
해당 포스트는 https://www.youtube.com/watch?v=yTSq6hJFmUg&t=193s 의 내용을 기반으로, 추가적인 기술적 해결 방안을 함께 정리한 글입니다.
MSA의 필요성
마이크로서비스 아키텍처(MSA)는 넷플릭스, 아마존, 쿠팡 같은 대규모 서비스의 성공 사례와 함께 많은 개발 조직이 관심을 갖는 아키텍처 패턴이다. 독립적인 배포, 기술 스택의 유연성, 팀 단위 자율성 등의 장점이 존재한다.
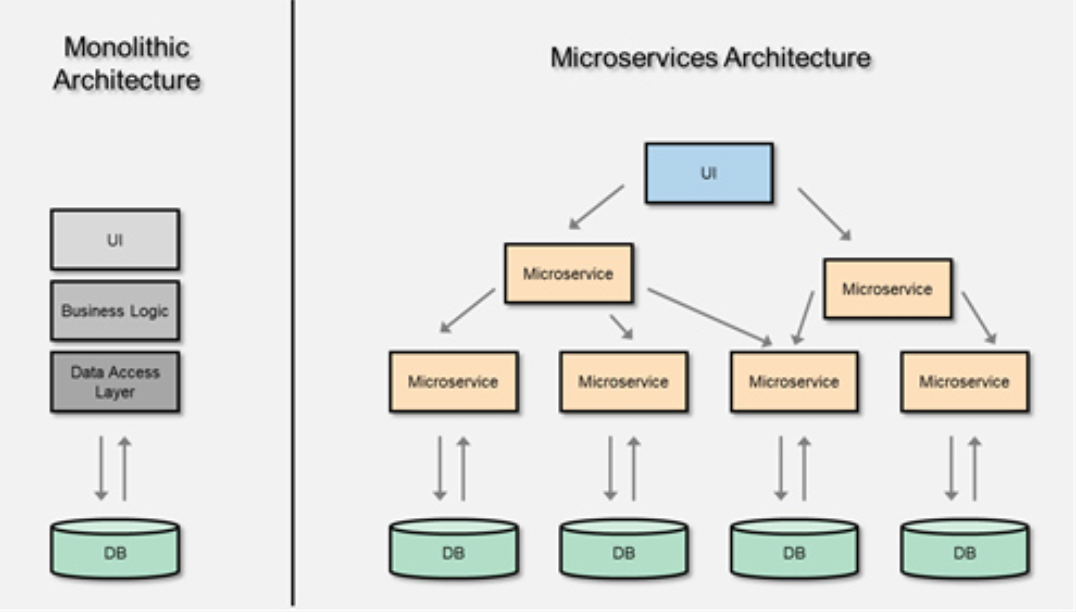
하지만 잘못 도입하면 모놀리식보다 훨씬 복잡한 분산 모놀리스(Distributed Monolith)라는 결과를 만들어낼 수 있다. MSA를 도입하기 전에 아래와 같은 신호가 있는지 먼저 점검해봐야 한다.
MSA 도입을 고려해야 하는 시점:
- 팀 규모가 커져서 하나의 코드베이스에서 동시 작업 시 충돌이 빈번해질 때
- 특정 모듈만 스케일 아웃이 필요한데 전체 애플리케이션을 통째로 확장해야 할 때
- 배포 주기가 팀 간 의존성 때문에 느려지고, 독립 배포가 필요할 때
- 장애 격리가 안 되어 하나의 버그가 전체 시스템을 다운시키는 상황이 반복될 때
이런 문제가 없다면, 모놀리식 아키텍처에서 시작해 점진적으로 전환하는 것이 훨씬 현명하다. 그럼 MSA를 도입한다고 결정했을 때, 어떤 문제들이 기다리고 있고 각각 어떻게 해결할 수 있는지 하나씩 살펴보자.
1. Managing Microservices
문제
마이크로서비스는 서비스의 경계를 어떻게 나누는지가 중요하다. 너무 잘게 나누면 수백, 수천 개의 서비스가 생겨 관리 오버헤드가 폭발적으로 증가하고, 서비스 간 API 호출이 늘어나 네트워크 지연이 생긴다. 반대로 너무 크게 나누면 모놀리식과 다를 바 없는 구조가 된다.
해결 방법
- DDD(Domain-Driven Design)의 Bounded Context 활용
- 비즈니스 도메인을 기준으로 서비스를 분리하면 의미 있는 단위로 나눌 수 있다.
- 하나의 Bounded Context가 하나의 마이크로서비스에 대응되도록 설계한다.
- 각 서비스는 자체 데이터베이스를 소유하고, 다른 서비스의 데이터에 직접 접근하지 않는다.
2. Monitoring & Logging
문제
모놀리식에서는 로그 파일로 디버깅이 가능했다. 하지만 MSA에서는 하나의 사용자 요청이 여러 서비스를 거치기 때문에, 어디서 문제가 발생했는지 추적하는 것 자체가 어려워진다. 서비스 간 의존성이 복잡해지면 예기치 못한 장애 지점을 사전에 인지하기도 힘들다.
해결 방법
- 분산 추적(Distributed Tracing) 시스템을 도입
- 모든 요청에 고유한 Trace ID를 부여하고, 서비스를 거칠 때마다 Span을 생성하여 요청의 전체 흐름을 시각화한다.
주요 도구 조합:
| 영역 | 도구 | 역할 |
|---|---|---|
| 분산 추적 | Zipkin, Jaeger | 요청 흐름 추적, 서비스 간 호출 관계 시각화 |
| 로그 수집 | ELK Stack (Elasticsearch + Logstash + Kibana) | 중앙 집중식 로그 수집 및 검색 |
| 메트릭 모니터링 | Prometheus + Grafana | CPU, 메모리, 응답 시간 등 실시간 메트릭 수집 및 대시보드 |
| 알림 | Alertmanager, PagerDuty | 임계치 초과 시 즉시 알림 |
각 서비스에서 발생하는 로그에 Trace ID를 포함시키면, 문제가 발생했을 때 해당 ID로 전체 호출 체인을 한눈에 볼 수 있다.
3. Service Discovery
문제
수많은 서비스가 여러 서버에 분산되어 있을 때, IP 주소를 하드코딩하는 방식은 서비스가 스케일 아웃되거나 재배포될 때마다 깨지게 된다.
해결 방법
서비스 디스커버리는 크게 세 가지 방식으로 접근할 수 있다.
1) Client-Side Discovery: Spring Cloud, Netflix, Eureka
[서비스 A] → [Eureka Server에서 서비스 B 위치 조회] → [서비스 B 직접 호출]각 서비스가 Eureka Server에 자신을 등록하고, 호출하는 측에서 레지스트리를 조회하여 대상 서비스의 위치를 찾는다.
2) Server-Side Discovery: API Gateway + Load Balancer
[서비스 A] → [API Gateway / Load Balancer] → [서비스 B]Spring Cloud Gateway나 Kong 같은 API Gateway가 라우팅, 로드밸런싱, 인증을 한 곳에서 처리한다.
3) Service Mesh: Istio / Linkerd
[서비스 A + Sidecar Proxy] ↔ [서비스 B + Sidecar Proxy]각 서비스 옆에 Sidecar Proxy를 배치하여 서비스 간 통신을 인프라 레벨에서 관리한다.
규모가 작다면 Eureka + API Gateway 조합으로 시작하고, 규모가 커지면 Service Mesh로 전환하는 것이 좋다.
4. Authentication & Authorization
문제
서비스 간 통신이 늘어나면, 아무 서비스나 다른 서비스의 API를 호출하거나 메시지 큐에 임의의 메시지를 넣는 등의 악용이 가능해진다. 외부 사용자에 대한 인증뿐 아니라, 서비스 간 내부 통신에 대한 인증 및 인가도 반드시 필요하다.
해결 방법
- API Gateway에서의 중앙 인증 + JWT 토큰 전파 방식이 가장 보편적
[클라이언트] → [API Gateway: JWT 검증] → [서비스 A: JWT에서 권한 확인] → [서비스 B: JWT 전파]동작 흐름:
1. 클라이언트가 로그인하면 API Gateway(또는 Auth 서비스)에서 JWT 토큰을 발급한다.
2. 이후 모든 요청은 JWT를 헤더에 포함하여 전달한다.
3. 각 서비스는 JWT의 서명을 검증하고, 토큰에 포함된 권한(scope/role)을 확인한다.
4. 서비스 간 내부 호출 시에도 JWT를 전파하거나, 별도의 서비스 간 인증(mTLS)을 적용한다.
서비스 간 통신 보안 강화:
- mTLS(mutual TLS): 서비스 메시를 사용하면 서비스 간 모든 통신을 자동으로 암호화하고 상호 인증 가능
- OAuth 2.0 Client Credentials Grant: 서비스가 다른 서비스를 호출할 때 사용하는 별도의 인증 흐름
5. Configuration Management
문제
각 서비스는 데이터베이스 접속 정보, API 키, 캐시 설정, 큐 연결 정보 등 다양한 설정값과 secrets를 관리해야 한다. 서비스마다 자체적으로 구성을 저장하면 코드베이스에 secrets가 노출되거나, 설정 변경 시 모든 서비스를 재배포해야 하는 문제가 발생한다.
해결 방법
- 중앙 집중식 구성 관리 시스템을 도입
| 도구 | 특징 |
|---|---|
| Spring Cloud Config | Git 저장소 기반, Spring 생태계와 자연스러운 통합 |
| HashiCorp Vault | Secrets 관리에 특화, 동적 자격증명 발급, 자동 만료 |
| AWS Parameter Store / Secrets Manager | AWS 환경에서 IAM 기반 접근 제어와 자동 로테이션 |
핵심 원칙:
- 환경별(dev/staging/prod) 설정을 분리하되, 하나의 시스템에서 중앙 관리한다.
- Secrets는 반드시 암호화된 저장소에 보관하고, 애플리케이션 코드와 분리한다.
- 가능하다면 서비스 재시작 없이 설정을 실시간으로 반영(Hot Reload)할 수 있어야 한다.
6. Fault Tolerance
문제
마이크로서비스 아키텍처는 구성 요소가 많아 장애 발생 확률이 높다. 하나의 서비스 장애가 연쇄적으로 전파되어 전체 시스템이 다운되는 Cascading Failure가 MSA에서 가장 위험한 상황이다.
해결 방법
- Circuit Breaker 패턴을 도입하여 연쇄 장애를 예방
정상 상태 [Closed] → 실패 임계치 초과 → 차단 상태 [Open] → 일정 시간 후 → 반개방 [Half-Open] → 성공 시 → [Closed]Resilience4j를 활용한 구현:
@CircuitBreaker(name = "paymentService", fallbackMethod = "paymentFallback")
@Retry(name = "paymentService")
@TimeLimiter(name = "paymentService")
public CompletableFuture<PaymentResponse> processPayment(PaymentRequest request) {
return CompletableFuture.supplyAsync(() ->
paymentClient.requestPayment(request)
);
}
public CompletableFuture<PaymentResponse> paymentFallback(PaymentRequest request, Throwable t) {
// 결제 서비스 장애 시 대체 로직
return CompletableFuture.completedFuture(
PaymentResponse.pending("결제 서비스 일시 장애, 재시도 예정")
);
}추가적인 Fault Tolerance 전략:
- Bulkhead 패턴: 서비스별로 스레드 풀을 격리하여 하나의 느린 서비스가 전체 스레드를 점유하는 것을 방지
- 비동기/이벤트 기반 통신: 동기식 HTTP 호출 대신 메시지 브로커(Kafka, RabbitMQ)를 활용하면, 한 서비스의 장애가 다른 서비스에 즉각적인 영향을 미치지 않는다.
- Timeout 설정: 모든 외부 호출에 적절한 타임아웃을 반드시 설정한다.
7. Data Consistency
문제
MSA에서 각 서비스가 자체 데이터베이스를 소유하면, 모놀리식에서 당연하게 사용하던 단일 트랜잭션이 불가능해진다. 예를 들어, "주문 생성 → 결제 처리 → 재고 차감"이 하나의 트랜잭션으로 묶이지 않기 때문에 중간에 실패하면 데이터 불일치가 발생한다.
해결 방법
- Saga 패턴을 통해 분산 트랜잭션을 관리
Choreography 방식 (이벤트 기반):
[주문 서비스] --주문 생성 이벤트--> [결제 서비스] --결제 완료 이벤트--> [재고 서비스]
↓ 결제 실패 시
결제 실패 이벤트--> [주문 서비스: 주문 취소 보상 트랜잭션]Orchestration 방식:
[Saga Orchestrator] → 1. 주문 생성 요청 → [주문 서비스]
→ 2. 결제 요청 → [결제 서비스]
→ 3. 재고 차감 요청 → [재고 서비스]
→ 실패 시 역순으로 보상 트랜잭션 실행- 모든 시점에서 데이터가 완벽하게 일치하지 않더라도, 최종적으로는 일관된 상태에 도달하도록 설계한다.
- 이를 보완하기 위해 Outbox 패턴(DB 변경과 이벤트 발행을 하나의 로컬 트랜잭션으로 묶는 방식)을 함께 적용하면 이벤트 유실을 방지할 수 있다.
8. Testing
문제
마이크로서비스 환경에서 테스트는 단일 서비스 테스트만으로는 충분하지 않다. 서비스가 연관된 기능을 통합 테스트하려면 해당 서비스들과 각각의 인프라를 모두 띄워야 하며, 상당한 비용과 시간이 소요된다.
해결 방법
- 테스트 전략을 MSA에 맞게 확장
* E2E 테스트 ← 최소한으로 (비용 높음)
* 통합 테스트 ← 핵심 시나리오 위주
* 계약 테스트 ← 서비스 간 API 호환성 검증
* 컴포넌트 테스트 ← 단일 서비스 + 외부 의존성 Mock
* 단위 테스트 ← 가장 많이 (비용 낮음)계약 테스트(Contract Test): Spring Cloud Contract나 Pact 같은 도구를 사용하면, 서비스 간 API 스펙이 변경될 때 의존하는 서비스가 깨지는 것을 사전에 감지할 수 있다.
Testcontainers를 활용하면 Docker 기반으로 테스트에 필요한 데이터베이스, Redis, Kafka 등을 코드에서 직접 띄우고 관리할 수 있어 통합 테스트의 부담을 줄일 수 있다.
9. Dependency Management
문제
MSA에서의 의존성은 세 가지 차원에서 복잡성을 만든다.
- 서비스 의존성: 서비스 A → 서비스 B → 서비스 C로 동기적으로 연결된 경우, C의 장애가 A까지 연쇄적으로 전파된다.
- 라이브러리 의존성: 공통 유틸리티를 내부 라이브러리로 만들어 공유할 때, 라이브러리 업데이트 시 하위 호환성이 깨지면 의존하는 모든 서비스가 영향을 받는다.
- 데이터 의존성: 다른 서비스가 생성한 데이터에 의존하는 경우, 데이터 스키마 변경이 연쇄적인 문제를 유발한다.
해결 방법
- 서비스 의존성: 비동기 이벤트 기반 통신으로 전환하여 동기적 결합도를 낮춘다. 불가피한 동기 호출에는 Circuit Breaker와 Fallback을 적용
- 라이브러리 의존성: Semantic Versioning(의존성 관리)을 엄격히 준수한다. 가능하다면 공유 라이브러리를 최소화하고 각 서비스의 독립성을 우선한다.
- 데이터 의존성: 서비스 간 데이터 공유 시 이벤트를 통한 데이터 복제(CQRS 패턴)를 사용하고, API 스펙 변경 시 API Versioning으로 하위 호환성을 보장한다.
10. Deployment Strategy
문제
서비스가 수십 개로 늘어나면 각각의 CI/CD 파이프라인을 관리해야 하고, 서비스 간 API 호환성을 유지하면서 독립 배포해야 하는 복잡성이 생긴다.
해결 방법
배포 방식 선택:
- Blue/Green 배포: 새 버전을 기존 환경과 동일하게 구성한 뒤, 트래픽을 한 번에 전환한다. 문제 발생 시 즉시 롤백 가능하다.
- Canary 배포: 새 버전에 소량의 트래픽만 먼저 보내 문제가 없는지 확인 후 점진적으로 확대한다. Kubernetes의 경우 Argo Rollouts로 자동화할 수 있다.
- Rolling 배포: 인스턴스를 하나씩 순차적으로 교체한다. 가장 일반적이지만 배포 중 구/신 버전이 공존하는 구간이 있다.
API Versioning을 통해 서비스 간 호환성을 관리한다. 새 API 버전을 배포하더라도 기존 버전을 일정 기간 유지하면 의존하는 서비스들이 순차적으로 마이그레이션할 수 있다.
마무리
MSA는 특정 문제를 해결하기 위한 아키텍처 도구이지, 그 자체가 목표가 되어서는 안 된다.
| 과제 | 핵심 해결 도구 |
|---|---|
| 서비스 관리 | DDD Bounded Context, Database per Service |
| 모니터링/로깅 | Zipkin/Jaeger, ELK Stack, Prometheus + Grafana |
| 서비스 디스커버리 | Eureka, Spring Cloud Gateway, Istio |
| 인증/인가 | JWT + API Gateway, mTLS, OAuth 2.0 |
| 구성 관리 | Spring Cloud Config, Vault, AWS Secrets Manager |
| 장애 허용 | Circuit Breaker (Resilience4j), Bulkhead, 비동기 통신 |
| 데이터 일관성 | Saga 패턴, Eventual Consistency, Outbox 패턴 |
| 테스트 | Contract Test, Testcontainers |
| 의존성 관리 | Semantic Versioning, API Versioning, 이벤트 기반 통신 |
| 배포 | Blue/Green, Canary, Argo Rollouts |
