카프카는 분산 애플리케이션으로서, 대용량의 실시간 데이터 처리를 위해 배치 전송, 파티션, 분산 기능을 구현했다. 또한, 데이터의 안정적인 저장을 위해 리플리케이션 기능과 분산된 서버에서 자동으로 파티션의 리더를 선출하는 기능을 구현했다. 이 기능들은 어떻게 동작하고, 어떤 목적으로 만들어졌는지 하나하나씩 알아보자.
카프카의 특징
카프카에는 높은 처리량과 빠른 메시지 전송, 운영 효율화 등을 위해 분산 시스템, 페이지 캐시, 배치 전송 처리 등의 기능이 구현되었다. 이 기능들에 대해 알아본다.
분산 시스템
분산 시스템은 말 그대로 시스템이 여러 대의 서버로 분산되어 서비스하는 구조를 의미한다. 여러 대의 컴퓨터는 공통의 목표를 가지고 서빙된다는 특징이 있다. 즉, 동일한 동작을 하는 여러 대의 서버로 이루어진 그룹을 분산 시스템이라고 한다.
마이크로서비스 아키텍처(MSA)와 분산 시스템은 같은 의미인가?
놉!
MSA 아키텍처는 애플리케이션을 별도의 구성 요소 또는 “서비스”로 나눈다.MSA를 이루는 구성 요소 중 하나의 서비스가 여러 대의 서버로 구성되어 있다면, 그 서비스 부분이분산 시스템이라고 볼 수 있지만MSA자체가분산 시스템이라고 볼 수는 없다.
즉,분산 시스템은 여러 대의 컴퓨터로 이루어진 하나의 시스템을 의미하고,MSA 아키텍처는 큰 규모의 애플리케이션을 작은 단위의 서비스로 분리하는 아키텍처를 의미한다.
분산 시스템의 장점은 다음과 같다.
- 단일 서비스에 비해 높은 성능
- 하나의 서버에서 장애가 발생하면 다른 서버 또는 노드가 대신 처리
- 확장이 용이
카프카도 분산 시스템의 일종이다. 카프카 클러스터를 생각해보면 된다. 카프카에서는 클러스터링을 통해 브로커를 여러 대로 설정할 수 있고, 하나의 브로커에서 문제가 생겨도 다른 브로커가 대체할 수 있다.
페이지 캐시
카프카는 처리량을 높이기 위한 기능을 몇 가지 추가했고, 그 중 하나가 페이지 캐시를 이용하는 것이다. 간단히 OS와 페이지 캐시가 어떤 관련이 있는지 살펴보자. OS는 물리적 메모리에 애플리케이션이 사용하는 부분을 할당하고 남은 잔여 메모리 일부를 페이지 캐시로 유지해 OS의 전체적인 성능을 높이게 된다.
디스크에 직접 읽기/쓰기 작업보다 페이지 캐시를 통한 읽기/쓰기는 처리속도가 훨씬 빠르기에 카프카는 페이지 캐시를 이용해 메시지를 저장한다.
페이지 캐시에 저장된 데이터들은 fsync() 함수를 이용하여 물리적 디스크로 저장된다. 만약, fsync() 함수가 자주 호출되면 I/O성능은 떨어지지만 안정성은 높아지는 효과를 얻는다.
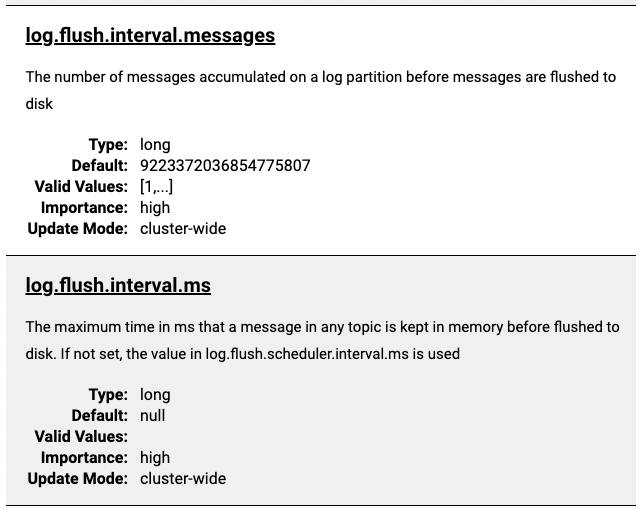
아래와 같은 설정을 변경해서, flush 주기를 수동으로 설정할 수 있다.
log.flush.interval.messages: 해당 수의 메시지들이 되면 디스크로 flushlog.flush.interval.ms: 해당 수의 시간이 되면 디스크로 flush
페이지 캐시란?
페이지 캐시는 운영체제의 가상 메모리 관리 기술 중 하나로, 물리 메모리와 디스크 사이에서 중간 계층 역할을 하면서 디스크에서 데이터를 읽어들이는 속도를 개선한다.
운영 체제는 메인 메모리 (RAM) 의 사용하지 않는 부분에페이지 캐시를 유지하여 캐시된 페이지의 내용에 더 빠르게 액세스하고 전반적인 성능을 향상시킨다.페이지 캐시는 페이징 메모리 관리와 함께 커널에서 구현되어 있다.
더 자세한 내용은 해당 포스팅을 참고하자!
카프카를 돌리는 브로커의 JVM 힙 사이즈
공식문서에서도 카프카를 돌리는 브로커의 JVM 힙사이즈는 6GB 이하로 잡기를 권장한다. 왜?
앞서 말했듯, 카프카는 다른 메시지 큐와는 달리, 디스크 기반으로 동작하기에 I/O 작업이 중요하고, 파일 시스템에 크게 의존한다. 근데 I/O 작업이 성능을 떨어트리니, 페이지 캐시를 이용한다. 페이지 캐시는 남은 메모리 공간을 사용해서 동작하기 때문에, 페이지 캐시를 너무 작은 부분으로서 동작하지 않게하기 위해, JVM의 Heap 사이즈를 너무 크게 잡지 않는 것을 권장한다.
카프카의 기본 Heap 메모리 사이즈는 1GB 이다. 설정 변경 방법은 JMX 설정방법을 참고해서,KAFKa_HEAP_OPTS="-Xmx6G -Xms6G"를 추가해주면 된다.
또한, 페이지 캐시를 서로 공유해야하기 때문에 하나의 시스템에 카프카를 다른 어플리케이션과 함께 실행하는 것은 권장하지 않는다.
배치 전송 처리
카프카에서는 작은 I/O 작업들을 묶어서 처리할 수 있도록 배치 작업으로 처리한다. I/O 작업이 빈번하게 일어나는 것이 속도를 저하시키는 원인이 될 수 있기 때문에, 높은 성능을 목표로한 카프카는 배치 처리를 지원하는 것이다.
카프카 데이터 모델
카프카는 고성능, 고가용성 메시징 어플리케이션으로 발전한 데는 토픽과 파티션이라는 데이터 모델의 역할이 컸다. 토픽과 파티션에 대해 알아보자.
토픽(Topic)에 대해서
카프카 클러스터는 토픽에 데이터를 저장한다. 즉, 토픽은 데이터를 저장하기 위한 저장소로 보는 것이 적당하다. 그리고 카프카에서는 데이터를 구분하기 위한 단위로 토픽이라는 용어를 사용한다.
- 예시로, 뉴스 관련 메시지들은 news 토픽으로 보내고, 영상 관련 메시지들은 video 토픽으로 보내는 것이다.
파티션(Partition)에 대해서
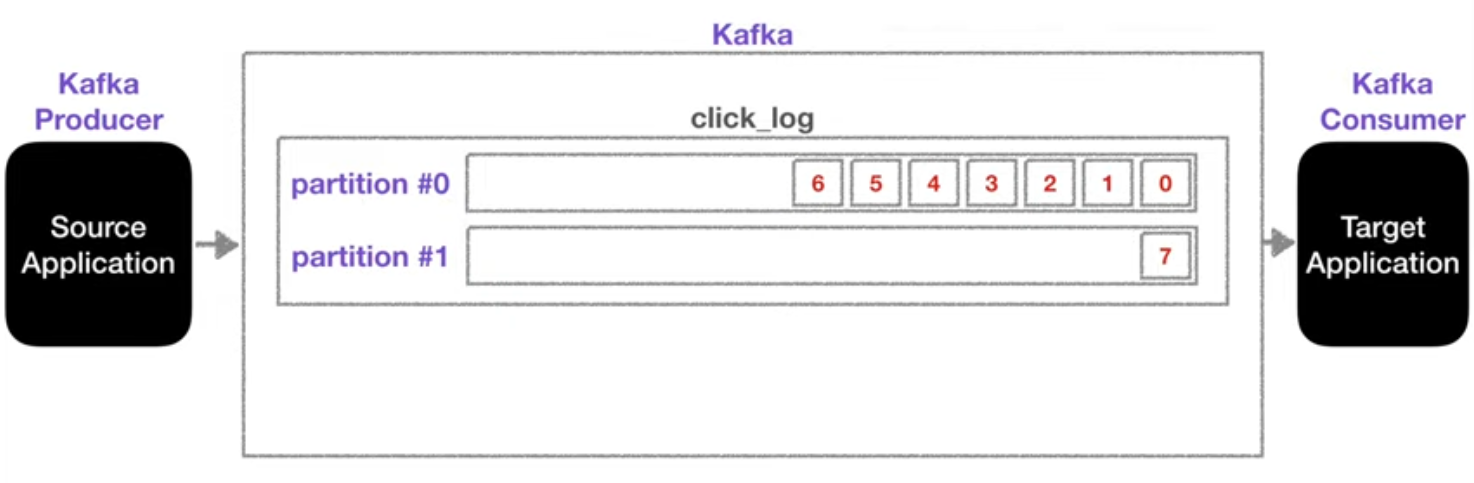
파티션은 토픽을 분할한 것이다. 왜 토픽을 파티셔닝해서 분할할까? 카프카에서는 효율적인 메시지 전송과 속도를 높이려면 토픽의 파티션 수를 늘려줘야 한다.
- 예시로, 1개의 메시지를 보내는데 1초가 걸린다고 가정해보자. 그리고 뉴스 토픽에 대해 파티션 개수를 1개에서 4개로 늘려주고, 프로듀서도 4개라면 각 프로듀서는 하나의 메시지를 각각의 뉴스 토픽의 파티션으로 보내게 된다. 이처럼 병렬 처리 방식으로 동시에 뉴스 토픽으로 보낼 수 있게 됨으로써 4개의 메시지를 보내는 데 1초가 걸리게 된다.
빠른 전송을 위해서는 토픽의 파티션을 늘려줘야 하며, 그 수 만큼 프로듀서 수도 늘려야 제대로 된 효과를 볼 수 있다.
파티션의 개수를 늘리면, 진짜 성능이 향상될까?
처음에 이해가 안됐다. 처음에는 리더 파티션이 읽기/쓰기 작업을 다하는데 어떻게 팔로워 파티션 개수가 는다고 성능이 향상되는 걸까? 라고 생각했다.
하지만 틀린 생각이었다. 애시당초에 파티션을 늘린다는 개념을 리더 파티션(Leader Partition)을 복제하는 팔로워 파티션(Follower Partition) 을 하나 더 늘린다고 생각한 부분 자체가 잘못되었다.
파티션을 복제한다는 개념은 여러 대의 브로커에서 고가용성을 위한 작업이다. 하지만 하나의 토픽 내에서 파티션 개수를 늘린다는 것은 처리를 분산시켜주는 의미를 가진다. 즉, 파티션을 늘린다는 것은 파티션을 복제한다는 것이 아닌 것이다!
예를 들어 파티션이 여러 개인 상황에서, 데이터를 보낼 때 key 값이 null이고, 기본 파티셔너를 사용한다면 라운드 로빈 방식으로 데이터를 보내게 된다. 그러면 앞서 말한 것처럼 데이터를 저장하는 데에도 파티션 개수를 늘리면 여러 파티션에서 병렬 처리를 함으로써 성능이 향상될 수 있다.
즉, 파티션을 늘린다는 것은 파티션을 복제하는 것과는 다른 개념이다! 헷갈리지 말고 사용하자! :)
파티션 수를 늘리는 게 무조건 좋은 걸까?
토픽의 파티션 수가 증가함에 따라 빠른 전송이 가능해진다. 하지만, 파티션 수가 늘어나면 카프카에 오히려 좋지 않은 영향을 미칠수도 있다.
- 파일 핸들러의 낭비
- 장애 복구 시간 증가
파티션의 적절한 개수는 어떻게 정해?
파티션 개수는 늘리는 것은 가능하지만, 줄이는 것은 불가능하기에 상황을 잘 고려해서 개수를 선정해야 한다. 그럼 어떤 기준으로 선정하는 것이 좋을까?
원하는 목표 처리량을 기준으로 잡는 것이 좋다. 다시 말하자면, 파티션을 늘리는 것은 가능하지만 파티션을 줄이는 것은 불가능하다. 그렇기에 처음에는 파티션을 작게 잡고 시작하다가 점차 요청이 많아지면, 그 때 상황에 맞춰서 파티션을 차근차근 늘려나가는 방법을 생각해보자!
시나리오를 예로 들며 이해해보자. 카프카 토픽의 파티션이 1일 때, 초당 10개의 메시지를 처리할 수 있다고 가정한다.
- 프로듀서들이 각각 초당 10개의 메시지를 해당 토픽으로 보내는데, 프로듀서의 개수는 4개이다. 즉,
초당 40개의 메시지를 처리할 수 있어야 한다.- 그렇기에 파티션을
4개로 늘리면, 초당 40개의 메시지를 처리할 수 있게 된다.
- 그렇기에 파티션을
- 컨슈머가 각각 초당 5개의 메시지를 해당 토픽에서 가져가는데, 컨슈머의 개수는 8개이다.
- 카프카에서는 컨슈머마다 각각의 파티션에 접근할 수 있게 파티션의 개수를
8개로 해줘야 한다.
- 카프카에서는 컨슈머마다 각각의 파티션에 접근할 수 있게 파티션의 개수를
프로듀서와 컨슈머 모두를 고려해주는 것이 좋다. 하지만 위에서 볼 수 있듯이 파티션의 적절한 개수를 찾기 위해 프로듀서와 컨슈머를 고려하는 방식이 다르다.
- 프로듀서 : 저장하려는 메시지를 받아줄 수 있도록 카프카의 성능이 뒷받침되어야 함
- 컨슈머 : 가져가려는 메시지를 카프카가 잘 제공할 수 있도록, 파티션의 개수를 늘려준다. 여기선 위와는 달리, 컨슈머의 성능이 메시지를
polling해가는 데에 제약조건이 된다.
오프셋과 메시지 순서
카프카에서는 각 파티션마다 메시지가 저장되는 위치를 오프셋(offset)이라고 부르고, 오프셋은 파티션 내에서 유일하고 순차적으로 증가하는 숫자(64비트 정수) 형태로 되어 있다.
- MySQL의 Auto-increment PK와 비슷하다.
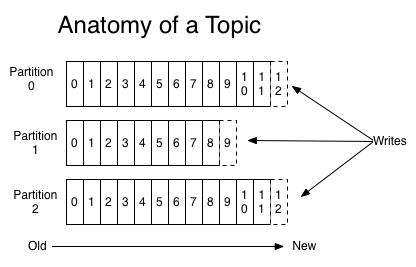
위의 그림을 보면 파티션 내에서 오프셋 번호는 유일하고 순차적으로 증가하고 있다.
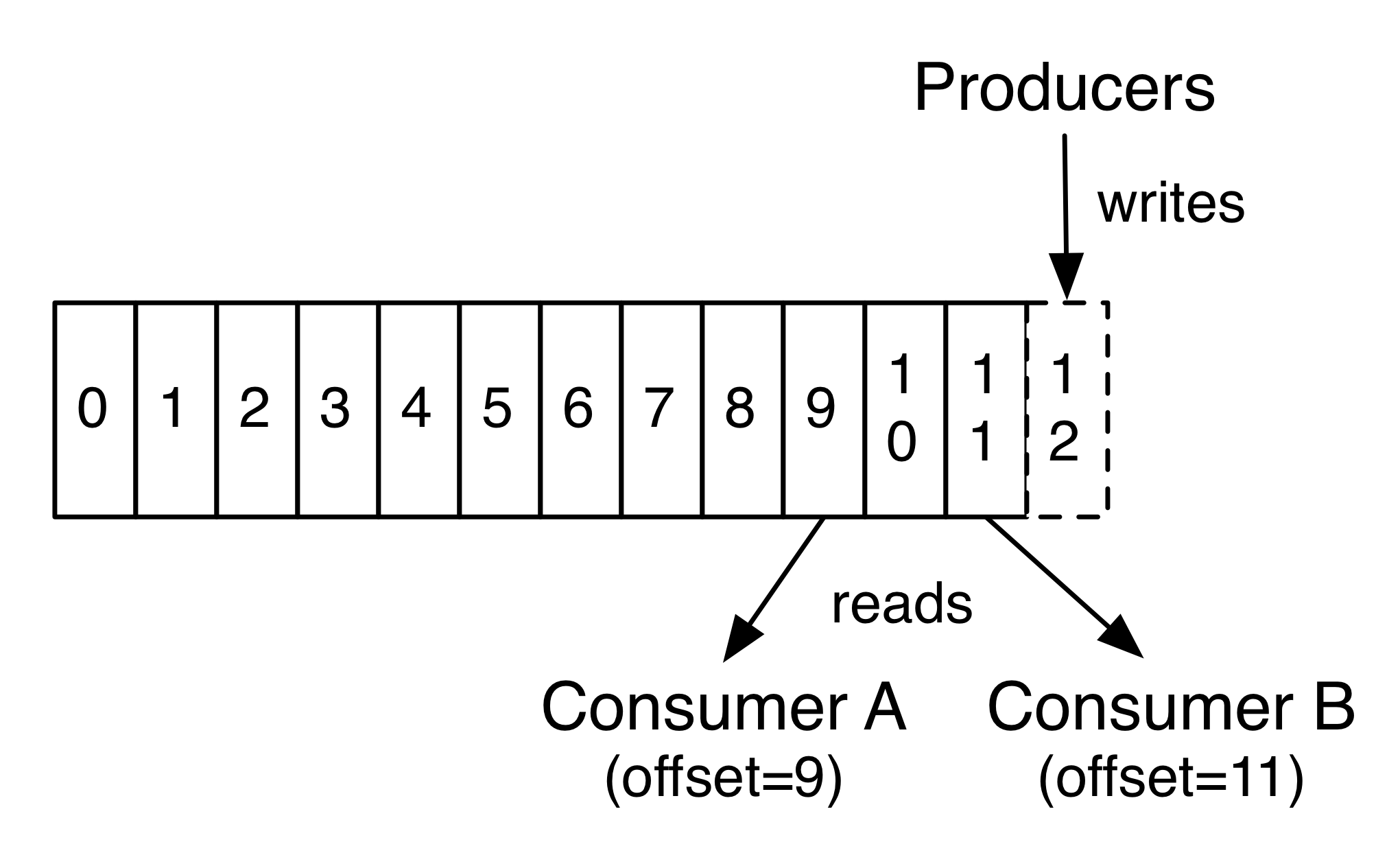
추가적으로, 카프카의 오프셋은 컨슈머 별로 해당 파티션에서 어디까지 읽었는지를 저장하고 있다. 그래서 여러 개의 컨슈머가 동일한 파티션에 대해 읽기 작업을 하더라도, 다른 컨슈머가 어디까지 읽었는지에 상관없이 해당 컨슈머가 읽은 부분부터 데이터를 읽을 수 있게 된다.
카프카의 오프셋을 컨슈머별로 저장하는 방법
ZooKeeper 또는 Kafka 내부 토픽 중 하나인
__consumer_offsets를 사용하여 컨슈머 그룹의 오프셋 정보를 저장한다.
카프카의 고가용성
고가용성하면 항상 나오는, SPoF(Single-Point-of-Failure) 문제... 카프카에서는 어떻게 SPoF 문제를 해결했는지 살펴보자.
카프카는 분산 애플리케이션으로 서버의 물리적 장애가 발생하는 경우에도 높은 가용성을 보장할 수 있도록 리플리케이션(Replication, 복제) 기능을 제공한다.
리플리케이션 팩터와 리더, 팔로워 역할
카프카에서는 리플리케이션 팩터라는 것이 있다. 각 토픽별로 다른 리플리케이션 팩터 값을 설정해줄 수 있고, 운영 중에도 리플리케이션 팩터 값을 변경할 수 있다.
replication : 1= 원본 1개만 존재replication : 2= 원본 1개와 복제본 1개 존재replication : 3= 원본 1개와 복제본 2개 존재
카프카 설정 파일에서 리플리케이션 팩터 바꾸는 법은 다음과 같다.
vi /usr/local/kafka/config/server.properties
# 파일 내에서, default.replication.factor = 2 (원하는 값으로 수정)복제 기능에서 중요한 점은 카프카에서의 복제는 토픽을 복제하는 것이 아니라, 파티션을 단위로 복제한다.
리플리케이션으로 구성된 대부분의 시스템들은 원본과 그것을 리플리케이션한 복제본을 구분하기 위해 다른 용어로 부른다.
- Zookeeper 에서는,
리더 <-> 팔로워 - RabbitMQ 에선,
마스터큐 <-> 미러드큐 - Kafka 에서는,
리더 <-> 팔로워
그리고 복제 기능에서 또 중요한 핵심은 모든 읽기와 쓰기는 리더 파티션을 통해서만 일어난다는 점이다. 즉, 팔로워 파티션은 리더 파티션의 데이터를 그대로 복제만 하고, 읽기와 쓰기에는 관여하지 않는다.
팔로워 파티션은 장애에 대응하기 위해서 존재하는 것으로, 가용성과 안정성을 위해 존재한다.
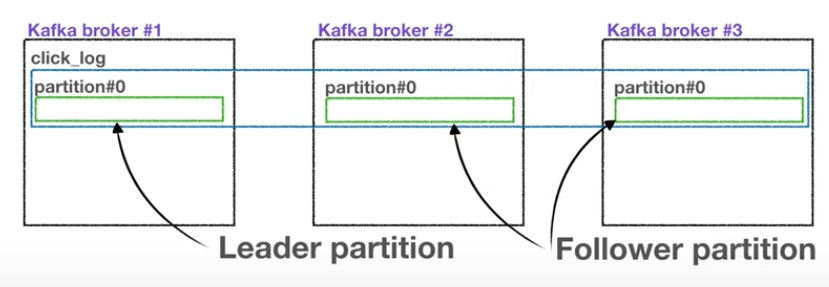
만약 위와 같이, 리플리케이션 구성된 토픽에서 장애가 발생하면 리더 변경으로 별다른 문제 없이 프로듀서의 요청들을 처리할 수 있게 된다.
복제 기능은 항상 좋은 것만은 아니다. 단점으로는 다음과 같다.
- 복제를 위해 너무 큰 저장소가 요구됨
- 브로커의 리소스 사용량 증가
- 브로커에서는 비활성화된 토픽이 복제를 잘하고 있는지 비활성화된 토픽의 상태를 체크하는 등의 작업이 이뤄지고 있기에 복제를 많이 할수록, 리소스 사용량이 증가한다.
리더와 팔로워의 관리
분산 애플리케이션은 각자의 방식으로 리플리케이션 작업을 처리한다. 리더는 모든 데이터의 읽기/쓰기에 대한 요청에 응답하면서 데이터를 저장해나가고, 팔로워는 리더를 주기적으로 보면서 자신에게 없는 데이터를 리더로부터 가져오는 방법으로 리플리케이션을 유지한다.
ISR (In Sync Replica)
하지만, 팔로워에 문제가 있어서 리더로부터 데이터를 가져오지 못하게 되면 정합성이 깨질 수 있다. 카프카에서는 이런 문제를 방지하고자, ISR(In Sync Replica) 라는 개념을 도입했다.
ISR의 의미는 현재 리플리케이션되고 있는 리플리케이션 그룹을 의미한다. ISR에는 중요한 규칙이 하나 있다.
- ISR에 속해 있는 구성원만이 리더의 자격을 가질 수 있다.
리더와의 데이터 동기화 작업을 매우 중요하게 처리하고 있으며, 이것을 유지하는 것이 바로 ISR이다. ISR이라는 그룹을 만들어 리플리케이션의 신뢰성을 높이고 있는 것이다.
리더 파티션은 팔로워 파티션들이 주기적으로 데이터를 확인을 하고 있는지 확인해서 만약 설정된 주기(replica.lag.time.max.ms)만큼 확인 요청이 오지 않으면, 해당 팔로워는 더 이상 리더의 역할을 할 수 없다고 판단해 ISR 그룹에서 추방시킨다.
리더 파티션은 참 하는 일이 많다...
모든 브로커가 다운되면?
생각해볼 수 있는 최악의 시나리오는 모든 브로커가 다운되는 것이다. 선택할 수 있는 해결방법은 다음과 같다.
- 마지막 리더가 살아나기를 기다린다.
- ISR에서 추방되었지만 먼저 살아나면 자동으로 리더가 된다.
첫 번째 방법처럼 마지막 리더가 동작하기를 기다린다면, 메시지 손실 없이 장애상황을 넘길 수 있다. 하지만 이 조건에서 가장 중요한 제약조건이 있다. "재시작시, 마지막 리더가 반드시 시작되어야 한다." 는 조건이 있다.
- 리더 브로커는 복구가 안되고 팔로워 브로커들은 복구가 된 상황에서 계속 리더 브로커가 정상화될 때까지 기다리는 건 장애가 길어지며 비즈니스적으로도 큰 손실을 가져올 수 있다.
두 번째 방법처럼 ISR 그룹에서 추방당했던 브로커를 재시작한다면, 메시지 손실이 발생할 수 밖에 없다. 하지만 이 방법은 클러스터 전체가 다운되어도 브로커 하나만이라도 정상화시켜 빠르게 장애 상황을 넘길 수 있다.
- 만약, 메시지가 손실되면 안되는 중요한 서비스라면 첫 번째 방법을 택하는 것이 좋아보인다.
이는 설정 파일로 개발자가 선택할 수 있다.
$ vi /usr/local/kafka/config/server.properties
# unclean.leader.election.enable = false
## - false : 1번째 방법 (메시지 손실X)
## - true : 2번째 방법(메시지 손실O)가용성과 일관성 중 어느 쪽에 더 초점을 두느냐에 따라 선택하면 될 것이다.
카프카에서 사용하는 주키퍼 지노드 역할
카프카에서 사용하는 주키퍼의 중요한 지노드들을 간단히 정리해본다.
/{토픽}/controller- 현재 카프카 클러스터의 컨트롤러 정보를 확인할 수 있다. 컨트롤러는 브로커 레벨에서 실패를 감지하고, 실패한 브로커에 의해 영향받는 모든 파티션의 리더 변경을 책임진다.
/{토픽}/brokers- 토픽의 파티션 수, ISR 구성정보, 리더 정보 등을 확인할 수 있다.
/{토픽}/consumers- 컨슈머가 각각의 파티션들에 대해 어디까지 읽었는지를 기록하는 오프셋 정보가 저장된다.
- 카프카 2.8 버전 이후부터 주키퍼에 오프셋을 저장하는 방법은 이후 종료되었고, 카프카 내부에서
Consumer Group Metadata라는 이름으로 오프셋 정보가 기록된다.
/{토픽}/config- 토픽의 상세 설정정보를 확인할 수 있다.
Reference
카프카, 데이터 플랫폼의 최강자
데브원영, 아파치 카프카
https://kafka.apache.org/documentation/
https://www.atlassian.com/ko/microservices/microservices-architecture/distributed-architecture
https://www.youtube.com/watch?v=SuHtHQkRV7g
https://en.wikipedia.org/wiki/Page_cache
https://wiki.terzeron.com/ko/OS일반시스템/Kafka/Kafka_소개
ttps://medium.com/@tas.com/파일-시스템에-대한-기초적인-개념정리-9144dabce95d
