Hadoop - MapReduce
- MapReduce는 대용량의 데이터를 분산 컴퓨팅 환경에서 병렬 처리하여 속도를 높이도록 제작된 데이터 처리 모델이다.
- 간단한 단위작업을 반복하여 처리할 때 사용한다.
- 큰 데이터를 특정 크기의 block으로 나누고 각 block에 대해서 Map task와 Reduce task를 수행한다.
- Map task와 Reduce task는 입력과 출력으로 key-value 구조를 사용한다.
- Map은 처리한 데이터를 (key, value)의 형태로 묶는 작업은 다음 list 형태로 반환한다.
- Reduce는 Map에서 처리한 데이터에서 중복된 key값을 지니는 데이터를 제거하여 합치고, 원하는 데이터를 추출한다.
MapReduce 처리과정
- input
- 데이터를 입력하는 단계
- 데이터를 읽어서 map으로 전달
- map
- 입력을 분할하여 key 별로 데이터를 처리
- combiner
- 네트워크를 타고 넘어가는 데이터를 줄이기 위하여 맵의 결과를 정리
- local reducer라고 함.
- combiner는 작업의 설정에 따라 없을 수도 있음
- partitioner
- map의 출력 결과 key 값을 hash 처리하여 어떤 reducer로 넘길지를 결정
- shuffle
- 각 reducer로 data를 이동
- sort
- reducer로 전달된 데이터를 key 값 기준으로 정렬
- reducer
- reducer로 데이터를 처리하고 결과를 저장
- output
- reducer의 결과를 정의된 형태로 저장
ex) input에서 단어의 개수를 count하는 문제.
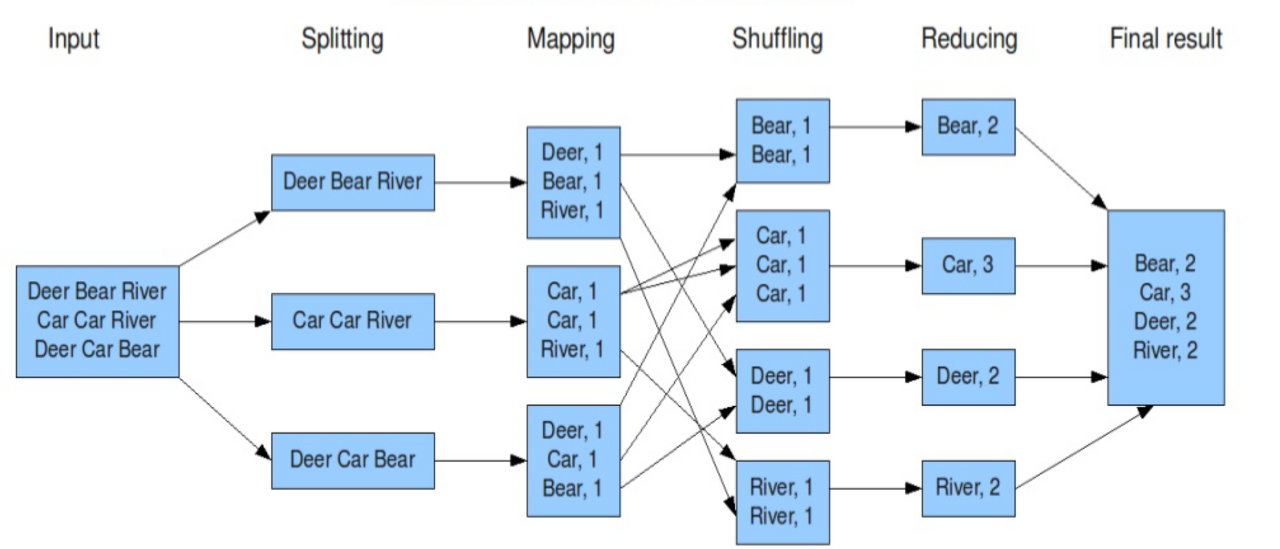
1. 단어의 개수를 세기 위한 텍스트 파일들을 HDFS에 업로드하고, 각각의 파일은 블록단위로 나누어 저장된다.
2. 순차적으로 block을 입력받는데, splitting 과정을 통해 block 안의 텍스트 파일을 한줄로 분할한다.
3. line을 공백기준으로 분리하고, map을 통해 (vocabulary, 1개)의 리스트를 반환한다.
4. shuffling 과정을 통해 연관성있는 데이터들끼리 모아 정렬한다.
5. Reduce(단어, 개수)를 수행하여 각 블록에서 특정 단어가 몇번 나왔는지 계산한다.
6. 결과를 합산하여 HDFS에 파일로 저장한다.
MapReduce의 제어
Map task와 Reduce task는 master node에 존재하는 job tracker에 의해 제어된다.
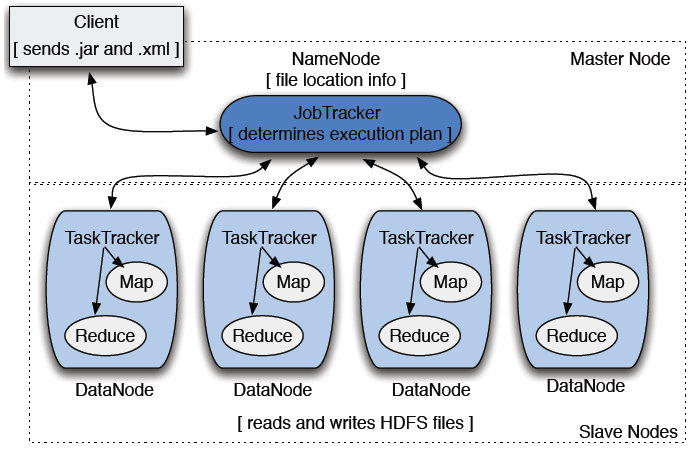
1. client는 job(데이터, Map Reduce 프로그램, 설정 정보 등)을 job trakcer에 보낸다.
2. Job Trakcer는 task tracker들에게 map task와 reduce task를 할당한다.
3. task tracker는 할당받은 map task와 reduce task를 인스턴스화 하여 task를 수행하며 진행상황을 job tracker에게 보고한다.
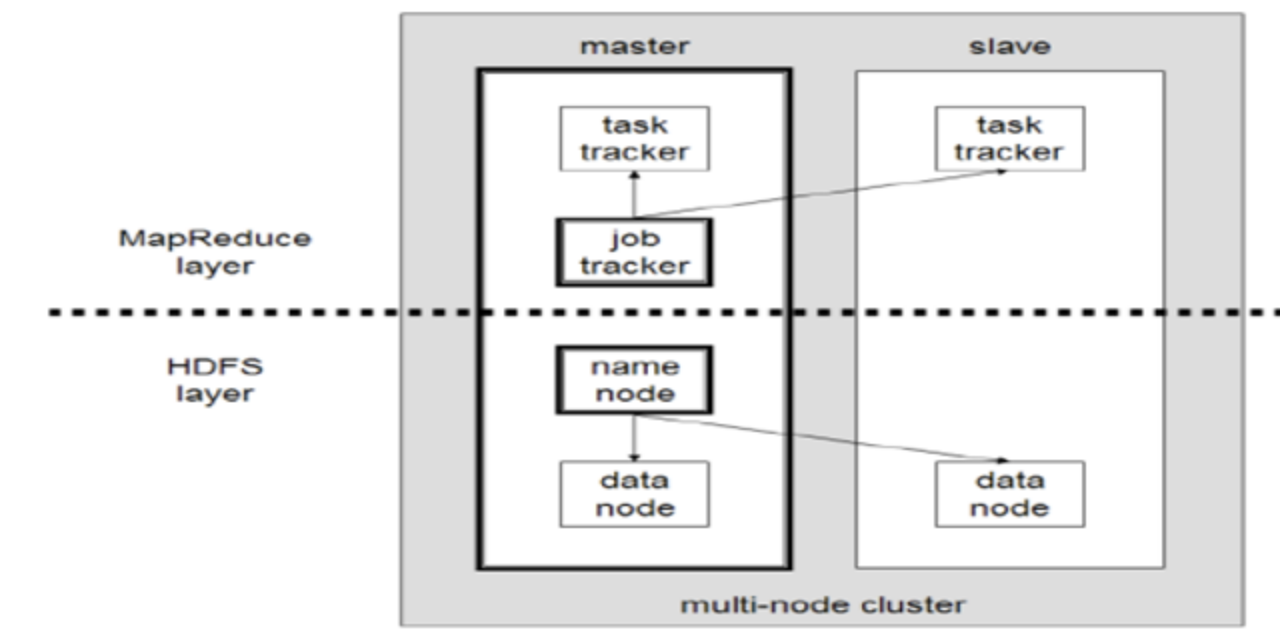
client
- 분석하고자 하는 데이터를 job의 형태로 job tracker에 전달
job tracker
- namenode에 위치
- hadoop cluster에 등록된 전체 job들을 스케줄링하고 모니터링 수행
task tracker
- datanode에서 실행되는 데몬(datanode에 위치)
- 사용자가 설정한 MapReduce 프로그램을 실행
- job tracker로부터 작업을 요청받고, 요척받은 map과 reduce 개수만큼 map task, reduce task 생성
- jobtracker에게 상황보고

Github - https://github.com/dddwsd