[AI Math] 통계학
통계적 모델링은 적절한 가정 위에서 확률분포를 추정하는 것이 목표이다.
유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확히 알아내는 것이 불가능하므로, 근사적으로 확률분포를 추정해야 한다. (예측. 예측모형의 목적은 분포를 정확히 맞추는게 아니라, 데이터와 추정방법의 불확실성을 고려하여 위험도를 최소화하는 것이다.)
모수적 방법론(parametric)
데이터가 특정 확률분포를 따른다고 선험적으로(a priori) 가정한 후 그 분포를 결정하는 모수(parameter)를 추정하는 방법
비모수 방법론(nonparametric)
특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌는 방법
비모수 방법론은 모수가 없는게 아니다!! 이름 보고 착각하지 말기
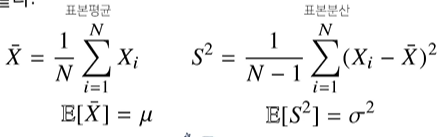
표본분산 구할 때 N-1로 나누는 이유는 unbiased 추정량을 구하기 위해서이다. (뭔소리?????????)
표본분포 Sample Distribution
표집분포 Sampling Distribution
통계량(표본평균, 표본분산)의 확률분포.
표본평균의 표집분포는 N이 커질수록 정규분포를 따른다.
최대가능도
Maximum likelihood estimation
가장 가능성이 높은 모수를 추정하는 방법.
데이터가 주어져있는 상황에서 모수 theta를 따르는 분포가 x를 관찰할 가능성
but 확률로 해석하면 안댐!
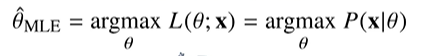
효석님이 발표하신 자료 참고하기 (구글드라이브)

튼튼