해당 정리는 유튜브
당근 채팅 시스템은 어떻게 만들까? | 2024 당근 테크 밋업
https://www.youtube.com/watch?v=_F6k0tg8ODo&t=1105s
를 기반으로 정리한 내용입니다.
채팅 시스템은 어떻게 전달 될까
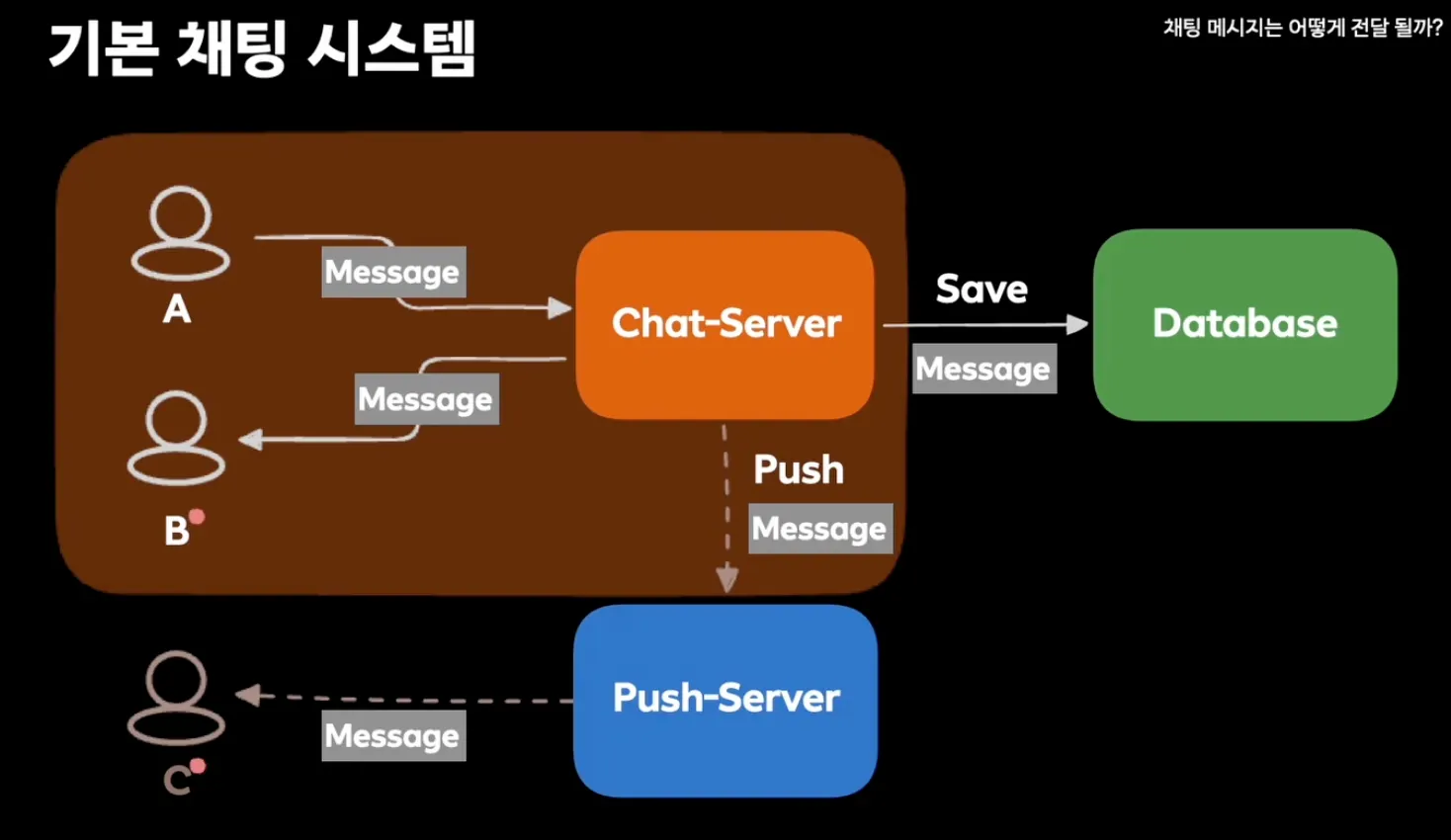
- 컴포넌트 정리: Chat-Server, Push-Server, Database
순서 정리
- A가 Chat-Server에 메시지 전달
- DB에 저장
- B에게 메시지 전달
- Push서버에 메시지 전달 이후 사용자에게 푸시알림 제공
서버가 1대만 있을 때 1:1 채팅
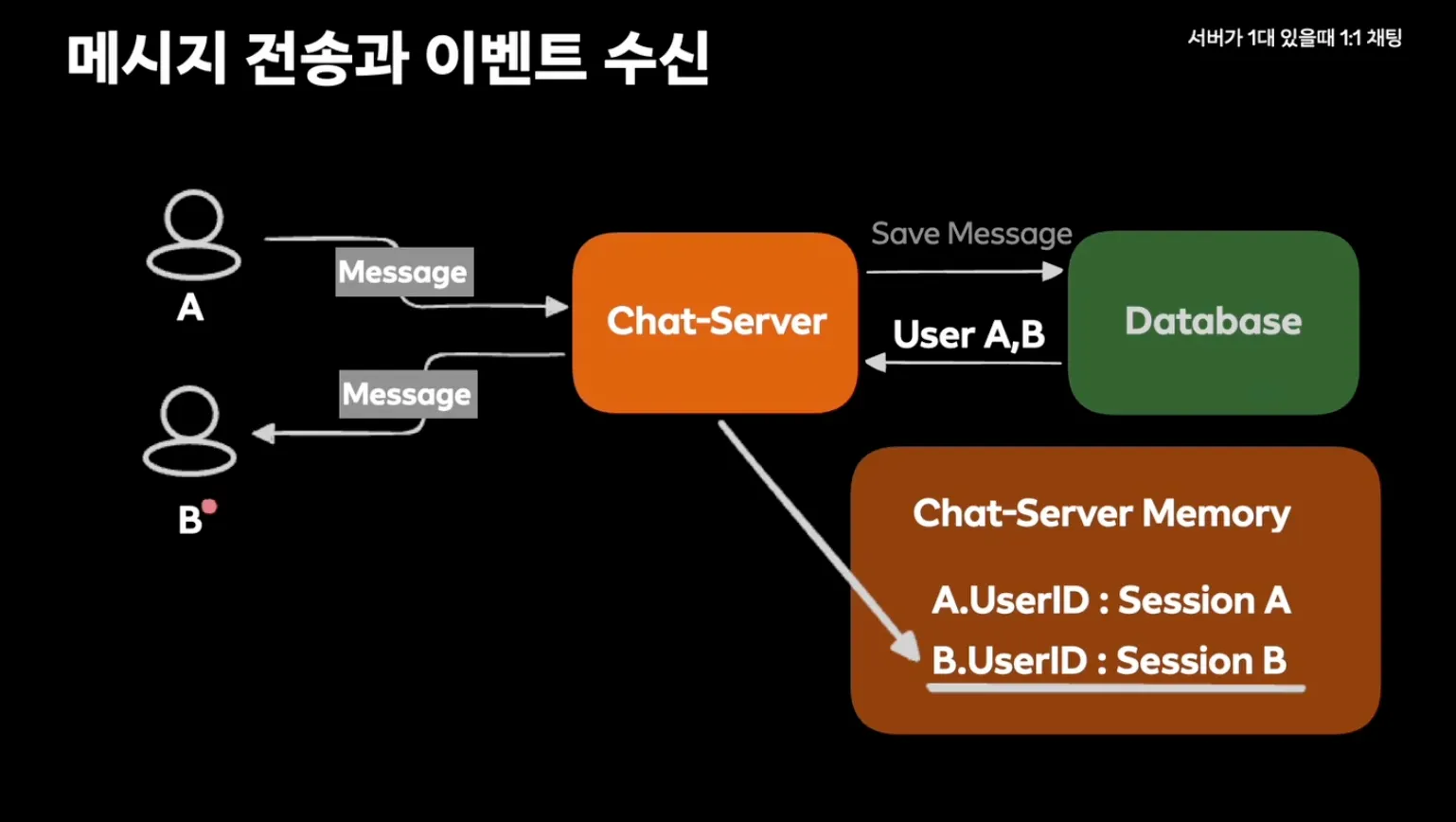
순서 정리
- A가 메시지 전달
- DB에서 유저 리스트 반환
- 메모리에서 현재 접속중인 사용자 확인 → 발신자 제외 나머지 멤버들에게 메시지 전달
Chat-Server Memory: 해당 채팅 서버만 접근 가능한 메모리
서버가 2대로 늘어난다면?
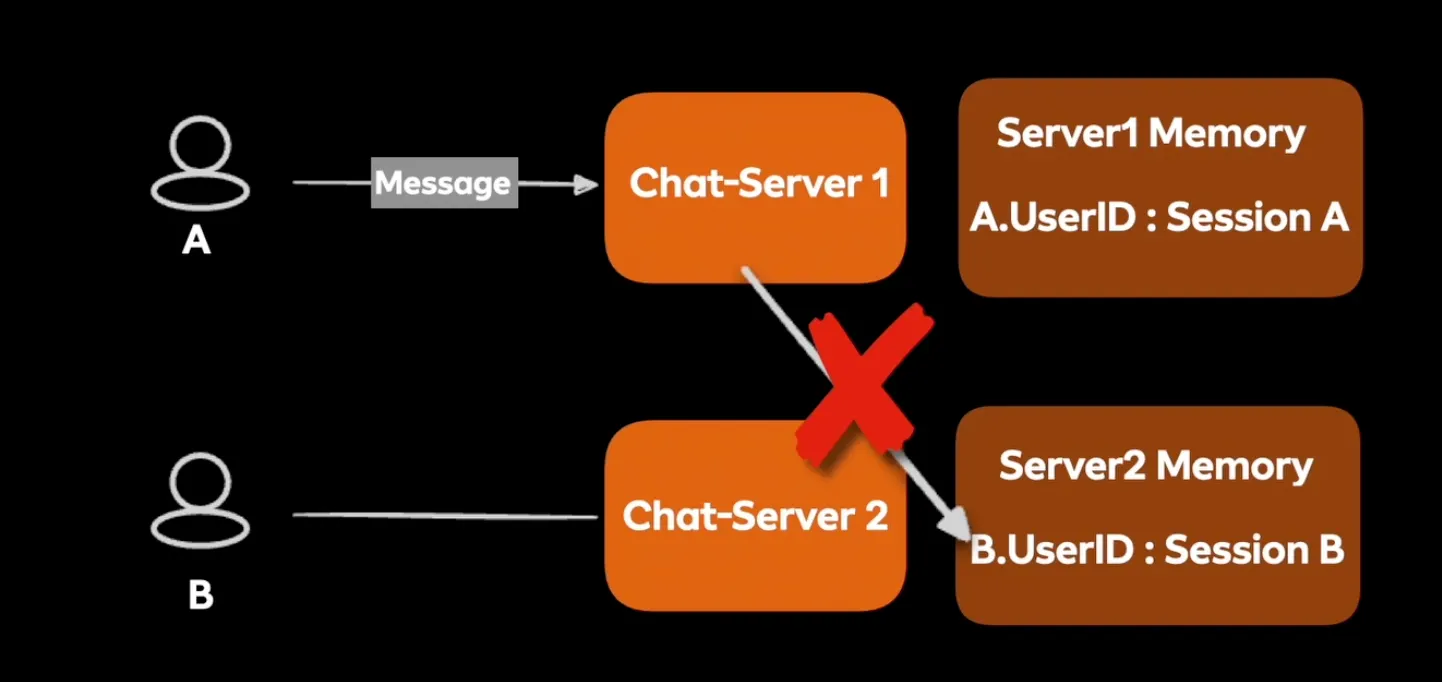
- 메모리 불일치 발생
- 해결방법1: 공유 메모리를 활용
- 해결방법2: Pub Sub 구조 활용
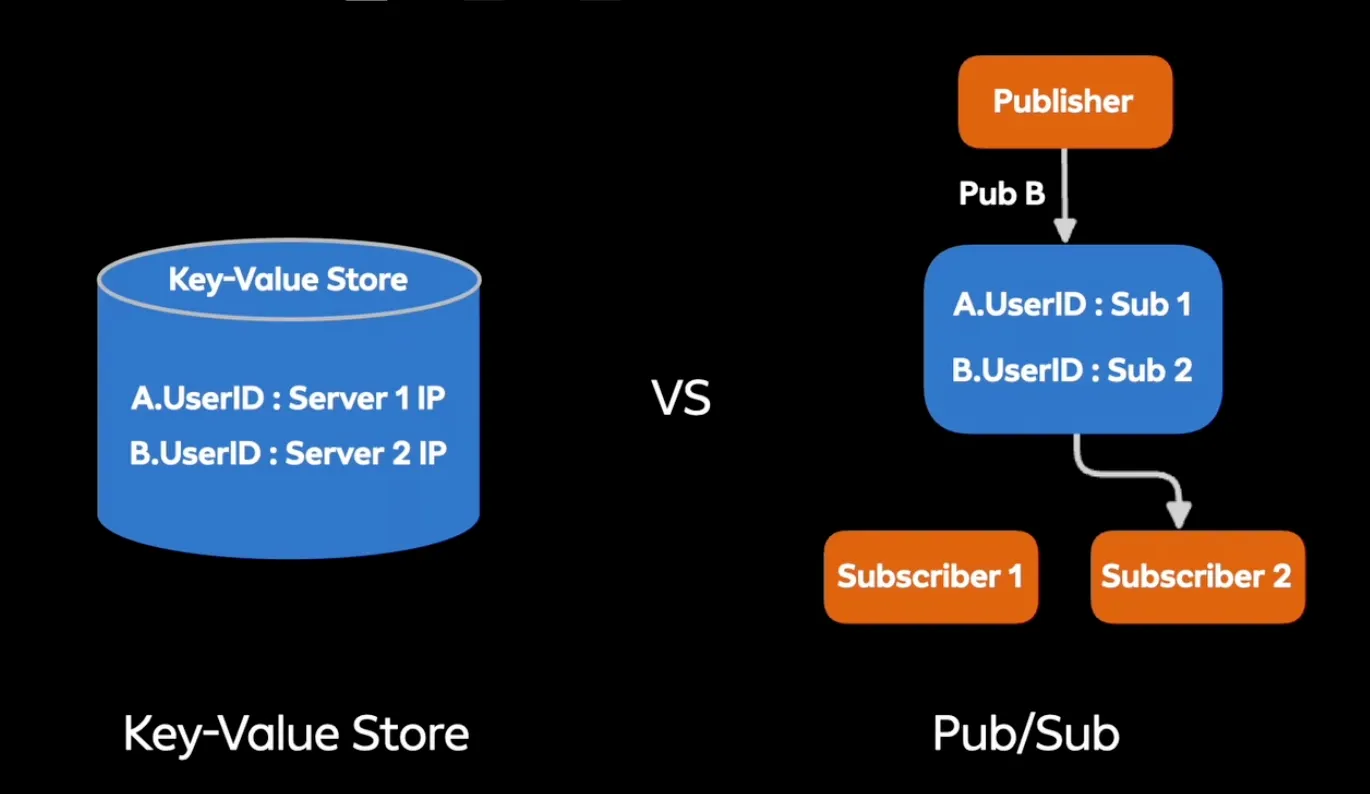
- 이번 세션에서는 공유 메모리만 다룬다
유저가 접속한 서버 IP 저장
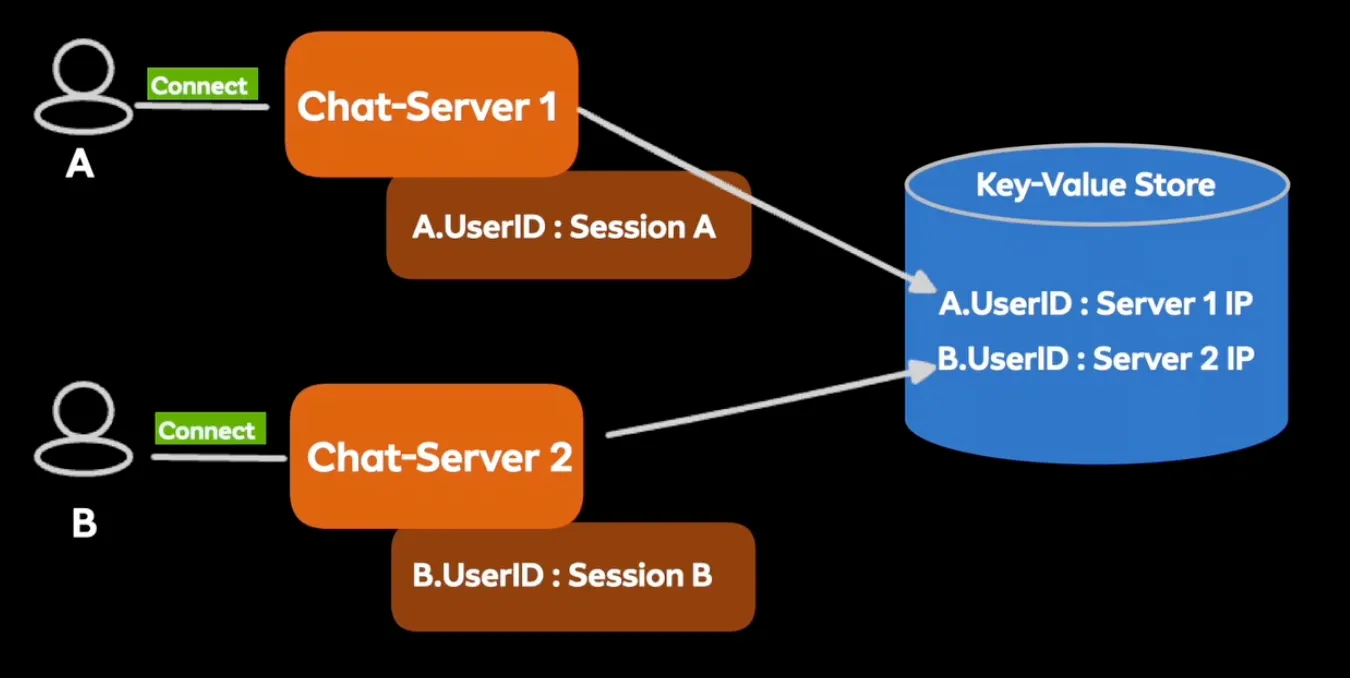
- 사용자 채팅방 입장 시 공유 메모리에 각 채팅서버 IP를 저장
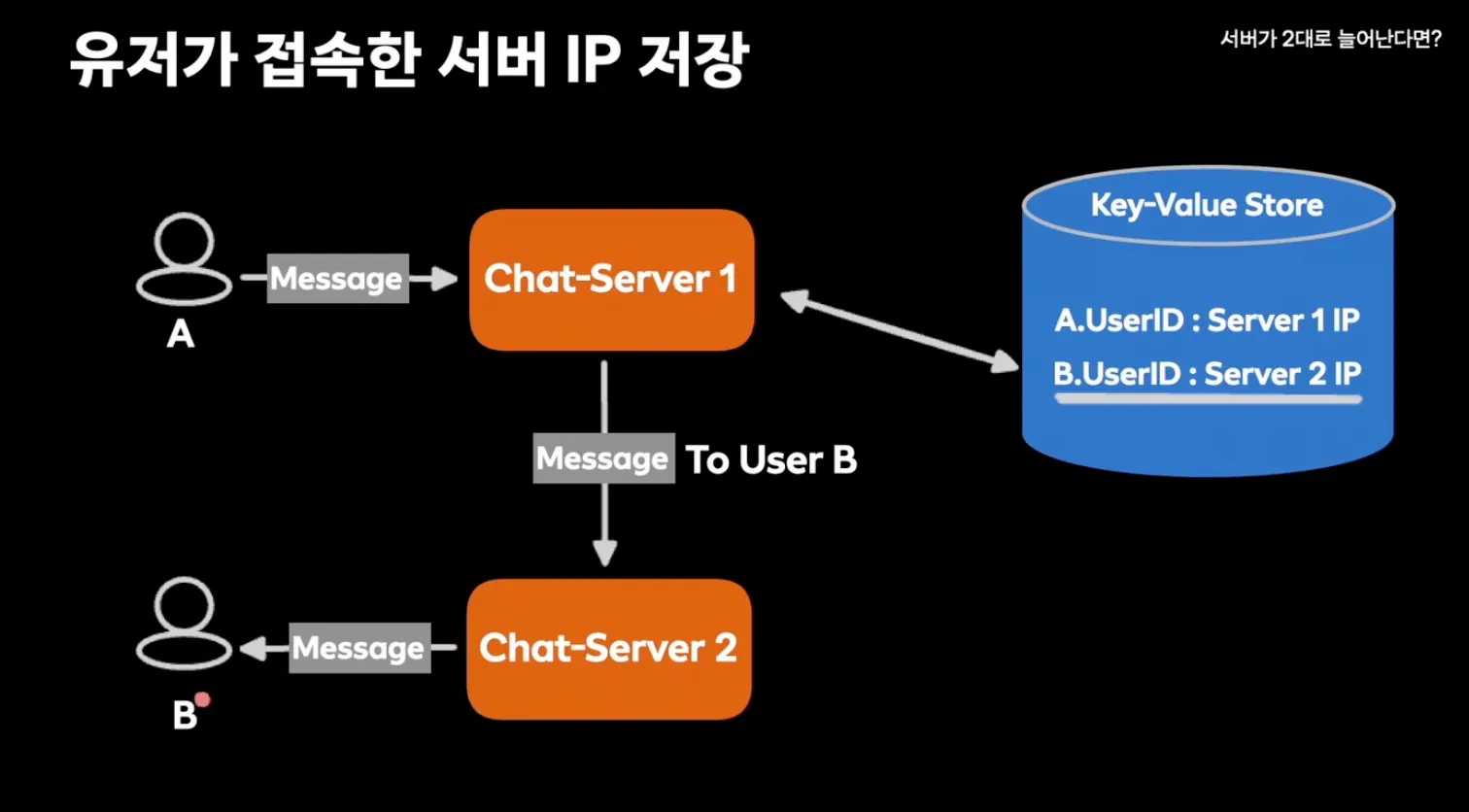
- A가 메시지를 보내면 공유 메모리에서 서버가 유저 B의 IP를 확인해서 메시지를 전달한다
서버가 10대로 늘어난다면?
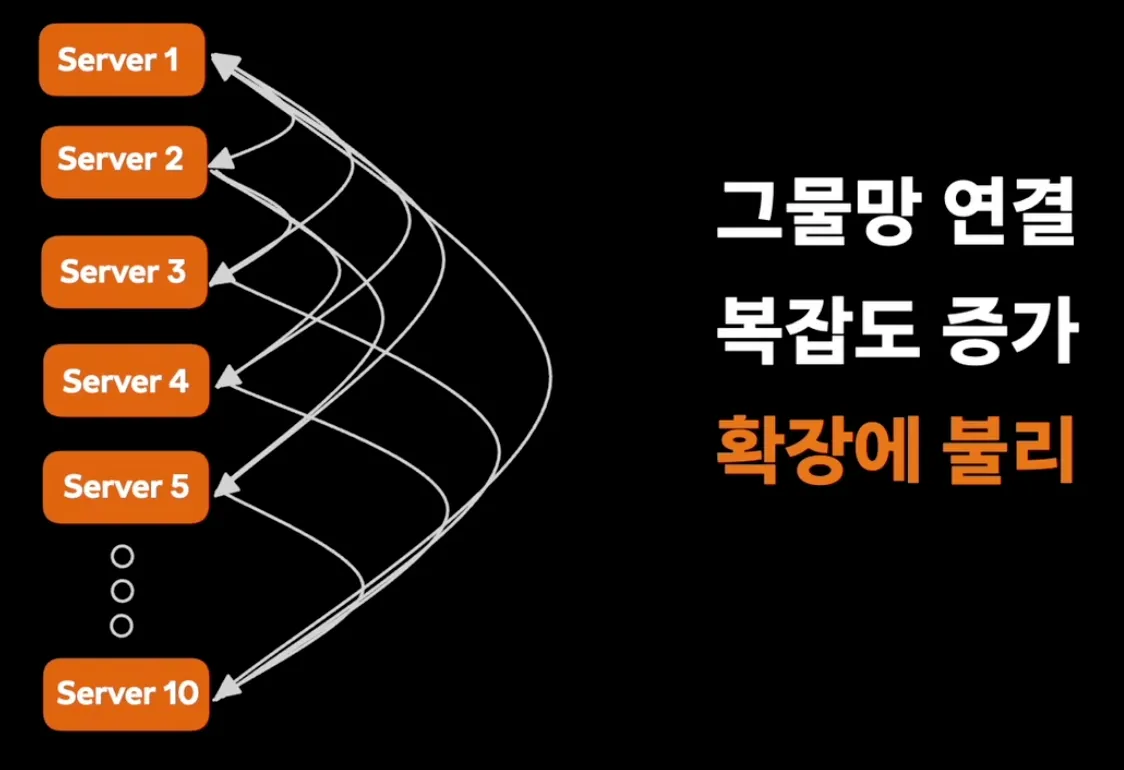
- 해결방법: Message Queue + Consumer를 활용한 서버 간 비동기 처리로 진행
- Message Queue: 메시지를 하나씩 저장
- Consumer: 메시지를 하나씩 꺼내서 처리하는 작업자
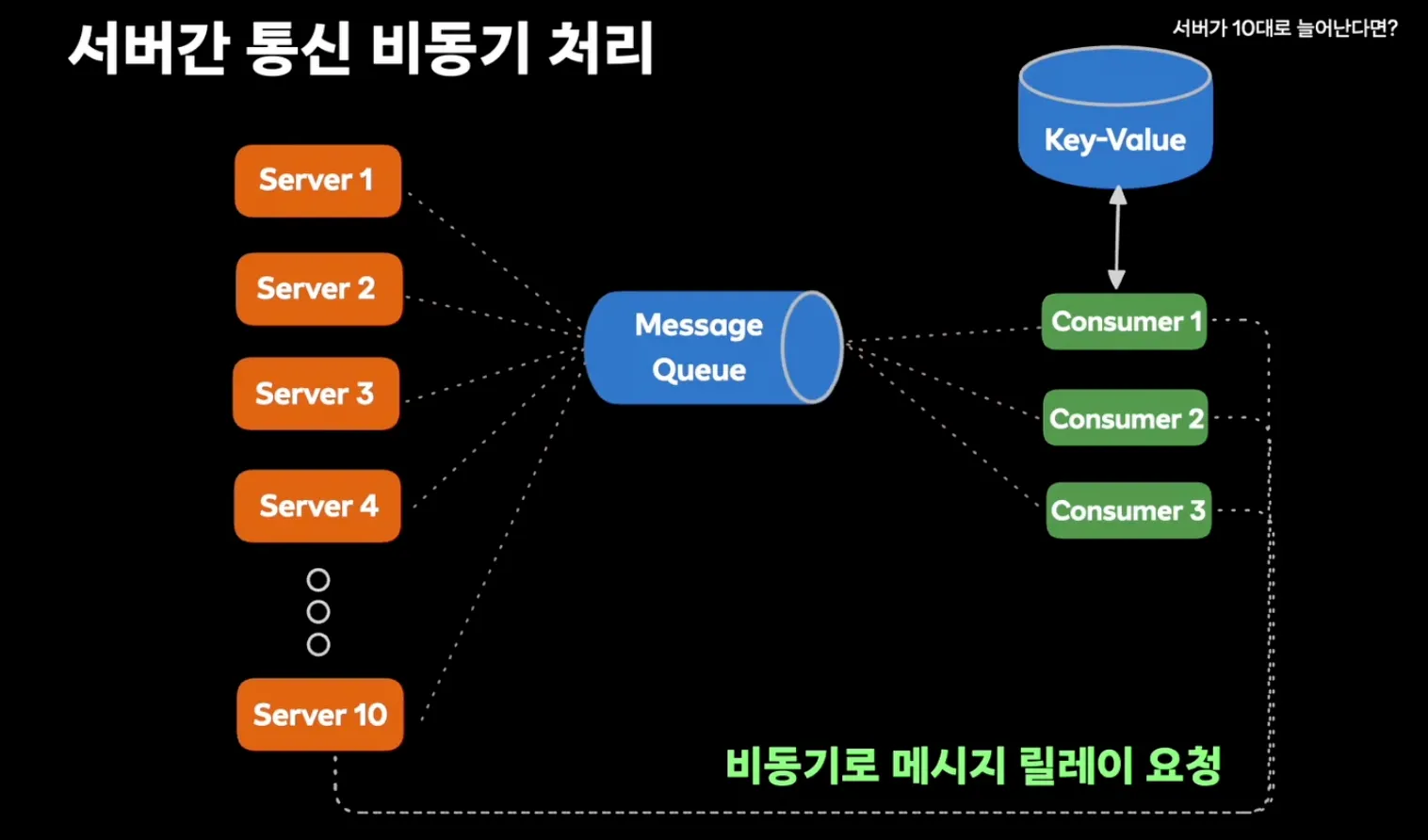
- 서버가 메시지를 입력하면 Message Queue에 메시지 저장
- Consumer가 메시지를 하나씩 빼서 공유 메모리 확인 후 각 서버에 전달
- → 서버가 하던 일을 Consumer에게 위임
푸시는 언제 보내야 할까요
- 미접속 유저
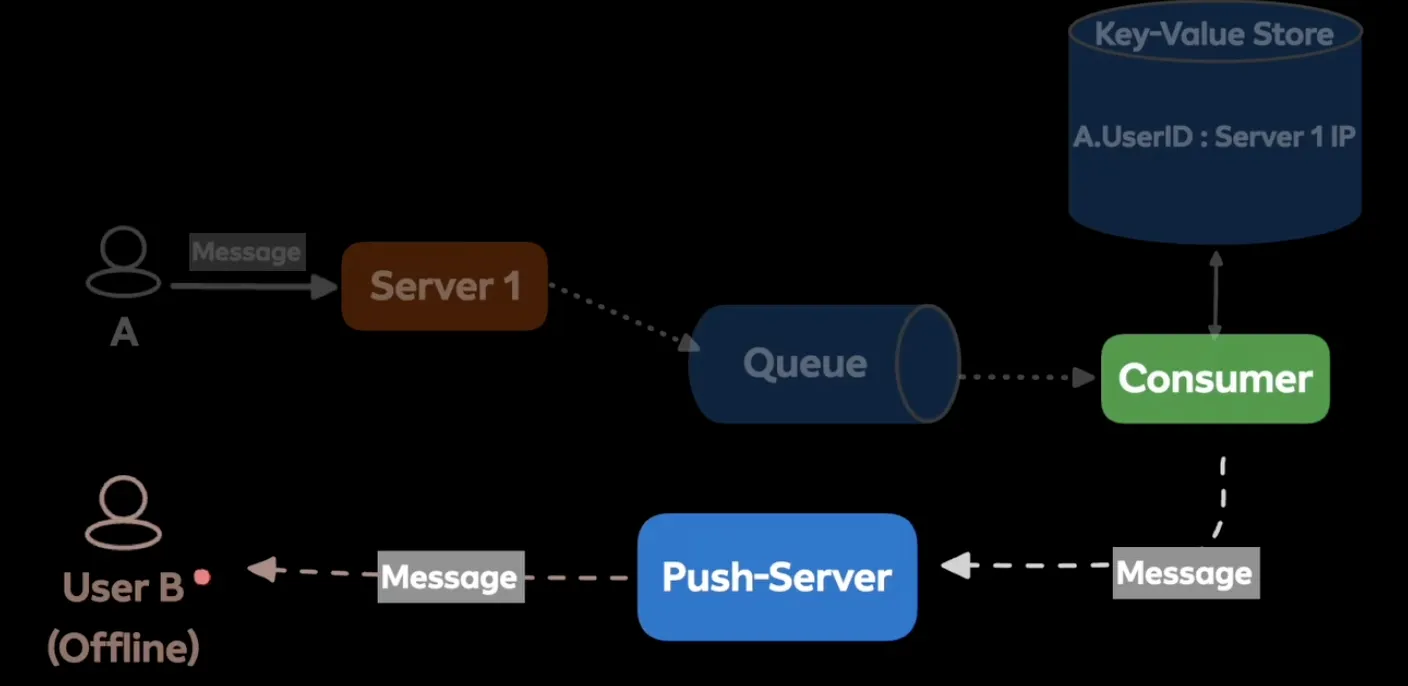
- Consumer는 공유 메모리를 통해 유저가 접속중이 아닌 사실을 확인
- 잘못된 데이터
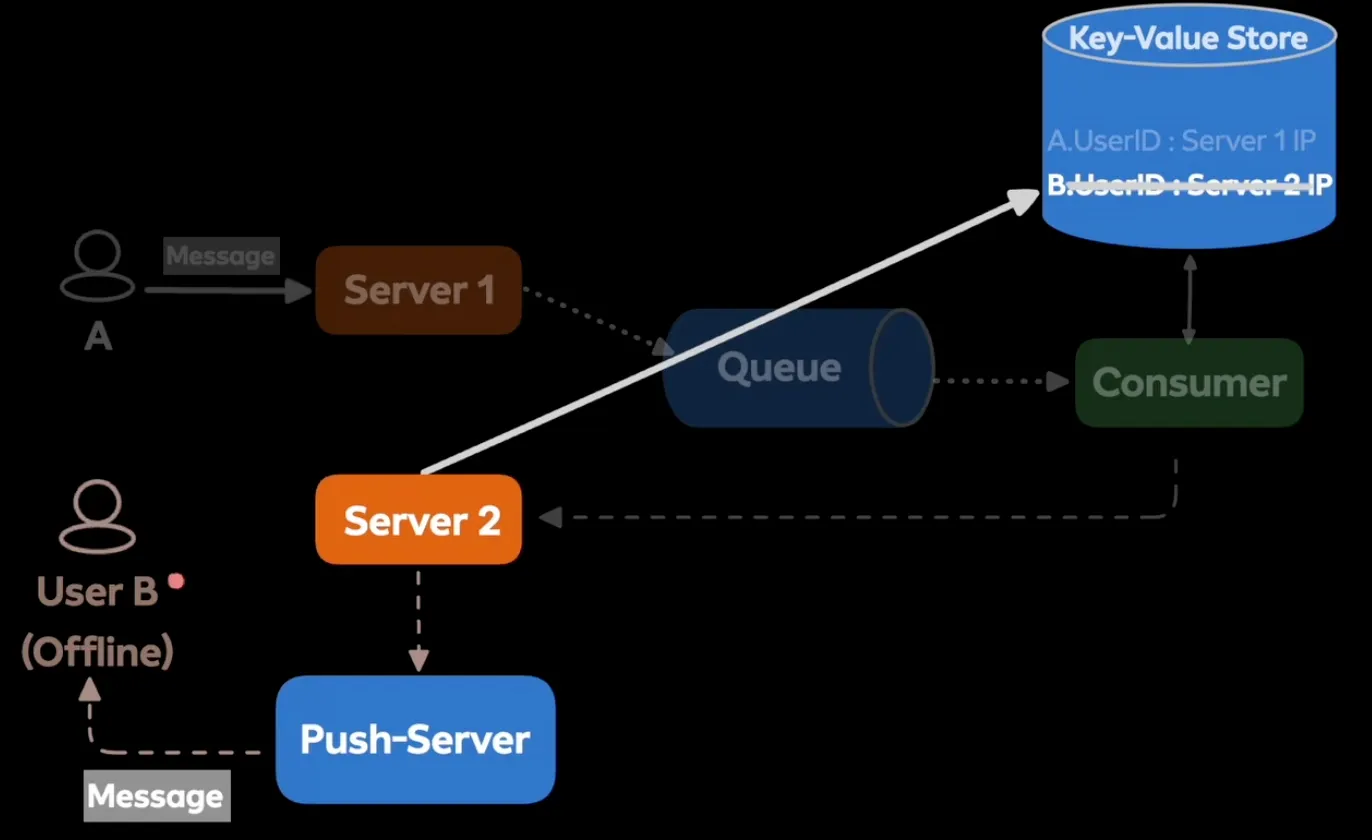
- 공유 메모리에 잘못된 데이터가 저장돼있을 경우
- 서버 내에서 푸시 서버로 전달
- 공유 메모리 완전 신뢰 x, 클라이언트 연결이 정상 종료되지 않고 서버 다운시 해당 상황 발생 가능
당근 사장님 프로필 1:1 채팅
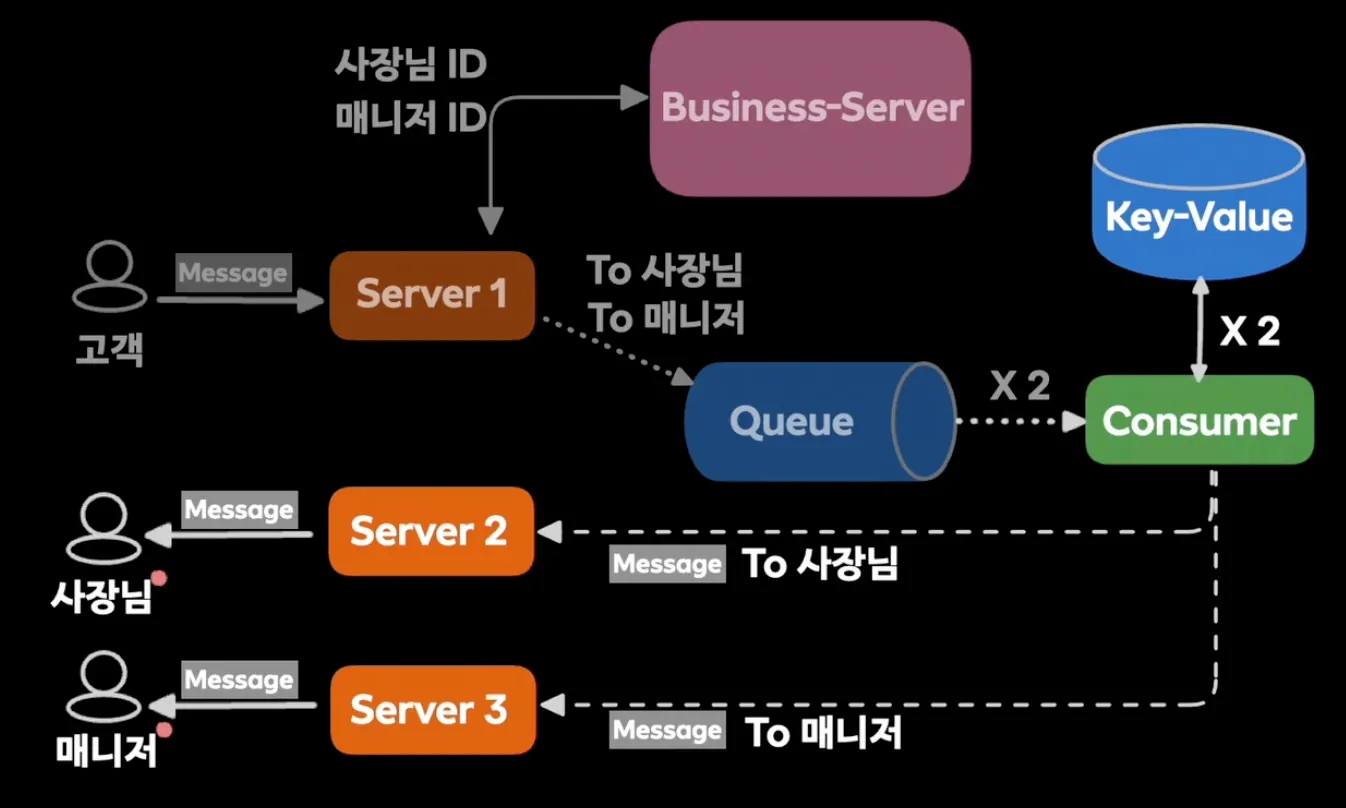
- 고객(1)이 메시지를 보내면 사장님과 매니저가 수신
당근 모임 그룹채팅
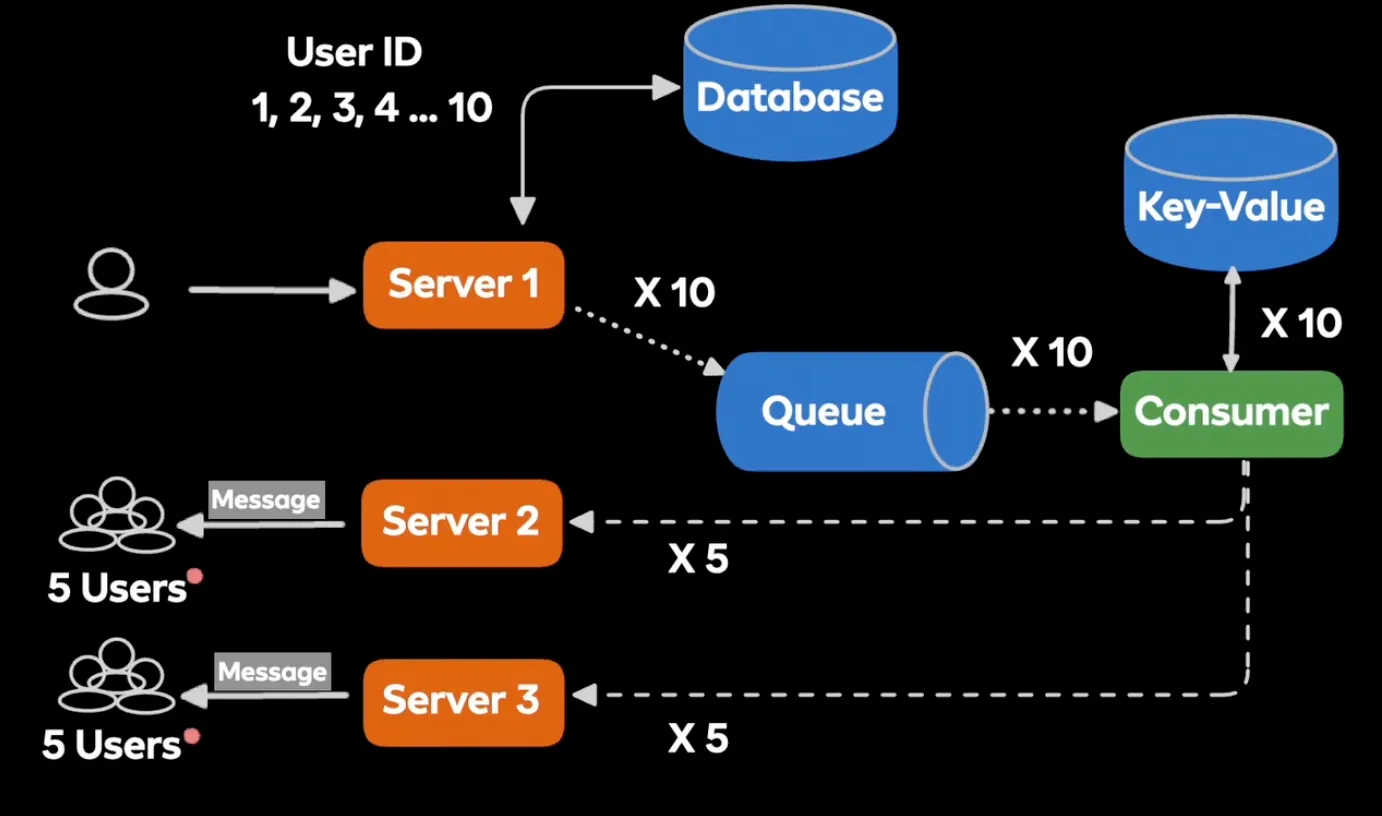
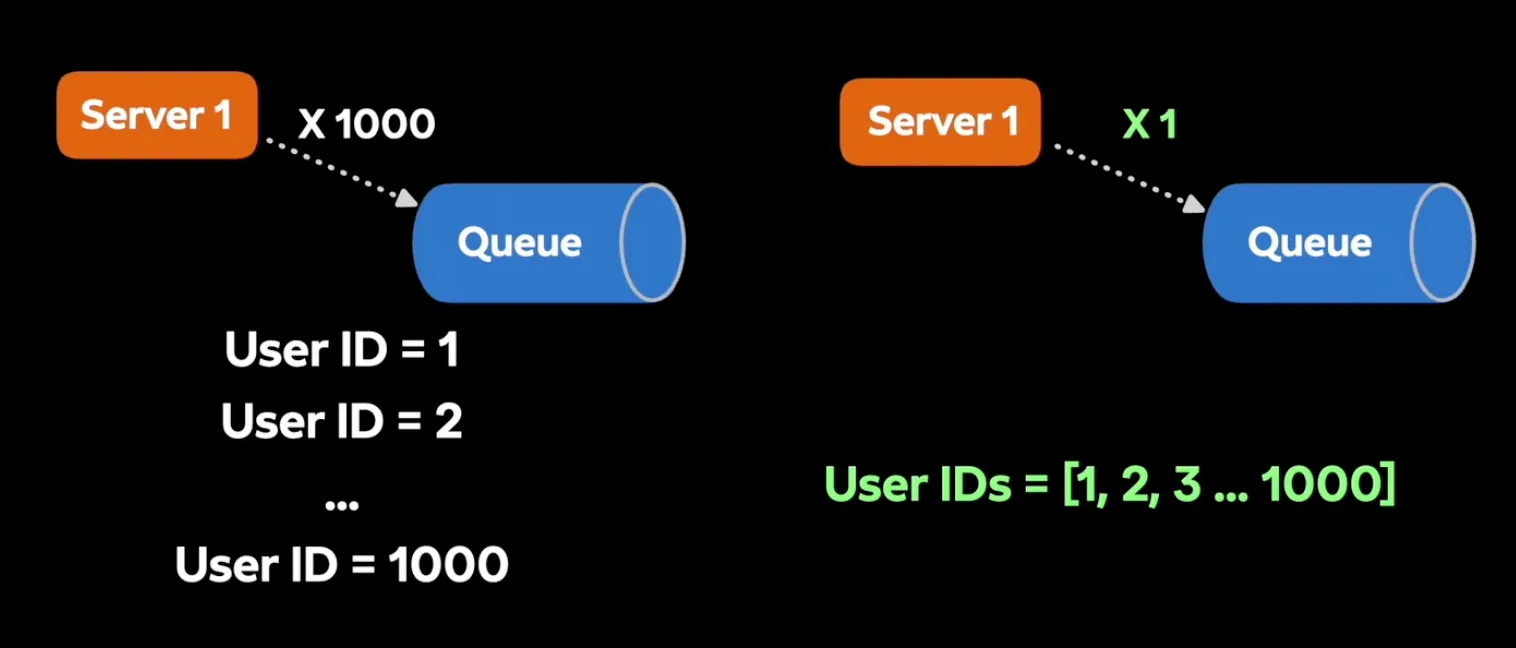
- 인원이 1000명으로 늘어난다면 → 요청을 1000번 진행하는 문제가 발생
- 해결방법: User ID를 묶어서 요청하자
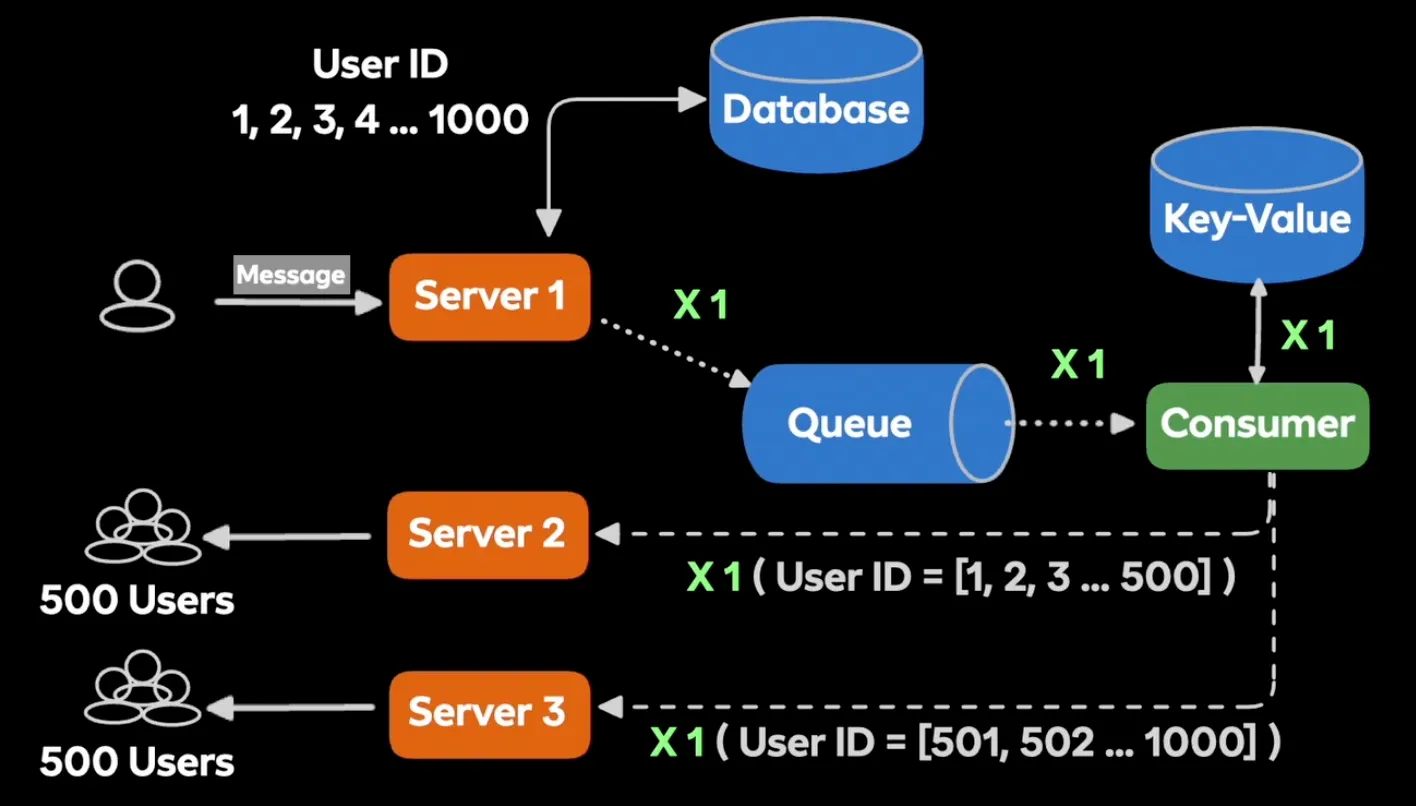
- Pub Sub을 사용하지 않고 Key-value를 사용한 이유
- → Pub Sub은 묶어서 처리가 불가능하다
- 한 번에 너무 많은 작업을 처리하면 시간이 오래 걸리지 않을까요?
→ 해결방법: 유저 ID를 청크 단위로 나누자
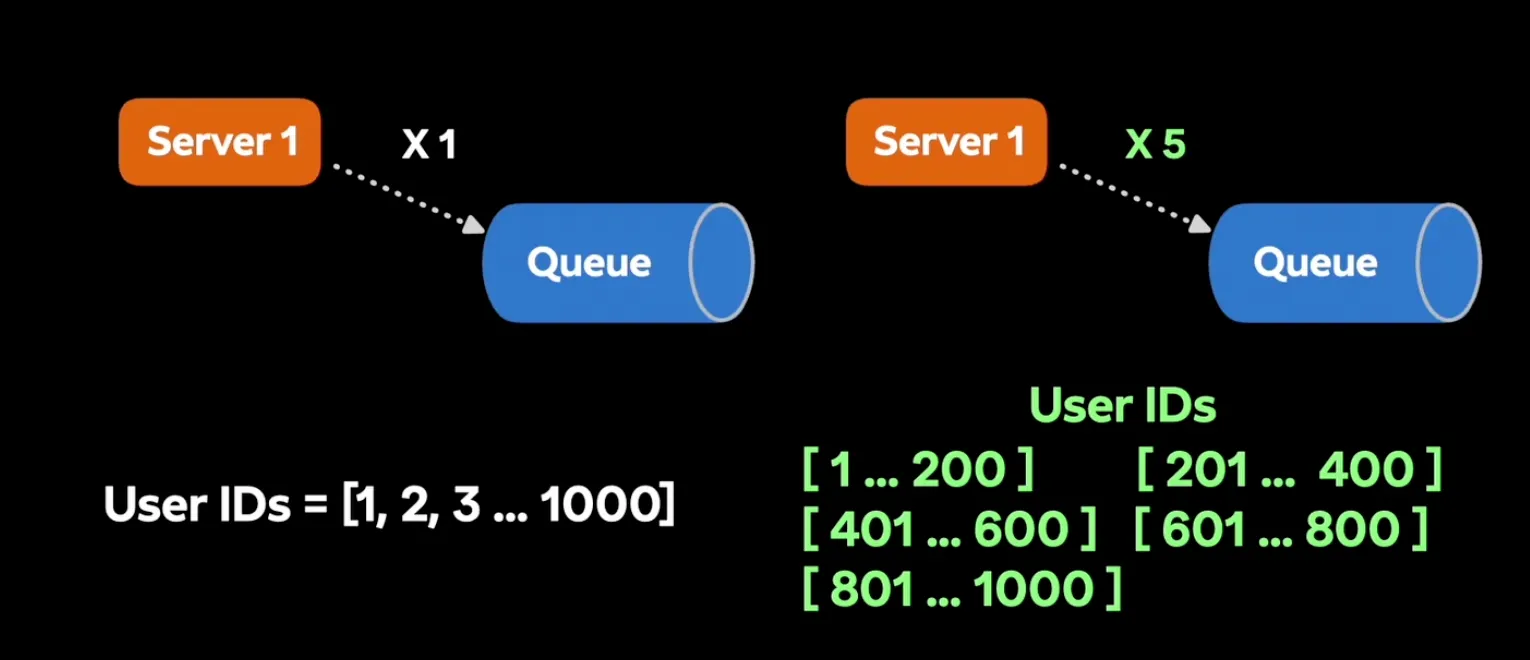
- 어느 유저가 어디 서버에 있는지 바로 알 수 있다
- 보내는 빈도수가 늘어나긴 하지만, 유저의 위치를 찾는 프로세싱 시간 단축 가능
최종
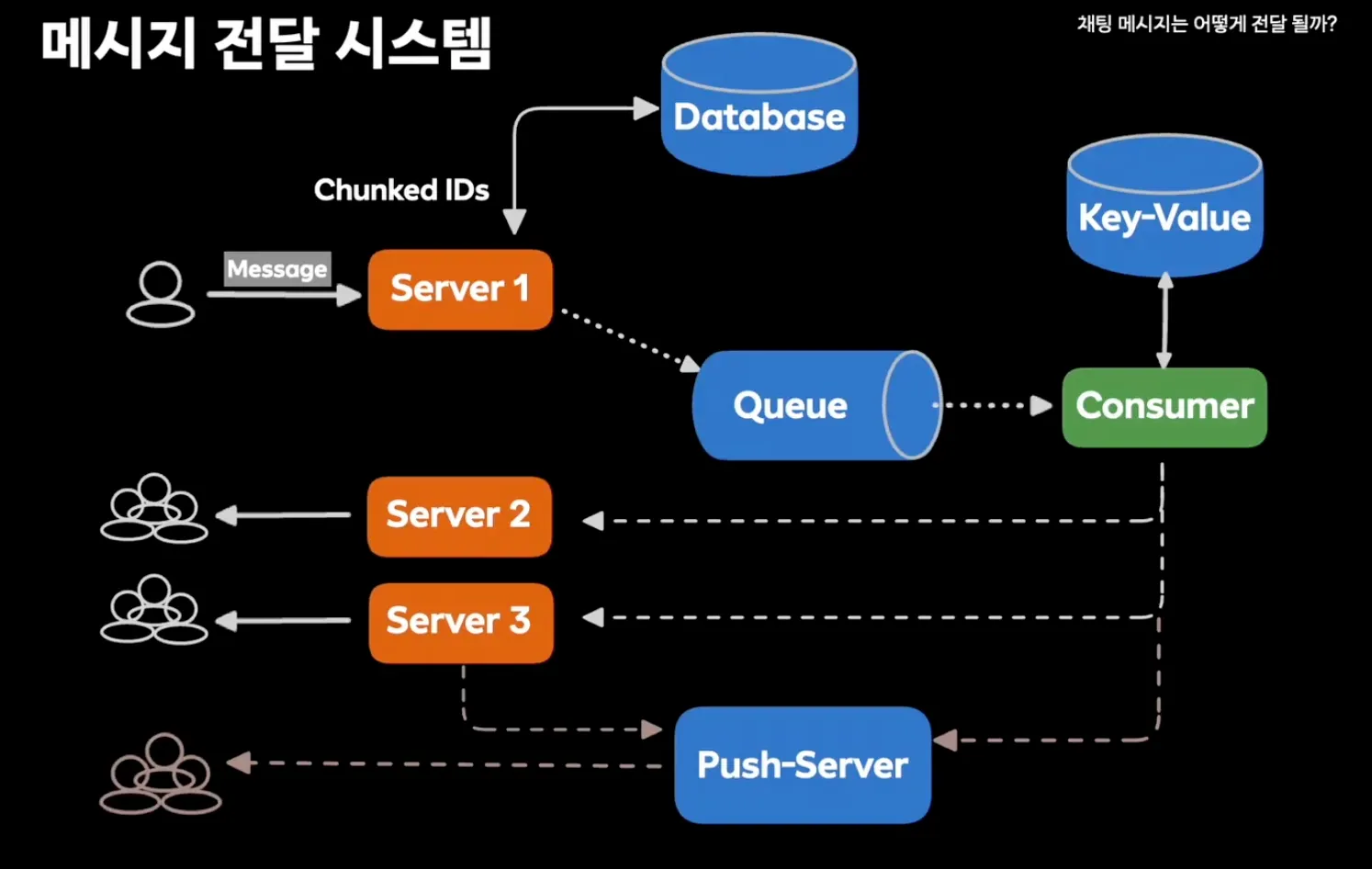
- 확장성과 신뢰성 효율성 확보
채팅 시스템은 어떻게 저장 될까
배경
- 예전에는 RDB 하나에 모든 데이터를 저장했다
- 캐시 및 쿼리 최적화, scale up을 진행했지만 그것마저 한계
- 채팅 데이터가 전체 데이터의 60%
→ 채팅 데이터베이스 분리 필요 + 확장성 + 실시간성
기본 구조
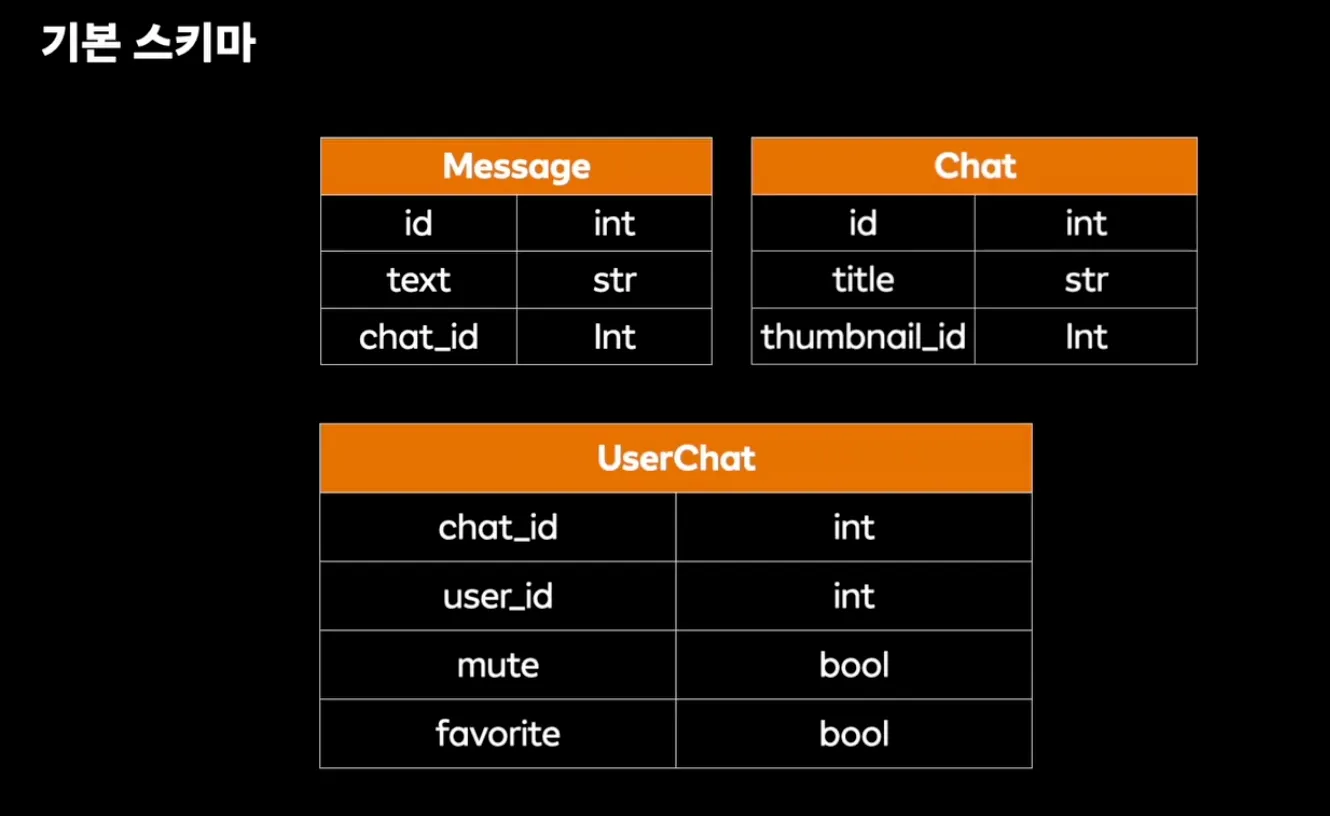
하나의 논리적 데이터베이스를 물리적으로 샤딩
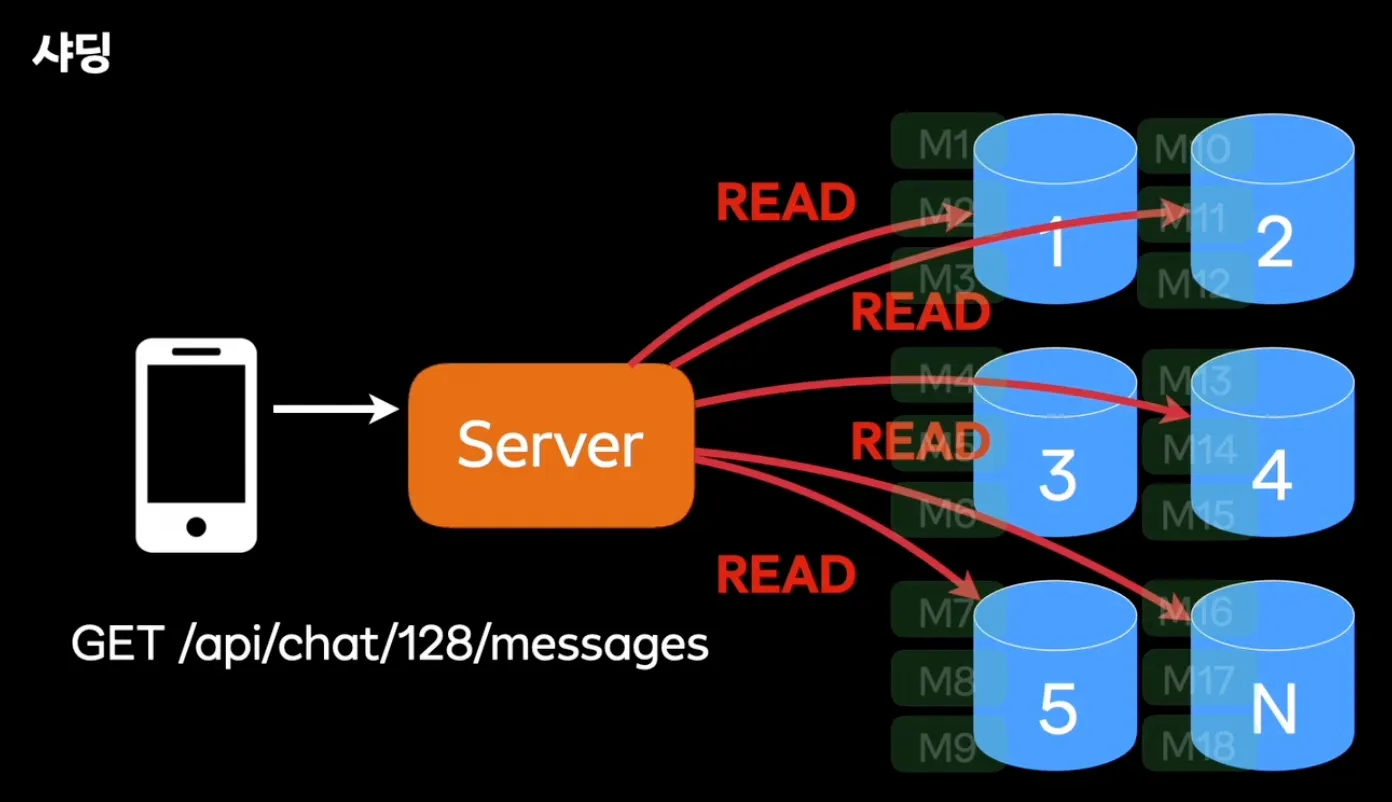
- 하지만 요청시마다 모든 데이터베이스를 읽을 수는 없다.
- Shard Key를 사용해서 같은 방의 메시지를 하나의 데이터베이스에 저장 (chat_id 사용)
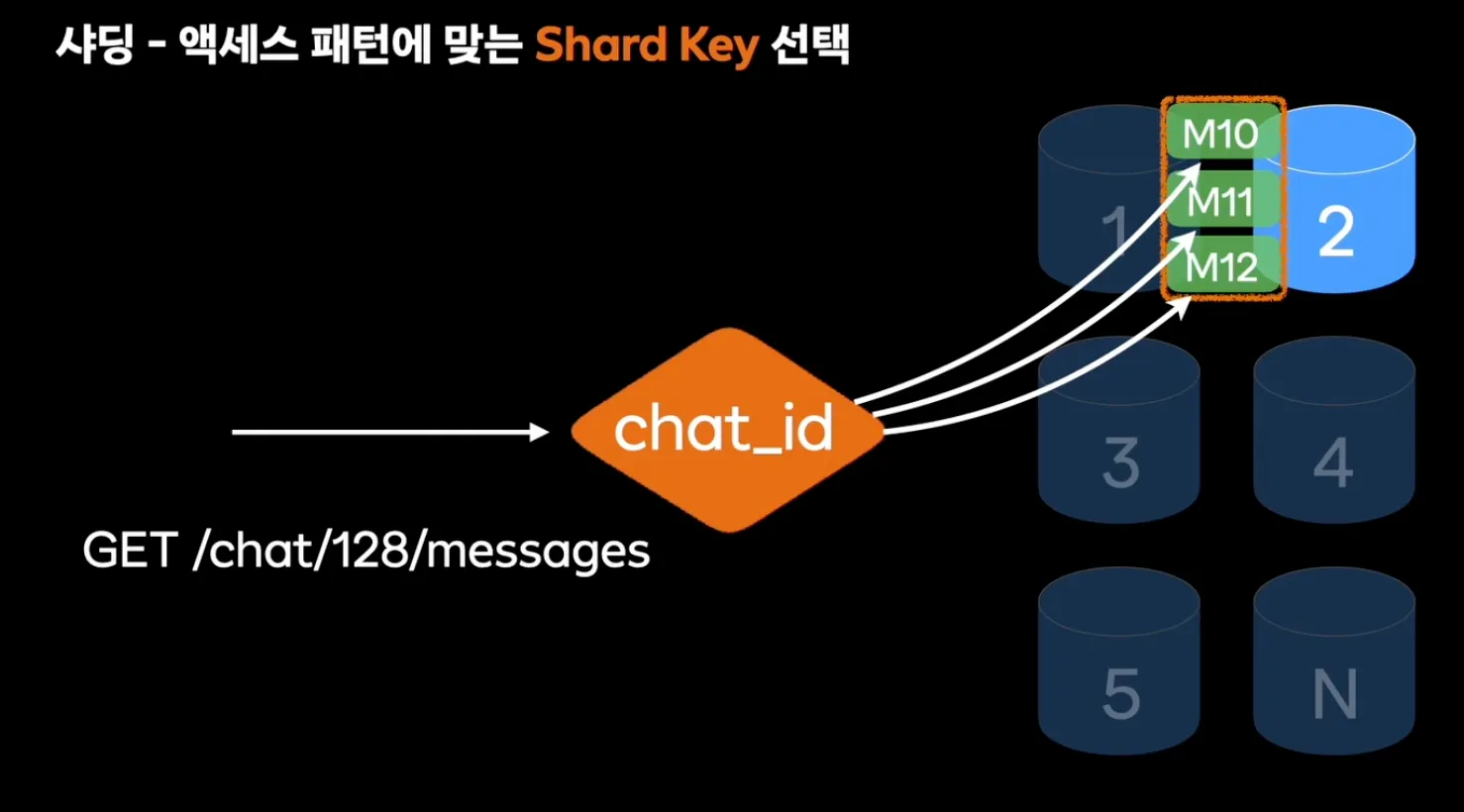
샤딩 종류

→ DynamoDB를 사용해서 설계했다
→ 적은 인원으로 관리 가능 (shard key만 설정하면 자동으로 샤딩 진행된다)
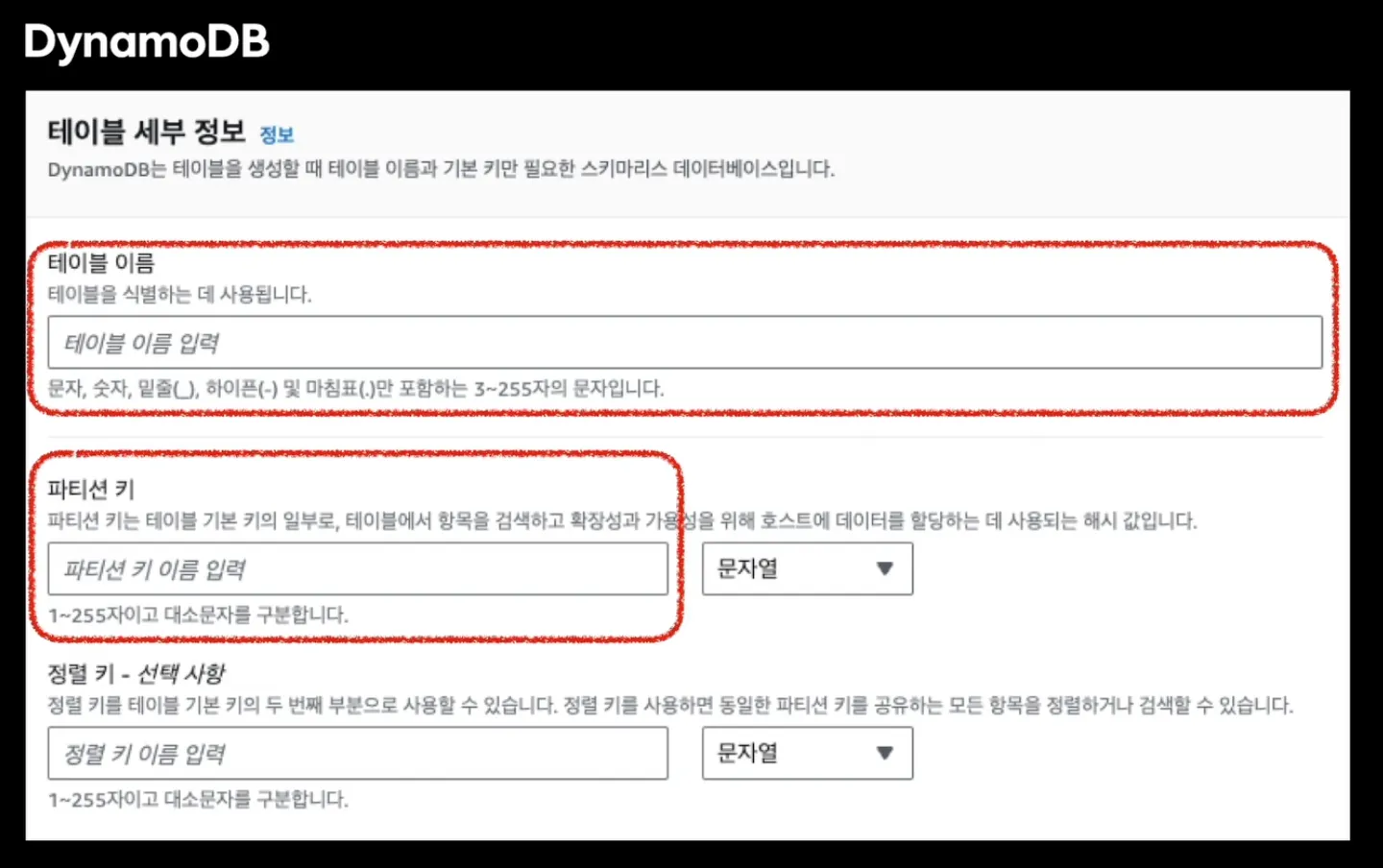
- 이와 같이 생성시에 파티션 키(샤드키)를 입력받는다.
채팅 실시간 API 최적화
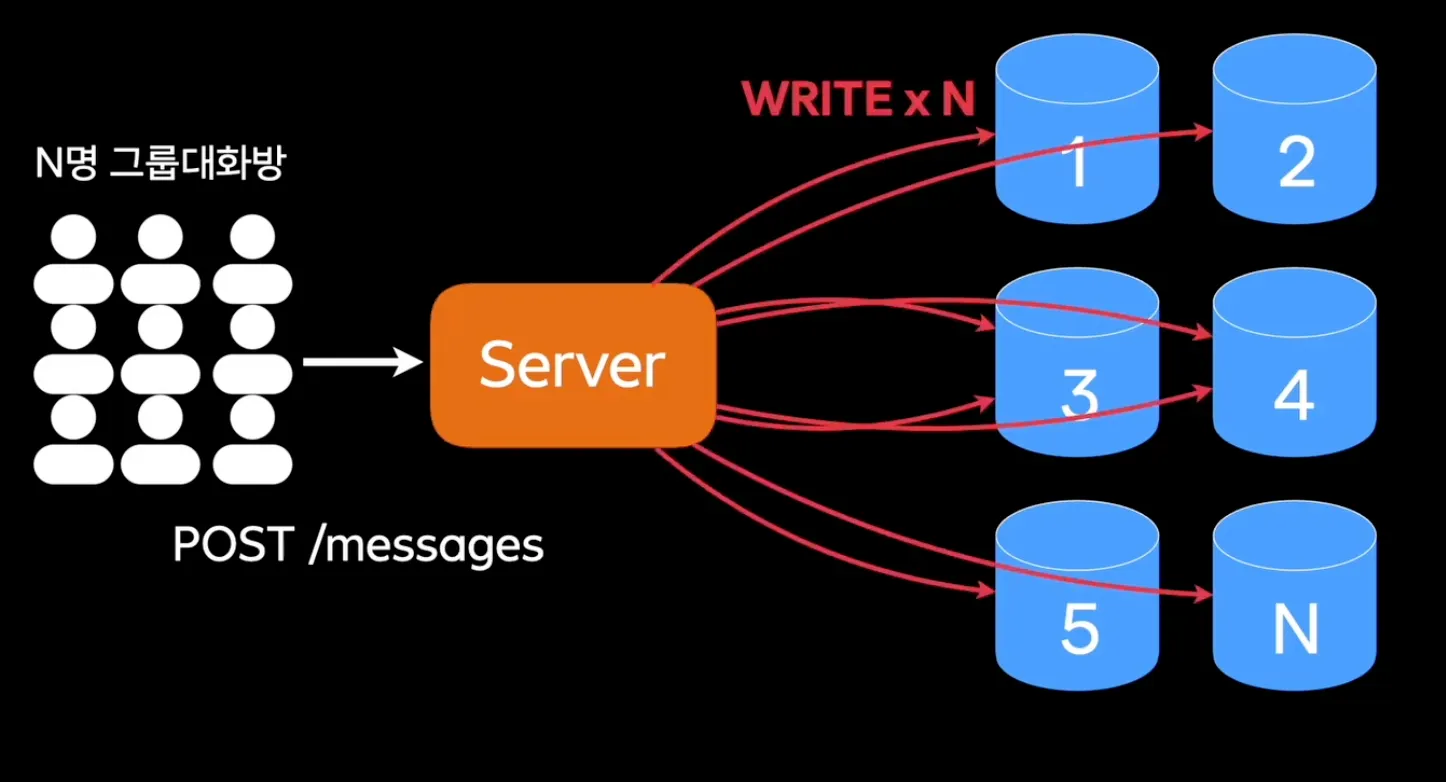
- N명의 그룹 대화방에서는 하나의 메시지만 생성돼도 여러 저장 로직 발생
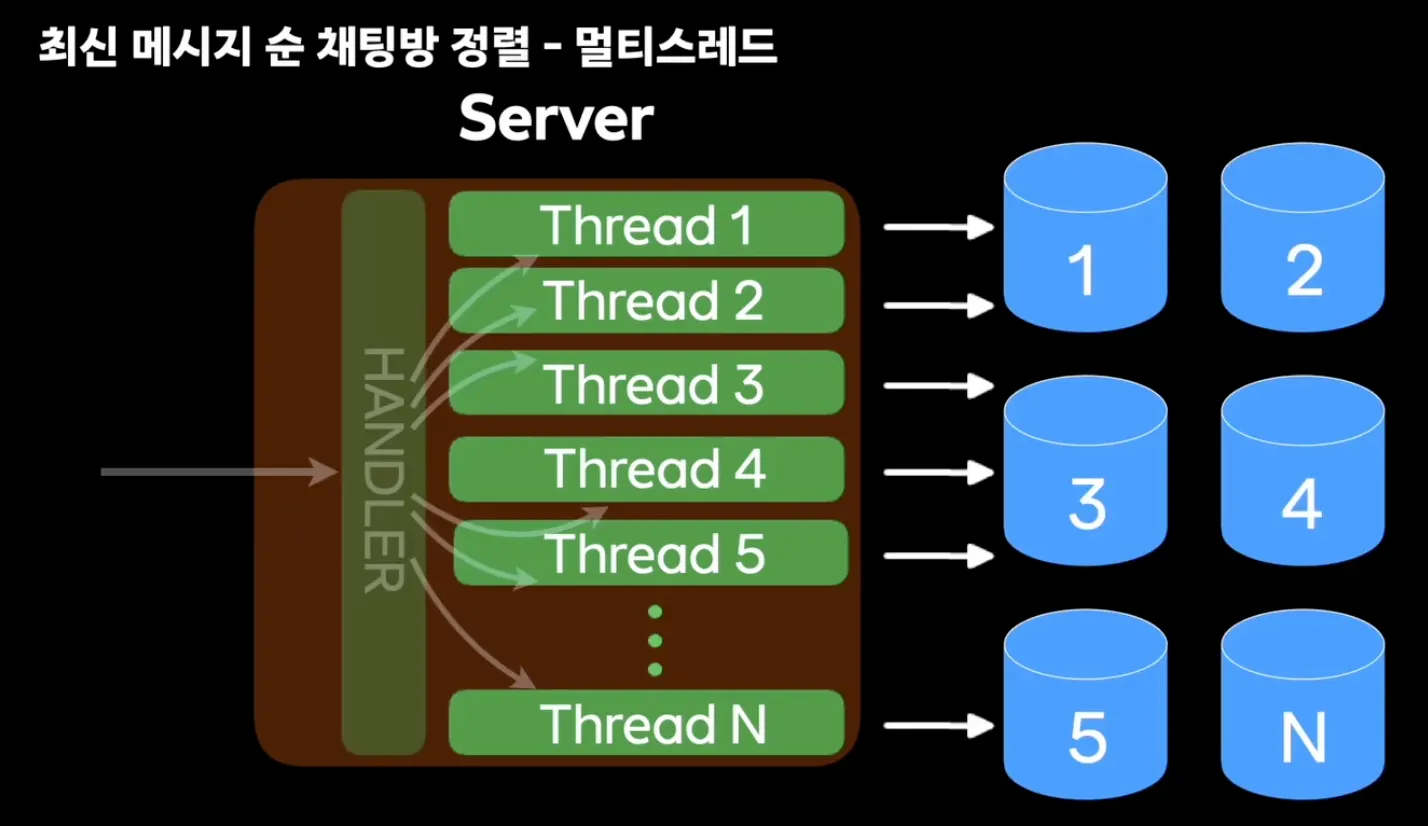
- 멀티 스레드 방식을 활용해서 최대한 빠르게 작동하도록 설계
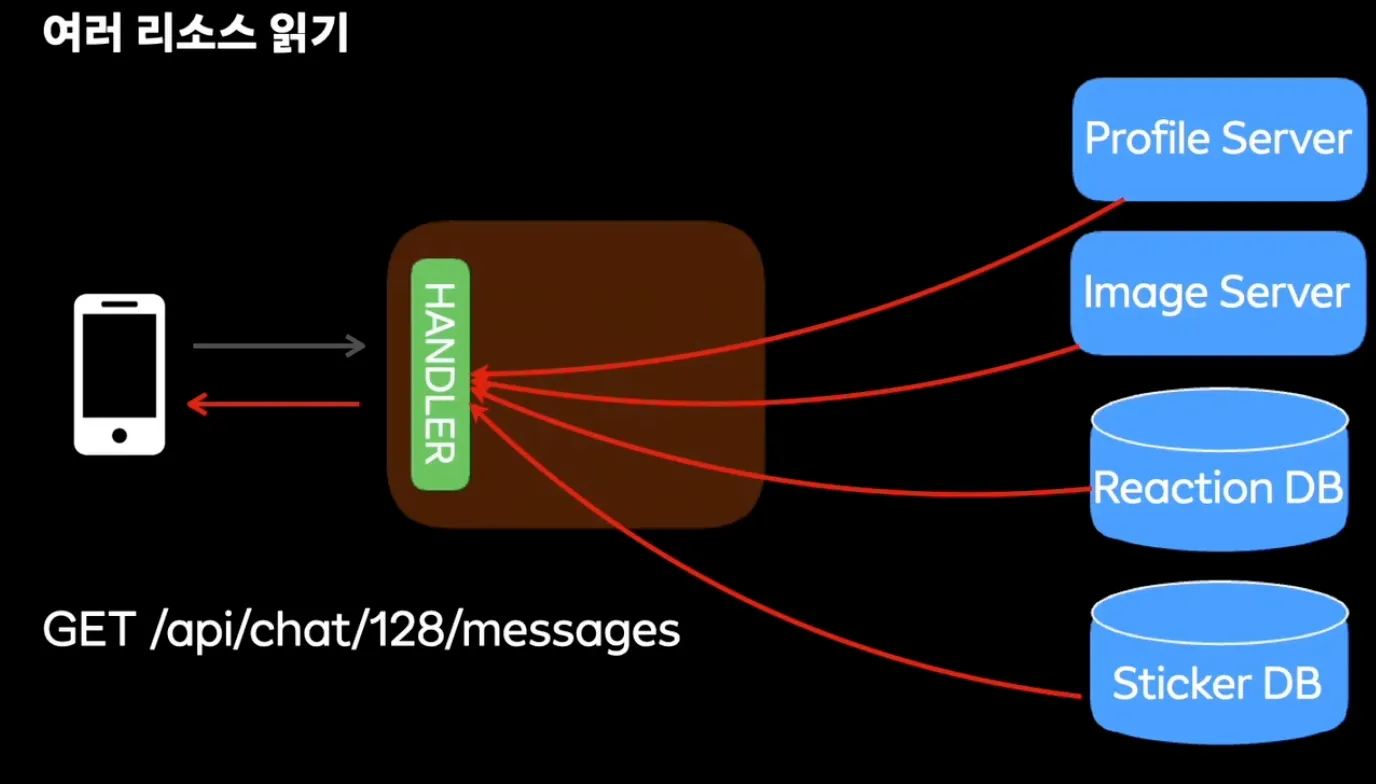
- 여러 리소스를 읽어오는 부분에서도 하나의 핸들러로만 작동시키면 너무 오래걸린다
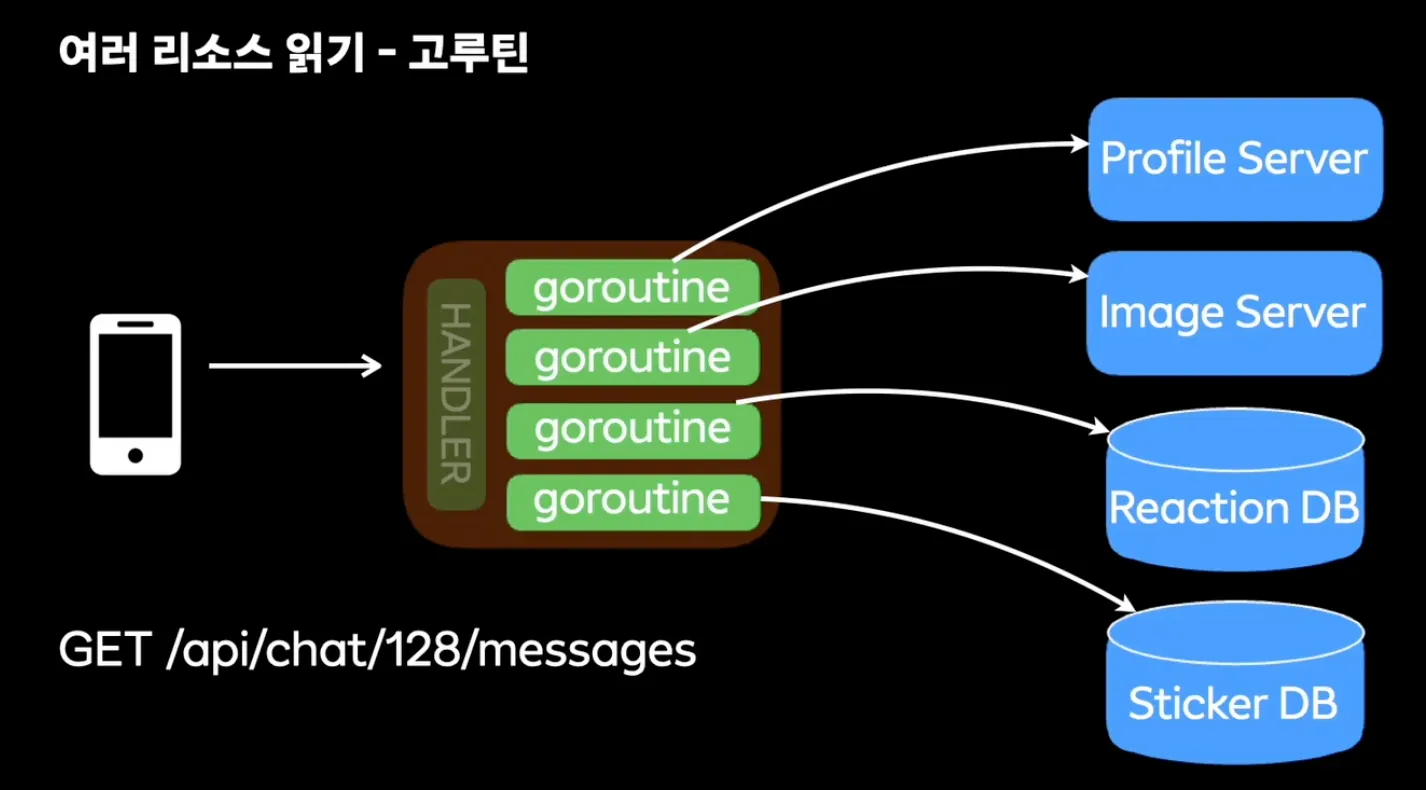
- 멀티 스레드 방식으로 클라이언트에게 최대한 빠르게 데이터 전달
비동기 처리와 이벤트 큐
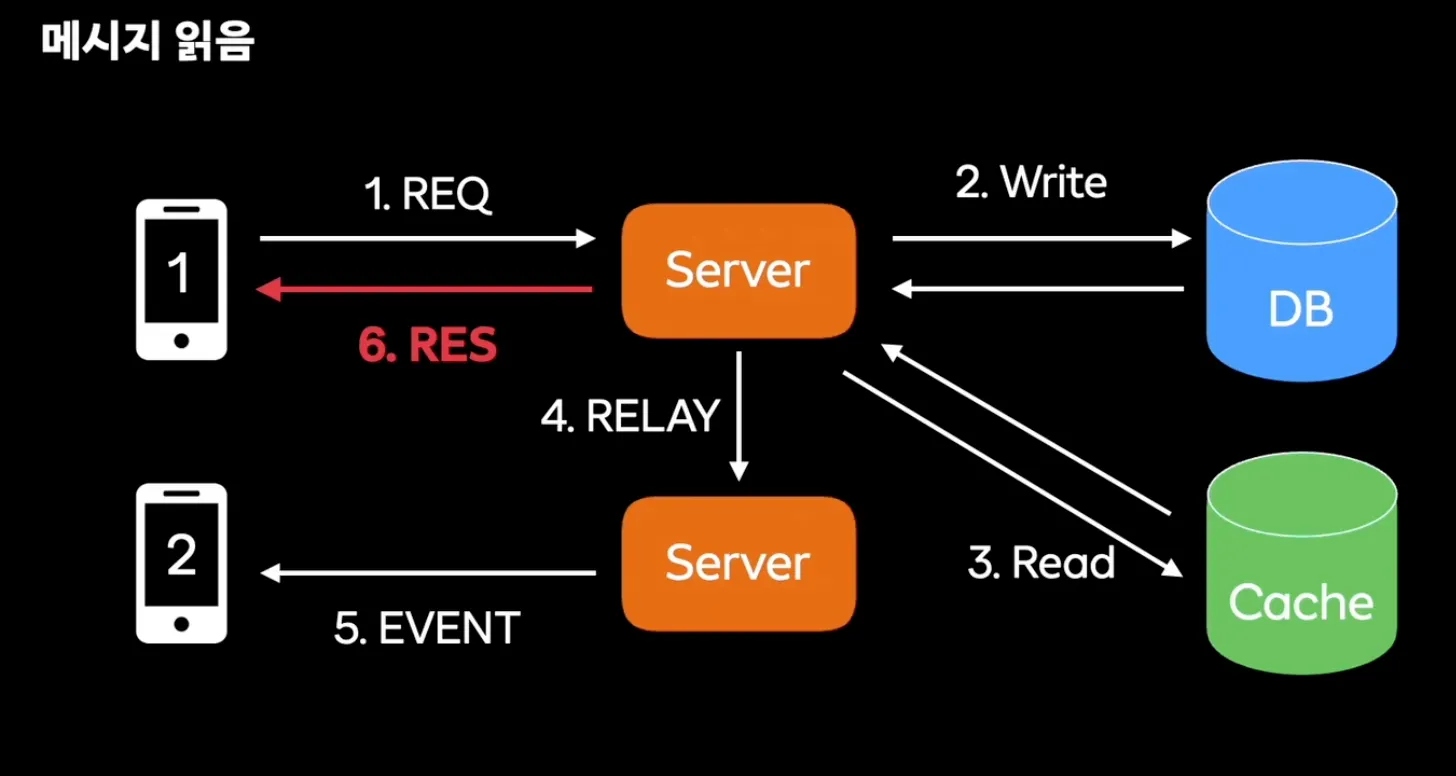
- 메시지를 읽었을시에 발생
- 메시지 읽었다는 트래픽을 서버에 전송
- DB에 저장 → 캐시메모리에서 채팅방 사용자 검색
- 해당 사용자의 서버에 접근 및 사용자에게 전달
→ 너무 오래걸린다
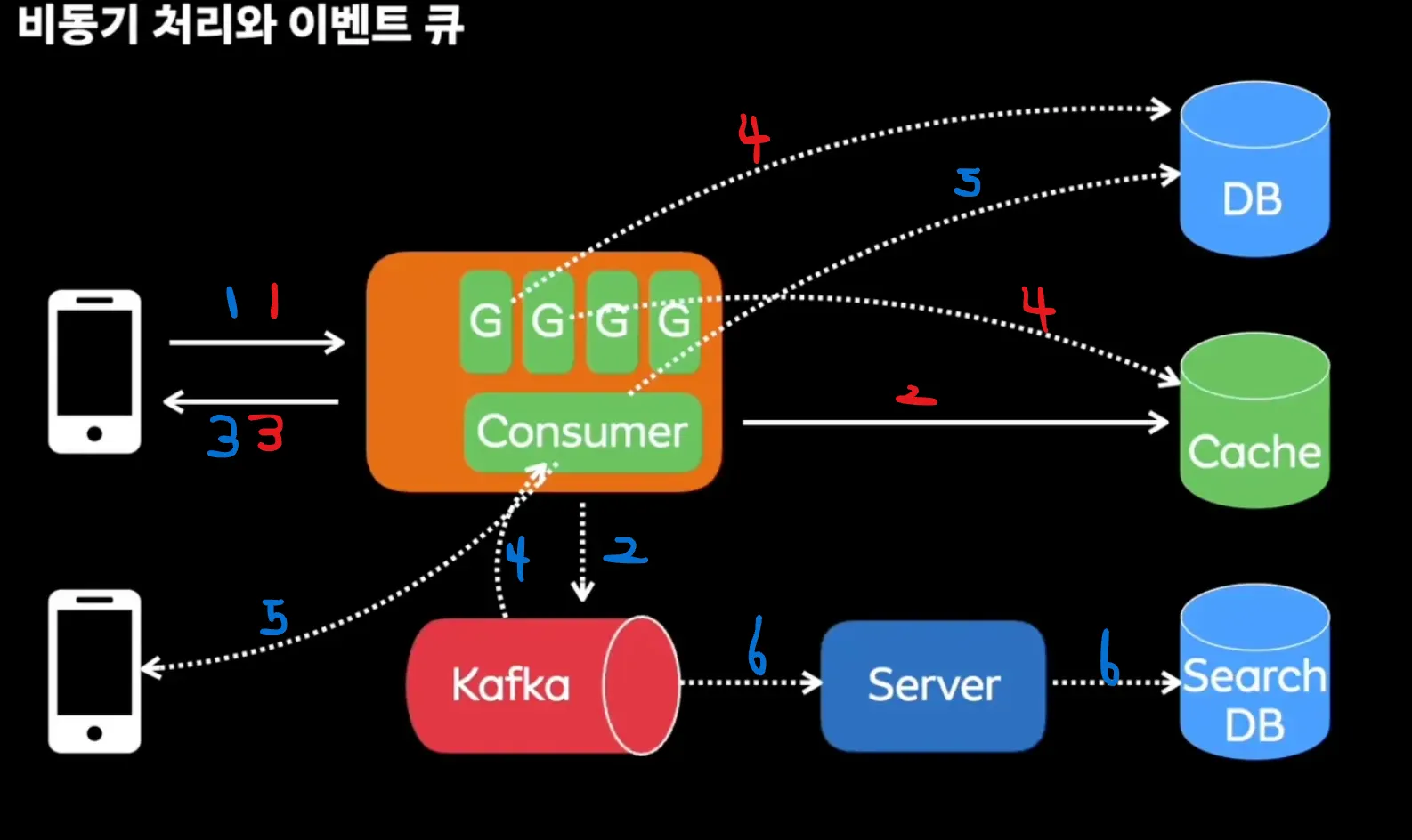
-
비동기 처리로 진행
-
이벤트 발생시 동기적으로 저장해야되는 데이터만 우선 저장 (캐시메모리에)
-
→ 이후 사용자에게 응답 먼저 (1→2→3)
-
이후 고루틴(스레드)으로 백그라운드 업데이트 진행 (4)
-
고루틴(스레드) 만들기 싫으면 kafka 활용
-
기본적인 사용자 응답 (1→2→3)
-
그에따른 로직 실행 (고루틴 역할을 kafka가 진행, 4→5)
-
검색엔진 데이터를 인덱싱하거나 다른 이벤트를 발행하는 기능에도 사용 (6)

공부 노트 & 회고