딥러닝
1.Federated Learning의 등장 배경
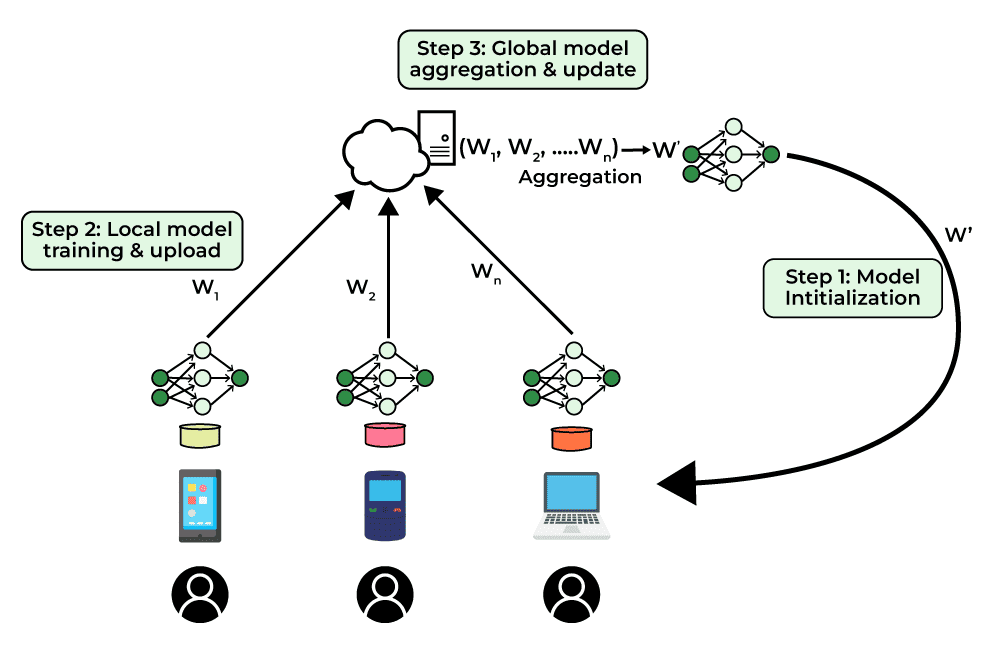
전통적인 머신러닝은 다음과 같은 방식을 따랐다. 사용자 단말(PC, 스마트폰 등)에서 데이터 수집 모든 데이터를 중앙 서버로 전송 서버에서 모델 학습 수행 이에 따라 몇 가지 문제점이 발생하게 되었다. 데이터 프라이버시 현대의 데이터는 민감한 내용을 많이 담고 있음 중앙 집중형 ML에서는 사용자 데이터가 중앙 서버에 수집 · 저장되는 경우가 많...
2.CNN(Convolutional Neural Network, 합성곱 신경망)
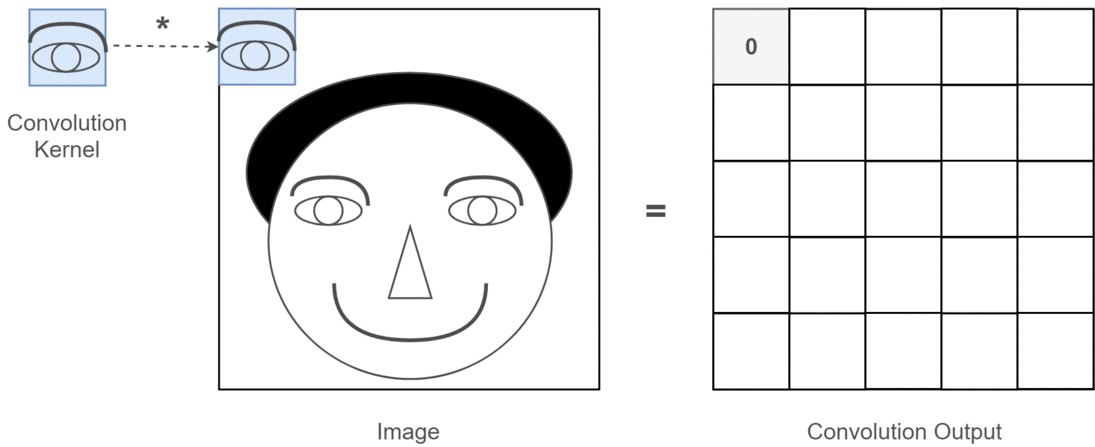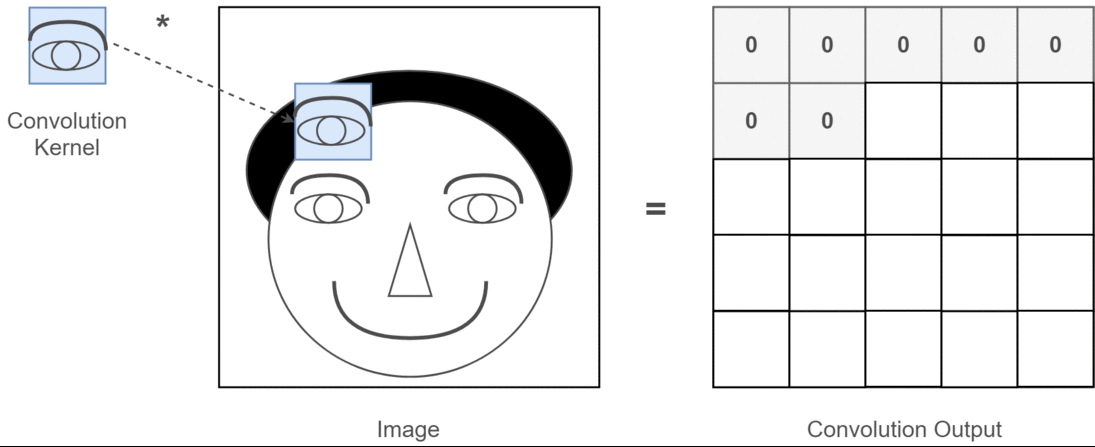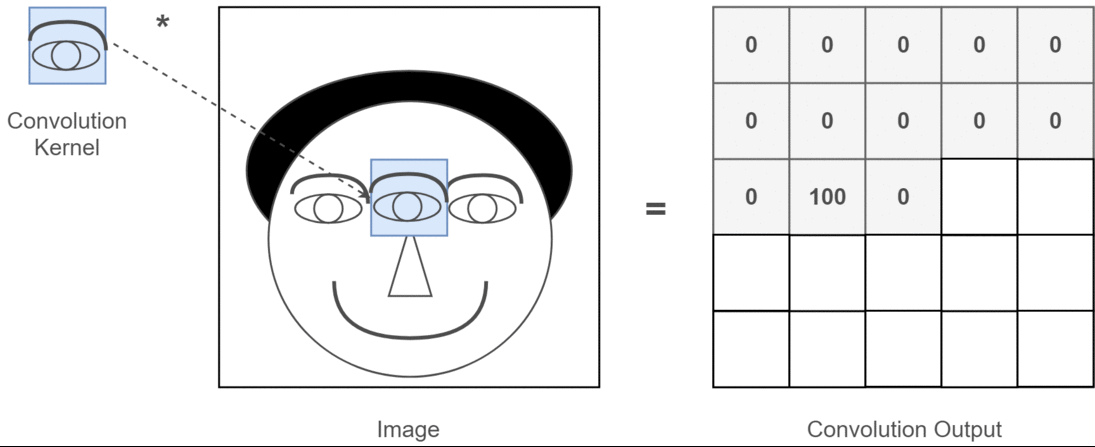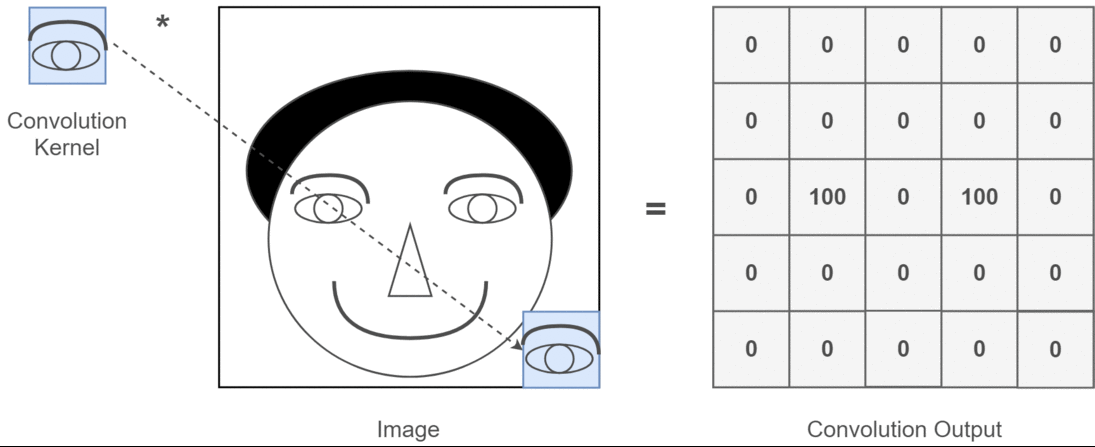
CNN의 등장 배경: ANN의 한계 인공지능이 사람처럼 이미지를 보고 분류했으면 좋겠다! ANN을 이미지에 적용 (이미지를 숫자로 바꿔 ANN에 넣음) 예: 32×32 크기의 RGB 이미지 (CIFAR-10, 컴퓨터에게 사물 인식 방법을 가르치는 데 사용할 수 있는 이미지 세트) → [32×32×3] = 3072차원 벡터 이 벡터를 그대로 ANN의 입...
3.역전파(backpropagation)

역전파란? > $W$를 어떻게 업데이트해야 Loss가 줄어들까? > CNN에는 수백만 개의 가중치가 있다. Q. 이 중 어떤 가중치를 Q. 얼마만큼 Q. 어떤 방향으로 바꿔야 할까? 역전파(backpropagation)란 모델의 출력에서 발생한 오차를 기준으로, 각 가중치가 오차에 얼마나 기여했는지를 계산하여 가중치를 어떻게 고쳐야 할지를 알려주는 과정...
4.Regularization(정규화)
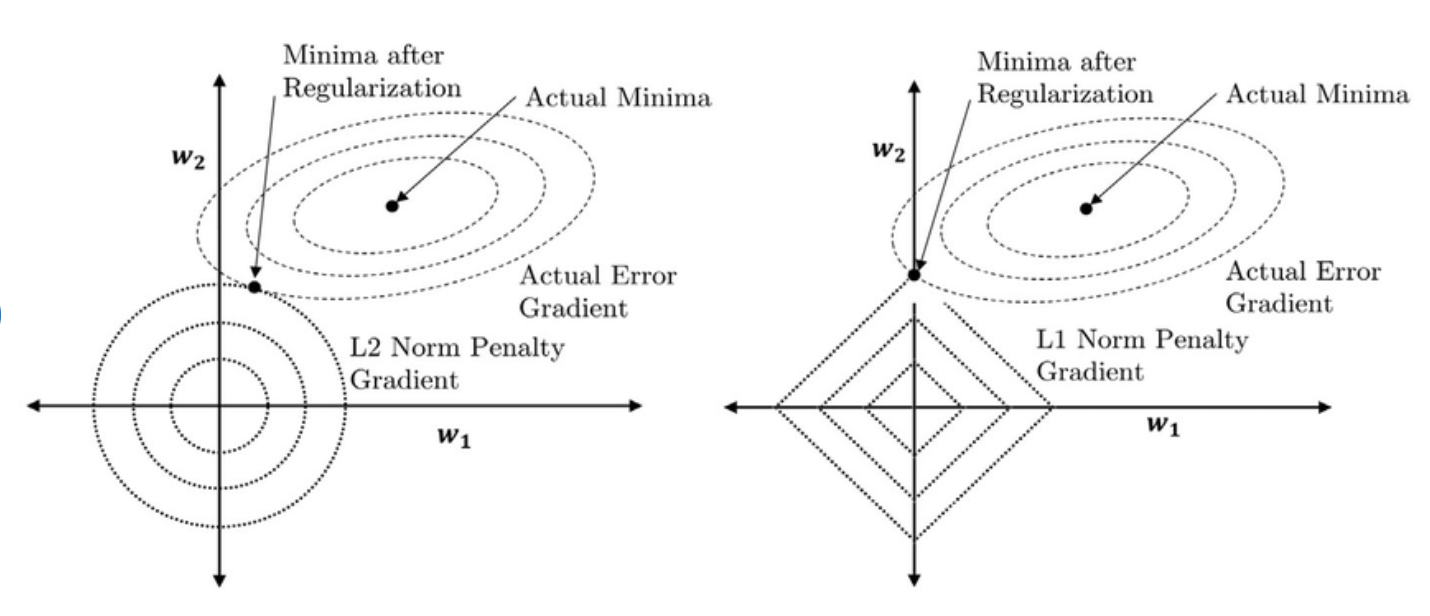
Regularization이란? > 데이터를 잘 맞추는 것과 모델을 단순하게 유지하는 것 사이에서 균형 잡기 정규화는 모델이 훈련 데이터에 너무 잘 맞아버리는 overfitting 현상을 막기 위해 모델에 제약을 주는 방법이다.overfitted model일수록 weight(가중치) 값이 크다. (노이즈까지 완벽히 맞추려면 아주 가파른 곡선, 급격히 변...
5.Data Augmentation(데이터 증강)
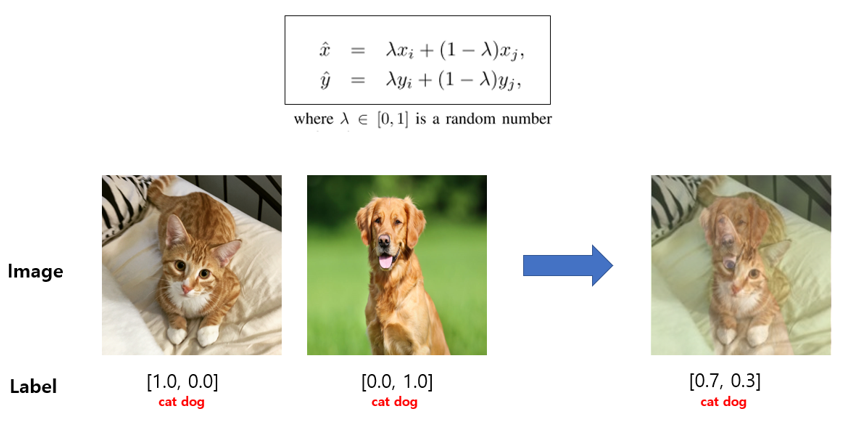
Data Augmentation(데이터 증강)은 Regularization(정규화)와 마찬가지로 overfitting 문제를 해결하는 방법이다. 다양한 유형의 학습 이미지 데이터 양을 늘리면 과적합 문제를 해결할 수 있다. || Regularization | Data Augmentation | |:---:|:---:|:---:| |개입 대상|모델|데이...
6.Federated Learning의 Challenges
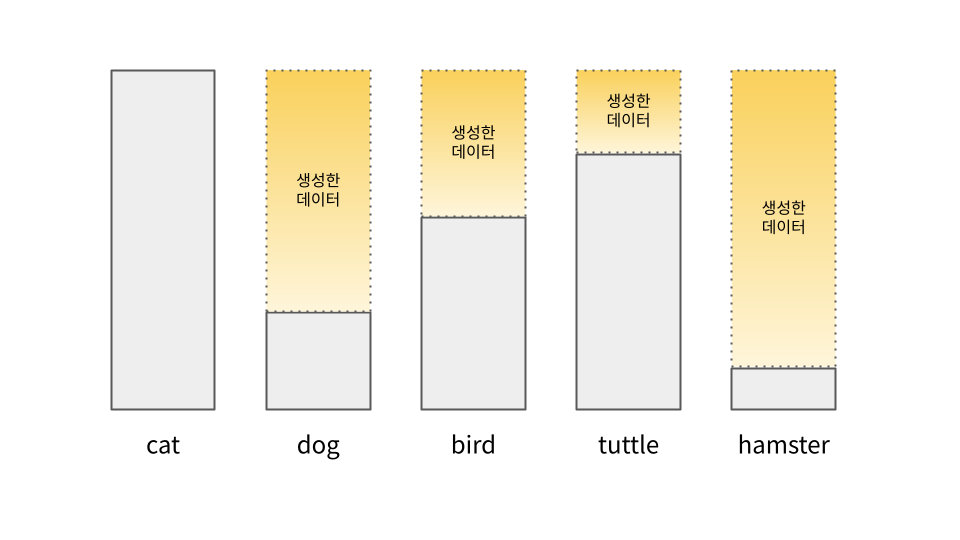
Communication Cost statistical accuracy와 communication efficiency는 trade-off 관계에 있다. 참여 클라이언트 수 매 라운드에 참여하는 클라이언트가 많을수록 전체 전송 데이터량이 증가한다. round 수, iteration 빈도 글로벌 모델이 수렴하기까지 서버-클라이언트 간에 모델 업데이트를 주...