전통적인 머신러닝은 다음과 같은 방식을 따랐다.
- 사용자 단말(PC, 스마트폰 등)에서 데이터 수집
- 모든 데이터를 중앙 서버로 전송
- 서버에서 모델 학습 수행
이에 따라 몇 가지 문제점이 발생하게 되었다.
-
데이터 프라이버시
- 현대의 데이터는 민감한 내용을 많이 담고 있음
- 중앙 집중형 ML에서는 사용자 데이터가 중앙 서버에 수집 · 저장되는 경우가 많으므로 개인정보 유출 위험에 노출될 수 있음
- "원본 개인 데이터를 중앙 서버로 마음대로 수집·활용하지 마라"는 규제의 강화
-
통신 비용과 지연 시간
- 방대한 양의 데이터
- 전부 서버로 전송하면 통신 비용이 증가
-
자원이 비효율적으로 사용되는 문제
- 디바이스의 연산 성능 향상
- 하지만 여전히 학습은 서버에서만 수행 (연산 비용 증가)
-
개인화 문제
- 사용자별 특성 반영 어려움
데이터를 보내지 말고, 모델만 움직이자!
이러한 문제점을 해결하기 위한 대안으로 Federated Learning이 등장하였다. FL은 중앙 서버의 조정 하에 다수의 클라이언트(모바일 기기 등)가 훈련 데이터를 분산된 상태로 유지하면서 협업적으로(collaboratively) 모델을 훈련하는 머신러닝 환경이다. 다시 말해, 각 클라이언트의 원시 데이터는 로컬에 저장되며 교환되거나 전송되지 않는다. 대신, 학습 목표를 달성하기 위해 즉각적인 집계를 목적으로 한 집중 업데이트가 사용된다.
“We term our approach Federated Learning, since the learning task is solved by a loose federation of participating devices (which we refer to as clients) which are coordinated by a central server.” (McMahan et al., 2016)
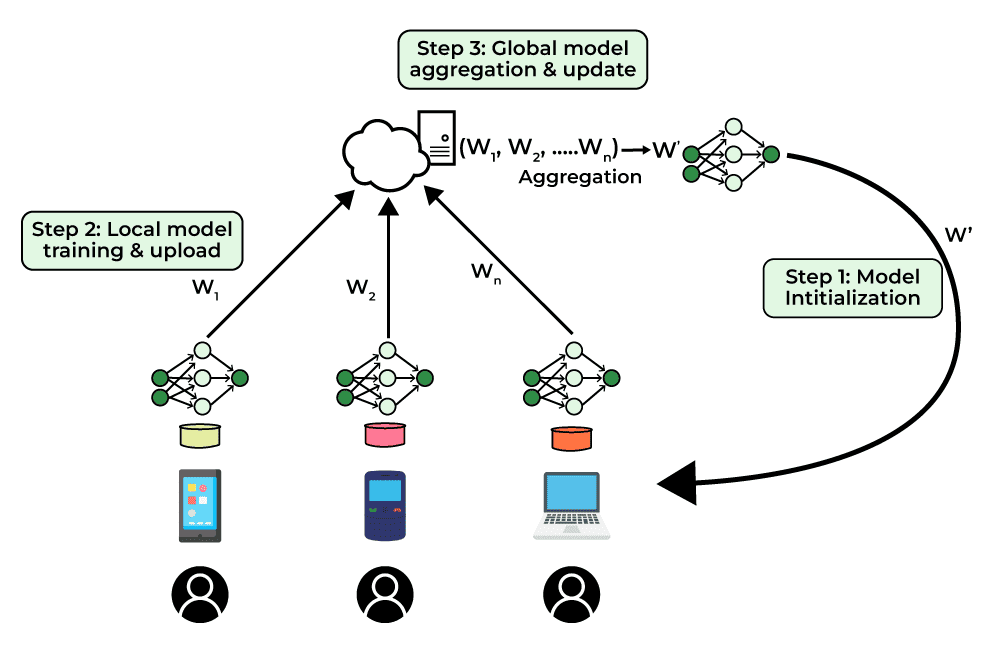
- 중앙 서버가 global model을 클라이언트 노드에 배포
- 클라이언트가 로컬 데이터를 사용하여 모델 훈련 후 업데이트(gradient, weight(가중치) 등)만 중앙 서버로 전송
- 중앙 서버가 클라이언트 업데이트를 집계 (여러 방법이 있지만 일반적으로 사용하는 방식은 Federated Averaging(FedAvg))
- 새롭게 업데이트 된 global model을 다시 클라이언트에 배포,
모델이 완전히 수렴하거나 충분히 훈련될때까지 연합 학습 반복 (각 iteration을 round라고 함)
Reference
- McMahan, Brendan, et al. "Communication-efficient learning of deep networks from decentralized data." Artificial intelligence and statistics. PMLR, 2017.
- Kairouz, Peter, et al. "Advances and open problems in federated learning." Foundations and trends® in machine learning 14.1–2 (2021): 1-210.
- Luzón, M. Victoria, et al. "A tutorial on federated learning from theory to practice: Foundations, software frameworks, exemplary use cases, and selected trends." IEEE/CAA Journal of Automatica Sinica 11.4 (2024): 824-850.
