카프카 관리를 위한 주키퍼
최근에는 하둡(Hadoop), 나이파이(NiFi), 스톰(Storm) 등 많은 어플리케이션이 부하 분산 및 확장이 용이한 분산 어플리케이션으로 개발되고 있다. 이러한 분산 애플리케이션을 이용하게 되면, 분산 어플리케이션 관리를 위한 안정적인 코디네이션 애플리케이션이 추가로 필요하게 된다.
코디네이션 어플리케이션이란?
코디네이션 어플리케이션은 분산 시스템에서 시스템 간의 정보 공유, 상태 체크, 서버들 간의 동기화를 위한 락 등을 처리해주는 서비스를 의미한다.
카프카는 분산 어플리케이션의 한 종류로서 주키퍼를 코디네이션 로직으로 이용하고 있다. 분산 애플리케이션이 안정적인 서비스를 제공할 수 있도록 분산되어 있는 각 애플리케이션의 정볼르 중앙에 집중하고 구성 관리, 그룹 관리 네이밍, 동기화 등의 서비스를 제공한다. 따라서 주키퍼의 기본적인 내용을 잘 알아두면 카프카를 이용하는 데에 많은 도움이 될 수 있다.
하지만, 카프카 4.0 버전부터는 주키퍼를 사용하지 않고도 카프카를 관리할 수 있도록 수정한다고 한다. 주키퍼를 사용하면 클러스터 메타데이터를 저장하고 동적 구성, 토픽, 토픽 내 파티션을 관리할 수 있지만 관리 계층을 추가하는 문제점이 있다라고 언급했다.
하지만 카프카 내부에 메타데이터를 저장하면 더 쉽게 관리할 수 있고, 버전 관리 등의 문제를 해결할 수 있다라고 언급하며, 카프카 4.0버전부터는 주키퍼가 아예 삭제되고, 기존 주키퍼는 내부적으로 관리되는 메타데이터용 프토로콜인 '카프카 라프트(Kafka Raft)또는크라프트(KRaft)’로 대체된다고 한다.
원문을 보려면 해당 글로 이동하세용
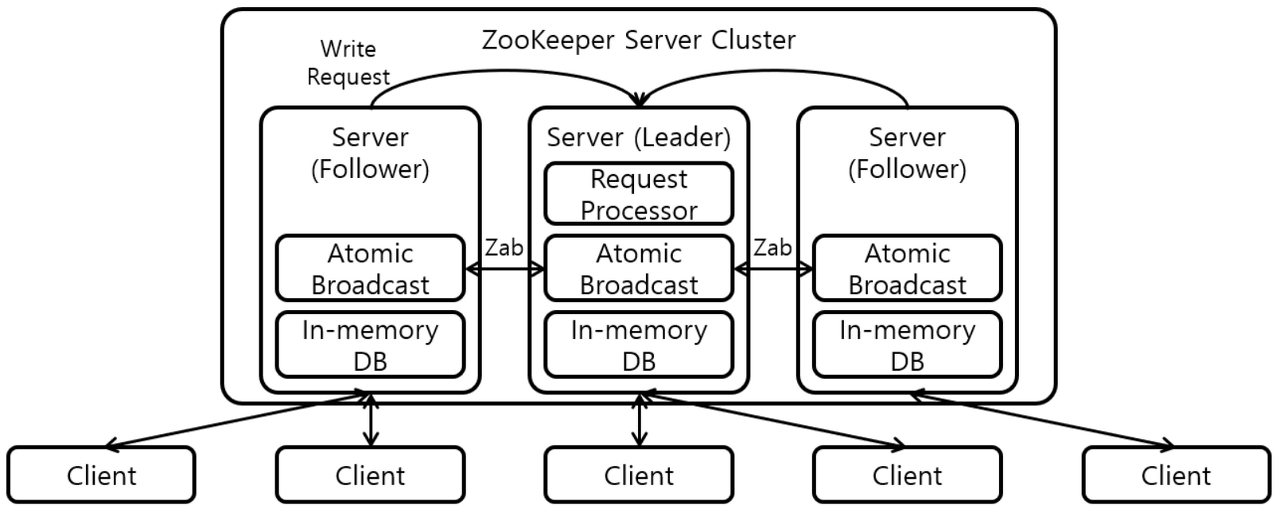
주키퍼의 구조
위의 그림과 같이 서버 여러 대를 앙상블(클러스터)로 구성하고, 분산 애플리케이션들이 각각 클라이언트가 되어 주키퍼 서버들과 커넥션을 맺은 후 상태 정보 등을 주고받는다. (여기서 클라이언트는 카프카가 된다)
상태 정보들은 주키퍼의 지노드(znode)라고 불리는 곳에 키-값 형태로 저장되고, 지노드에 저장된 것을 이용하여 분산 애플리케이션들은 서로 데이터를 주고받게 된다.
주키퍼에서 사용되는 지노드는 데이터를 저장하기 위한 공간 이름을 말하는 것이고, 일반적으로 지노드에 저장하는 데이터 크기는 바이트에서 킬로바이트 정도로 작고, 우리가 알고 있는 컴퓨터의 디렉토리 구조와 비슷한 계층형 구조로 구성되어 있다.
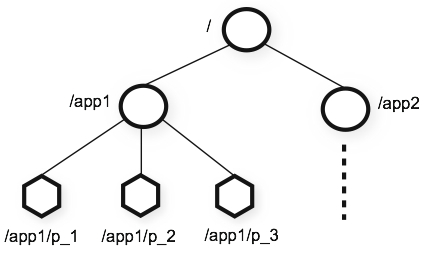
주키퍼의 특징
- 주키퍼의 각 지노드는 데이터 변경 등에 대한 유효성 검사 등을 위해 버전 번호를 관리하며, 지노드의 데이터가 변경될 때마다 지노드의 버전 번호를 증가한다.
- 일반적인 시스템과 달리, 주키퍼에 저장되는 데이터는 모두 메모리에 저장되어 처리량이 매우 크고 속도 또한 빠르다.
- 주키퍼는 좀 더 신뢰성 있는 서비스를 위해 앙상블(클러스터)이라는 호스트 세트를 구성할 수 있다.
- 앙상블로 구성되어 있는 주키퍼는 과반수 방식에 따라 살아 있는 노드 수가 과반 수 이상 유지된다면 지속적인 서비스가 가능해진다.
- 그렇기에 홀수 개수로 주키퍼의 호스트를 만들어야 한다.
- 아래의 그림을 참고해보자.

카프카, 주키퍼 설치 (도커 이용)
이제 도커로 주키퍼 서버 3대와 카프카 브로커 3대를 컨테이너로 만들어 주키퍼와 카프카를 설치하고 간단하게 이용해보도록 한다!
주키퍼 설치
주키퍼 호스트 생성 (도커 네트워크)
우선, 도커 네트워크를 생성해준다. 주키퍼와 카프카 컨테이너가 포트포워딩을 해주지 않아도 서로 서버끼리 통신할 수 있도록 하나의 네트워크 안에 컨테이너들을 띄운다. 컨테이너 환경은 CentOS 7로 설정해줬다.
$ docker network create book-zoo
## 주키퍼 book-zk1 호스트 생성
$ docker run -it --name book-zk1 --hostname book-zk1 \
--network book-zoo -p 2181:2181 \
-v /Users/gimbogyu/Documents/Study/kafka-book/zookeeper/zk1/data:/data \
centos:7 /bin/bash
## 주키퍼 book-zk2 호스트 생성
$ docker run -it --name book-zk2 --hostname book-zk2 \
--network book-zoo -p 2182:2181 \
-v /Users/gimbogyu/Documents/Study/kafka-book/zookeeper/zk2/data:/data \
centos:7 /bin/bash
## 주키퍼 book-zk3 호스트 생성
$ docker run -it --name book-zk3 --hostname book-zk3 \
--network book-zoo -p 2183:2181 \
-v /Users/gimbogyu/Documents/Study/kafka-book/zookeeper/zk3/data:/data \
centos:7 /bin/bash필요한 라이브러리 설치 (자바, wget, net-tools, nmap-ncat)
주키퍼는 자바 어플리케이션이라 서버 내에 자바가 설치되어 있어야 한다. 그리고 각종 필요한 라이브러리 다운받아준다.
yum install -y wget java-1.8.0-openjdk nmap-ncat net-tools주키퍼 설치
zookeeper-3.4.10 버전 다운받아준다.
$ cd usr/local/
$ wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
$ tar zxf zookeeper-3.4.10.tar.gz심볼릭 링크 설정
주키퍼 버전이 표시된 폴더를 사용하는 경우, 추후 주키퍼의 버전을 변경하게 되면 배포 스크립트 등에 설정되어 있는 경로를 모두 변경해야 하기 때문에 버전을 변경하더라도 동일한 경로를 계속 사용할 수 있도록 심볼릭 링크로 설정해서 사용하는 것이 좋다.
심볼릭 링크란, 파일이나 디렉토리를 가리키는 파일로, 기존 파일이나 디렉토리에 대한 참조를 가지고 새로운 파일을 만드는 것을 의미한다.
$ ln -s zookeeper-3.4.10 zookeeper
$ ls -la zookeeper # 확인용 커맨드! 아래 그림 참고
앙상블 내 주키퍼 노드를 구분하기 위한 ID 설정
해당 예제에서는 myid를 각각 1, 2, 3 으로 설정해준다.
$ mkdir /data
$ echo (노드번호) > /data/myid # ex : echo 1 > /data/myid
$ cat /data/myid # 확인용주키퍼 환경설정파일 편집
$ vi /usr/local/zookeeper/conf/zoo.cfg아래의 내용으로 수정해준다.
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data
clientPort=2181
server.1=book-zk1:2888:3888
server.2=book-zk2:2888:3888
server.3=book-zk3:2888:3888주키퍼 실행 및 중지
# 주키퍼 실행
$ /usr/local/zookeeper/bin/zkServer.sh start
# 주키퍼 중지
$ /usr/local/zookeeper/bin/zkServer.sh stop
# 주키퍼 상태 확인
$ /usr/local/zookeeper/bin/zkServer.sh status
아래의 그림처럼 나오면 주키퍼 앙상블(클러스터)가 정상적으로 작동하는 것이다!
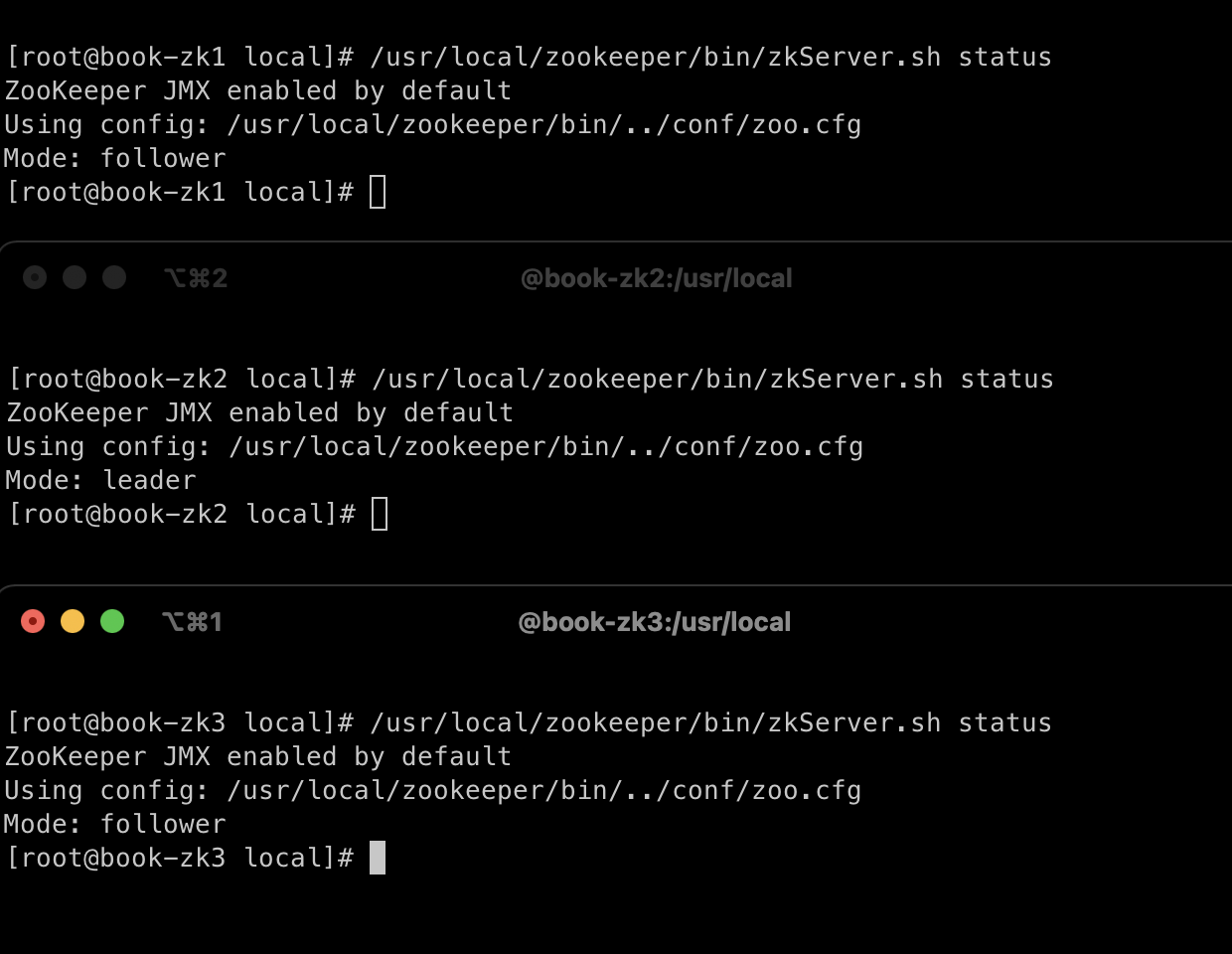
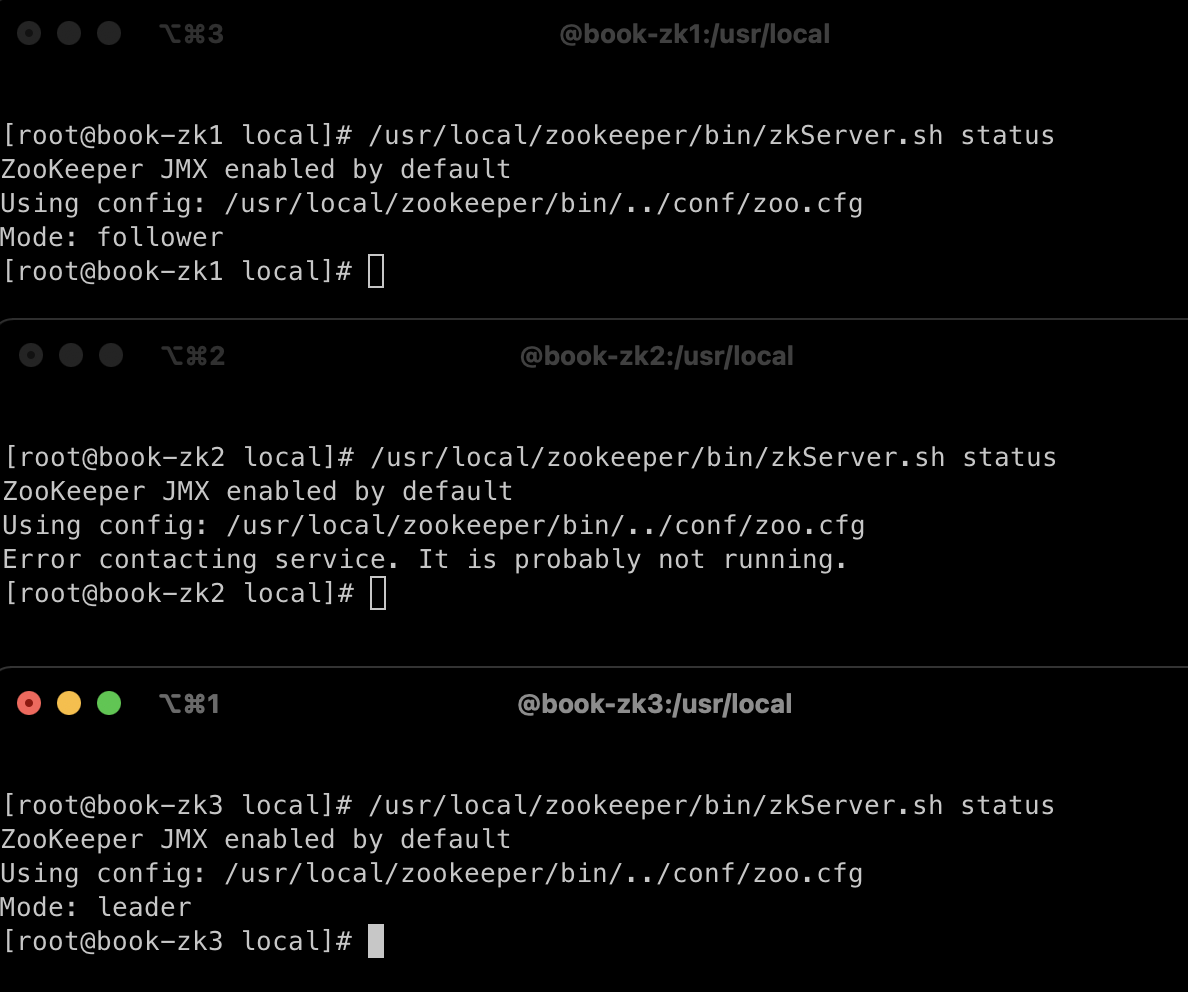
주키퍼 앙상블 테스트!
위의 그림을 보면 book-zk2 호스트가 leader 로 동작하고 있다. 근데 주키퍼 앙상블에서는 과반수가 동작하면, 정상적으로 동작한다고 했으니 한 번 Leader 주키퍼 노드를 꺼보았다! 그랬더니 book-zk3 호스트가 leader가 되어 정상 작동하고 있었다! :)
카프카 설치
카프카 브로커도 주키퍼와 마찬가지로 CentOS 7 운영체제 컨테이너에서 다운받고 사용할 것이다. 또한 카프카 브로커들도 주키퍼 서버들과 같은 네트워크에 위치시켜서 통신해주도록 한다.
카프카 브로커 생성 (도커 컨테이너)
## 카프카 브로커 3대 생성
# 카프카 book-kaf1 브로커 생성
$ docker run -it --name book-kaf1 --hostname book-kaf1 \
--network book-zoo -p 9092:9092 \
-v /Users/gimbogyu/Documents/Study/kafka-book/kafka/kaf1/data:/data \
centos:7 /bin/bash
# 카프카 book-kaf2 브로커 생성
$ docker run -it --name book-kaf2 --hostname book-kaf2 \
--network book-zoo -p 9093:9092 \
-v /Users/gimbogyu/Documents/Study/kafka-book/kafka/kaf2/data:/data \
centos:7 /bin/bash
# 카프카 book-kaf3 브로커 생성
$ docker run -it --name book-kaf3 --hostname book-kaf3 \
--network book-zoo -p 9094:9092 \
-v /Users/gimbogyu/Documents/Study/kafka-book/kafka/kaf3/data:/data \
centos:7 /bin/bash
## 필요한 라이브러리 다운로드
yum install -y wget java-1.8.0-openjdk nmap-ncat net-tools카프카 다운로드 및 심볼릭 링크 설정
## 카프카 다운로드
$ cd /usr/local
$ wget https://archive.apache.org/dist/kafka/1.0.0/kafka_2.11-1.0.0.tgz
$ tar zxf kafka_2.11-1.0.0.tgz
## 심볼릭 링크 설정
$ ln -s kafka_2.11-1.0.0 kafka
$ ls -la kafka # 확인용 커맨드카프카 저장 디렉토리 생성 (모든 브로커에서 생성)
$ mkdir /data/data1
$ mkdir /data/data2카프카 설정파일 수정
카프카는 일반 메시지 큐 서비스들과는 달리, 컨슈머가 메시지를 가져가더라도 저장된 데이터를 임시로 보관하는 기능이 있기 때문에, 카프카에서 사용할 저장 디렉토리를 설정파일에 입력해준다.
지노드를 구분해서 데이터 충돌 방지
그리고, 서로 다른 어플리케이션에서 동일한 지노드를 사용하게 될 경우, 데이터 충돌이 발생할 수 있어서, 하나의 주키퍼 앙상블 세트와 하나의 어플리케이션만 사용하는 것을 권장한다. 여러 개의 어플리케이션이 하나의 주키퍼 앙상블 세트에 접근하는 것이 잘못된 방법은 아니지만, 약간의 설정을 변경해 주키퍼 앙상블 세트를 여러 개의 어플리케이션에서 공용으로 사용할 수 있는 방법이 있다. 그 방법은 지노드를 구분해서 사용하는 것이다.
하지만 아래의 예제에서는 그냥 3대의 카프카 브로커가 동일한 지노드를 사용하는 방법을 알아보도록 한다.
vi /usr/local/kafka/config/server.properties- broker.id 는 브로커별로 다르게 설정 (ex. 1, 2, 3)
broker.id=1
- log.dirs 는 구성한 디스크 작성
log.dirs=/data/data1,/data/data2
- zookeeper.connect 는 지노드 설정 값 입력하기
zookeeper.connect=book-zk1:2181,book-zk2:2181,book-zk3:2181/book-kaf
카프카 실행 및 중지, 로그 모니터링
## 카프카 시작
$ /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
## 카프카 중지
$ /usr/local/kafka/bin/kafka-server-stop.sh
## 로그 확인
$ cat /usr/local/kafka/logs/server.log주키퍼, 카프카 연결 확인방법
TCP 포트 확인
주키퍼 확인
netstat -ntlp | grep 2181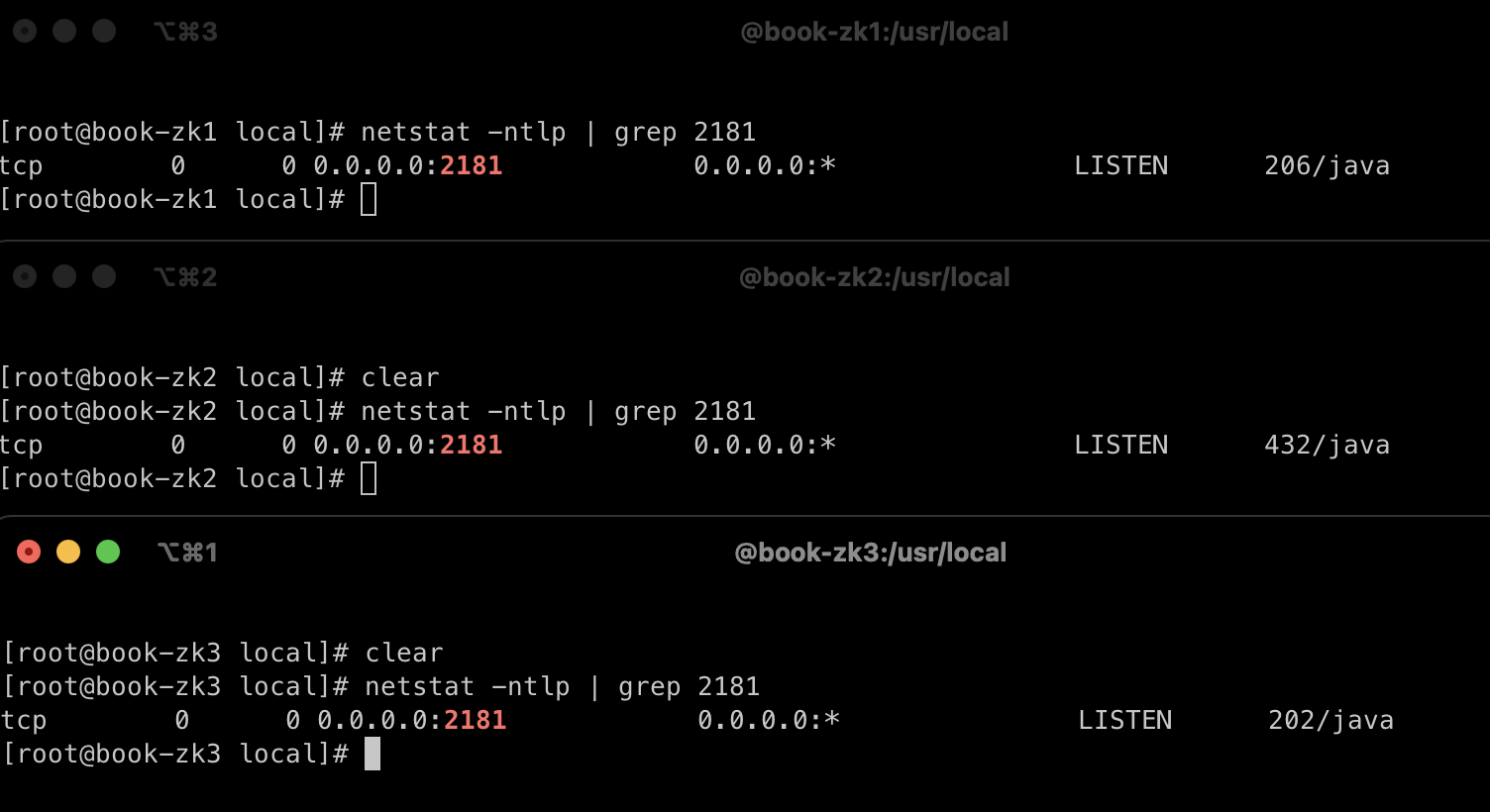
카프카 확인
netstat -ntlp | grep 9092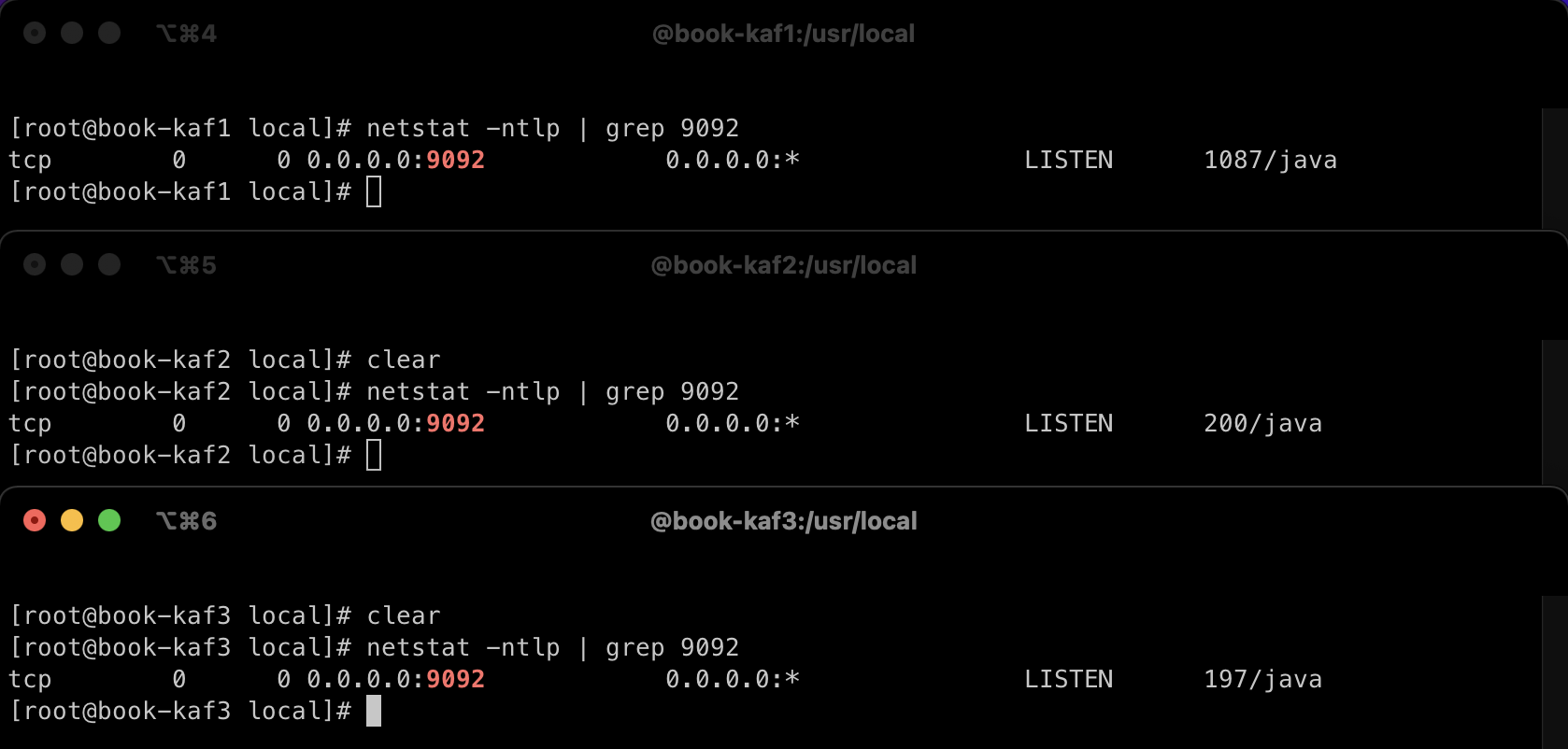
주키퍼 지노드를 이용한 카프카 정보 확인
$ /usr/local/zookeeper/bin/zkCli.sh
$ ls / # 최상위 계층의 지노드 아래의 지노드 확인
$ ls /book-kaf/brokers/ids # 해당 지노드에 연결된 브로커 ID 확인/usr/local/zookeeper/bin/zkCli.shls /ls /book-kaf/brokers/ids
지노드 삭제 방법 -
deleteallorrmr
rmr은 곧 삭제될 함수라고 한다.deleteall을 사용하자. 근데 zookeeper3.4.10 에는deleteall이 없다..
직접 카프카 동작 확인해보기
카프카에 토픽도 만들어보고, 토픽에 메시지를 보내보고, 토픽에서 메시지를 가져오는 실습을 진행해보자!
카프카 토픽생성
## 카프카 토픽 생성하는 명령어 [카프카 노드에서 진행]
/usr/local/kafka/bin/kafka-topics.sh \
--zookeeper book-zk1:2181,book-zk2:2181,book-zk3:2181/book-kaf \
--replication-factor 1 --partitions 1 --topic book-topic --create
토픽에 메시지 생성 (Publishing)
# 토픽에 메시지 퍼블리싱하는 명령어 [카프카 노드에서 진행]
/usr/local/kafka/bin/kafka-console-producer.sh \
--broker-list book-kaf1:9092,book-kaf2:9092,book-kaf3:9092 \
--topic book-topic
#
> This is message
> This is another message
# 입력창 종료하려면, Ctrl + C
메시지 가져오기 (Consumer)
## 메시지 가져오는(Consuming) 명령어
/usr/local/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server book-kaf1:9092,book-kaf2:9092,book-kaf3:9092 \
--topic book-topic --from-beginning
# 아래는 출력문
This is message
This is another message
이렇게 주키퍼 개념에 대해 간단히 알아보고 카프카와 주키퍼 설치 방법과 직접 실습해보며 잘 동작하는지 확인해볼 수 있었다.
Reference
카프카, 데이터 플랫폼의 최강자
https://data-engineer-tech.tistory.com/8
https://funveloper.tistory.com/33
https://ifuwanna.tistory.com/488
https://xangmin.tistory.com/169
https://akageun.github.io/2019/11/11/docker-zookeeper-for-dev.html
https://www.ciokorea.com/news/235594
https://zookeeper.apache.org/doc/current/zookeeperOver.html
