Causal Inference
Causal Inference, 즉 인과관계추론은 통계학의 한 분야로 사회과학 등 다양한 분야에 응용될 수 있는 영역이다. 2021년 노벨경제학상이 인과관계추론 분야에서 수상되며 전통적인 방법론이었으면서도, 최근 통계학의 중요한 분야로 떠오르는 추세이다. 기존의 선형모형론부터 최근의 데이터사이언스 기법들은 대개 input data와 target variable 사이의 상관관계만을 파악할 수 있지만, 사실 사회과학적 영역부터 다양한 비즈니스 도메인까지 인과관계를 파악할 수 있는 것은 대단한 이점이다. 이에 대학원 복학 전까지 Causal Infernece 분야를 대략적으로 살펴보고자 Elements of Causal Infernece 교재를 공부해보기로 했는데, 이 책을 고른 이유는 인과관계추론을 statistical learning의 관점에서 설명해놓았기 때문이다. Causal Infernece 관련 강의를 진행하는(Youtube) Brady Neal이라는 사람이 홈페이지에 어떤 교재를 읽으면 좋을지 추천해준 글이 있는데, 이를 참고해보는 것도 좋을 것이다. 필자는 앞선 교재를 공부해보며, 공부 내용을 정리하여 주기적으로 포스팅해보도록 하겠다.
Causal Modeling
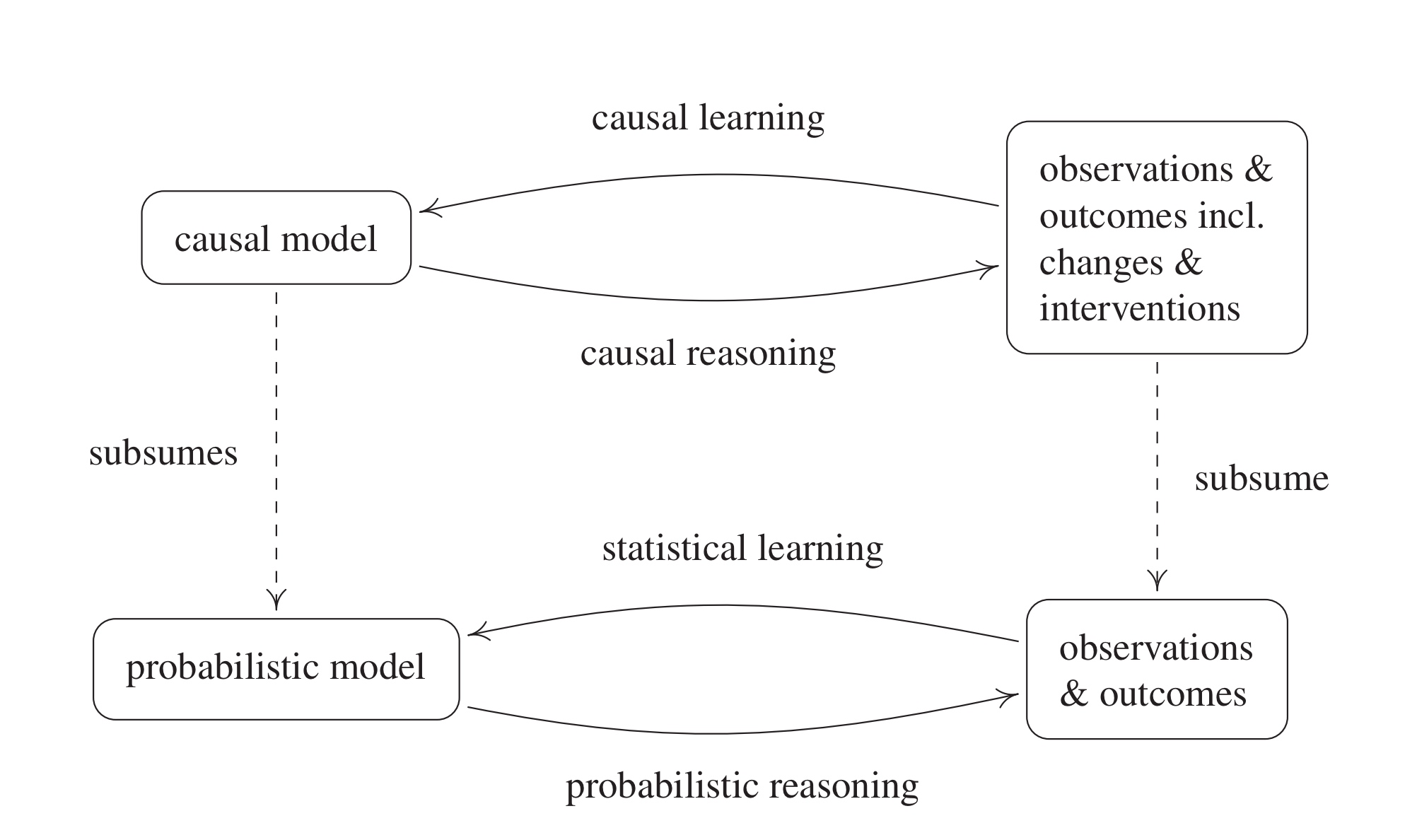
일반적으로 통계학에서 다루는 모델을 확률론적 모델, 즉 probabilistic model이라고 한다면 이는 변수 간의 joint distribution, 혹은 확률변수 간의 관계식 등으로 나타난다. 반면, 통계학의 유명한 격언인 ’Correlation doesn’t imply causation’ 과 같이 인과관계 모델(causal model)은 상관관계를 나타내는 probabilistic model에 비해 추가적인 정보를 요구한다. 즉, causal model은 probabilistic model을 수반하지만 그 역은 성립하지 않는다.
Statistical Learning 관점에서 살펴보면, statistical learning(ML,DL 포함)의 영역은 관측 데이터(empirical)로부터 probabilistic model을 추론하는 과정이다. 따라서 만일 관측 데이터로부터 causal model을 추론하고 싶다면(causal learning), 관측 데이터에 추가적인 정보(데이터의 변화나 개입에 대한 정보)가 필요할 것이다(위 그림 참고).
Reichenbach’s Common Cause Principle
인과관계 추론에서 유명한 원리 중 하나로 Reinchenbach’s Common Cause Principle, 줄여서 RCCP가 있다. 이는 어떤 두 확률변수 가 존재하고 확률적으로 상관관계를 갖는다면(positively correlated), 즉
을 만족한다면
- A가 B의 원인(cause)이다.
- B가 A의 원인이다.
- 제3의 선행변수 C가 존재하여 다음을 만족한다.
여기서 는 event 가 일어나지 않는 여사건을 의미한다.
이때 3번의 경우가 핵심인데, A와 B가 인과관계처럼 보일 수 있으면서도 사실은 선행되는 별개의 사건이 각각의 원인이 되어 원래 독립인 사건들을 인과관계가 있는 것 처럼 만들 수 있다는 사실이다. 다음과 같은 예시를 살펴보도록 하자.
Ex. MNIST Digit Problem
MNIST 데이터셋을 생성하는 과정을 생각해보자. 즉, 특정 한자리 자연수에 대한 손글씨 이미지를 생성하는 과정을 생각하면 된다. 이때, 우리는 다음 그림에서와 같은 두 경우를 생각할 수 있다.
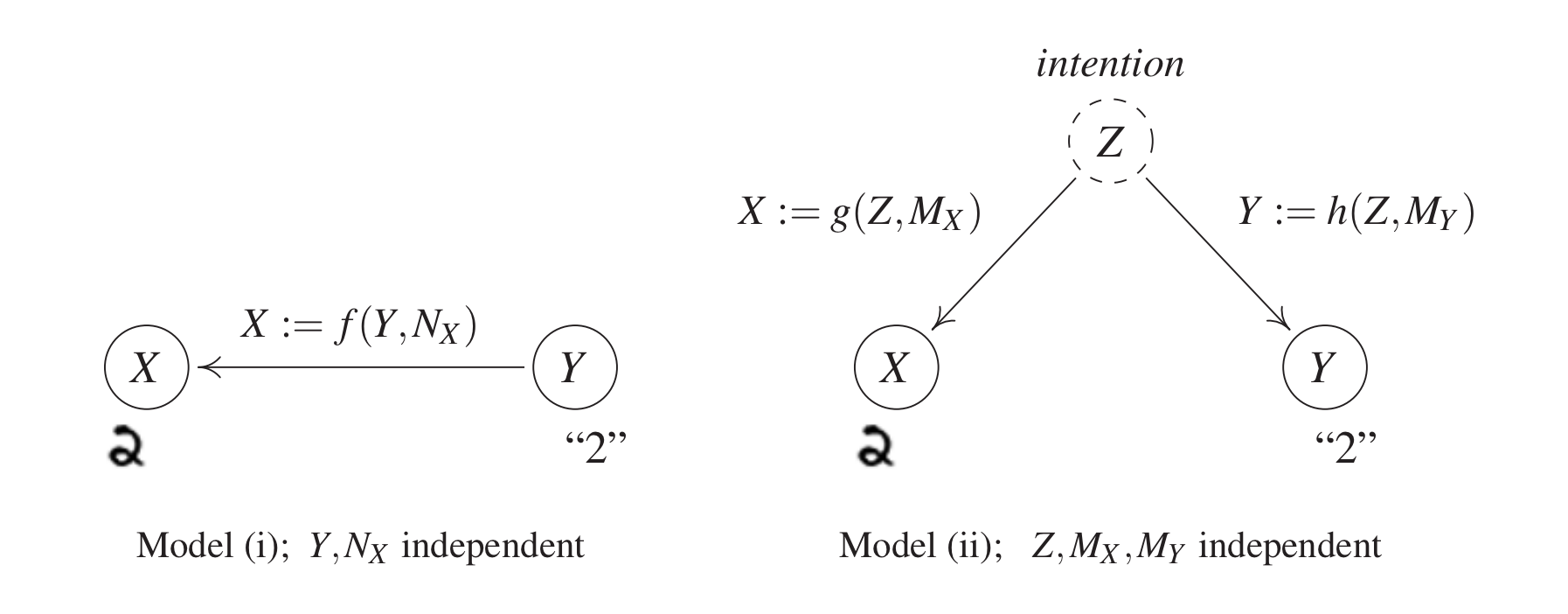
- 모델 1은 Target Variable Y가 주어지고(ex. 2, 3…) 이에 따라 손글씨를 쓰는 상황을 의미한다. 이 경우 생성된 데이터 X는 Y에 의해 영향을 받으므로 Y와 Noise Variable 의 함수로 나타내진다(그림 왼쪽).
- 반면, 모델 2의 경우는 데이터를 생성하는 주체(여기서는 사람)가 무슨 글자를 쓸지 미리 생각한 후(intention) 이를 바탕으로 Target Variable, 즉 글자의 레이블과 데이터를 생성하는 방식이다. 따라서 여기서는 주체의 의도인 새로운 제3의 변수 Z가 포함되며, 각 데이터와 레이블은 Z와 각 Noise Variable의 함수로 표현된다.
위 두 모델의 가장 큰 차이점은 Y를 변화했을 때 X가 변화하는지의 유무이다. 모델 1에서는 X가 Y의 함수로 주어지므로 Y의 변화는 X에 영향을 미친다. 반면, 모델 2에서는 Y를 변화시켜도 선행 의도 Z가 변화하지 않으므로, X 역시 변화하지 않는다. 즉, X와 Y 사이에는 인과관계가 존재하지 않는다.
인과관계추론에서의 가정
인과관계 모델(다음 글에서 자세히 살펴볼 예정)에서 한 변수가 다른 변수에 영향을 미치거나, 혹은 한 변수가 생성되는 것과 관련된 과정들을 메커니즘(mechanism) 이라고 정의한다. 이는 Input-Output으로 이루어진 함수 구조를 생각하면 된다.인과관계 모델에서 이러한 메커니즘들은 다음 세 가지 가정을 만족해야 하는데, 이를 (Physical) Independence of Mechanism이라고 한다.
- Intervenability, Autonomy, Modularity, Invariance, Transfer
첫번째 원칙은 하나의 메커니즘을 변화시킬 때 다른 메커니즘 자체가 변화되서는 안된다는 것이다. 이를 Autonomy라고도 하는데, 각 메커니즘은 고유한 함수로 미리 지정되어 있으므로 하나의 함수가 변화한다고 해서 다른 함수가 변화하지는 않는다는 것이다. 즉, 메커니즘을 잇는 메커니즘(meta-mechanism)은 존재하지 않는다는 의미이다. Intervenability, Modularity, Invariance는 아래 예시를 통해 살펴보자.
EX. 도시의 고도(A)와 기온(T)의 관계
고도와 기온의 인과관계를 파악해보는 문제를 생각해보자. 이때 모델에 대한 인위적인 개입(Intervention)은 고도의 변화와 기온의 변화 두 가지로 가능하다. 먼저 어떤 도시에 대해 초대형 엘리베이터를 설치하여 고도를 변화시키면 이는 기온의 변화로 이어질 수 있다. 반면, 어떤 도시에 초대형 산불 등으로 인한 기온의 변화(증가)가 있다고 해서 이는 도시의 고도 변화로 이어지지 않는다(고도는 이미 측정된 것이므로). 즉, physical mechanism으로서 보다는 가 더 타당하다는 것을 알 수 있고 이를 이용해의 설명 모델을 만들 수 있다. 이때 physical mechanism은 첫번째 항 에 해당하는데, Intervenability는 모델에 대한 개입, 즉 의 변화가 physical mechanism 에 영향을 주지 않는다는 것이다. 예시에서도 어떤 도시의 고도를 변화시키는 Intervention이 가정된다고 해서 고도와 온도의 실제 물리적 관계가 변화하지는 않는다는 것이 자명하다. 또한, 이러한 Physical mechanism은 실제로 Autonomous, Modular, Invariant 해야한다.
- Independence of Information in Mechanisms
두번째 원칙은 각 메커니즘에 포함된 정보는 서로 독립적이어야 한다는 것이다. 이는 확률적 독립 뿐 아니라, 서로 무관하다는 실체적 특성을 의미한다. 위 예시의 경우 메커니즘 는 에 대한 정보를 갖고 있지 않아야 하며, 이는 확률변수 A의 분포에 영향을 받지 않는다는 것을 의미한다. 즉, 고도에 따른 온도 메커니즘은 어떤 도시들이 선택되느냐에 의해 영향을 받지 않는다.
- Independent Noise
마지막 원칙은 각 메커니즘에 포함된 Noise Variable이 서로 독립이어야 한다는 것이다. 모델에서(각각 Cause, Effect) 메커니즘이 으로 주어지는 상황을 생각해보자. 이때 Noise variable 은 discrete하게 주어진다(finite set 의 원소로 주어진다). 만일 N이 특정 값 s로 고정되면(), 위 메커니즘은 로 reduce된다. 즉, Noise가 어떤 값으로 고정되는 것은 함수모임 에서 특정 메커니즘을 취하는 것과 동치이다.
이번에는 세개 이상의 노드를 가진 조금 더 복잡한 causal model을 생각해보자. 이때 두 노드 에 대한 노이즈 변수가 종속이라고 하자. 즉, 가 결정되면 의 값에도 영향을 준다는 것이다. 그런데, 앞선 설명에서 Noise의 결정은 메커니즘의 결정과 동치이므로 이는 두 메커니즘 가 서로 종속임을 의미한다. 이는 메커니즘의 독립을 의미하는 두번째 원칙에 위배되므로 노이즈 변수가 독립이어야만 한다.
