해당 정리는 유튜브
[우아한테크세미나] 191121 우아한레디스 by 강대명님
https://www.youtube.com/watch?v=mPB2CZiAkKM
를 기반으로 정리한 내용입니다.
Redis 소개
Cache란?
- 요청올 결과를 미리 저장해두었다가 빠르게 서비스를 해주는 것을 의미
- ex) Dynamic Programming
- -> 빠르게 접근할 수 있도록 데이터를 임시로 저장해 두는 장소
CPU Cache
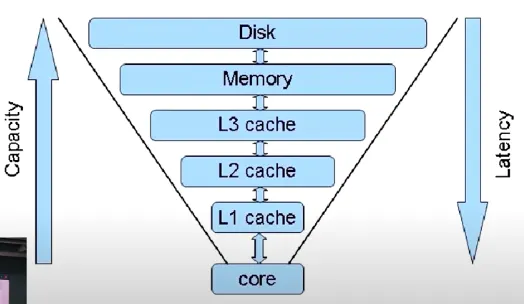
-
Redis는 memory에 존재한다.
-
일반적인 웹 서비스 구조: 클라이언트 → 웹 서버 → DB구조에서 DB 내부에도 캐시가 존재한다.

- 메모리 크기 초과 시, 디스크를 사용해야 하며 캐시에 계속 접근하다 보면 기존 캐시를 날리고 디스크에 새로 써야 하므로 속도가 느려질 수 있다.
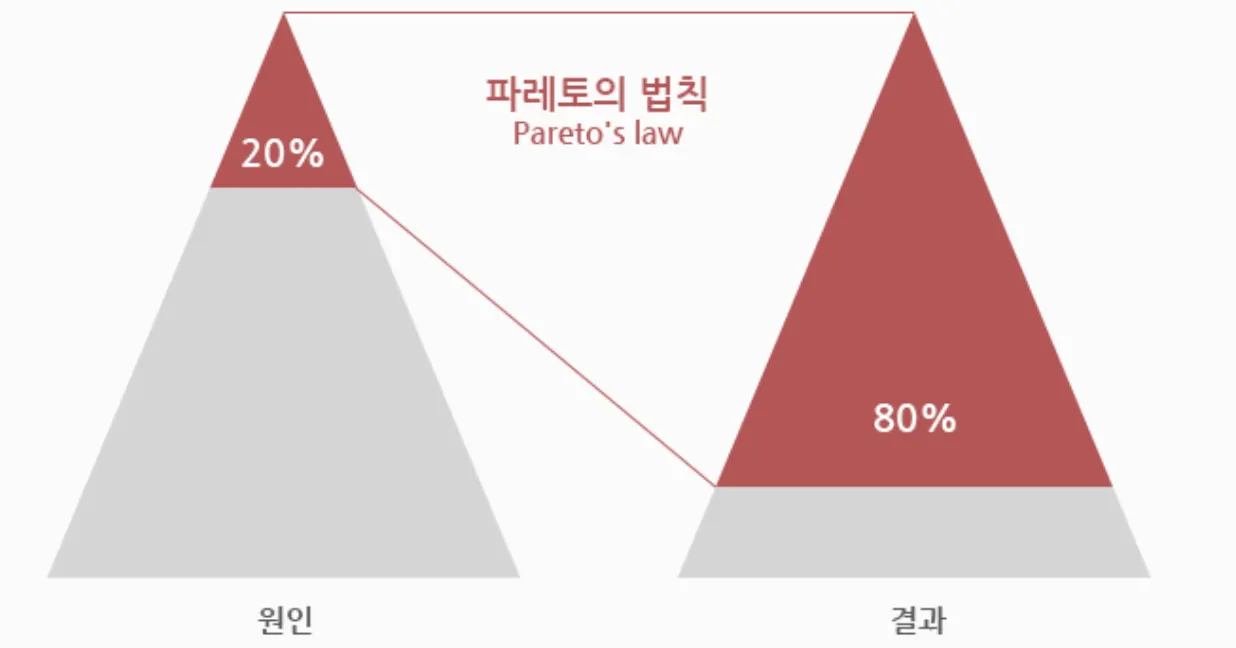
- 전체 요청의 80%는 20%의 사용자 → 적은 메모리로 효율적으로 캐싱이 가능하다
Cache 구조 1 - Look aside Cache
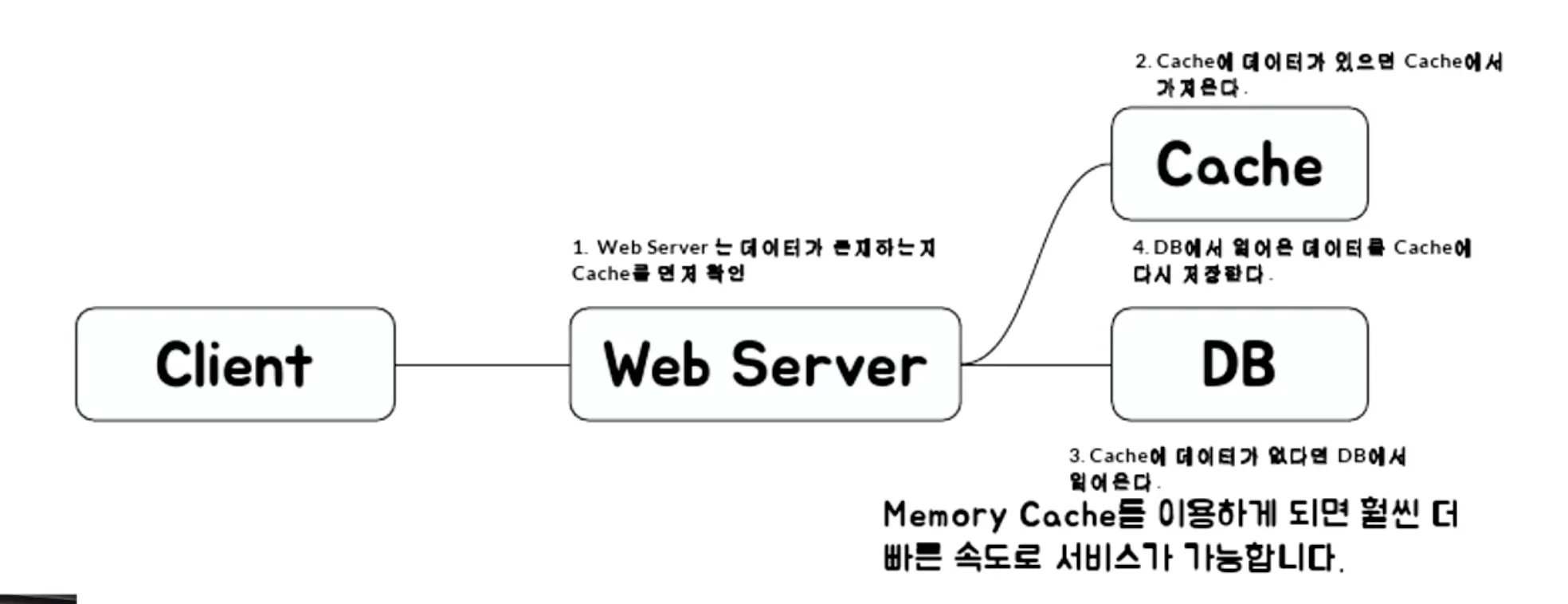
- DB에 도달하기 전 캐시에서 데이터를 확인
- 데이터가 없으면 DB에 접근하여 캐시를 저장하고 결과 반환
Cache 구조 2 - Write-Back
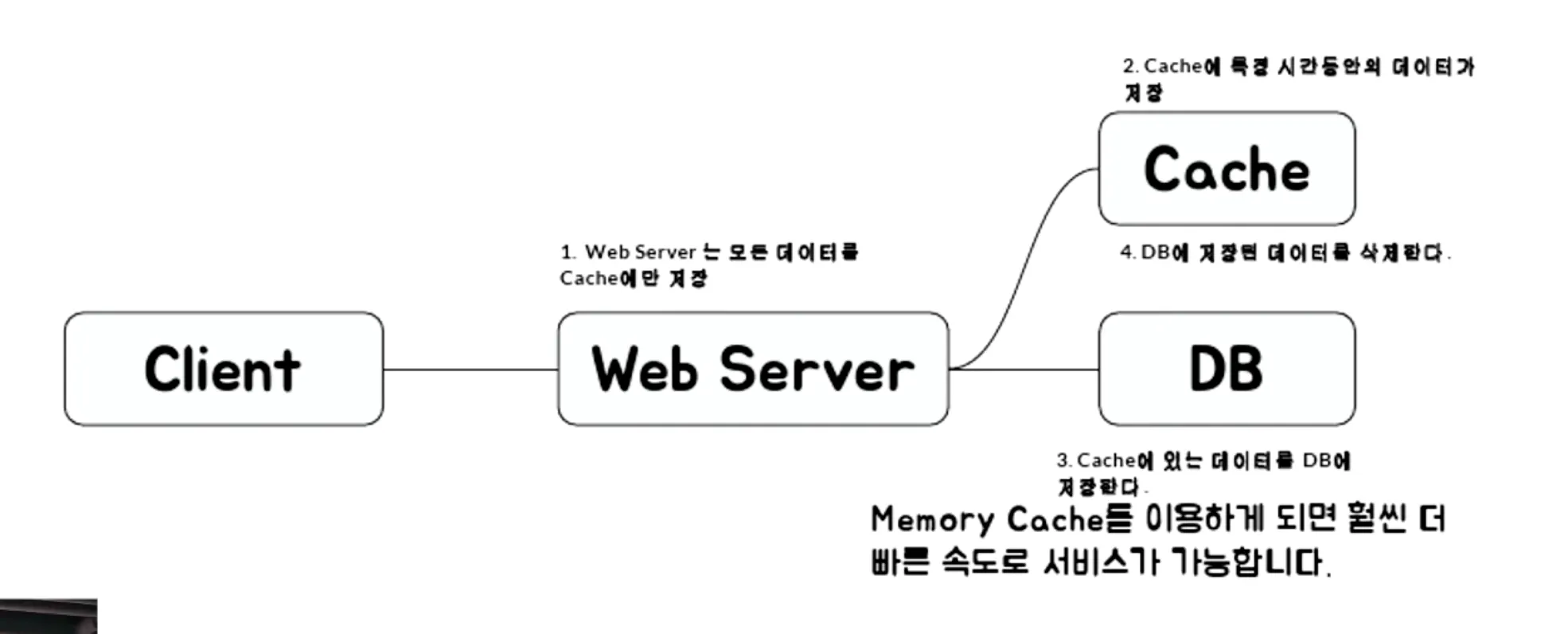
- 데이터를 매번 디스크에 저장하는 것보다 캐시에 저장했다가 특정 시점에 일괄 저장
- 데이터 insert가 자주 발생하는 경우 주로 사용, 쓰기 속도가 빠르다
→ ex) insert query 1번 vs insert query 500번
단점: 캐시에만 저장되어 있는 데이터는 장애 발생 시 소실 가능성이 있다
활용 예시: 배치 저장, 백업 시 분산하여 저장
Redis 컬렉션의 장점
Collection의 중요성
- Memcached는 컬렉션 제공 x, Redis는 제공한다
- 이미 구현된 라이브러리를 활용하는 것이 개발 생산성이 높다
→ 데이터 조회 및 삽입 과정에서 속도 향상
Collection 활용 예시
- in-memory 환경에서 랭킹 서버의 구현이 필요한 경우
- redis의 sorted set 사용 가능
- 친구 리스트를 관리 - key value 형태로 저장
- 일반 메모리 환경에서는 두 트랜잭션이 겹치면 데이터 정합성 문제 발생 가능
- → 데이터베이스 4원칙 ACID 위반
ex)

정상

race condition 발생
Redis에서는 원자성을 보장하기 때문에 삽입 시 원하는 결과를 보장 받을 수 있다.
→ 하지만 같은 요청이 빠르게 두 번 발생하면 데이터가 중복 저장되는 문제가 생길 수도 있다.
Redis 사용처
- 여러 대의 서버가 하나의 데이터베이스를 사용할 때
- 하나 서버에서만 사용해도 전역 변수 대신 redis를 사용하면 좋다.
- 인증 토큰, ranking board, 유저 api limit 등
Redis Collections
String - 단일 Key
- Set
- Get
List
- Lpush, Rpush, LPOP, RPOP
Set
- SADD : value가 이미 key에 있으면 추가되지 않는다
- SMEMEBER : 모든 value 출력
- SISMEMBER : value가 존재하면 1, 없으면 0
Sorted Set
- ZADD : 데이터 삽입
- ZRANGE : 해당 범위 출력 ↔ ZRERANGE
Hash
→ 안중요함
Redis Collection 주의 사항
- 하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않다 → 1000개 이하 몇 천개 수준으로 유지하는 것이 좋음
- Expire는 Collection의 item 개별로 걸리지 않고 전체 Collection에 대해서만 걸림 → 즉 해당 10000개의 아이템을 가진 Collectiondp expire 가 걸려있다면 그 시간 후에 10000개 아이템이 모두 삭제
Redis 운영
- 메모리 관리를 잘하자
- redis는 in-memory data store
- 물리적 memory 이상을 사용하면 swap 사용으로 해당 메모리 page 접근 시 마다 성능 저하
- maxmemory: 설정된 메모리 이상 사용하지 않도록 키를 랜덤하게 삭제하거나 Expire된 키를 지우는 옵션
- jemalloc 할당 방식 때문에 Redis가 실제로 사용하는 메모리 양을 정확히 알기 어려움
→ 페이지 단위로 할당하기 때문에 실제 사용량보다 더 많은 메모리를 사용할 수 있다.
jemalloc: 메모리 관리 라이브러리
- 큰 메모리를 사용하는 instance 하나보다는 작은 메모리를 사용하는 instance 여러개가 안전하다
→ write의 경우 copy-on-write로 인해 이론적으로 2배의 메모리를 사용한다
메모리가 부족할 떄는?
- migration 기준: 실제 사용량의 70% 정도 도달하면 업 스케일링 진행
- 메모리를 줄이기: zip list로 변환, 속도는 느려지더라도 메모리상에서 이득

- O(N) 관련 명령어를 주의하자
- redis는 single threaded
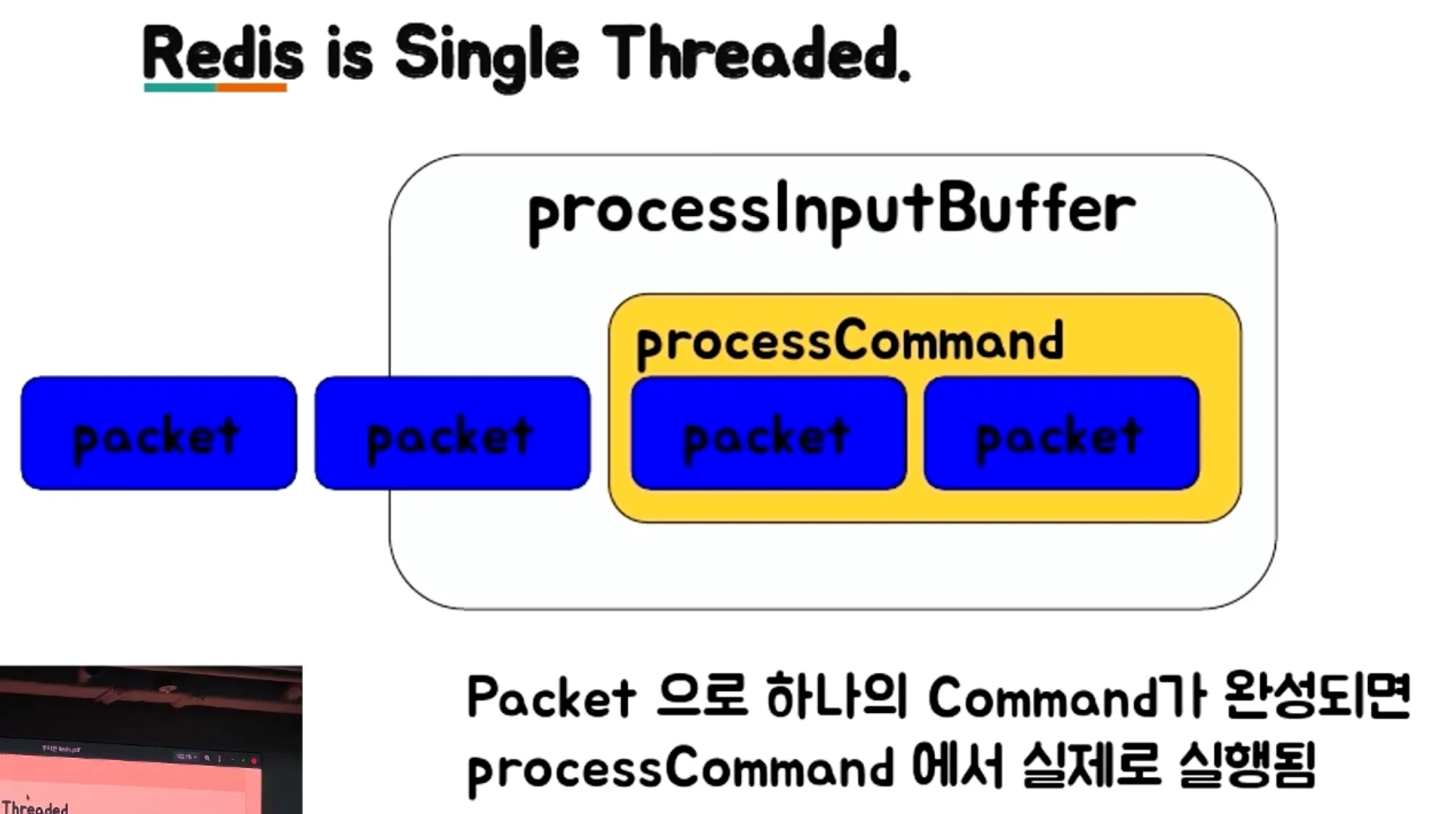
- 1초 걸리는 작업이 하나라도 발생하면 나머지 99,999개 명령은 1초 동안 대기
주의할 명령어
- KEYS: 모든 키를 조회하는 명령어
- FLUSHALL, FLUSHDB: 데이터 다 날리는 거
- Delete Collection: 컬렉션 전체 삭제
- Get All Collection:
대안
- SCAN: KEYS 대신 SCAN 명령어를 사용하여 조금씩 데이터를 조회
- 컬렉션 분할: 큰 컬렉션을 작은 컬렉션 여러 개로 나누어 관리
ex) Userranks → Userrank1, Userrank2, Userrank3
- Redis Replication 및 페일오버
- Async Replication
→ Replication Lag 발생 가능, A가 수정되면 B도 수정되지만 그 복제 과정에서 차이가 발생
Replication 설정 과정
- Secondary에 replicaof or slaveof 명령을 전달
- Secondary는 Primary에 sync 명령 전달
- Primary는 현재 메모리 상태를 저장하기 위해
- Fork 한 프로세서는 현재 메모리 정보를 disk에 dump
- 해당정보를 secondary에 전달
- Fork 이후의 데이터를 secondary에 계속 전달
Redis Replication 시 주의할 점
- Replication 과정에서 fork가 발생하므로 메모리 부족 발생 가능 (COW 때문)
- Redis-cli —rdb 명령 또한 fork 발생
- AWS 나 클라우드 Redis는 fork없이 replication이 작동하지만 속도가 느리다, 하지만 안전하다.
Redis 데이터 분산 방법 - Sharding
- Consistent Hashing
- key 값을 해싱해서 나보다 크면서 가장 가까운 서버로 이동
ex) 15000이 나오면 10000, 20000, 30000 서버 중에 20000으로 간다
→ 20000 서버가 죽었을 때 17500만 30000으로 이동하고 다른 데이터들은 그대로
→ 서버가 죽거나 증설했을 때 해당 서버의 데이터만 이동
→ 1/n만큼만 움직인다 키의 해쉬 값이 해쉬가 일정하면 값이 일정하기 때문에 가능
- Range Sharding
- 키의 범위를 기준으로 서버를 할당

→ 서버의 상황에 따라 놀고 있는 서버와 안놀고 있는 서버와 극심하게 나눠질 수 있다
→ 확장은 편하지만 중간에 빠져나가거나 초창기 유저가 저장 되어 있는 서버만 계속 일함
→ Index Server를 할당해서 속도를 향상 시킬 수 있지만 서버가 죽어버리면 데이터베이스가 바보된다.
- Redis Cluster
- Hash 기반으로 Slot 16384로 구분
- Hash 알고리즘은 CRC16을 사용
- Slot = crc16(key) % 16384
- Key가 Key{hashkey} 패턴이면 실제 crc16에 hashkey가 사용된다
- 특정 Redis 서버는 이 slot range를 가지고 있고, 데이터 migration은 이 slot 단위의 데이터를 다른 서버로 전달하게 된다
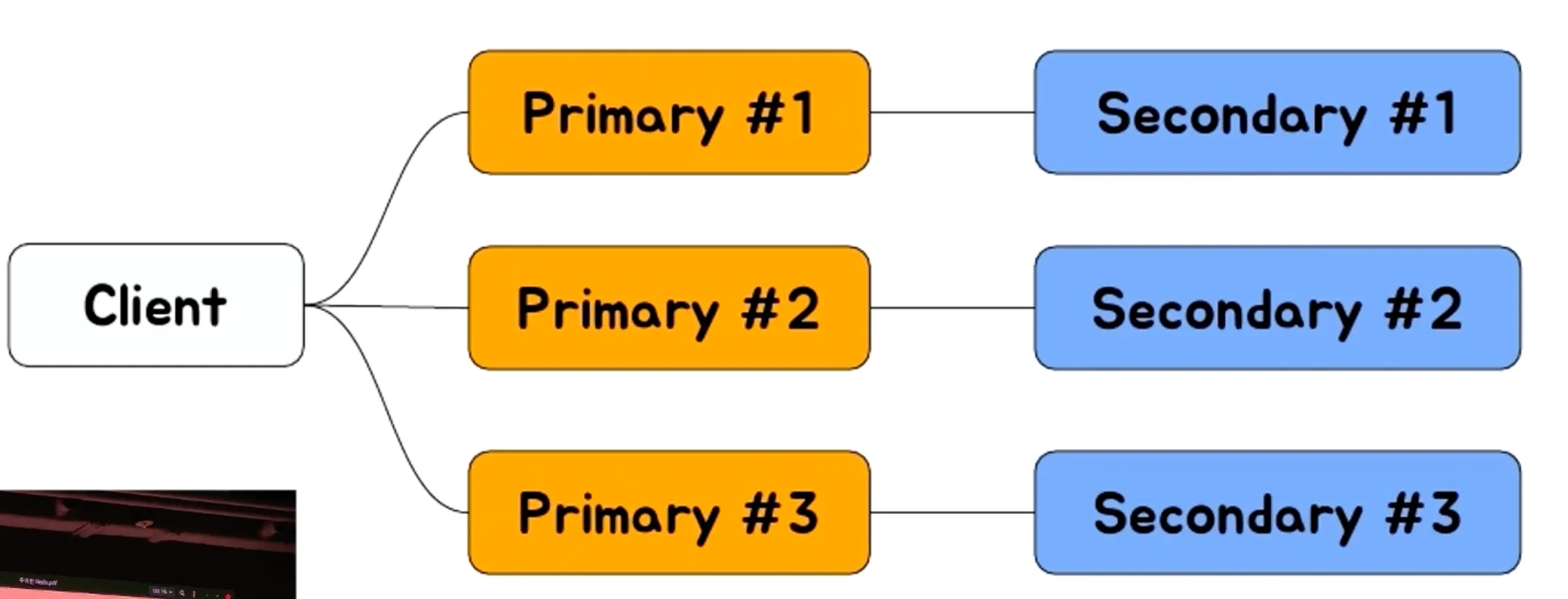
장점
- Primary가 죽으면 Replica 중 하나가 자동으로 Primary로 승격
- Slot 단위의 데이터 관리 각 키의 저장 위치를 명시적으로 할당할 수 있다
단점
- 리소스 사용량이 더 많다
- Migration 자체는 관리자가 시점을 결정해야 함
- Library 구현이 필요
Redis Failover
- Coordinator 기반 Failover
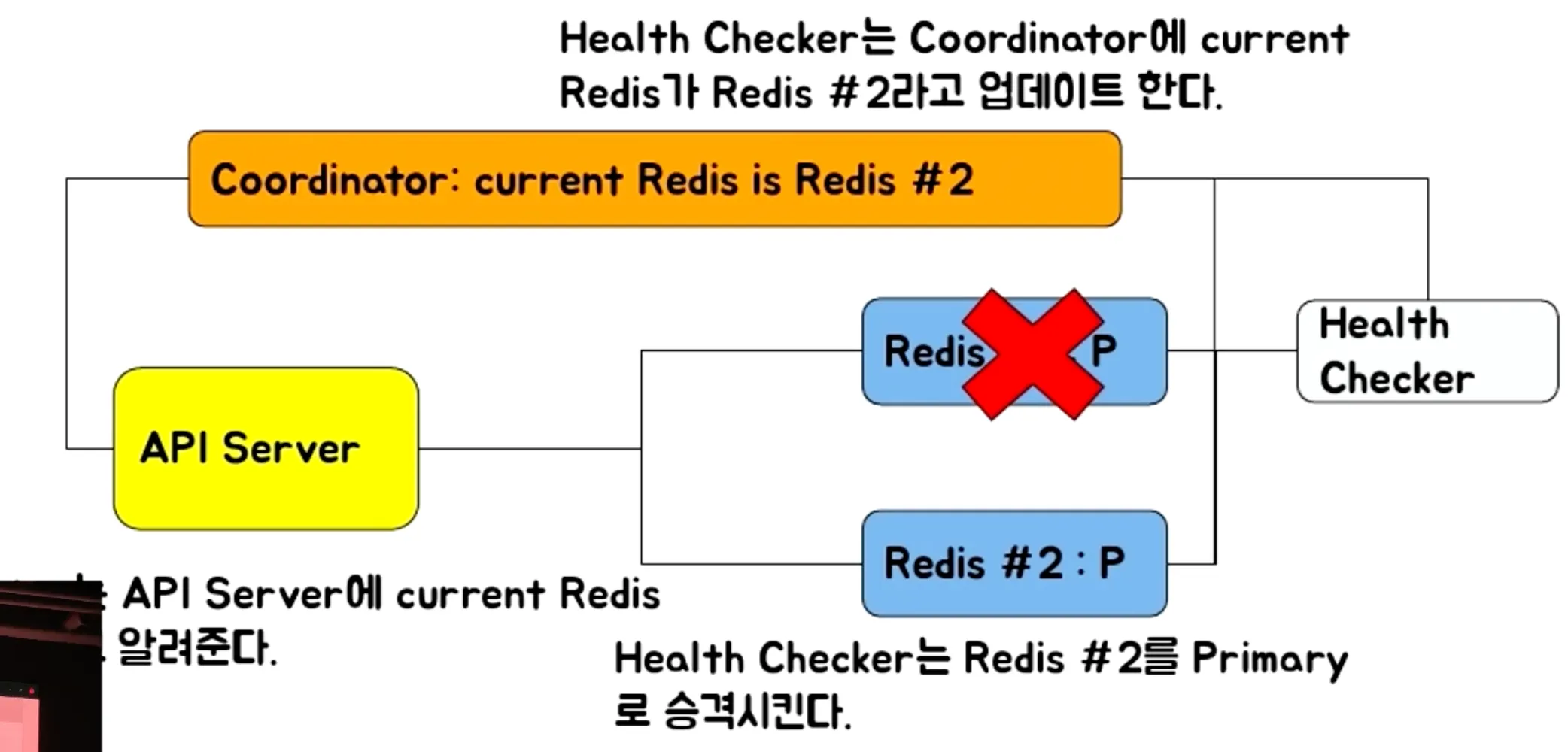
- 외부 설정 저장소에 서버 정보를 저장하고, 장애 감지 시 스케줄러가 이를 감지
- 장애 감지 → Replica 승격 → Coordinator에 변경 사항 업데이트 → 애플리케이션이 업데이트된 정보를 확인하고 새로운 Primary로 접속
- 장점: 다른 설정 변경 없이 간단하게 구현 가능
- 단점: 다른 솔루션을 사용하고 있었다면 변환하기 힘들다
- VIP/DNS 기반 Failover
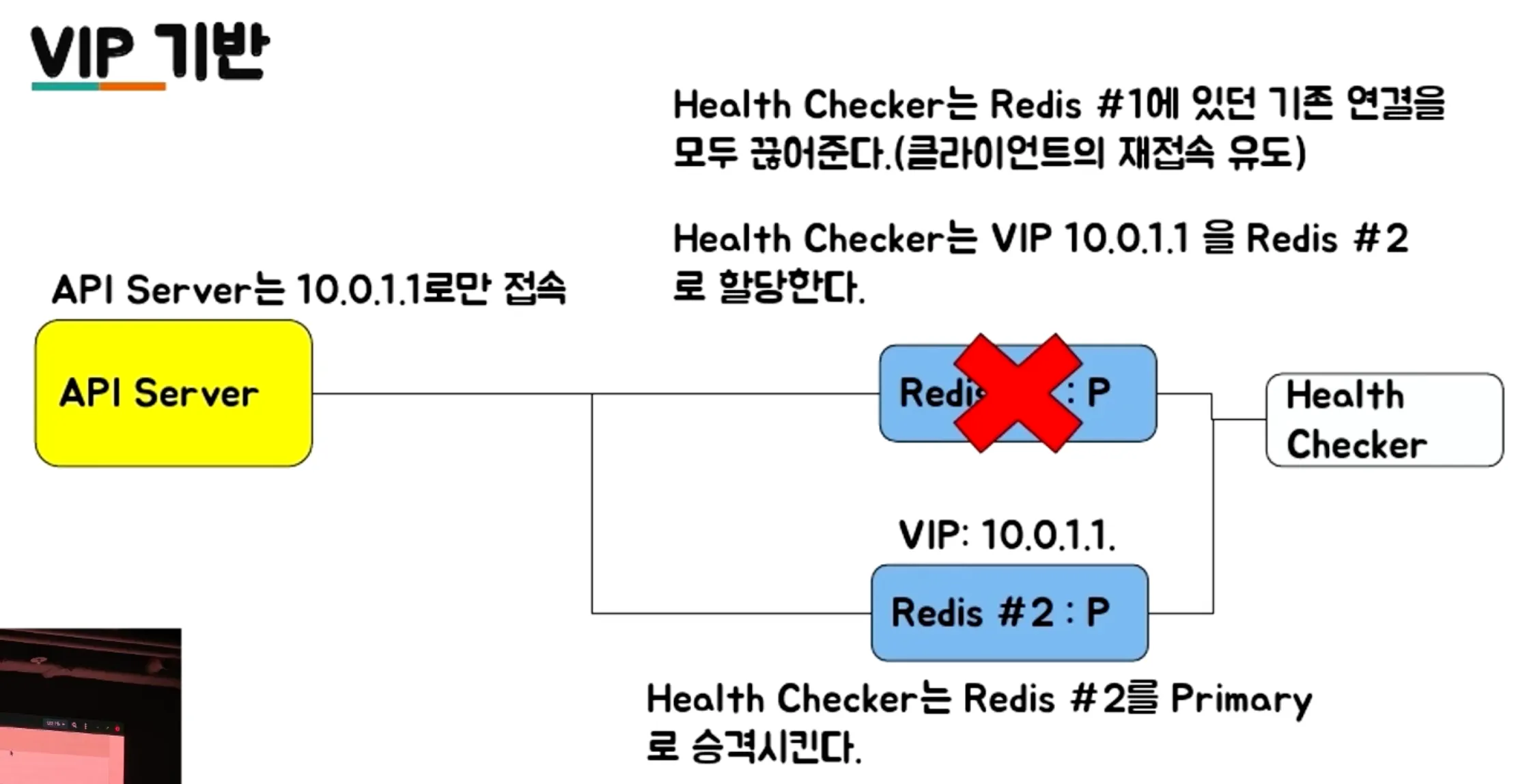
- 가상 IP를 할당하고, 장애 발생 시 VIP를 새로운 Primary 서버로 할당
- 클라이언트가 IP 주소를 변경할 필요 없이 동일한 VIP로 접속하면 자동으로 새로운 서버로 연결
- 외부로 서비스를 제공해야 하는 서비스 업자에게 유리 ex) 클라우드 업체
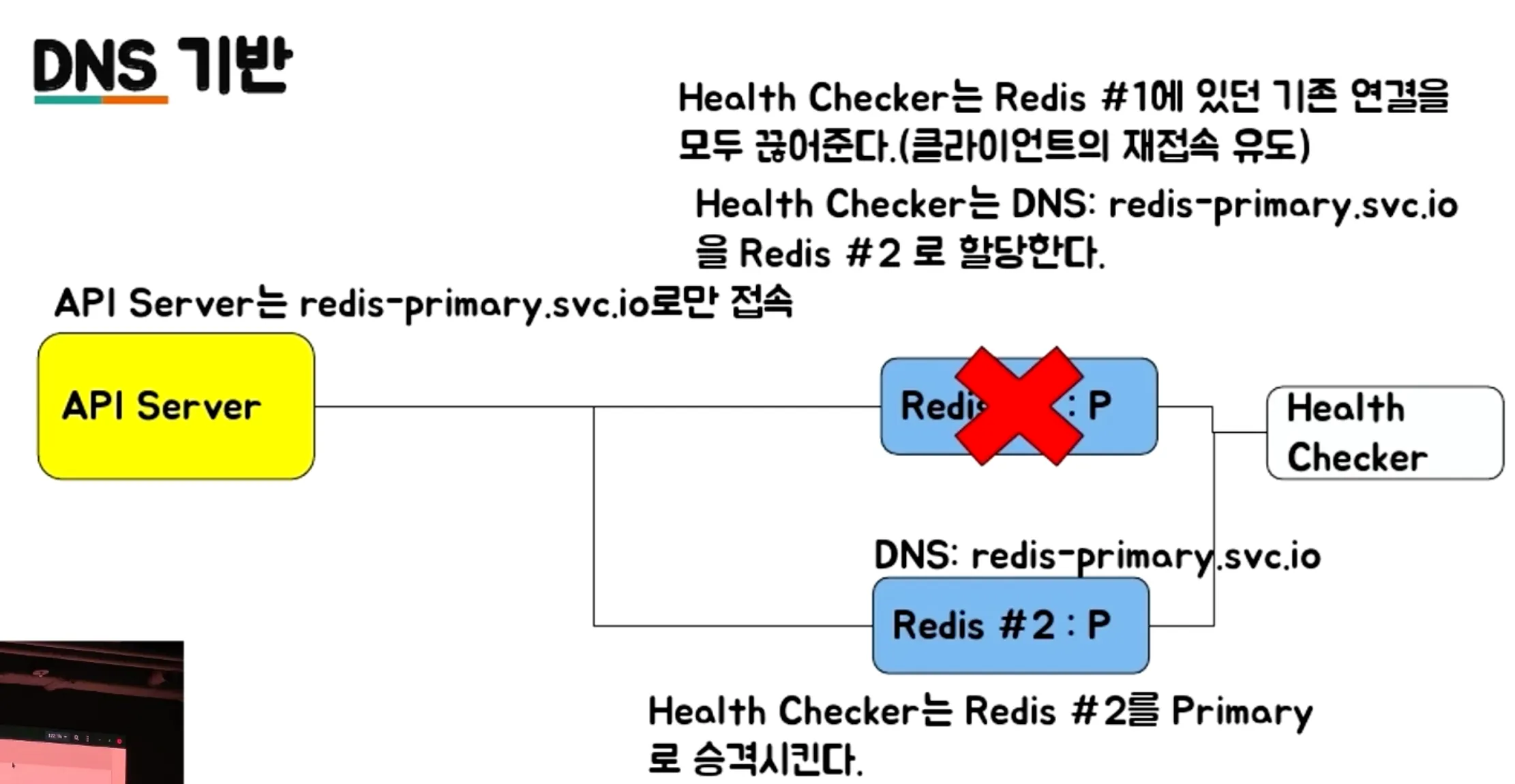
- 원리: 도메인 이름을 설정하고, 장애 시 DNS 레코드를 변경하여 새로운 Primary 서버를 가리키게 한다.
- DNS 캐싱 문제로 인해 변경 사항이 반영되기까지 시간이 걸릴 수 있다
- DNS Cache TTL을 관리해야 한다.
- Redis Cluster 사용 (이미 다룸)
Monitoring
- Reids Info를 통한 정보:
- RSS : Physical memory를 얼마나 쓰고 있느냐 (Swap 사용 여부 확인)
- Used Memory : 실제 Redis가 생각하는 자기가 쓰고 있는 memory
- Connection 수: 싱글 스레드이므로, Connect/Disconnect가 빈번하면 성능이 저하될 수 있다
- 초당 처리 요청 수: CPU 사용량과 연관
- System
- CPU
- Disk
- Network rx/tx
if (CPU 100%)
- 처리량이 매우 많다면?
- 좀 더 CPU 성능이 좋은 서버로 이전
- O(N) 계열의 특정 명령이 많은 경우
- Monitor 명령을 통해 특정 패턴을 파악하는 것이 필요
- Monitor 잘못 쓰면 부하로 해당 서버에 더 큰 문제를 일으킬 수도 있다
결론
- Redis는 매우 좋은 툴이다
- 메모리를 빡빡하게 사용하면 관리하기가 어렵다
Redis를 캐시로 사용할 경우
- Redis가 문제가 있을 때 DB등의 부하가 어느 정도 증가하는 지 확인 필요
- Consistent Hashing도 실제 부하를 아주 균등하게 나누지는 않음 Adaptive Consistent Hashing을 이용해 볼 수 있다
Redis를 Persistent Store로 사용하는 경우
- 무조건 Primary / Secondary구조로 구성이 필요
- 메모리를 절대로 빡빡하게 사용하면 안된다
- RDB / AOF가 필요하다면 Secondary에서만 구동
