[DL] CV overview
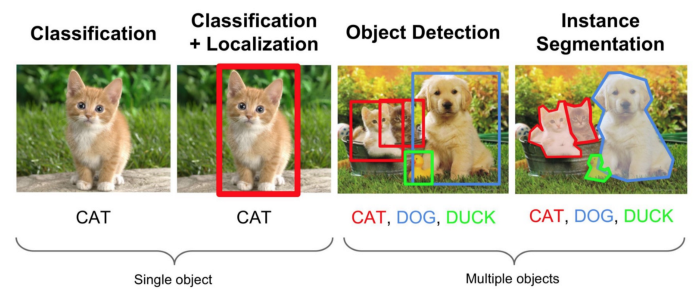
Semantic Segmentation
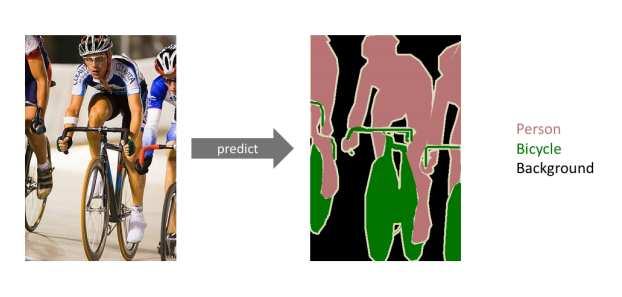
사진을 이해하는 것.
사진에 있는 모든 픽셀을 미리 지정된 개수의 class로 분류하는 것.
FCN (Fully Convolutional Network)
Semantic segmentation의 SOTA와 같은, 엄청난 파장을 일으켰던 모델이라고 함!
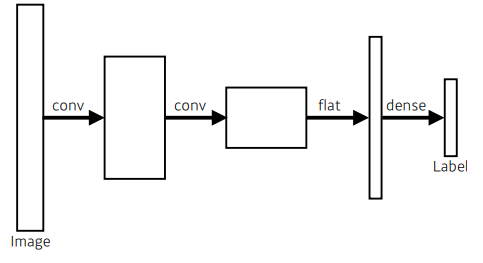
그냥 CNN이 아래와 같았다면,
FCN은 다음과 같다.
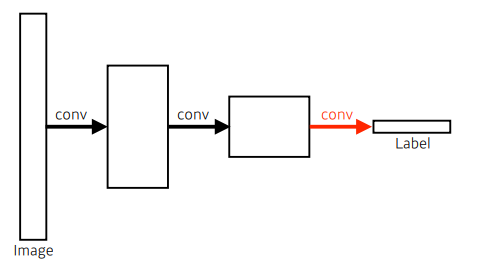
Fully connected layer (=Dense Layer)를 없앤 모습이다.
FCN은 VGG16의 마지막 레이어인 FC 레이어를 1x1 convolution layer로 바꾼 모델이다.
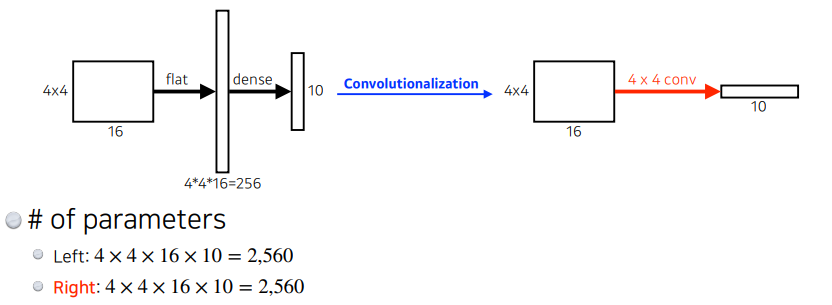
dense layer를 없애는 과정을 convolutionalization (말하다 숨찰듯;;) 이라고 한다.
근데 파라미터 개수도 다를게 없는데 왜 할까?
그 이유는, 마지막에 FC 레이어를 거치고 나면 위치 정보가 사라지는 문제가 있기 때문이라고 한다.
모델을 거치고 나면 낮은 해상도의 Class Presence Heat Map이 생성된다.
우리는 원래 input image에다가 "어디에 뭐가 있어요"를 보여줘야 하기 때문에, 이 heat map을 UPsampling해줘야 한다.
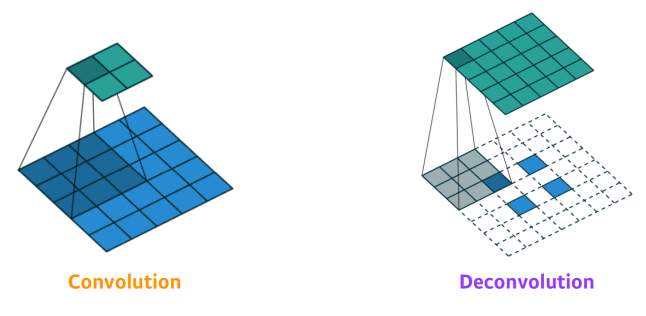
Upsampling
padding을 많이 주고 Convolution 연산을 진행하면 된다.
A.K.A Deconv
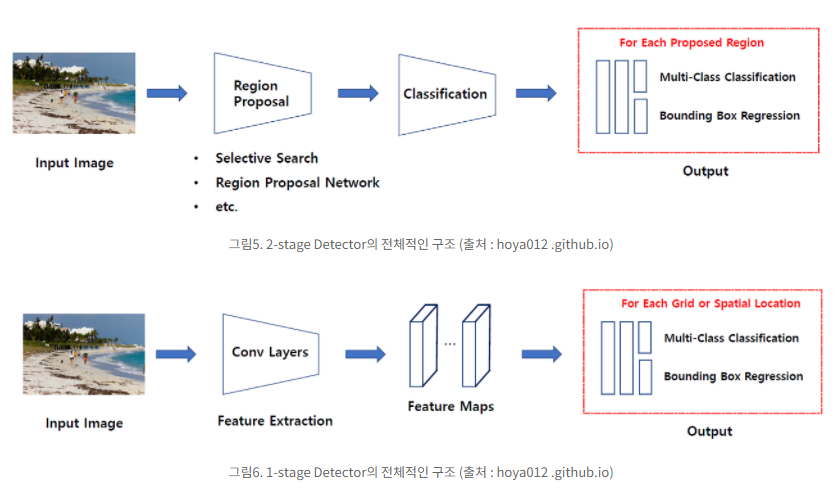
Object Detection
여러 물체에 대해 어떤 물체인지를 분류하는 Classificatin 문제와,
그 물체가 어디에 있는지 위치 정보를 나타내는 Localization 문제를 둘 다 해내야 하는 분야
지금까지 발표된 논문들을 보면, 위 두 문제를 동시에하는 모델도 있고, 순차적으로하는 모델도 있다.
R-CNN
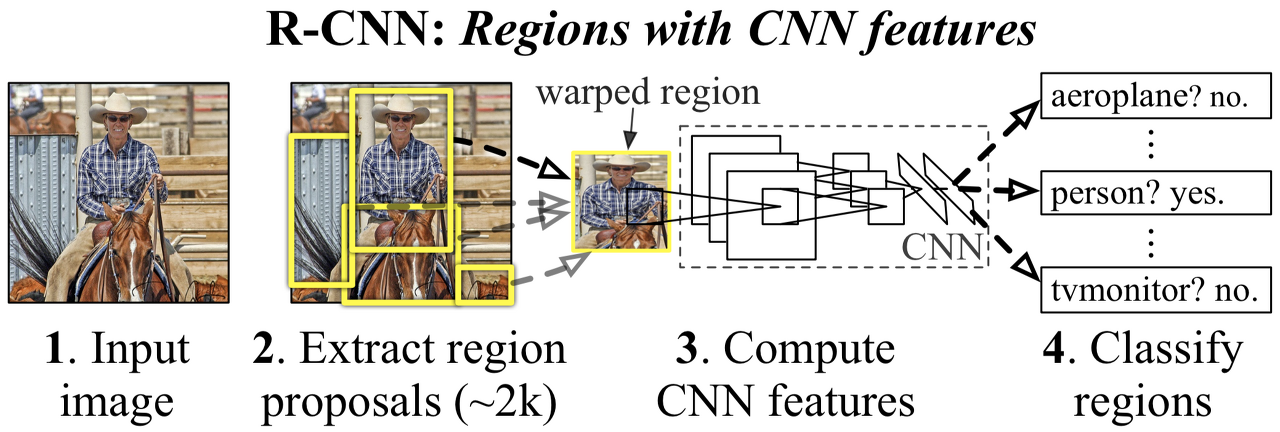
1. 이미지를 input으로 집어넣는다.
2. 2K개의 Bounding Box를 Selective Search 알고리즘을 통해 추출하고, 크롭한다.
3. 크롭한 이미지들을 모델에 넣기 위해 같은 사이즈로 Warping한다.
4. 2K개의 Warping된 이미지를 각각 AlexNet 모델에 넣는다.
5. Linear SVM을 이용해 Classification을 진행한다.
Selective Search?
객체와 주변의 색감, 질감, Enclosed 여부를 파악하는 등 다양한 전략으로 물체의 위치를 파악한다.
Bounding Box를 무작위로 많이 생성하고, 이들을 merge하면서 물체를 인식한다.
Selective Search 논문
의문점!
Q. 왜 Classifier로 Softmax가 아닌 SVM을 사용했을까?
A. 그냥 SVM을 썼을 때 성능이 더 좋아서...?
단점
Backprop이 안된다.
SPPNet
Spatial Pyramid Pooling in Deep CNN
CNN의 문제점은, 인풋 크기가 고정되어야 한다는 점이다.
앞서 본 모델들은 인풋 크기를 위해 warping, cropping을 진행했는데 이는 이미지 특징을 망가뜨린다.
SPPNet은 Spatial Pyramid Pooling Layer를 추가해서 입력 사이즈 제한을 뛰어넘는다.
자세한 원리는 여기
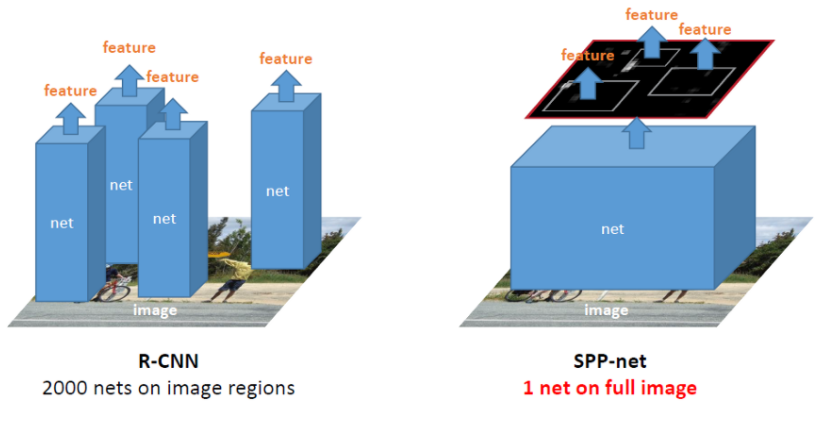
2K개의 바운딩박스를 먼저 만들고 크롭하여 각각을 CNN에 하나하나 다 집어넣은 R-CNN과 달리,
SPPNet에서는 이미지를 먼저 CNN에 넣고 CNN으로 생성된 feature map에서 selective search를 적용하여 feature를 추출한다.
입력 사이즈에 제한이 없고 CNN 수를 줄여서 시간이 단축되었지만, backprop이 안되는건 극복하지 못했다.
Fast R-CNN (추가예정..)
SPPNet의 문제인 "backprop안됨"을 해결!
Region of Interest (ROI) Pooling
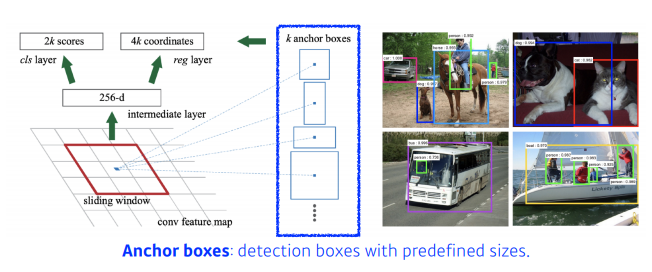
Faster R-CNN
Faster R-CNN = Fast R-CNN + RPN
Region Proposal Network (RPN)
YOLO
대따 빠름.
영상이 들어오면 동시에! 여러 오브젝트의 classification, localization을 진행한다.
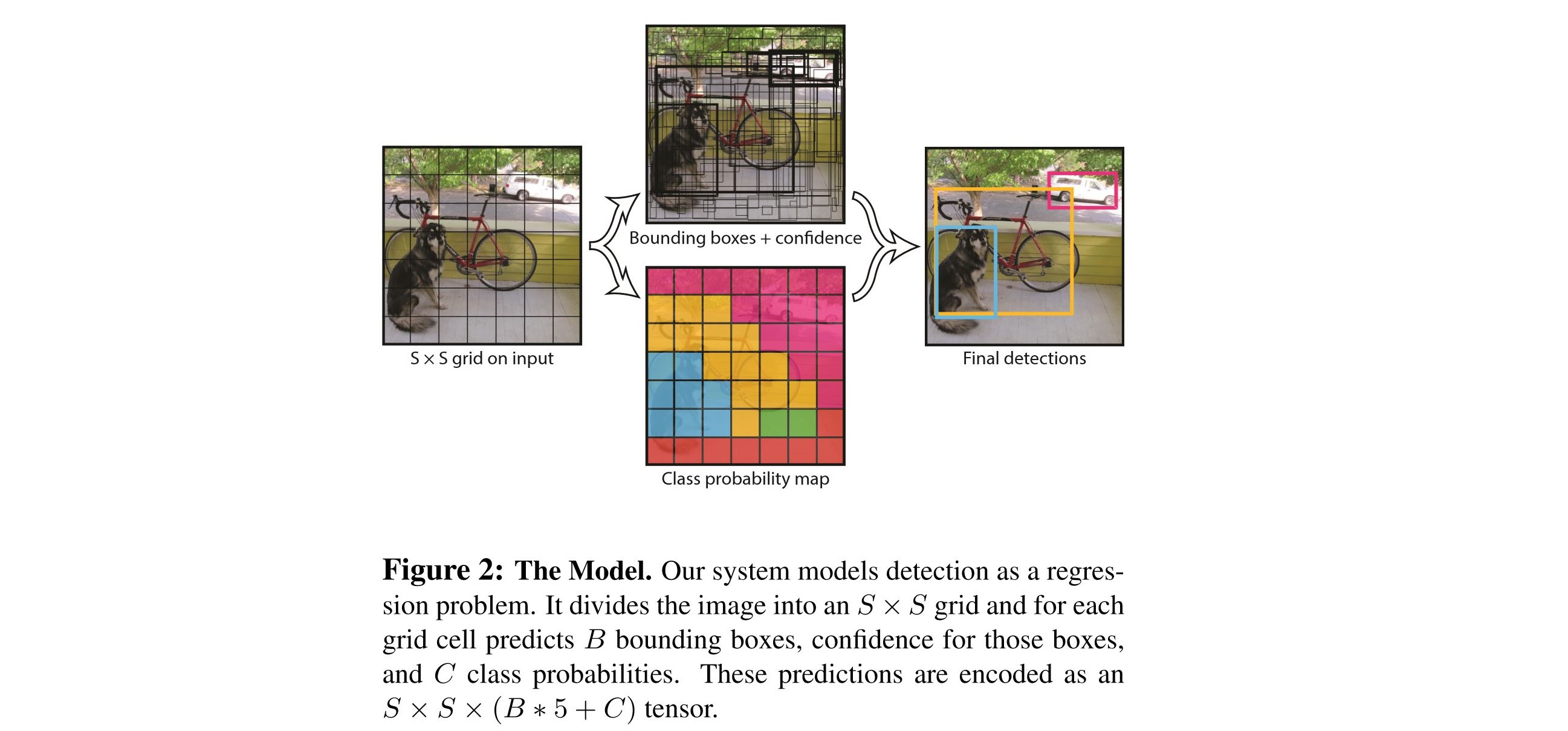
1. 이미지가 들어오면, SxS 그리드로 인풋을 나눈다.
2. 각각의 그리드 셀은 B개의 바운딩 박스와 각 바운딩 박스에 대한 confidence score를 가진다.
3. 각각의 그리드 셀은 C개의 conditional class probability를 갖는다.
4. 각각의 바운딩 박스는 x, y, w, h, confidence로 구성된다. (좌표와 너비, 높이를 알면 박스를 정의할 수 있으니까!)
5. 최종적으로, SxSx(B*5+C) 사이즈의 tensor가 된다.
