 제공할 수 있다. 통신 경로가 짧고 직접적이어서 최소한의 지연으로 통신이 이루어진다. 또한 한 노드의 장애가 다른 노드들에게 영향을 미치지 않고 다른 경로를 통해 통신이 가능하다.
- 노드가 많아질수록 연결이 복잡하고 비용이 높아지는 단점이 있다.
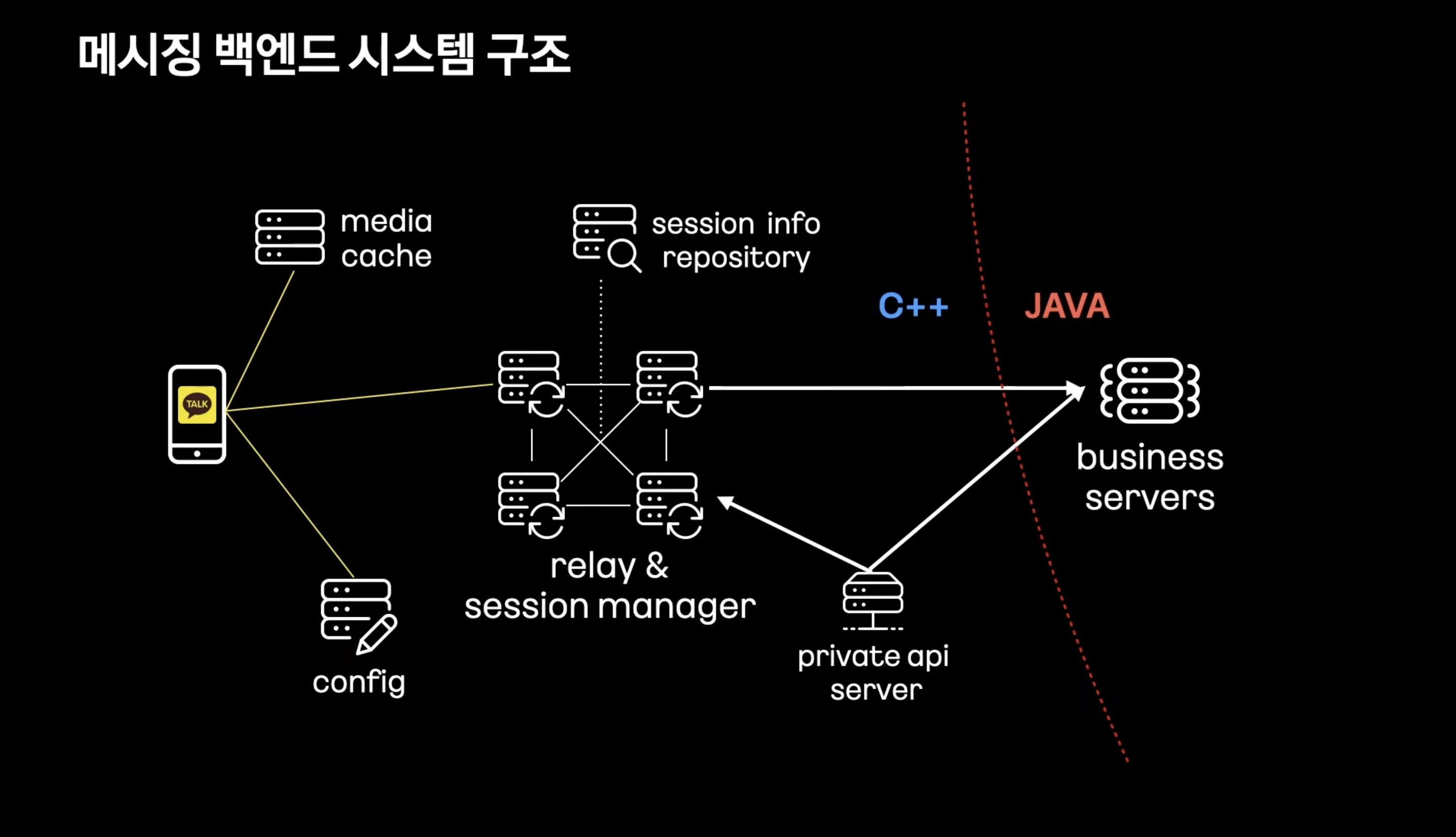
클라이언트와 직접 통신하는 앞단 서버들은 대량의 트래픽을 관리하기 위해 C++
비즈니스 로직, DB와 통신하는 비즈니스 서버는 JAVA

epoll 기반 비동기 입출력?
- 리눅스에서 제고하는 비동기 입출력 모델 중 하나.
- non-blocking
- 여러 개의 입출력 작업을 동시에 처리할 수 있어 효율적인 I/O 처리를 가능
- 잦은 메모리 할당시 발생하는 시스템콜로 인한 지연을 줄이기 위해 쓰레드별로 미리 메모리 버퍼 할당

2011년 이후로 10년간 문제없이 운영해온 메시징 서버
앞으로도 문제가 없을까?
커스텀 엔진과 양산 엔진의 차이
커스텀 엔진 : 한땀 한땀 정성들여 구현 -> 뛰어난 성능 but 유지보수에 어려움
양산형 엔진 : 범용성을 위해 규격화된 모듈구조, 호환성이 좋다. -> 비교적 낮은 성능 but 유지보수, 확장 용이
개선된 서버는 커스텀 엔진과 같았다.
직접 개발한 프로토콜
외부 라이브러리 사용 최소화
제약이 생기기 시작
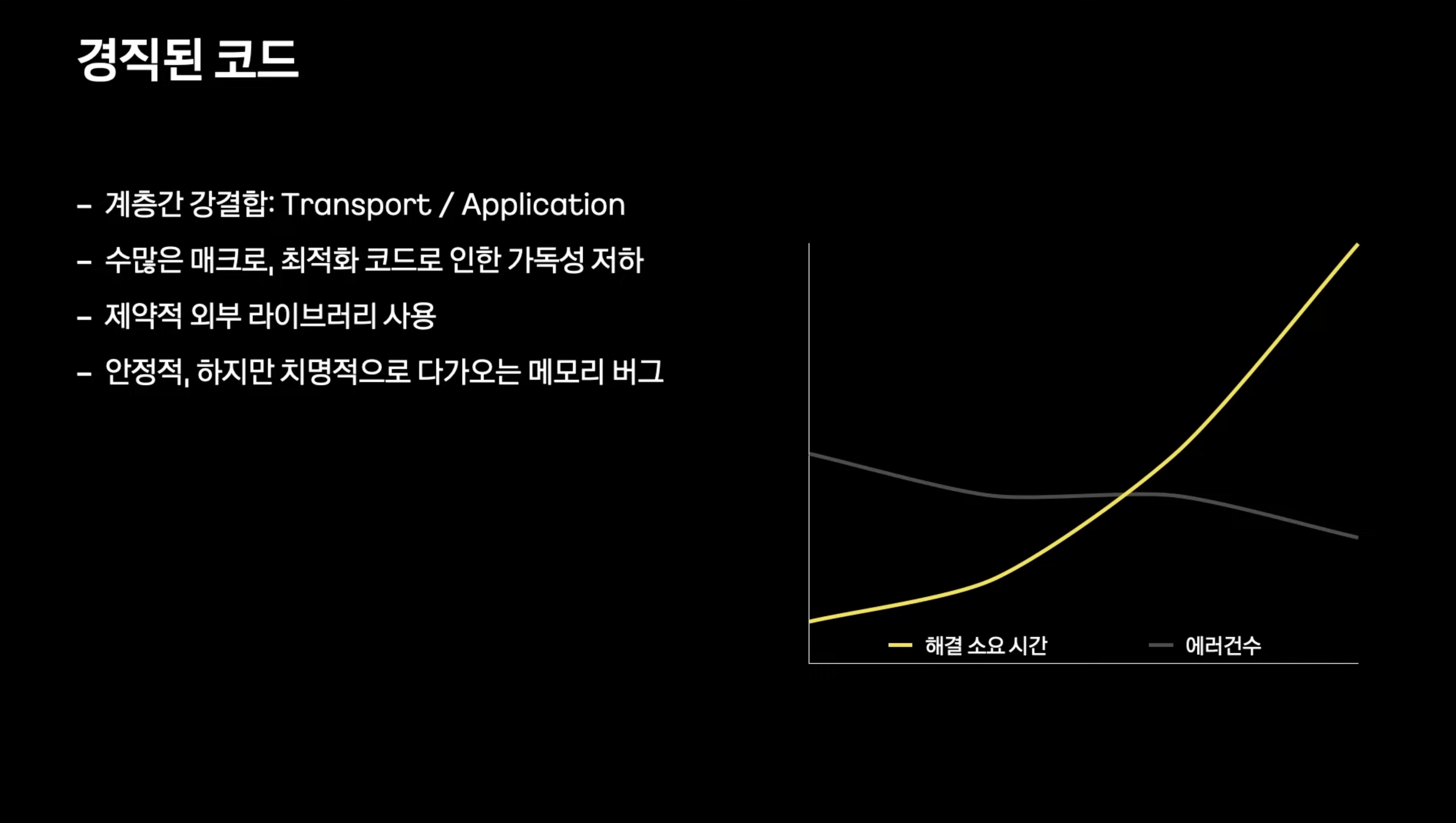
- 직접 만든 프로토콜과 내부 어플리케이션 사이에 강결합으로 인해 프로토콜 확장에 제약
- 확장성 별로
- 메모리 버퍼풀을 사용하는 방식으로 성능은 좋아졌지만 버퍼 크기로인해 메모리 사용 효율 낭비
-> 메모리 버그 발생시 문제 해결에 어려움을 겪음

-
코드의 규모에 비해 적은 단위테스트, 파이썬 스크립트를 통해 원격으로 통합테스트를 하지만 개인이 테스트하기엔 스테이징에 어려움이 많아 복잡했다.
-
실수를 유발하기 쉬운 구조의 배포시스템
-
Spring Java 개발자는 많지만 C++인재가 부족해서 트러블슈팅에 어려움을 겪었고 점점 심해지는 상황
-
배포시스템을 개선하거나 단위테스트를 추가해서 진입장벽을 낮출수는 있다. 하지만 현재 코드의 근본적인 구조는 해결불가, 개편하는건 처음부터 다시만드는 꼴
동일 비즈니스 서버들과 함께가는 것이 좋겠다. -> 비스니스 서버 기술 스택을 따라가기로 결정

- 앞으로 진행될 재건축들은 기본적으로 이런 비즈니스 서버들으 모습을 담으면서 각 모듈에서 필요로하는 사항들을 기반으로 변형하는 방식을 취하기로 했다.
1단계
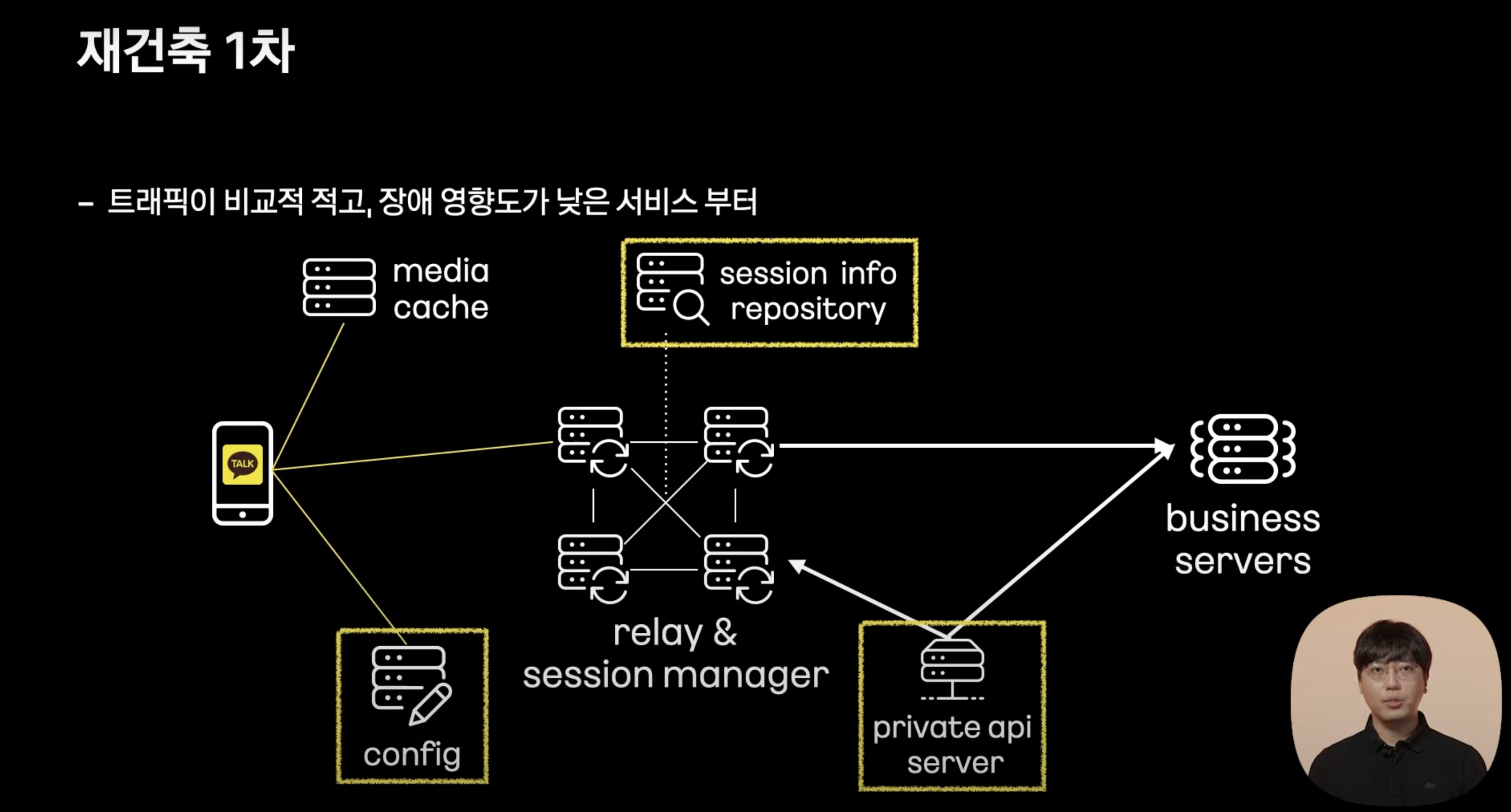
- 각 서버 모듈의 역할은 명확하다.
- 각 모듈에 1대1 대응할 수 있는 대체 서버를 개발
- 변경 과정이 큰 Session과 Papi에 대해

- 호출시 자체프로토콜 -> 사내 다양한 서비스에서 이를 지원해야함 -> 확장에 제약
- 프로토콜 추가에 따른 문서화 부족
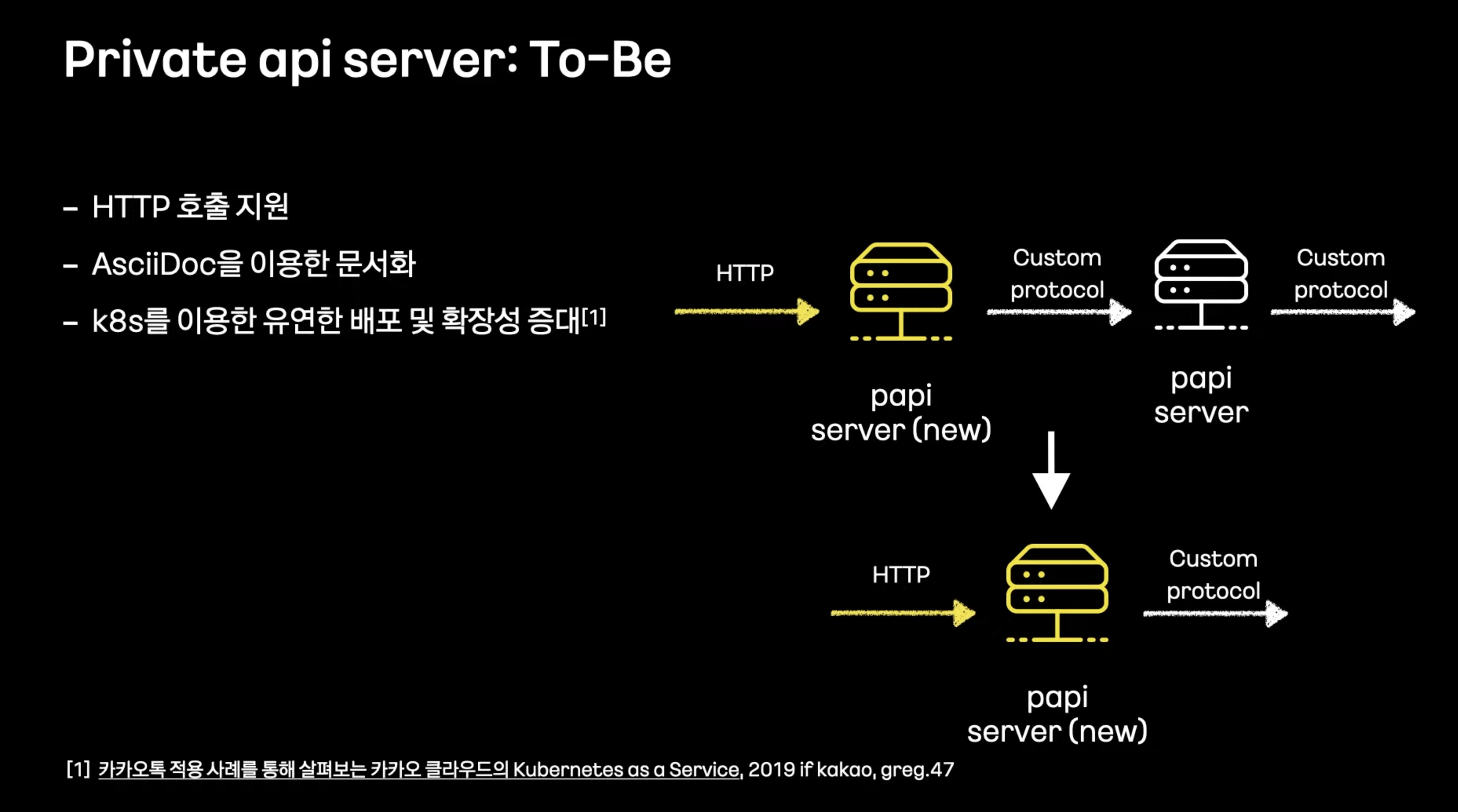
- 장애방지, 호환을 위해 앞단에서 프로토콜 변환만하는 프록시 형태로 구현한 후 완전히 대체

- 릴레이 서버에 연결되어 있는 클라이언트들이 어떤 서버에 접속해 있는지 세션 정보 저장
- 인메모리 저장 특정기준으로 모듈화 해서 여러서버에 저장 -> 확장, 배포가 어려움 클라이언트에 대한 추가정보, 부가로직이 들어가기 어려움
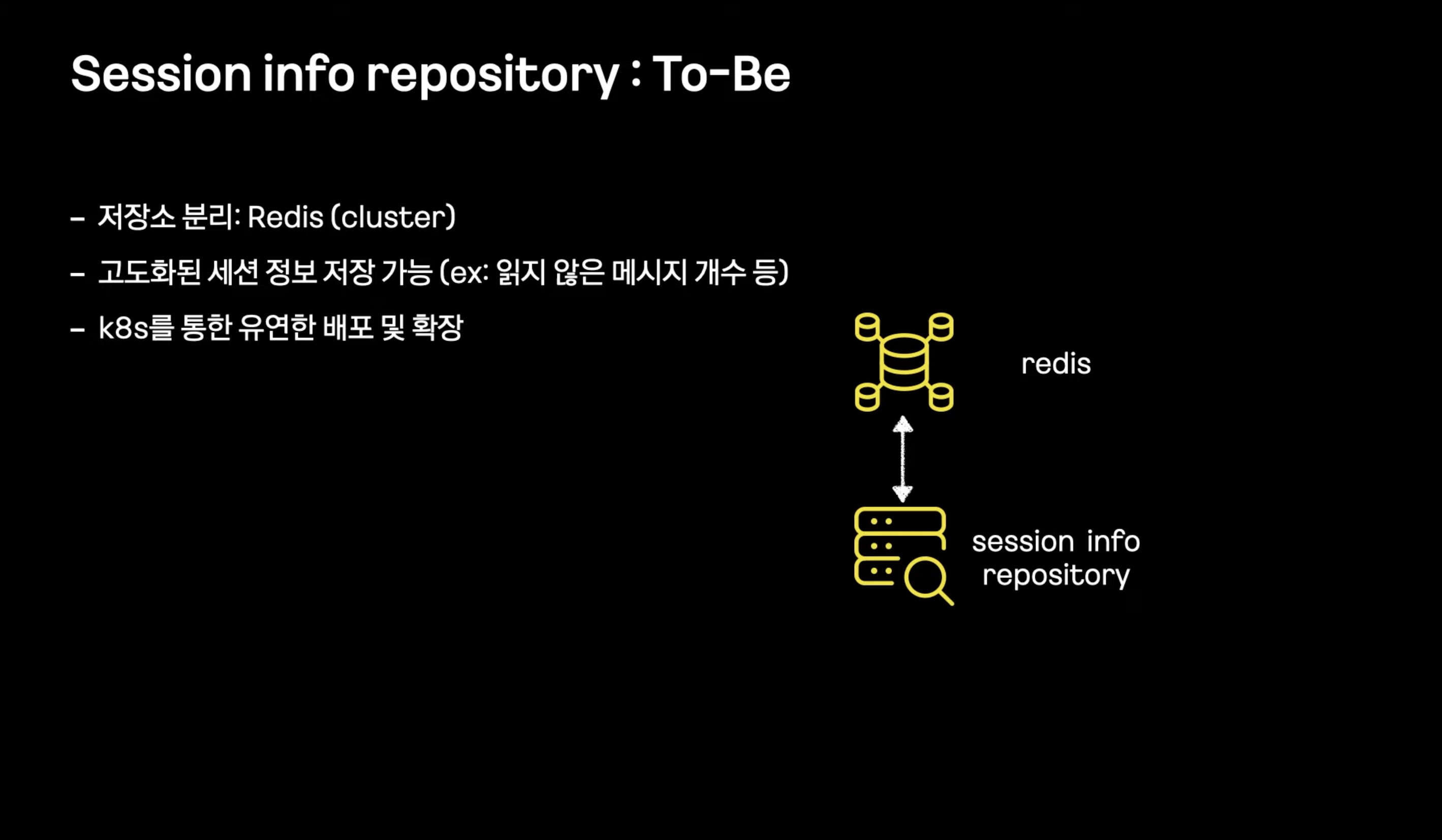
- 저장소를 어플리케이션에서 레디스로 저장하도록 변경
- 배포, 확장을 위해 k8s 적용
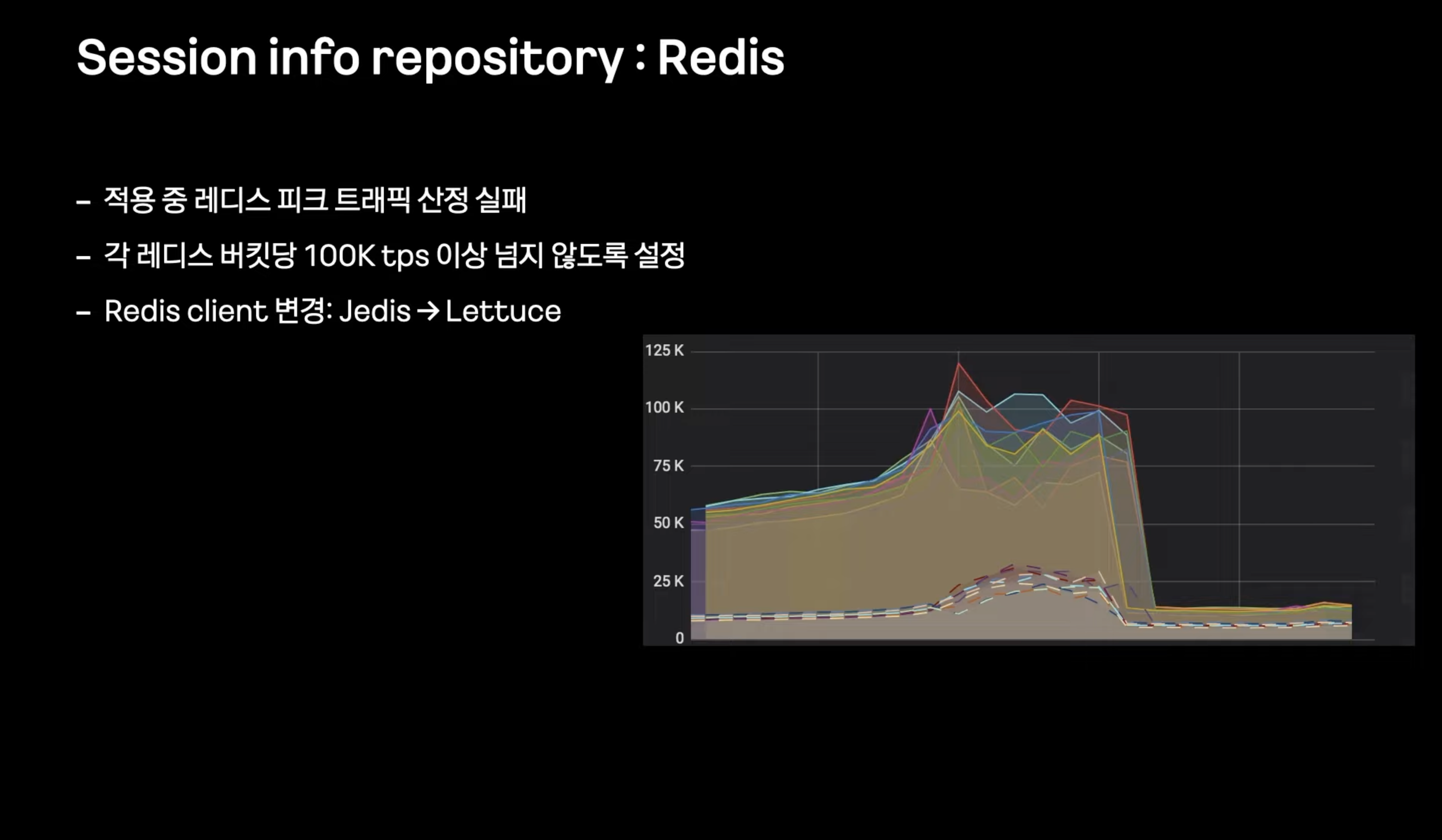
- 실서비스에서 벤치마크 테스트에서는 놓친 유형의 트래픽이 발생
- 레디스 버킷별 트래픽이 권장 한계인 100K tps를 초과해서 지연발생 -> 롤백
-> 실제 시나리오에 맞는 테스트를 추가해서 해결
-> 어플리케이션 자체에서 무의미한 커넥션을 많이 무는 Jedis 대신 Lettuce로 변경
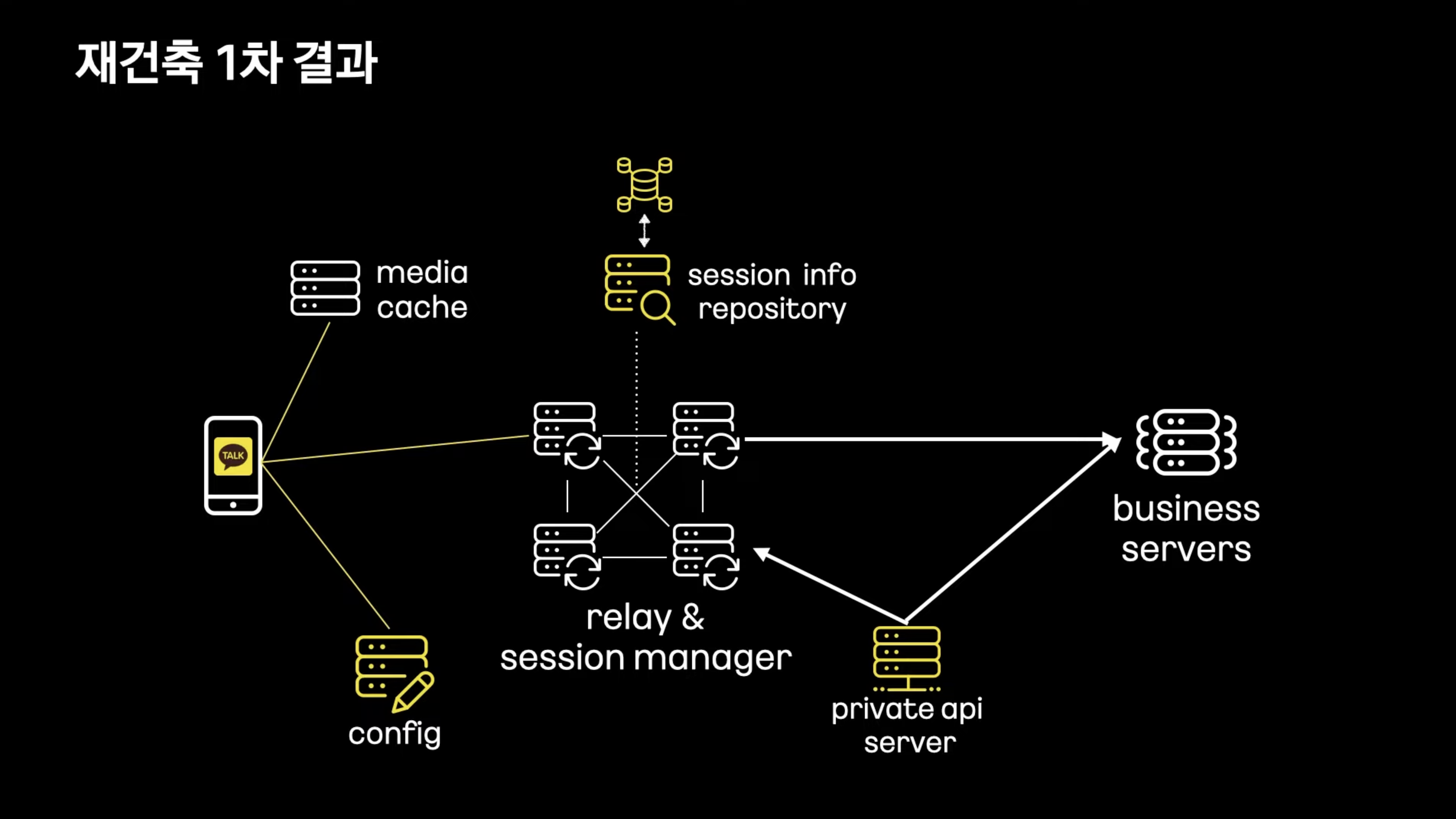
- Config, Session, Papi -> JVM기반 서버로 변경 완료
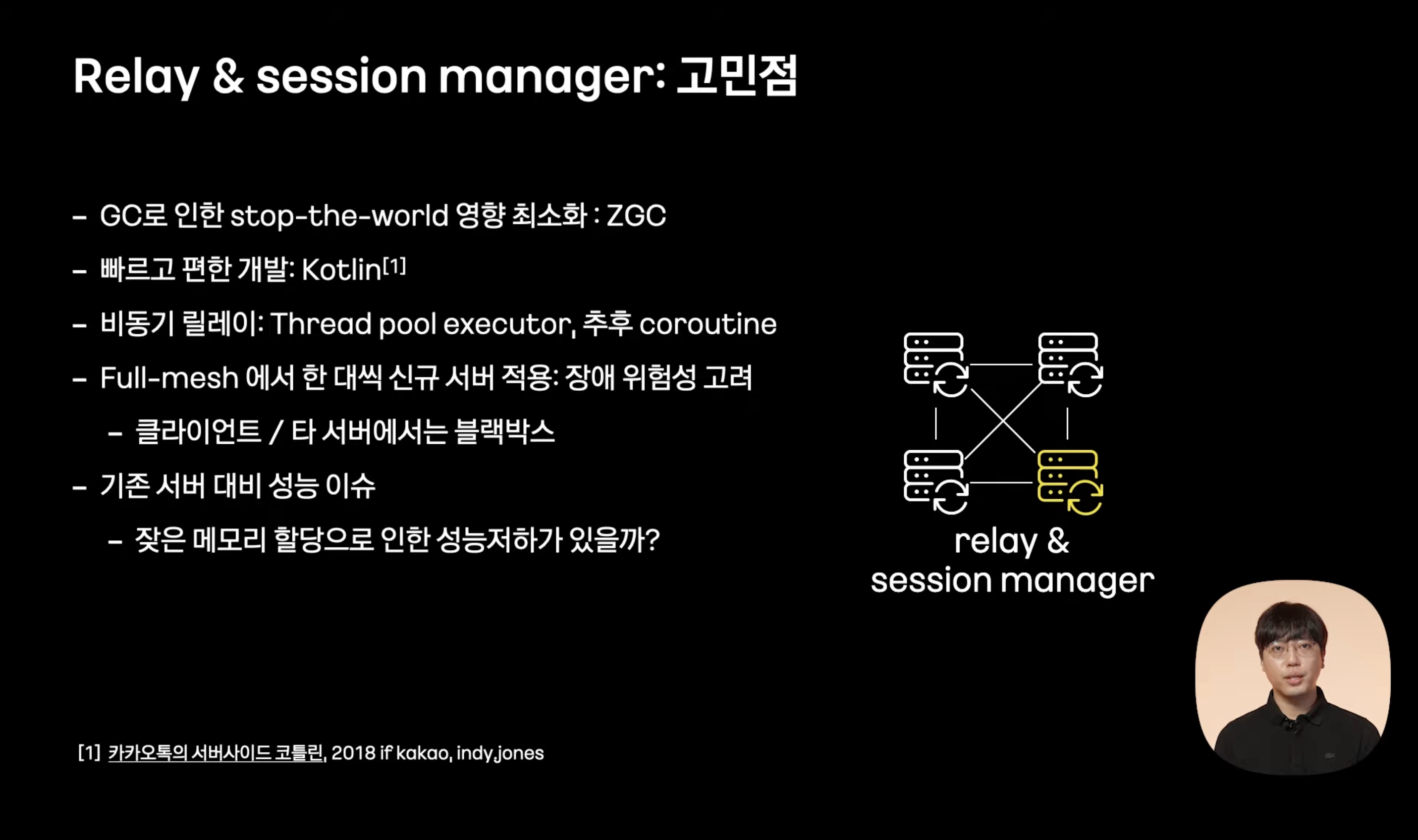
2단계
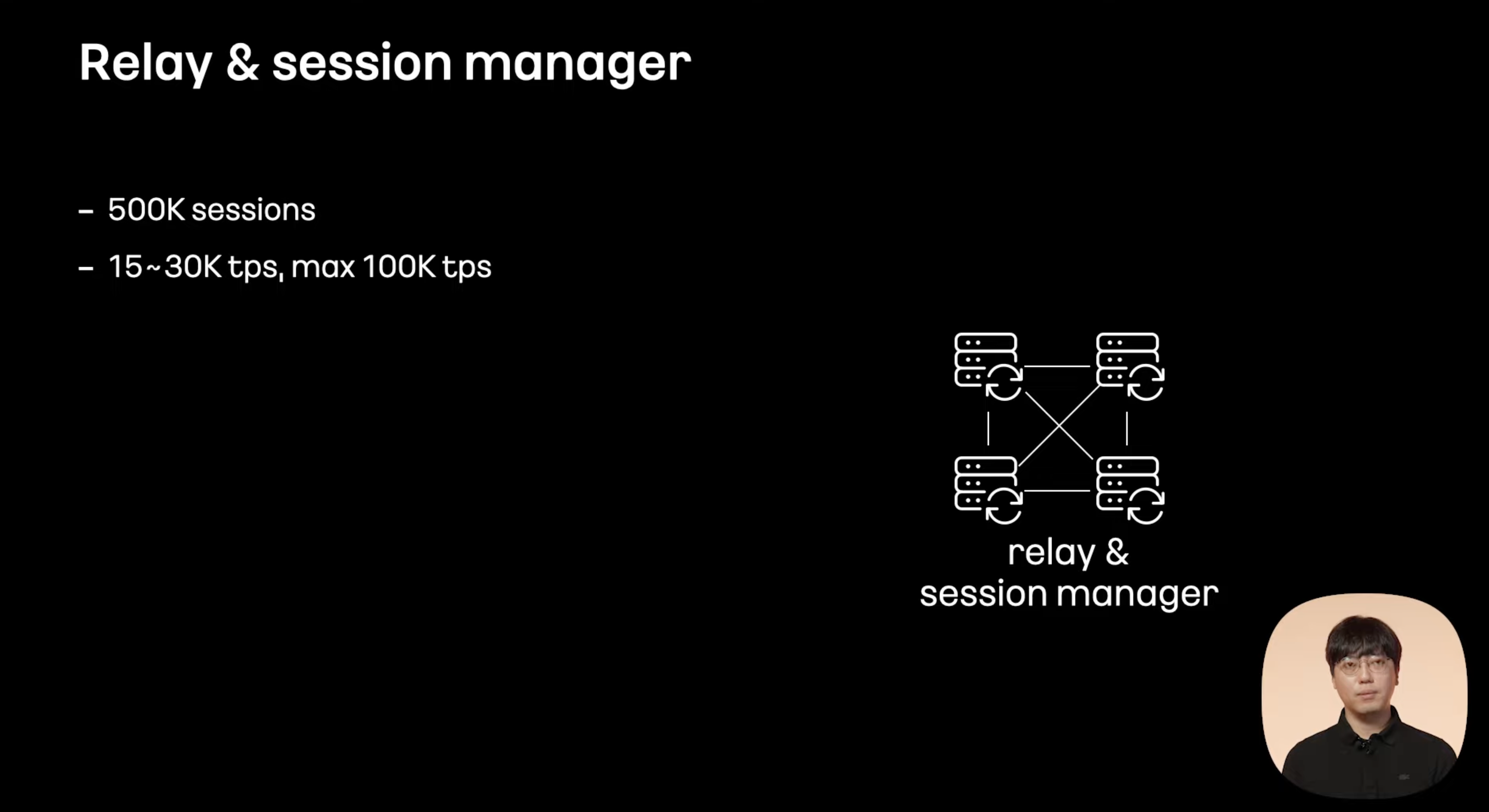
메세지 릴레이와 클라이언트를 관리하는 서버들
Full Mesh
대당 약 50만 세션
최대 100k tps
원활한 릴레이를 위해 빠른 처리시간 요구
코틀린 : 기존 프로젝트 대비 간결, 가독성 높은 코드, 생산성 높은 코드
쓰레드풀 비동기 릴레이 -> 코루틴 활용
타 클라이언트와 full-mesh 상대 서버에서는 해당 모듈이 신규 모듈인지 아닌지 모르는 블랙박스 형태로 -> 한 대씩 순차적으로 적용하며 장애 위험도 낮춤
기존 서버 대비 성능이 잘 나올까?
쓰레드풀 비동기 : 코루틴
- 스레드는 운영체제의 스케줄러에 의해 관리되는 반면 코루틴은 어플리케이션 수준에서 제어되는 루틴
- 스레드는 병렬 처리를 지원하여 여러 개의 스레드가 동시에 병렬적으로 실행될 수 있다. 코루틴은 동시성을 지원하여 여러 개의 코루틴이 동시에 실행될 수 있지만 실제로는 하나의 스레드에서 실행되기 떄문에 병렬 처리를 지원하지는 않는다.
- 스레드는 컨텍스트 스위칭 비용 -> 코루틴은 None
- 코루틴 코드가 한층 간결
Stop the world
- GC가 힙 메모리를 안전하게 정리할 수 있도록 모든 애플리케이션 스레드가 정지되는 현상
ZGC, G1GC 차이에 대해
- 두 가비지 컬렉션의 목적에 대해
- ZGC -> 가장 짧은 일시 중단 시간을 목표로 어플리케이션의 응답 시간을 최소화하자.
- G1GC -> 전체 힙을 균형있게 관리하여 장기기간의 일시 중단을 피하고 힙을 효율적으로 사용하자.

-
CPU 사용량은 (새롭게 세션 오브젝트가 생성될때) JVM 이 높지만 실서버 자원애 비해 낮아 이정도 성능차이는 상관 없다고 판단.
-
프로토콜 처리속도, 메시지 릴레이 시간은 내부 로직 개편으로 성능 개선
-
stop the world G1GC, ZGC간 차이가 있음
-
C++ 서버에서 차지하고있는 메모리르 기준으로 JVM의 힙사이즈를 적용
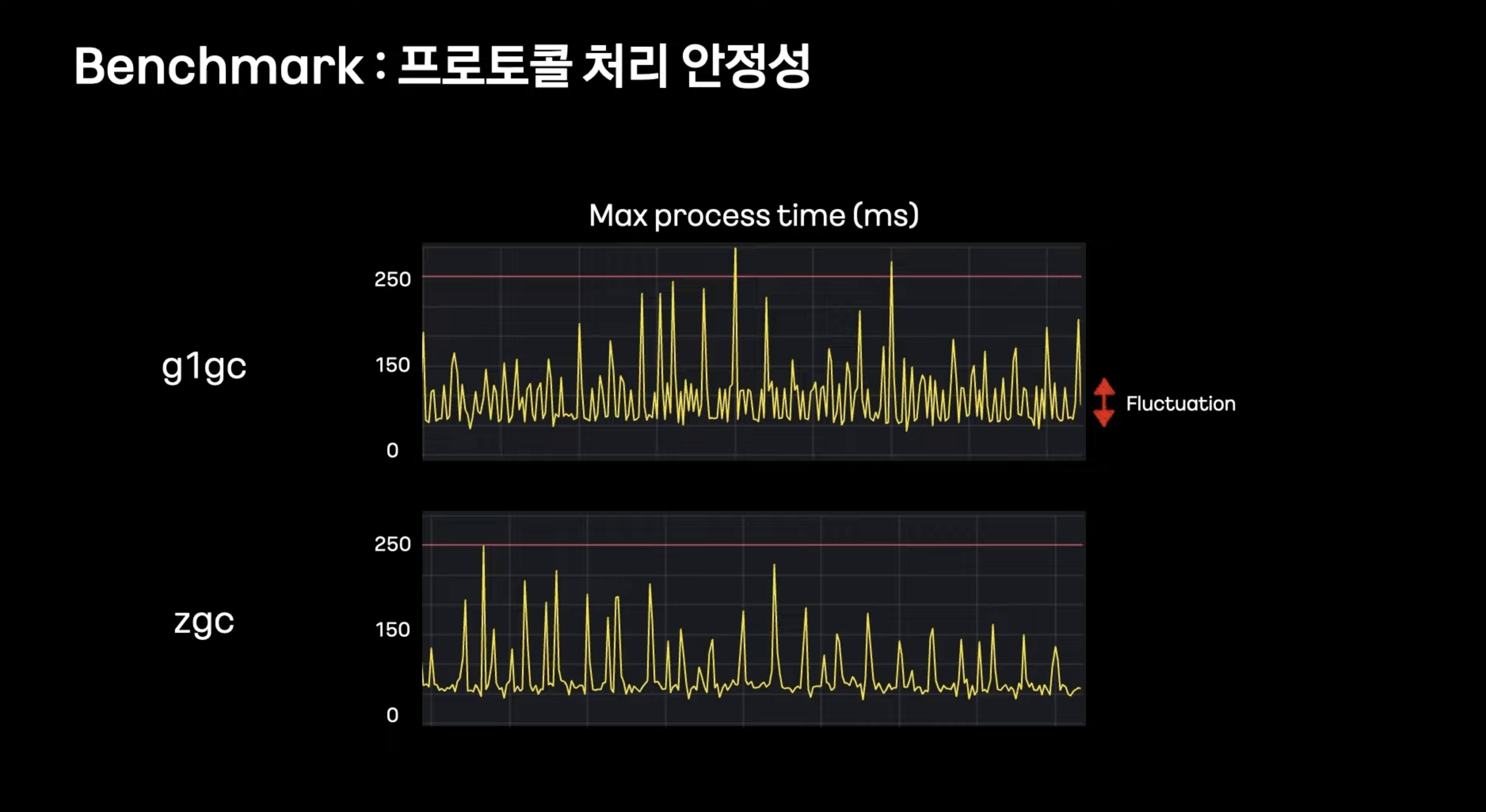
각 GC별 프로토콜 처리속도의 최대값
프로토콜 처리속도 변동 빈도가 ZGC보다 G1GC가 더 높은걸 확인
-> 이 결과가 Maximum pause gc time과 유관할것이라고 예측
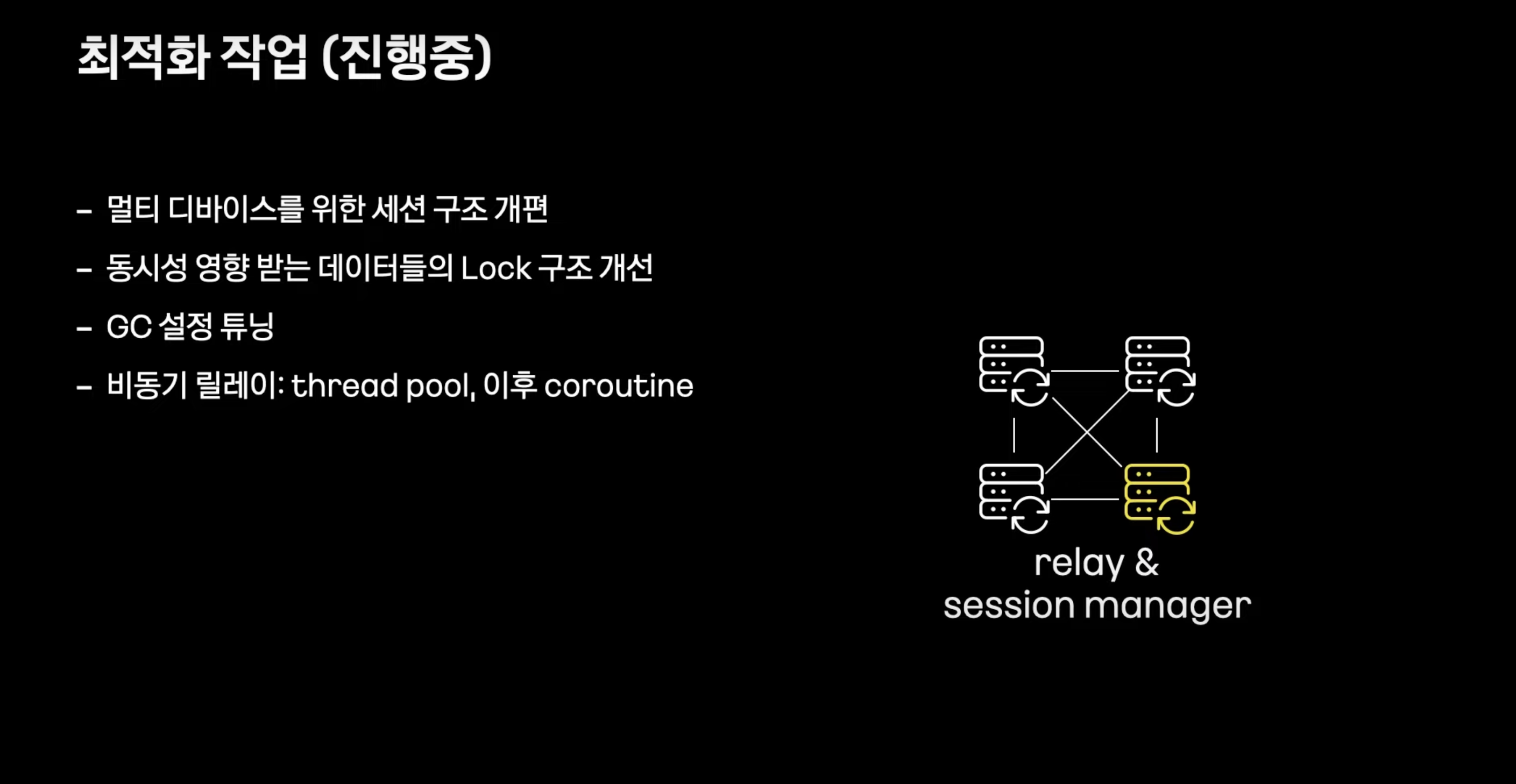
- 멀티디바이스를 위해 서버 내부 세션 클래스 구조 개편, 클라이언트 요청에서 들어오는 데이터 스트림을 필요한 데이터 외엔 파싱하지 않도록 처리
- 스펙에 맞게 LOCK 구조 개선
- 현재는 thread pool(task executor)를 통해 이루어지고 있지만 CPU자원을 줄이기 위해 코루틴 도입 예정


netty

-
계층 분리를 통해 릴레이 서버들간 릴레이 프로토콜을 안정적으로 개선 가능 -> 패킷사이즈 제한과 같은 커스텀 프로토콜로 인한 제약이 많았고 내부 통신 프로토콜들을 전부 변환하기에는 장애 위험성이 너무 높았다. -> 사람 많은 방의 릴레이나 멀티 디바이스 확장을 유연하게 적용할 예정
-
미디어 캐시 개선 고민중
