목차
- 옵티마이저란
- 쿼리 실행절차
- 옵티마이저의 종류
- 기본 최적화
- 풀 테이블 스캔과 풀 인덱스 스캔
- 병렬 처리
MySQL에서는 EXPLAIN 명령어로 쿼리의 실행계획을 알 수 있습니다. 또한, DataGrip 혹은 Workbench에서는 실행 쿼리에 커서를 올려두면 실행계획을 띄워주기도 합니다.
옵티마이저(Optimizer)란?
옵티마이저는 말 그대로 최적화시켜주는 장치를 의미합니다. 사실 모든 DBMS에서는 쿼리의 실행계획을 수립하는 옵티마이저를 가지고 있고 굉장히 복잡한 부분이기에 이해하는 것도 상당히 어렵습니다. 하지만 실행 계획에 대해 잘 이해해야만 실행 계획의 불합리한 부분을 찾아내서 더 최적화된 방법으로 실행 계획을 수립할 수 있도록 유도할 수 있기에 쿼리를 실행할 수 있기에 모든 개발자들은 실행 계획에 대해 자세히 알아야 합니다.
옵티마이저의 종류
옵티마이저는 2개로 크게 나눌 수 있는데, 비용 기반 최적화(Cost-based optimizer, CBO)와 규칙 기반 최적화(Rule-based optimizer, RBO) 로 나뉩니다.
- 대부분의 DBMS에서는
비용 기반 최적화를 선택 - 예전 DBMS에선
규칙 기반 최적화도 사용됨
비용 기반 최적화는 쿼리를 처리하기 위한 여러 가지 가능한 방법을 만들고, 각 단위 작업의 비용(부하) 정보와 대상 테이블의 예측된 통계 정보를 이용해 실행 계획별 비용을 산출합니다. 이렇게 산출된 실행 방법별로 비용이 최소로 소요되는 방법을 채택합니다.
하지만, 규칙 기반 최적화는 테이블의 레코드 건수나 선택도 등을 고려하지 않고 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립하는 방식입니다. 그래서 같은 쿼리에 대해서는 매번 같은 실행계획을 수립한다는 특징을 가집니다. 그래서 많은 DBMS에서 채택하지 않는 방식이 되었습니다.
쿼리 실행절차
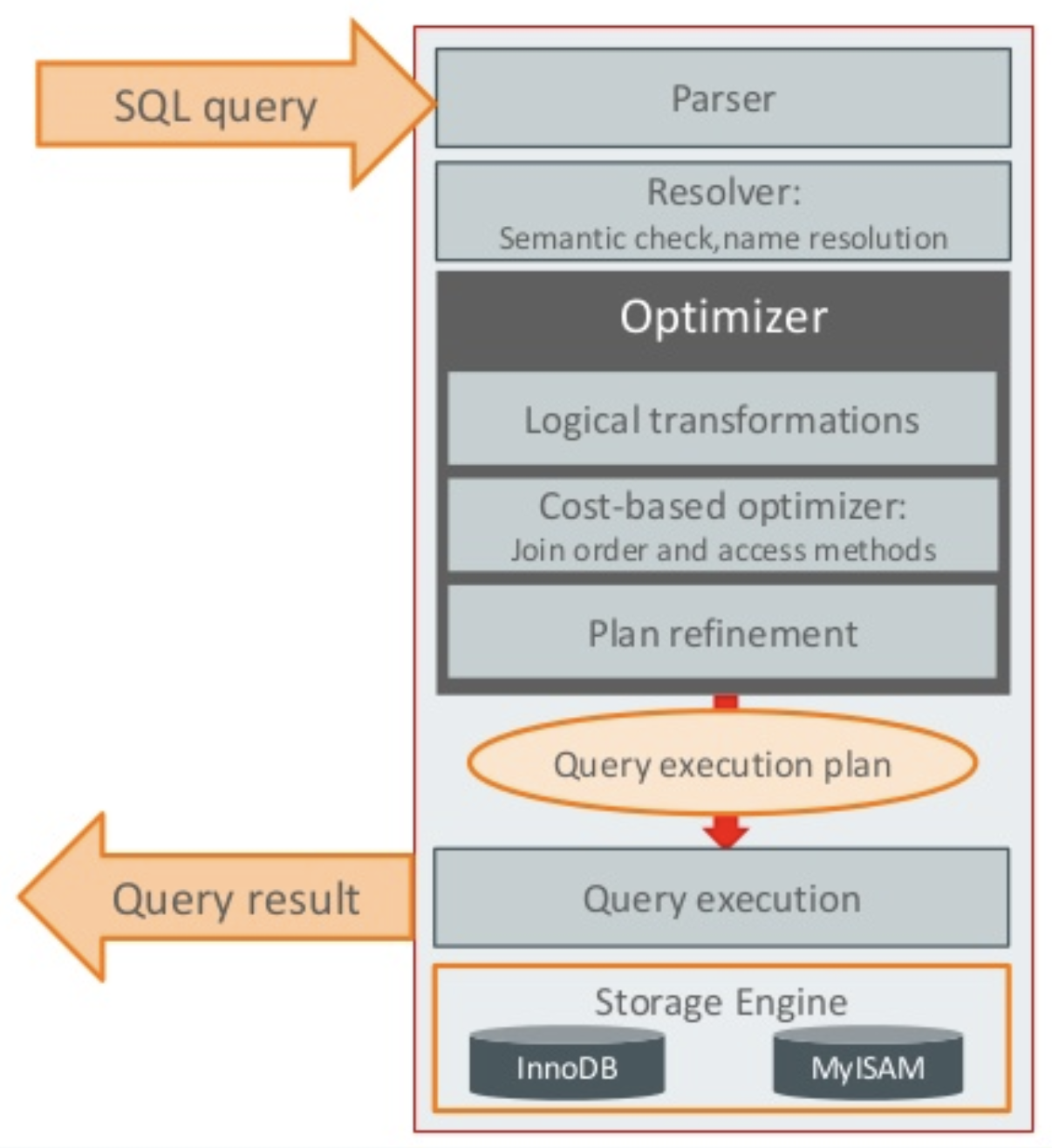
- SQL 파싱 : SQL 문장을 잘게 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리 (파싱 트리, parsing tree)
- 최적화 및 실행계획 수립 : SQL 파싱 트리를 확인하면서 어떤 테이블부터 읽고 어떤 인덱스를 이용해 테이블 읽을지 선택
- 스토리지 엔진으로부터 데이터 가져오기 : 앞 단계에서 만들어진 실행계획을 기반으로 스토리지 엔진으로부터 데이터 로드
첫 번째 단계인 SQL 파싱은 MySQL 서버의 SQL 파서라는 모듈로 처리합니다. SQL 문장이 잘못된 문법을 가지고 있다면 첫 번째 단계에서 걸러집니다. 첫 단계를 무사히 지나가면 SQL 파싱트리 가 생기는데 이를 기반으로 MySQL 서버에서는 쿼리를 실행합니다. (SQL 문장 자체를 실행하는 것이 아님!)
두 번째 단계에서는 최적화 및 실행계획 수립 단계로서 MySQL 서버의 옵티마이저에서 처리합니다. 두 번째 단계가 완료되면, 세 번째 단계에서는 수립된 실행 계획대로 스토리지 엔진에 레코드를 읽어오도록 요청하고 MySQL 엔진에서는 받은 레코드를 조인하거나 정렬하는 작업을 수행합니다.
첫 번째 단계와 두 번째 단계는 MySQL 엔진에서만 처리되고, 세 번째 단계에서는 MySQL 엔진과 스토리지 엔진이 동시에 참여해서 처리합니다.
- MySQL 엔진과 스토리지 엔진에 대한 차이를 알고 싶다면 해당 포스팅으로~
쿼리 내부적으로 사용되는 명령어의 실행절차는 아래 그림과 같다.
기본 최적화
같은 RDBMS라서 같은 결과를 내더라도 RDBMS별로 만들어내는 과정은 천차만별입니다. MySQL에서는 어떻게 결과를 만들어내는지 기본적인 부분들에 대해서 알아보겠습니다.
풀 테이블 스캔과 풀 인덱스 스캔
풀 테이블 스캔은 인덱스를 사용하지 않고, 테이블의 데이터를 처음부터 끝까지 읽어서 요청된 작업을 처리하는 작업을 의미합니다.
MySQL은 다음과 같은 조건일 때 MySQL 옵티마이저를 선택합니다.
- 테이블의 레코드 건수가 너무 작아서 인덱스를 통해 읽는 것보다 풀 테이블 스캔하는 편이 더 빠른 경우
- WHERE 절이나 ON 절에 인덱스를 이용할 수 있는 조건이 없을 경우
- 인덱스 레인지 스캔을 사용할 수 있는 쿼리라고해도, 옵티마이저가 판단한 조건 일치 레코드 건수가 너무 많은 경우
일반적으로 테이블의 전체 크기는 인덱스보다 훨씬 크기에 테이블을 처음부터 읽는 것은 많은 디스크 I/O가 발생해서 데이터베이스에 상당한 부담을 주게 됩니다.
그래서 대부분 DBMS는 풀 테이블 스캔을 실행할 때 한 꺼번에 여러 개의 블록이나 페이지를 가져오는 기능이 내장되어 있습니다.
페이지 : 데이터베이스 내에서 데이터를 관리할 때에는 레코드별로 관리되는 것이 아니라, 페이지로 관리됩니다. 페이지는 여러 개의 레코드를 가지는 구조를 가집니다.
하지만 풀 테이블 스캔 시에, 한꺼번에 몇 개씩 페이지를 읽어올지 설정하는 시스템 변수는 없습니다. 그래서 많은 사람들이 풀 테이블 스캔을 진행하면 페이지를 하나씩 읽어 오는 것으로 생각합니다.
이것은 MyISAM 스토리지 엔진의 경우에는 맞는 이야기지만, InnoDB 에는 틀린 말입니다. InnoDB는 특정 테이블의 연속된 데이터 페이지가 읽히면 백그라운드 스레드에 의해 리드 어헤드(Read ahead) 작업이 자동으로 시작됩니다.
리드 어헤드(Read ahead)란, 어떤 영역의 데이터가 앞으로 필요해지리라는 것을 예측해서 요청이 오기 전에 미리 디스크에서 읽어 InnoDB 버퍼 풀에 가져다 두는 것을 의미합니다.
즉, 풀테이블 스캔이 시작되면 처음 몇 개의 데이터 페이지는 포그라운드 스레드가 페이지 읽기를 실행하지만 특정 시점부터는 읽기 작업을 백그라운드 스레드로 넘김으로써 한 번에 4개 또는 8개의 페이지를 읽으면서 계속 그 수를 증가시킵니다.
포그라운드 스레드는 미리 버퍼 풀에 준비된 데이터를 가져다 사용하기만 하면 되므로, 쿼리가 상당히 빨리 처리됩니다.
innodb_read_ahead_threshold시스템 변수 값을 통해 InnoDB 스토리지 엔진이 언제 리드 어헤드(Read ahead) 작업을 시작할지 임계값을 설정할 수 있습니다.
포그라운드 스레드에 의해, 해당 개수 만큼의 연속된 페이지가 읽히면 InnoDB 스토리지 엔진은 백그라운드 스레드를 이용해 대량으로 그다음 페이지들을 읽어서 버퍼 풀로 적재합니다.
- 일반적으로 디폴트 설정으로도 충분하지만, 데이터 웨어하우스용으로 MySQL을 사용한다면 이 옵션을 더 낮은 값으로 설정해서 더 빨리 리드 어헤드가 시작되게 유도하는 것도 좋은 방법입니다.
풀 인덱스 스캔은 인덱스를 처음부터 끝까지 스캔하는 것을 의미합니다. 인덱스는 테이블에 비해 적은 레코드 개수를 가집니다.
- 단일 인덱스라면, 2개의 레코드(PK, 인덱스 레코드)
- 복합 인덱스라면, 보통 3개의 레코드
- 테이블 레코드 중 일부를 사용 (2~3개)
[SQL A] SELECT COUNT(*) FROM employees;
[SQL B] SELECT * FROM employees;SQL A는 풀 인덱스 스캔을 하고, SQL B는 풀 테이블 스캔을 하게 됩니다. 왜? 인덱스는 적은 레코드의 건수만 필요로 하기에 디스크 I/O 비용이 테이블 스캔에 비해 저렴합니다. 그렇기에 레코드 정보를 가져올 필요 없이, 레코드 개수만을 세는 쿼리라면 풀 인덱스 스캔으로 최적화를 진행하게 됩니다. 하지만 인덱스가 설정된 레코드 이외에도 다른 레코드를 가져와야 한다면 풀 테이블 스캔을 하게 됩니다.
병렬 처리
여기서 병렬 처리는 여러 쿼리를 동시에 처리하는 것을 의미하는 것이 아니라, 하나의 쿼리를 병렬로 실행하는 것을 의미합니다. MySQL 8.0 버전부터는 하나의 쿼리에 대해서 병렬 처리가 가능해졌습니다. 아직 병렬 처리는 제약이 많아서, 아무런 WHERE 조건 없이 테이블의 전체 건수를 가져오는 쿼리만 병렬로 처리할 수 있습니다.
innodb_parallel_read_threads시스템 변수로 변경 가능
다른 명령어나 기능들에 대한 최적화는 다음 포스팅에서 다루도록 하겠습니다.
Reference
Real MySQL 8.0 1판 - 백은빈, 이성욱
https://stackoverflow.com/questions/54357532/what-is-the-execution-order-of-the-partition-by-clause-compared-to-other-sql-cla
https://jjon.tistory.com/entry/optimizer-trace
