[DL] Convolutional Neural Network, 합성곱 신경망
CNN 개요
이미지에서 특정 feature, 즉 특성을 뽑는 연산이다.
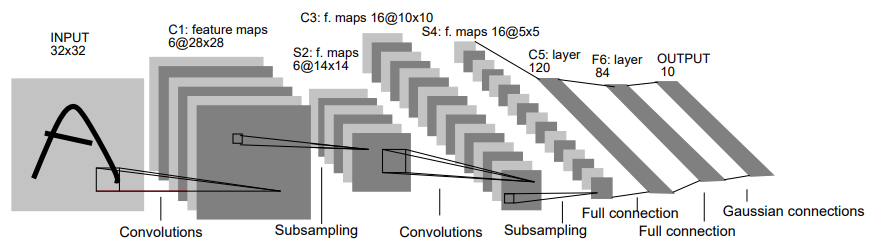
MLP를 생각해보면, 28x28 사이즈의 이미지가 들어왔을 때 이를 학습시킬려면 우선 1차원 형태로 flatten시켜야 한다. 이 과정에서 이미지의 공간적/지역적 정보가 손실되고, parameter 수가 늘어난다.
그래서 우리는
- 이미지의 특징을 추출할 수 있고
- Flatten하지 않고 행렬 그대로 사용할 수 있고
- Parameter 수는 획기적으로 줄인
Filter를 사용한다!
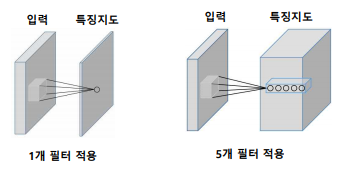
필터을 이용해서 국소적으로 증폭시키고 싶은 부분이나 감소시키고 싶은 부분의 정보를 추출해낼 수 있다.
input image에 대해 특정 커널(=필터)을 stride(보폭)만큼 이동해서 곱해가며 Feature Map을 만들어낸다.
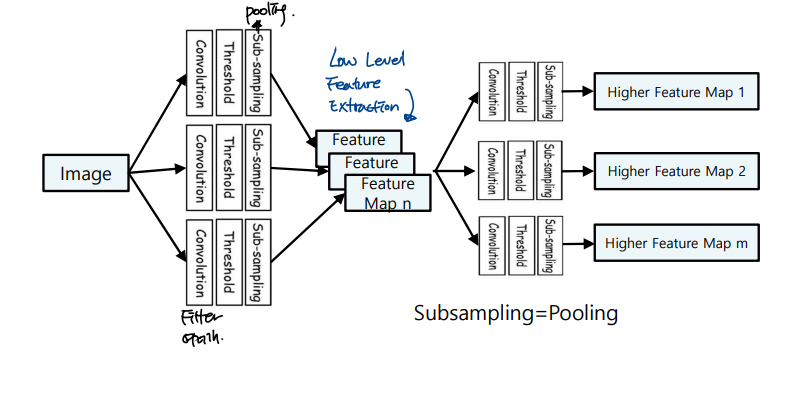
CNN 모델은
- Convolution Layer
- Pooling layer
- fully connected layer
로 구성된다.
Conv Layer, Pooling Layer에서는 feature extracting이 일어나고
F.C Layer에서는 decision making이 일어난다.
이때 Conv Layer과 Pooling Layer 사이에는 ReLU 등 Activation function이 들어가고,
분류문제의 경우 맨 마지막 F.C Layer 이후에 Softmax 연산이 진행됨.
Param. 수 계산해보기
코드
# input_shape=(3, 128, 128) # 3 channels, 128x128 model = Sequential() model.add(Conv2D(16, (3, 3), input_shape=input_shape)) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(32, (3, 3))) # model.add(BatchNormalization()) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(64)) model.add(Activation('relu')) # model.add(Dropout(0.2)) model.add(Dense(3)) model.add(Activation('softmax'))
결과
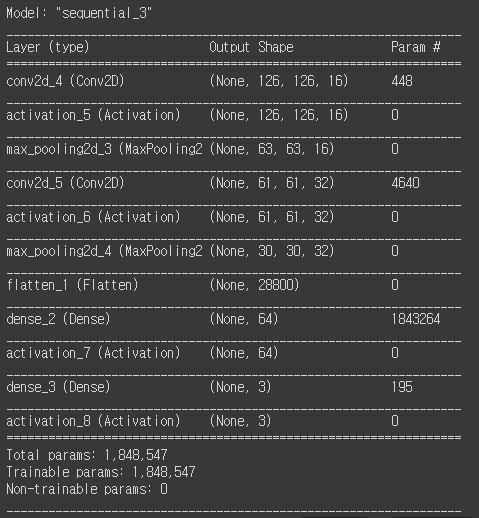
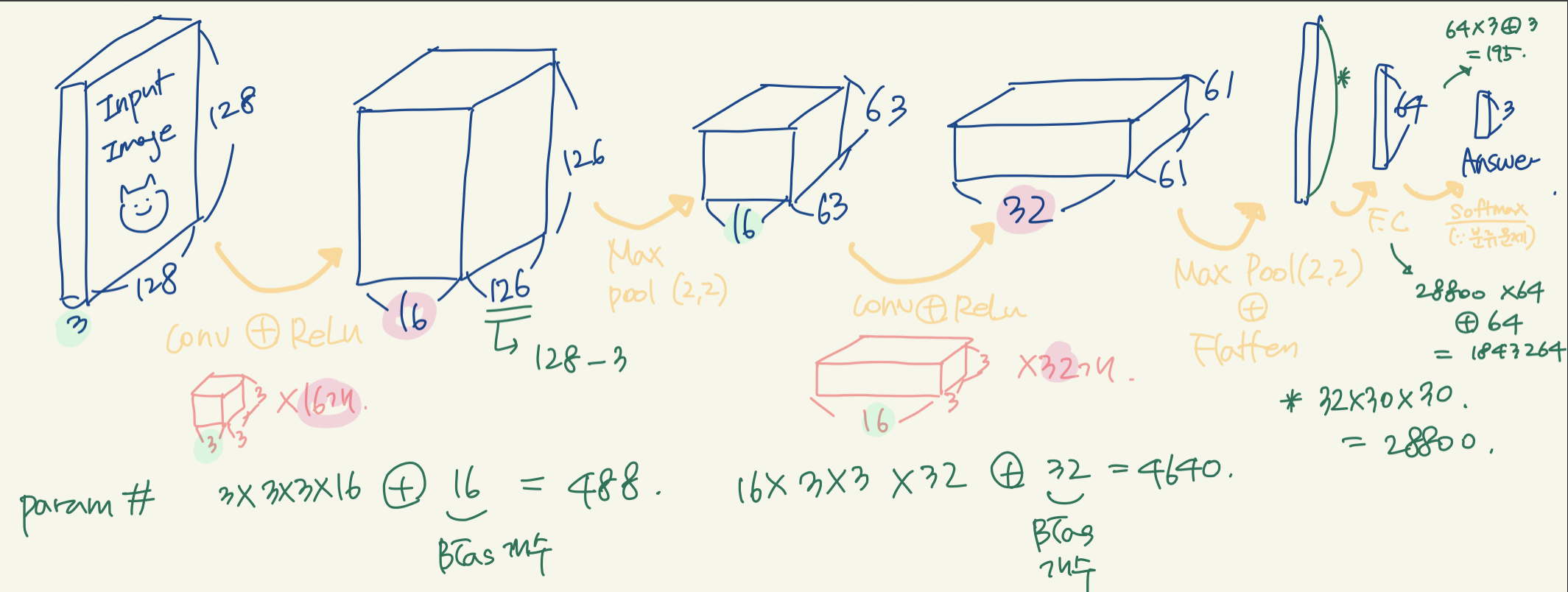
나 말고는 아무도 못알아볼 듯 한 param 계산 과정
해본걸로 만족 ^^;;; 해보면서 완벽하게 이해함
Modern CNN
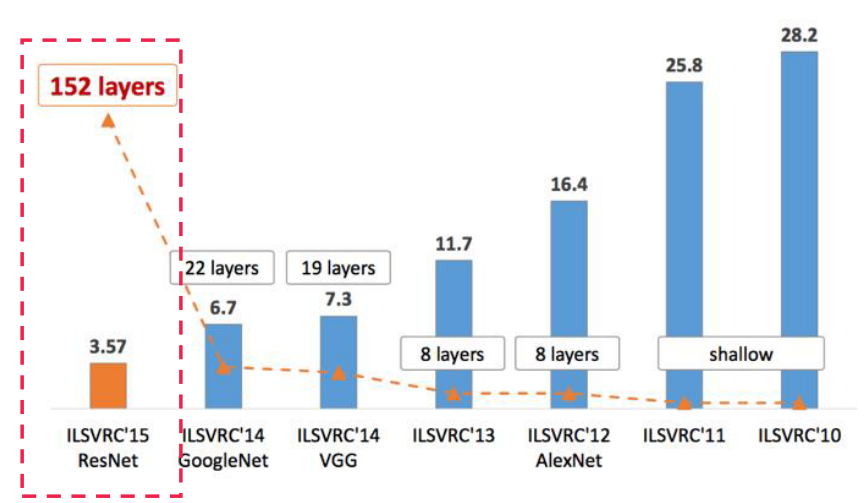
AlexNet
- ReLu Activation
Vanishing Gradient 문제 해결했음 - GPU 연산
- Data Augmentation
- Dropout
등, 지금보면 conventional한 작업들의 초석을 마련한 모델.
VGGNEt
3x3 필터들을 쌓아서 depth를 늘렸음
1x1 필터를 이용해 Fully connected layer를 구현함
레이어 개수에 따라서 VGG16, VGG19로 나뉨
Why 3x3 Conv?
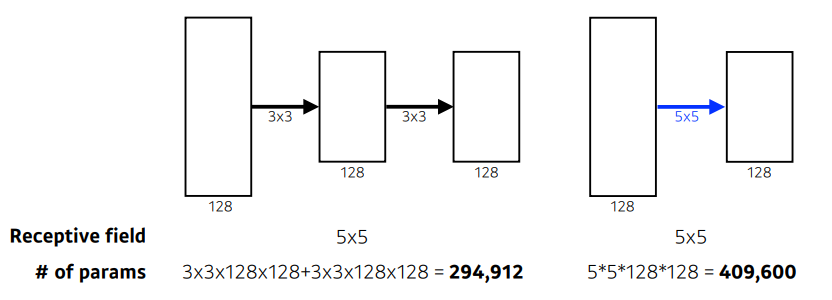
3x3 conv를 두 번 거친 것이
5x5 conv를 한 번 거친 것과
- Receptive Field는 같으나
- Param 개수가 현저히 낮다.
GoogleNet
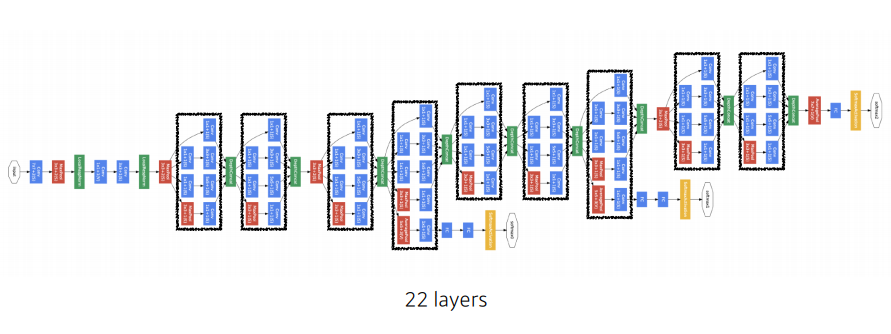
1x1 conv를 살뜰히 사용한 모델
1x1 conv를 이용해서 차원축소를 진행한다.
차원 축소를 위해서, 1x1 크기의 필터로 Convolution을 진행한다.
우리가 알고있는 사실:
- 컨볼루션 레이어가 깊어질수록 학습이 잘 됨
- Parameter 수가 많으면 Generalization, 학습효과가 좋지 않음
따라서 우리는 레이어는 깊게 하고, param 수는 최소화하기 위해 1x1 conv를 한다.
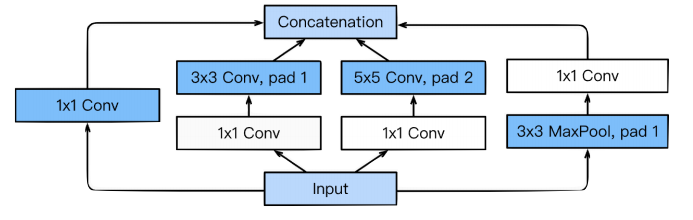
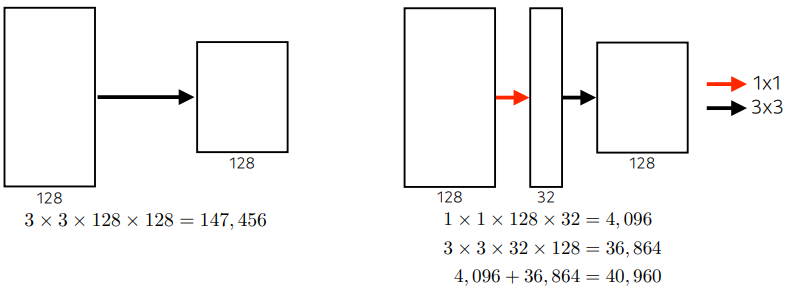
앞서 살펴본 3x3과 같은 느낌.
Output 크기는 같으나, 중간에 차원축소를 한번 넣어놔서 param 수를 70% 절약한다.
ResNet
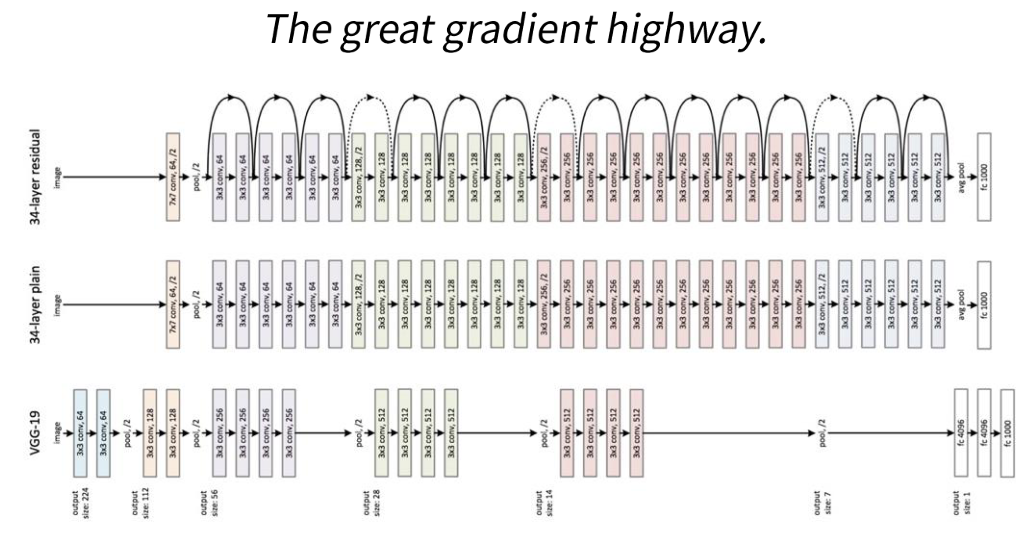
Skip Connectinon
gradient를 전달하기 위한 좋은 통로가 된다.
Residual Learning
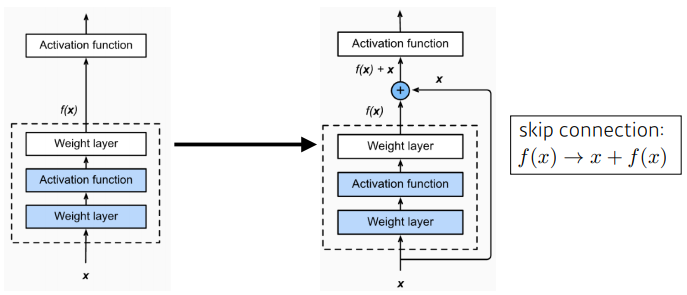
내가 이해한 바로는
- Gradient Vanishing 문제를 해결하기 위해 고안된 장치
인 것 같다...
조금 더 공부하고 추가하겠음
가능하면 논문을 주말에 읽어보도록
Bottleneck Architecture (1x1 Convolution)
