
2개월 LXP 프로젝트를 마치고, 이어서 3개월 LXP 프로젝트를 시작하게 되었습니다.
(시간이 너무 빠르네요,,)
2개월 LXP vs. 3개월 LXP
2개월 LXP와 비교했을 때, 이번 3개월 LXP에서 가장 크게 달라진 점은 아래와 같습니다.
- 프론트엔드와의 협업
- 기존 로드맵 형식과는 다른 LXP 기획
- 프로젝트 운영 방식 및 코드 구조
제가 포텐업에서 가장 매력적으로 느꼈던 것 중 하나가 바로 "프론트엔드와의 협업" 이었고, 이번 프로젝트에서 그 경험을 실제로 해볼 수 있었습니다.
이번 글에서는 협업 과정에서 느낀 점과, 기능 개발을 진행하며 마주했던 고민들, 그리고 새롭게 정리된 생각들을 중심으로 회고해보려 합니다.
들어가기 전
이전 회고에서의 목표가 무엇이었는지 확인해보겠습니다.
생각보다 이전 프로젝트에서 목표를 많이 잡았더라구요,,🥹
- 어그리게이트 경계 잡는 연습 더 해보기
- 조회 모델 설계 연습 (DTO / Projection / Read Model)
- 단순 DTO를 넘어서, “이 화면을 위한 Read Model은 무엇인가?”를 먼저 고민하고 구성해 보기
- 이해가 막히면 설계 단계에서 질문하기
- 작은 단위로 자주 PR 보내기
- 도메인 시나리오를 설명하는 테스트를 꾸준히 쌓아가기
이제 위 목표들을 중심으로,
이번 프로젝트에서 어떤 시도를 했고 어떤 고민을 거쳤는지 차근차근 정리해보겠습니다.
'gorogoro' 프로젝트
1, 2개월 차 프로젝트와 달리 이번 프로젝트에서는 프론트엔드와 협업을 진행하며
매번 새로운 프로젝트를 만드는 방식이 아니라, 하나의 서비스를 기준으로 기능을 점진적으로 확장해 나가는 방식으로 개발을 진행했습니다.
개발을 시작하기 전 프론트엔드 분들과 논의하여 1차 MVP로 가져갈 기능들을 먼저 정의했고,
저는 그중 Cart(장바구니) 도메인을 맡아 구현하게 되었습니다.
왜 헥사고날 아키텍처였나?
저희 프로젝트는 이번에 헥사고날 아키텍처를 사용하게 되었습니다.
헥사고날 아키텍처를 선택한 데에는 “이번엔 구조를 끝까지 가져가 보고 싶다”는 목표와 함께,
처음부터 도메인을 보호하는 구조를 전제로 개발을 시작해보고 싶다는 의도가 있었습니다.
이전 프로젝트들에서는 구조를 의식하긴 했지만,
개발 속도나 편의성을 이유로 도메인과 인프라가 점점 섞이는 경험을 했습니다.
실제로 적용해보니, 기능 하나를 추가할 때마다
“이 로직을 어디에 두는 게 맞을까?”에서 계속 멈추게 되었고,
그제서야 구조를 이해했다고 착각하고 있었다는 걸 깨달았습니다.
그 과정에서 도메인 로직을 작성할 때 DB나 프레임워크를 거의 의식하지 않게 되었고,
“이 코드는 어디에 있어야 하는가?”를 자연스럽게 기준으로 삼게 되었습니다.
이 과정 자체가 설계 연습이 되었고,
이전보다 구조에 대해 훨씬 많은 고민을 하게 만든 선택이었다고 느낍니다.
패키지 구조
모든 세부 구현을 나열하기보다는,
제가 가장 많이 고민했던 지점이 드러나는 구조 위주로 핵심 패키지와 클래스만 정리해보았습니다.
├── cart
│ ├── application // 유스케이스 조합 및 흐름 제어
│ │ ├── port
│ │ │ ├── in // 서비스가 제공하는 기능 명세 (UseCase) : 유일한 진입 인터페이스
│ │ │ └── out // 외부 시스템이나 인프라에 대한 의존성 계약
│ │ └── service
│ │ ├── CartCommandService.java // 생성, 수정, 삭제 흐름 담당
│ │ └── CartQueryService.java // 조회 흐름 담당
│ ├── common // 공통으로 사용하는 기술 요소 ex) 공통 예외, 설정 등
│ ├── domain // 핵심 비즈니스 규칙 정의
│ │ ├── model
│ │ │ └── CartItem.java
│ │ └── repository // 저장소 계약
│ │ └── CartRepository.java
│ ├── infrastructure
│ │ ├── adapter // port.out의 구현체
│ │ └── persistence // JPA 기반 저장소 구현
│ │ ├── CartRepositoryAdapter.java
│ │ └── jpa
│ │ └── CartJpaRepository.java
│ └── presentation // 외부 요청 진입점
│ └── web
│ └── CartController.java
└── GorogoroCartApplication.java
덕분에 이후 기능을 추가할 때 각 로직의 책임과 위치를 비교적 명확한 기준으로 판단할 수 있었습니다.
흐름도
아래는 요청 흐름을 단순화한 다이어그램입니다.
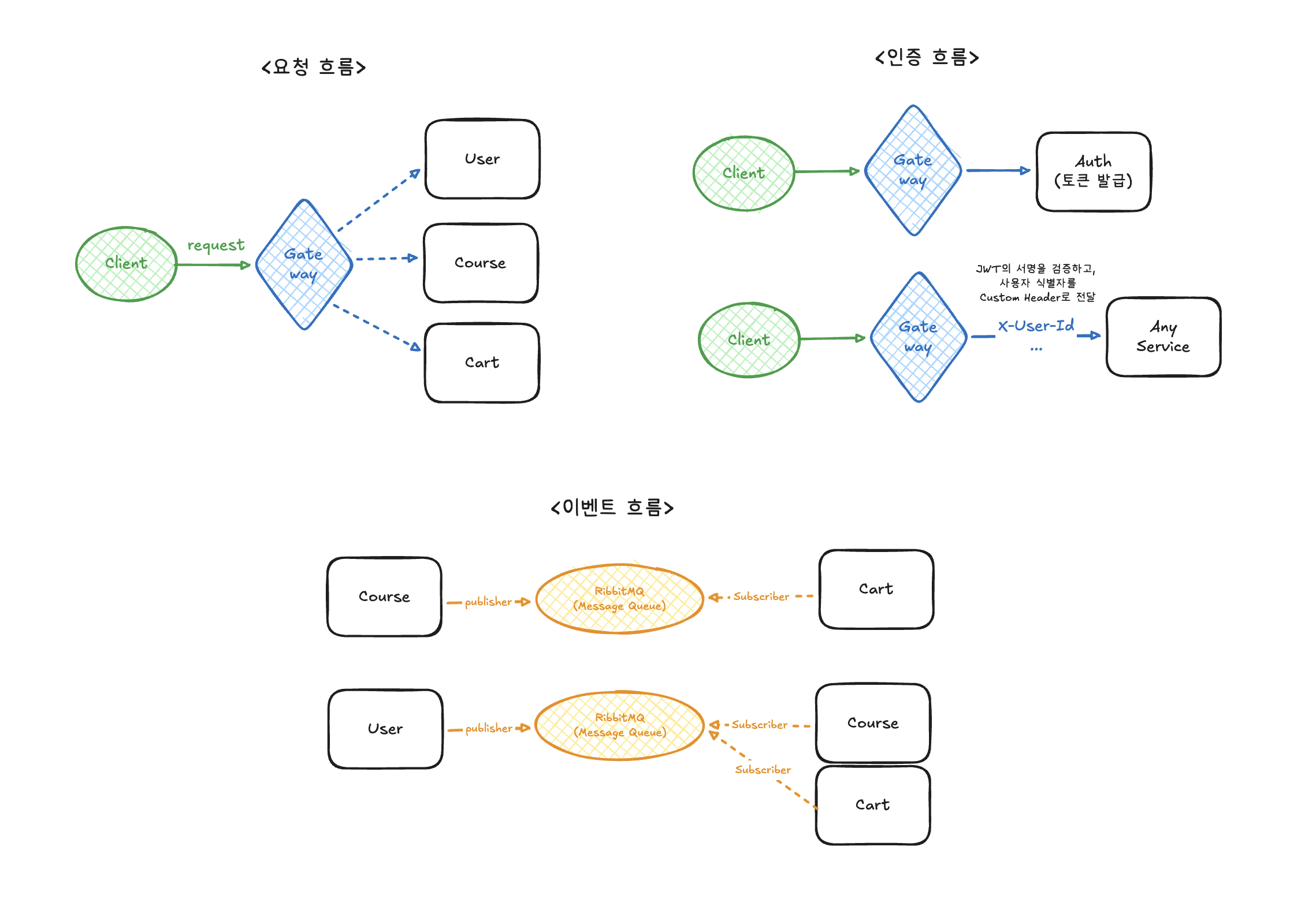
요청 흐름, 인증 흐름, 이벤트 흐름을 분리하여 설계했습니다.
- Gateway는 인증 판단과 라우팅만 담당하고,
- Auth는 토큰 발급,
- User는 사용자 상태의 단일 진실(Single Source of Truth)
을 가지도록 역할을 나누었습니다. 다른 도메인은 이벤트를 통해 상태 변경을 반영하도록 설계했습니다.
이렇게 나누고 나니, Cart 도메인에서는 “인증을 어떻게 처리할지”를 거의 고민하지 않아도 되어 도메인 로직에 더 집중할 수 있었습니다.
프로젝트 진행 과정
거대한 이벤트 스토밍
이전까지는 이벤트 스토밍을 한 팀 단위로 진행하였지만, 항상 같은 도메인으로 이벤트 스토밍을 진행하다 보니 다른 관점으로 보는 것에 어려움이 있다고 생각했습니다.
그래서 저희는 프론트엔드와의 협업을 진행하기 전, 백엔드 두 팀의 협업 이벤트 스토밍을 진행하였습니다.
확실히 혼자 생각하고 진행할 때보다 모두가 생각하는 이벤트, 정책이 다르다는 것을 인지하고 이를 통해 생각하지 못했던 이벤트나 정책들이 떠오르는 경험을 할 수 있었습니다.
두근.두근 FE와의 만남
개발을 시작하기 전, 백엔드 팀에서 진행했던 이벤트 스토밍 결과를 공유하며 전체 흐름과 도메인 개념을 먼저 맞추는 시간을 가졌습니다.
이 과정에서 단순히 기능 목록을 전달하는 것이 아니라,
“이 기능은 어떤 상황에서 등장했고, 어떤 상태 변화를 만들고 싶은지”를 중심으로 설명했습니다.
그러다보니 자연스럽게 유비쿼터스 언어를 정리할 수 있었고, FE와 BE가 같은 단어를 같은 의미로 쓸 수 있었습니다.
저희의 협업 방식은 문서 중심이었습니다.
API 명세, 응답 예시, 상태 설명까지 최대한 상세하게 정리했고, 이 정도면 충분히 오해 없이 개발할 수 있겠다고 생각이 들었습니다.
하지만 실제로 API를 붙이는 단계에서 작은 이슈가 있었습니다.
명세가 잘못된 것은 아니었지만, 같은 응답을 두고 FE와 BE가 머릿속으로 그린 화면이 달랐습니다.
문서가 틀렸다기보다는, 문서가 모든 맥락을 대신해주지는 못한다는 걸 체감했습니다.
화면과 직접 맞닿는 API일수록 “이 응답을 어디에 쓰는지”, “이 필드가 바뀌면 화면에서 무엇이 달라지는지”까지 함께 이야기해야 한다는 것을 배울 수 있었습니다.
문서는 협업의 출발점이지, 끝이 아니라는 것을 깨달았습니다.
그 이후로는 API 하나를 정의하더라도 문서 + 짧은 대화 + 화면 기준 설명을 함께 가져가려 노력했고, 더 효율적인 협업을 할 수 있게 되었습니다.
BE 간의 협업 과정
각 도메인을 완전히 분리된 레포지토리로 관리하면서 의존성을 낮출 수 있다는 장점이 있었습니다.
한 도메인의 변경이 다른 도메인에 직접적인 영향을 주지 않는 구조는 심리적인 안정감도 주었습니다.
하지만, 이 구조가 항상 편하기만 한 건 아니었습니다.
이벤트 처리나 다른 도메인의 상태를 참고해야 하는 상황에서는
전반적인 코드를 이해하는 데 시간이 조금 필요하다는 점도 있었습니다.
물론 코드 리뷰를 진행하면서 점점 다른 도메인에 대한 이해도 높아졌고, 협업 과정에서 다른 팀원분들이 적극적으로 리뷰를 해줘서 좋은 협업 분위기를 느낄 수 있었습니다.
초반에는 공통 컨벤션을 충분히 맞추지 않은 상태에서 개발이 진행되어 각 도메인마다 응답 포맷이 달랐었고, 프론트엔드 분들에게 혼란을 주는 일도 있었습니다.
이 경험을 통해, 기술적으로 분리된 구조일수록 초기 단계에서의 문서화와 컨벤션 합의가 훨씬 중요하다는 것을 체감할 수 있었습니다.
고민했던 부분
Domain Model vs. JPA Entity Model
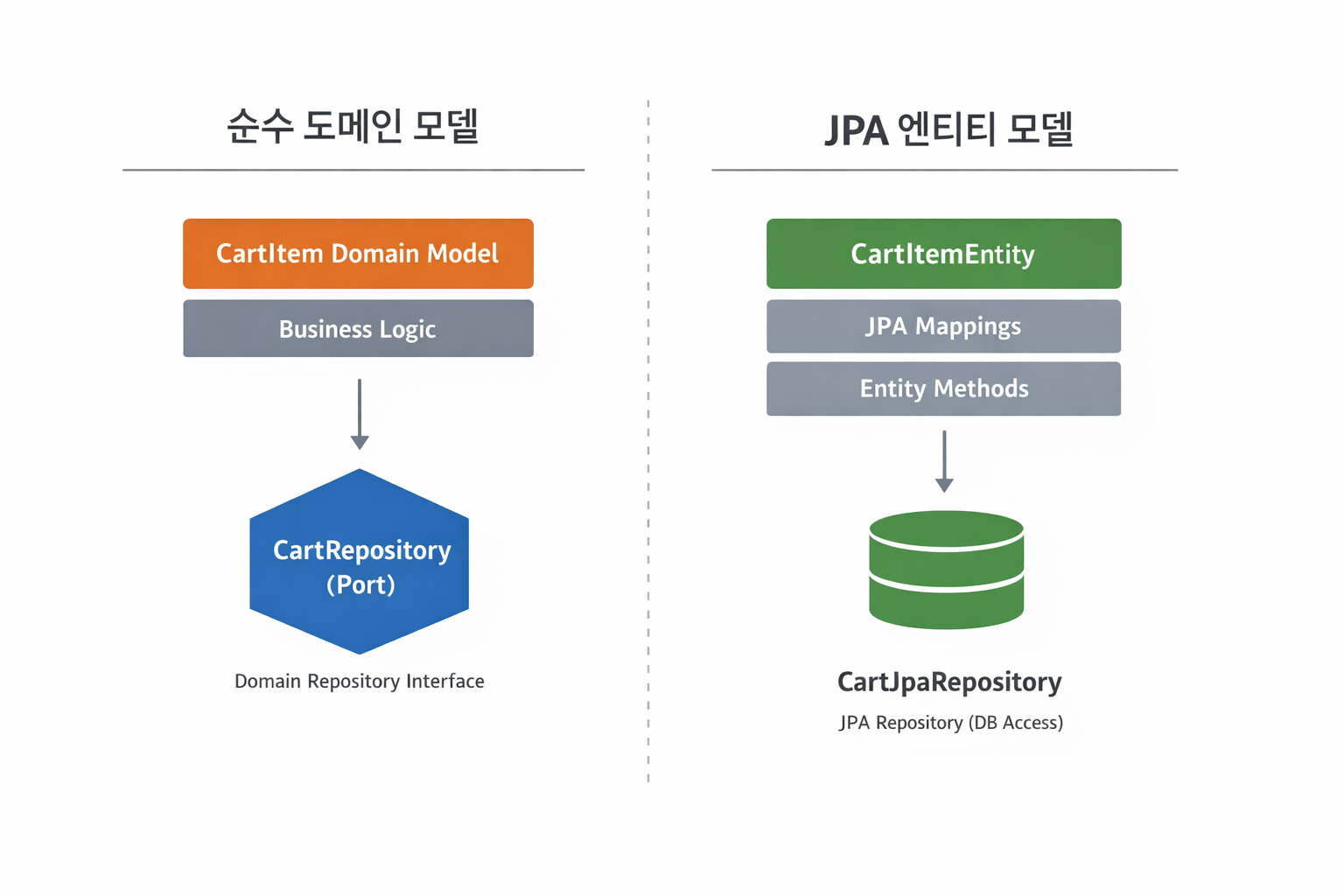
장바구니 도메인을 설계하면서 처음에는 도메인 모델과 JPA 엔티티 모델을 분리하여 관리하는 방식을 선택했습니다.
헥사고날 아키텍처를 적용한 만큼, 도메인이 인프라에 의존하지 않는 구조를 끝까지 가져가 보고 싶었기 때문입니다.
레이어드 구조였다면 JPA 엔티티를 그대로 도메인처럼 사용하는 선택도 가능했겠지만, 이번 프로젝트에서는 “도메인이 어떤 책임을 가져야 하는가”를 더 명확히 드러내고 싶었습니다.
그래서 저장 방식이나 ORM 제약보다, 도메인 행위와 규칙을 먼저 정의하는 방향으로 접근했습니다.
하지만 구현을 진행하면서, 이 선택이 현재 장바구니 도메인의 성격과는 맞지 않을 수 있지 않을까에 대한 고민이 들었습니다.
Cart 도메인에는 할인 정책이나 복잡한 비즈니스 규칙처럼 빈번하게 변경되거나 독립적으로 보호해야 할 정책이 존재하지 않았고, 대부분의 로직이 CRUD 성격의 단순한 상태 변경에 가까웠습니다.
그럼에도 도메인 모델을 기준으로 설계를 유지하다 보니,
아래와 같이 간단한 기능조차 조회 → 판단 → 변경의 흐름을 매번 명시적으로 풀어내야 했고,
그 과정에서 코드 양과 수정 포인트가 빠르게 늘어났습니다.
그래서 CartItem을 순수 도메인 모델로 유지하기보다는, JPA 엔티티 기반으로 사용하는 방향으로 설계를 변경하였습니다.
이 상황에서 도메인 분리는 설계를 보호하기보다는, 오히려 흐름을 복잡하게 만드는 요인이 될 수 있다고 느꼈습니다.
변경 전
@Override
public void addCourse(AddCourseToCartCommand command) {
Long userId = command.userId();
List<CartItem> baselineItems = loadBaselineItems(userId);
Cart targetCart = buildTargetCart(userId, baselineItems);
targetCart.addCourse(command.courseId());
cartRepository.save(targetCart, baselineItems);
}
@Override
public void clearCart(ClearCartCommand command) {
Long userId = command.userId();
// 불러오기
List<CartItem> baselineItems = loadBaselineItems(userId);
// 판단(비교)하기
Cart targetCart = buildTargetCart(userId, baselineItems);
targetCart.clear();
// 저장하기
cartRepository.save(targetCart, baselineItems);
}변경 후
@Override
public void addCourse(AddCourseToCartCommand command) {
...
CartItem newItem = CartItem.of(command.userId(),command.courseId(), Instant.now());
cartRepository.save(newItem);
}
@Override
public void clearCart(ClearCartCommand command) {
cartRepository.deleteAllByUserId(command.userId());
}도메인 규칙이 복잡하고 자주 변경된다면 나누는 것이 좋다. 예를 들어 이커머스의 각종 할인 정책(쿠폰, 마일리지 등)은 복잡하고 변경이 잦다. 이런 도메인은 가능한 한 순수하게 유지하여, 테스트 가능성(testability)을 극대화하고 리팩터링을 통해 쉽게 구조를 변경할 수 있도록 해야 한다.
이런 고민 과정을 통해 도메인 분리는 ‘무조건 적용해야 할 원칙’이 아니라,
도메인의 복잡도와 변경 가능성, 그리고 팀의 설계 이해도에 따라 선택되어야 한다는 기준을 갖게 되었습니다.
API 호출 동기? 비동기?
장바구니 구현 과정에서 또 하나 고민했던 지점은 강의 정보 조회를 어떤 방식으로 처리할 것인가였습니다.
장바구니에는 강의 ID만 저장되어 있었고,
화면에 필요한 강의 정보(제목, 썸네일, 가격 등)는 Course 도메인에서 가져와야 했습니다.
이때 두 가지 선택지가 있었습니다.
- 장바구니에 필요한 강의 정보를 저장하고, 비동기 이벤트로 갱신할 것인가
- 요청 시점마다 Course 도메인에 동기 API를 호출할 것인가
이 고민은 호출 방식 자체보다는 “장바구니가 강의 정보를 소유해야 하는가”였습니다.
비동기 방식이라면 호출 비용을 줄이고 조회 성능을 개선할 수 있었지만,
장바구니는 사용자가 담은 항목을 관리하는 도메인이지
강의의 상태나 정보를 책임지는 도메인은 아니라고 판단했습니다.
강의 정보의 최신성 역시 Course 도메인의 책임에 가깝다고 보았고,
장바구니가 이를 내부에 저장하는 순간 도메인 간 책임 경계가 흐려질 수 있다고 느꼈습니다.
그래서 강의 정보는 Course 도메인이 소유하고,
장바구니는 조회 시점에 동기 API로 참조하는 방식을 선택했습니다.
이 선택은 호출 횟수나 성능 측면에서는 부담이 될 수 있지만, 데이터의 최신성을 보장할 수 있고
각 도메인이 무엇을 책임지는지가 명확해진다는 장점이 있었습니다.
이번 고민을 통해 비동기 처리가 항상 더 나은 해법은 아니며,
도메인이 무엇을 ‘기억하느냐’보다 무엇을 ‘소유하느냐’가 더 중요하다는 기준을 세울 수 있었습니다.
마무리하며,,
글을 마무리하기 전에, 프로젝트 시작 전 세웠던 목표들을 다시 한 번 꺼내 봤습니다.
1. 어그리게이트 경계 잡는 연습 더 해보기
Cart 도메인을 단일 책임으로 가져가며, “이 기능이 정말 Cart의 책임인가?”를 계속 질문할 수 있었습니다. 완벽하다고 말하긴 어렵지만 이전보다 경계를 의식하며 설계했다는 점에서 의미있었습니다.
2. 조회 모델 설계 연습 (DTO / Projection / Read Model)
조회 흐름을 Command와 분리하고, 화면 단위로 필요한 데이터가 무엇인지 고민하는 경험을 할 수 있었습니다. 하지만, Projection과 Read Model을 더 적극적으로 활용하지 못한 아쉬움은 있습니다.
3. “이 화면을 위한 Read Model은 무엇인가?”를 먼저 고민하기
FE 협업 과정에서 이 질문이 자연스럽게 등장했고, API를 기능 기준이 아니라 화면 기준으로 바라보게 되었습니다.
4. 이해가 막히면 설계 단계에서 질문하기
이벤트 스토밍, 협업 미팅, 코드 리뷰 과정에서 이전보다 훨씬 빠르게 질문하고 의견을 나눌 수 있었습니다.
5. 작은 단위로 자주 PR 보내기
도메인 단위로 쪼개서 PR을 보내는 습관을 유지하려 노력했고, 리뷰를 통해 설계에 대한 피드백을 빠르게 받을 수 있었습니다.
하지만, "자주"는 아니었던 것 같습니다. 한 기능을 작업하면서 구현 방식이 틀린 방향은 아닌지에 대한 걱정에 재확인하는 과정에서 구현 시간을 많이 잡아먹었던 것 같습니다.
6. 도메인 시나리오를 설명하는 테스트 쌓기
일부 시도는 했지만, “설명을 위한 테스트”까지는 아직 충분히 쌓지 못했다는 아쉬움이 있습니다.
전체적으로 보면, 모든 목표를 완벽하게 달성했다기보다는 어디까지 고민해봤고, 어디가 아직 부족한지 명확해졌다는 점이 이번 프로젝트를 진행하면서 가장 크게 배운 점이라고 생각합니다.
다음 프로젝트를 위한 목표
- 헥사고날 구조를 ‘지키는 것’보다 ‘언제 느슨하게 가져갈지 판단하는 연습’ 해보기
- Projection / Read Model을 실제로 활용해 보는 경험 쌓기
- API 설계 시 문서 중심에서 한 단계 더 나아가, 늘 더 나은 협업 방식 고민하기
- 도메인 시나리오를 설명하는 테스트를 “나를 위한 테스트”가 아니라 “동료에게 설명할 수 있는 테스트”로 작성해보기
설계도 협업도,
결국 정답을 맞히는 일이 아니라
계속 질문하고 조정해 나가는 과정이라는 걸 배울 수 있었습니다.
달라도 괜찮았고, 그래서 더 많이 배울 수 있었다.
긴 글 읽어주셔서 감사합니다 ☺️
참고
