이미지 데이터에 대한 확률분포
이미지 데이터는 많은 픽셀들로 구현되어 있고 그 픽셀들은 3차원(RGB) 데이터를 포함하고 있어서 이미지 데이터는 고차원 데이터라고 할 수 있다. 즉, 이미지 데이터는 다차원 특징 공간의 한 점으로 표현된다.
- 이미지의 분포를 근사하는 모델을 학습할 수 있다.
사람의 얼굴에는 통계적인 평균치가 존재할 수 있다.
- 모델은 이를 수치적으로 표현할 수 있게 된다.
이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 분포를 의미한다.
- 다변수 확률분포(multivariate probability distribution) 예시는 다음과 같다.
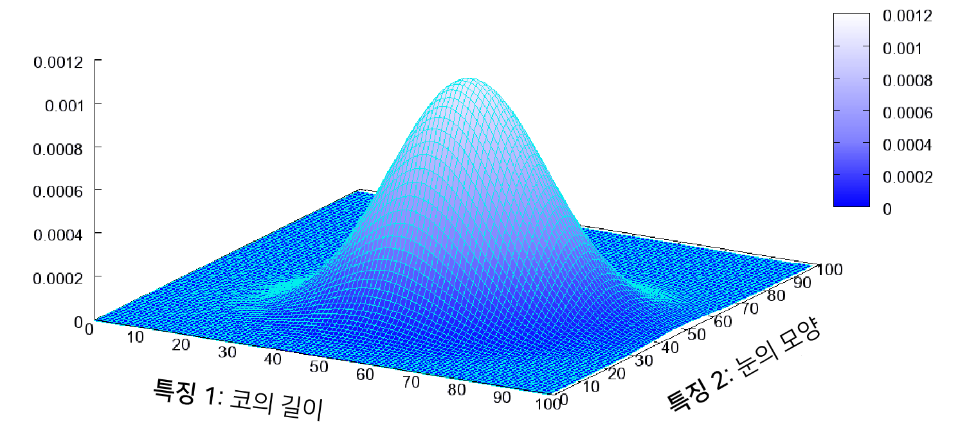
생성 모델(Generative Models)
생성 모델은 실존하지 않지만 있을 법한 이미지를 생성할 수 있는 모델을 의미합니다.
- 분류 모델은 특정한 decision boundary를 학습해서 분류하지만,
- 생성 모델은 각각의 클래스에 대해서 적절한 분포를 학습하는 형태이다.
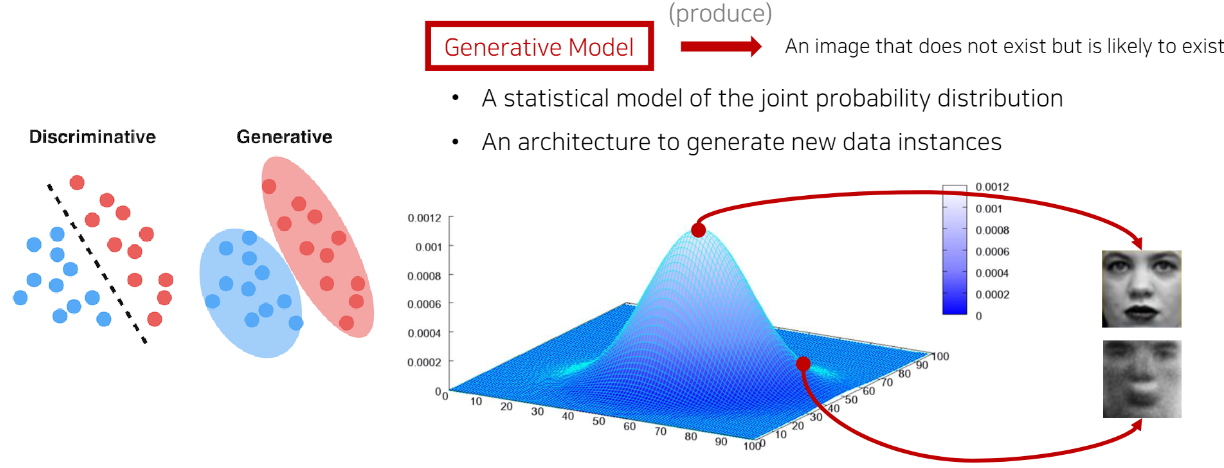
위의 사진에서 new data instance란, 이미지 한 장을 의미합니다.
생성 모델의 목표
이미지 데이터의 분포를 근사하는 모델 G를 만드는 것이 생성 모델의 목표이다. 모델 G가 잘 동작한다는 의미는 원래 이미지들의 분포를 잘 모델링할 수 있다는 것이다.
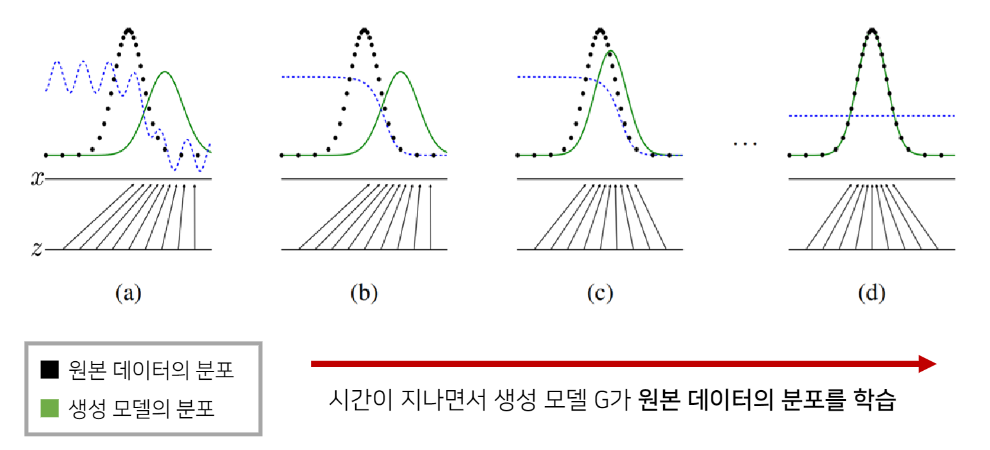
모델 G의 학습이 잘 되었다면 원본 데이터의 분포를 근사할 수 있다.
- 학습이 잘 되었다면 통계적으로 평균적인 특징을 가지는 데이터를 쉽게 생성할 수 있다.
GAN(Generative Adversarial Networks)
이름에서 적대적 네트워크가 붙어있는 이유는 생성자(generator)와 판별자(discriminator) 두 개의 네트워크를 사용하기 때문이다. 즉, GAN은 생성자와 판별자 두 개의 네티워크를 활용한 생성 모델이다.
- 생성자(G) : 학습이 다 된 이후에 사용해서 이미지를 생성할 때 사용하는 모델
- 판별자(D) : 생성자가 잘 학습할 수 있도록 도와주는 모델
결과적으로 두 개의 모델을 같이 학습시키면서 결과적으로 생성자 즉, 생성 모델을 학습시킬 수 있게 된다.

생성자는 값을 낮추고자 노력하고, 판별자는 값을 높이고자 노력하게 된다.
-
왼쪽 항
- : 원본 데이터의 distribution(분포)
- : 원본 데이터에서 한 개의 데이터(x)를 샘플링한다는 의미.
- 샘플링 할 때에, 미니배치 형식으로 여러 개를 샘플링할 수도 있다.
- : D에 x를 넣어서 값을 구한 다음 평균값을 구한다는 의미
-
오른쪽 항 (기본적으로 생성자는 노이즈 벡터로부터 새로운 입력을 받아서, 새로운 이미지 만들기 가능하다)
- : 노이즈를 샘플링할 수 있는 distribution (분포)
- : 위의 분포에서 랜덤하게 샘플링한 노이즈(z)
- : z를 토대로 가짜 이미지 생성

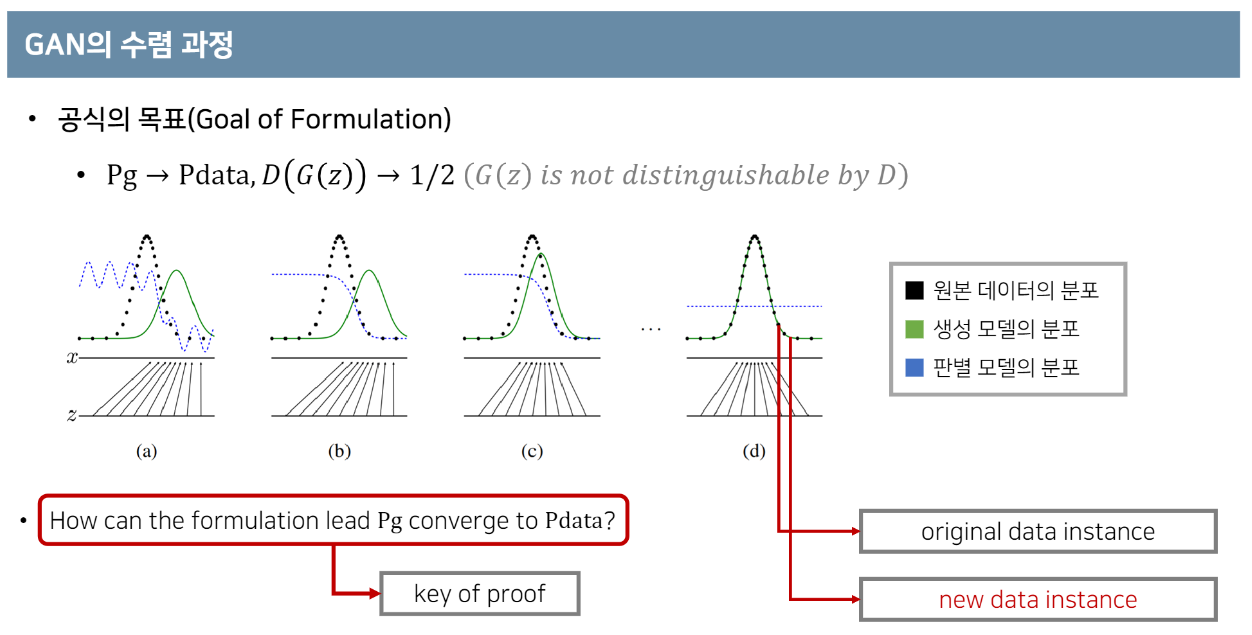

목표 : 생성자의 분포(Pg)가 원본 데이터의 분포()를 잘 따를 수 있게끔 만들어야 한다. 즉, 가 로 수렴할 수 있도록 해줘야 한다.
Discriminator는 학습이 이뤄진 뒤 가짜 이미지와 진짜 이미지를 더 이상 구분할 수 없기 때문에, 항상 1/2를 내보내게 된다.
논문의 핵심 : Pg가 어떻게 Pdata로 수렴할 수 있는가??

Global Optimality : 매 상황에 대해서 생성자와 판별자가 각각 어떤 포인트로 global optimal을 가지는 지에 대해 설명하는 것이다.G가 고정되어 있는 상황에서, D의 optimal point는 위 이미지의 'Proposition' 결과와 같다.
즉, 판별자(D)는 Pdata(x) / {Pdata(x) + Pg(x)} 의 위치에서 최댓값을 가진다!!
- 아래의 함수들이 만나는 포인트를 보면 알 수 있다. (아니면 미분을 해서 확인해보는 방법도 있다)
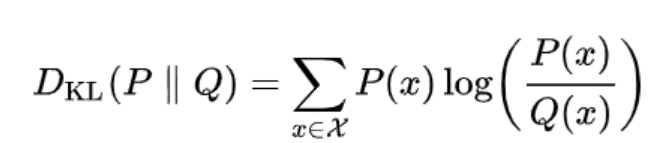
첫 번째 term과 두 번째 term은 KL divergence(쿨백 라이블러 발산)로 치환될 수 있다. (KL divergence에 대해선 아래에서 조금 더 자세히 다루도록 한다)
- JSD 값이 0 이 되면(Pdata 와 Pg가 동일), global optima는 -log(4)가 된다.
KL Divergence (쿨백-라이블러 발산)
KL divergence는 input으로 들어온 두 개의 분포가 얼마나 다른지를 측정하는 방법이다.
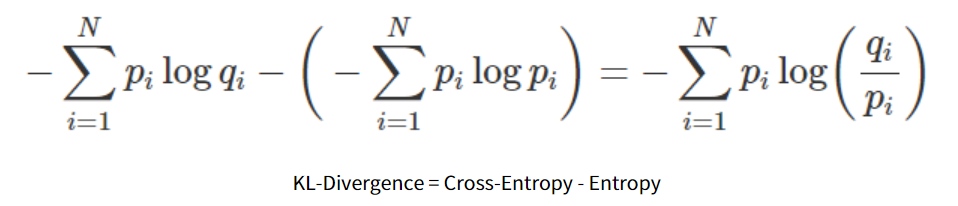
KLD (KL divergence 칭함)은 값이 낮을수록 두 분포가 유사하다라고 해석한다. (Entropy의 값이 낮을수록 랜덤성이 낮다고 해석하는 것과 비슷하다)
모델 학습에서의 KLD
보통 Classification 문제에서 Binary 또는 Categorical Cross-Entropy를 쓰는데, 사실 KLD를 사용하는 것과 동일하다고 표현해도 무방하다.
위 식에서 Entropy에 해당하는 부분은 실제 값으로 고정된 값이기에 생략할 수 있고, 실제 모델이 학습하면서 최소화할 부분은 KLD 식의 앞부분에 해당하는 Cross-Entropy 이기 때문이다.
하지만 실제 진짜를 모방하기 위해 가짜의 분포를 정말 잘 만들어내야 하는 GAN에서는 이에 대한 정보가 굉장히 중요하다.
그리고 실제 증명과정에서는 KLD는 distance matrix로 활용하기 어렵기 때문에 실제로 증명과정에서 KLD를 사용하진 않고, KLD를 거리 개념으로 해석할 수 있게 변환해준 Jensen-Shannon divergence를 사용한다.
Reference
https://www.youtube.com/watch?v=AVvlDmhHgC4
https://hwiyong.tistory.com/408
