HDFS Federation
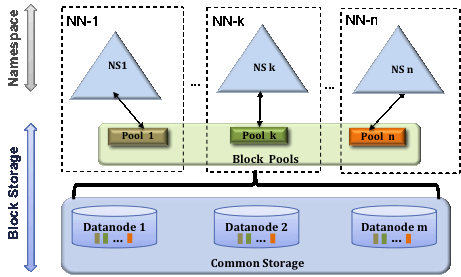
- namenode는 파일 정보 메타데이터를 메모리에서 관리한다.
- 파일이 많아지면 메모리 사용량이 늘어나게 되고, 메모리 관리가 문제가 되고 이를 해결하기 위해 hadoop v2부터 HDFS federation을 지원한다.
- HDFS federation은 디렉토리(namespace) 단위로 namenode를 등록하여 사용하는 것이다.
- HDFS federation을 사용하면 파일, 디렉토리의 정보를 가지는 네임스페이스와 블록의 정보를 가지는 block pool을 각 네임노드가 독립적으로 관리한다.
- namespace와 block pool을 namespace volume이라하고 namespace volume은 독립적으로 관리되기 때문에 하나의 namenode에 문제가 생겨도 다른 네임노드에 영향을 주지 않는다.
HDFS 고가용성
- HDFS는 namenode가 단일 실패 지점이기 때문에 namenode에 문제가 발생하면 모든 작업이 중지되고, 파일을 읽거나 쓸수도 없기 때문에 hadoop v2에서 이 문제를 해결하기 위해 HDFS 고가용성을 제공한다.
- HDFS 고가용성은 이중화된 두대의 서버인 active namenode와 standby namenode를 이용하여 지원한다.
- active namenode와 standby namenode는 datanode로부터 block report와 heartbeat를 모두 받아서 동일한 metadata를 유지하고, 공유 스토리지를 이용하여 edits 파일을 공유한다.
- active namenode는 namenode의 역할을 수행하고, standby namenode는 active namenode와 동일한 metadata 정보를 유지하다가, active namenode에 문제가 발생하면 standby namenode가 active namenode로 동작한다.
- active namenode에 문제가 발생하는 것을 자동으로 확인하는 것이 어렵기 때문에 보통 zookeeper를 이용하여 장애 발생시 자동으로 변경될 수 있도록 한다.
- standby namenode는 secondary namenode의 역할을 동일하게 수행한다. 따라서 HDFS는 고가용성 모드로 설정하였을때는 secondary namenode를 실행하지 않아도 된다.
- 고가용성 모드에서 secondary namenode를 실행하면 오류가 발생한다.
HDFS safemode
- datanode를 수정할 수 없는 상태
- safe mode가 되면 data는 읽기 전용 상태가 되고, 데이터 추가와 수정이 불가능하며 데이터 복제도 일어나지 않는다.
- 관리자가 서버 운영 정비를 위해 세이프 모드를 설정할 수도 있고, namenode에 문제가 생겨서 정상적인 동작을 할 수 없을 때 자동으로 safe mode로 전환된다.
HDFS 데이터 블록 관리
- HDFS 운영중 데이터 노드에 문제가 생기면, 데이터 블록에 문제가 발생할 수 있다.
- CORRUPT 상태
- Under replicated 상태
- HDFS는 heartbeat를 통해 데이터 블록에 문제가 생기는 것을 감지하고 자동으로 복구를 진행한다.
- 다른 데이터 노드에 복제된 데이터를 가져와서 복구한다.
- 하지만 모든 복제 블록에 문제가 생겨서 복구하지 못하게 되면 corrupt가 발생한다.
- corrupt 상태의 파일들은 삭제하고, 원본 파일을 다시 HDFS에 올려주어야 한다.
HDFS 휴지통
- HDFS는 사용자의 실수에 의한 파일 삭제를 방지하기 위해 휴지통 기능을 제공한다
- 휴지통 기능이 설정되면 HDFS에서 삭제한 파일은 바로 삭제되지 않고, 각 사용자의 홈디렉토리 아래 휴지통 디렉토리로 이동된다.
- 휴지통 아래의 파일은 복구할 수 있다.
- 휴지통 디렉토리는 지정한 간격으로 체크포인트가 생성되고, 유효기간이 만료되면 체크포인트를 삭제한다.
- 삭제되면 해당 블록을 해제하고, 사용자에게 반환한다.
HDFS 명령어
- HDFS command는 사용자 커맨드, 운영자 커맨드, 디버그 커맨드로 구분한다.
WebHDFS REST API 사용법
- HDFS는 REST API를 이용하여 파일을 조회하고, 생성, 수정, 삭제하는 기능을 제공한다.
- 이 기능을 이용하여 원격지에서 HDFS의 내용에 접근하는 것이 가능하다.
HDFS 암호화
- HDFS는 민감정보의 보안을 위해 암호화 기능을 제공한다.
- 암호화를 적용하면 디스크에 저장되는 파일을 암호화하여 저장하고, HDFS의 디렉토리에 접근할 때 하둡 KMS를 이용하여 key기반으로 전송 데이터의 암/복호화를 지원한다.
HDFS 사용량 제한 설정
- HDFS 관리자는 디렉토리 별로 파일 개수와 파일 용량을 제한할 수 있다.
데이터 압축
- 데이터 압축 여부와 사용할 압축 형식은 성능에 큰 영향을 줄 수 있다.
- 데이터 압축을 고려해야 할 가장 중요한 두 장소는 MapReduce 작업과 HBase에 저장된 데이터 측면이다.
- 데이터를 압축 및 합축 해제하는 데 필요한 처리 용량, 데이터를 읽고 쓰는데 필요한 디스크 IO 및 네트워크를 통해 데이터를 보내는 데 필요한 네트워크 대역폭의 균형을 유지해야 한다.
- 이러한 요소의 올바른 균형은 사용 패턴뿐만 아니라 클러스터 및 데이터의 특성에 따른다.
- 데이터가 이미 압축된 경우 압축하지 않는 것이 좋다.
RPC
- HDFS는 서버와 클라이언트간 통신에 RPC를 이용한다.
- RPC는 Remote Procedure Call은 원격자에 있는 노드의 함수를 실행하여 결과를 반환할 수 있다.
EC - Eraser Doding
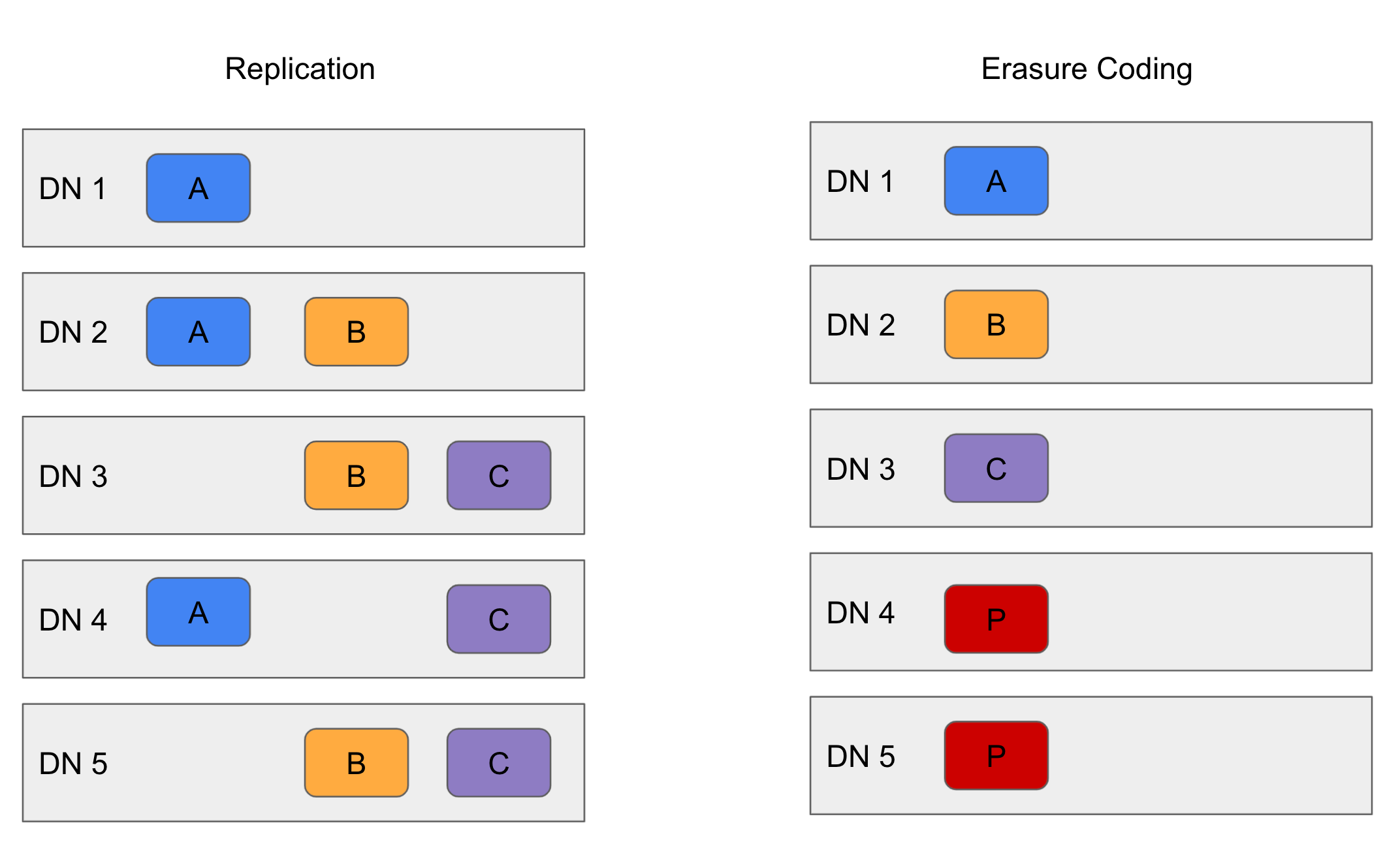
EC 목적
- HDFS는 3x 복제(원본 1개, 복제본 2개, 총 3개)를 이용해서 내결함성을 제공한다
- 복제는 저장 공간, 네트워크 대역폭등에서 200%의 오버헤드를 가지는 것으로 계산된다.
- 상대적으로 낮은 액세스 활동이 있는 콜드 데이터 세트의 경우 추가 블록 복제본은 거의 액세스 되지 않지만 다른 복제본과 동일한 양의 리소스를 소비한다.
- EC는 훨씬 적은 저장공간을 사용하여 동일한 수준의 내결함성을 제공한다.
- 일반적인 EC설정에서 스토리지 오버에드는 50% 이하이다.
- EC는 파일의 복제 개수는 항상 1이며 setrep 명령을 통해 변경할 수 없다.
EC 배경
- 스토리지 시스템에서 EC의 주요 용도는 RAID 구성이다. RAID는 스트라이핑을 통해 EC를 구현한다
- 스토라이핑은 논리적으로 순차적인 데이터(파일)를 더 작은 단위(비트, 바이트 or 블록)로 나누고 연속된 장치를 다른 디스크에 저장한다.
- 원본 데이터 셀의 각 스트라이프에 대해 특정 수의 패리티 셀이 계산되고 저장된다. 이 과정을 인코딩이라 한다.
- 모든 스트라이핑 셀의 오류는 남아있는 데이터 및 패리티 셀을 기반으로 계산을 디코딩하여 복구할 수 있다.
- EC를 HDFS와 통합하면 기존 복제 기반 HDFS 배포와 유사한 데이터 내구성을 제공하면서 스토리지 효율성을 향상시킬 수 있다.
ex) 6개의 블록이 있는 복제파일은 18 블록의 디스크 공간을 사용한다. 하지만 EC(6데이터, 3패리티) 배포를 사용하면 9 블록의 데스크 공간만 사용한다.
EC 구조
- EC의 스트라이핑 이점
- 온라인 EC(EC 형식으로 즉시 데이터 쓰기)를 가능하게하여 변환단계를 피하고 즉시 저장 공간을 절약한다.
온라인 EC는 또한 여러 디스크 스핀들을 병렬로 활용하여 순차 I/O성능을 향상시킨다. 이것은 하이 엔드 네트워킹이 있는 클러스터에서 특히 바람직하다. - 작은 파일을 여러 datanode에 자연스럽게 배포하고 여러 파일을 단일 코딩 그룹으로 묶을 필요가 없다.
이렇게 하면 삭제, 할당량보고 및 연합 namespace간 마이그레이션과 같은 파일 작업이 크게 단순화 된다.
balancer
- HDFS를 운영할 때 데이터 불균형이 발생하면 밸런싱을 실행해야 한다.
- 밸런서는 작업간 많은 데이터 이동이 발생하기 때문에 대역폭을 지정하여 다른 작업에 영향이 가지 않도록 하는 것이 좋다.
데이터 불균형이 발생하는 경우
- 데이터 노드를 추가하는 경우
- 하둡의 데이터 저장 공간이 부족하여 데이터노드를 추가하는 경우 다른 노드의 사용공간은 70~80% 정도인데 신규 데이터노드는 사용공간이 0%
- 대량의 데이터를 삭제하는 경우
- 특정 데이터 노드에 블록이 많이 저장되어 데이터 노드간 저장공간 차이가 20~30% 정도 발생하는 경우
- 대량의 데이터를 추가하는 경우
- 특정 데이터 노드에 데이터가 적은 경우 네임노드는 데이터 저장공간이 적은 노드를 우선적으로 사용하는데, 이 경우 특정 노드로 I/O가 집중된다.

Github - https://github.com/dddwsd