Apache Spark
- 빅데이터 처리를 위한 오픈소스 병렬분산처리 플랫폼
- 클라우드의 Apache Hadoop, Apache Mesos, Kubernetes에서 자체적으로 실행될 수 있다.
아키텍쳐
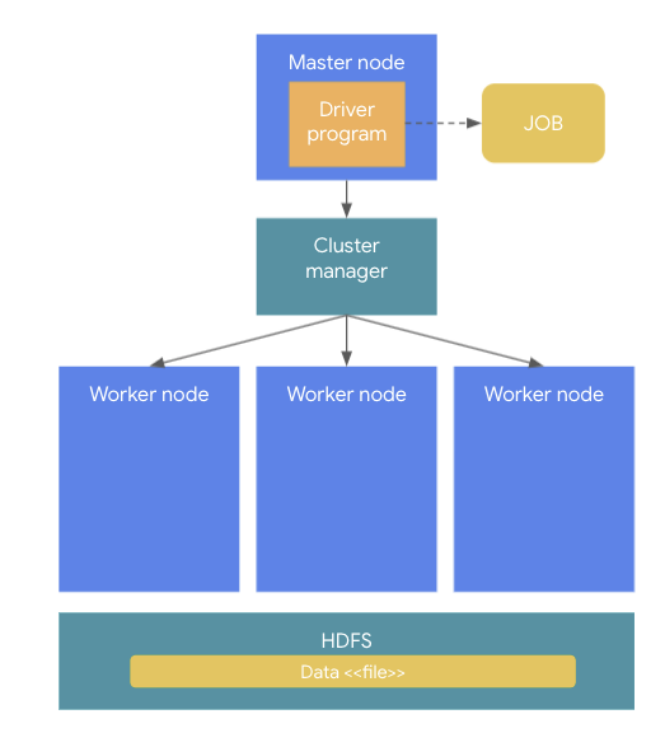
spark application (= spark cluster)
- 실제 task를 수행하는 역할을 담당
- spark cluster는 master node와 worker node로 구성된다.
- 1개의 spark application에는 1개의 driver와 n개의 executor가 존재한다.
- executor는 cluster manager에 의하여 해당 spark application에 할당되며, spark application이 완전히 종료되면 할당에서 해방된다.
- 따라서 서로 다른 spark application간의 직접적인 데이터 공유는 불가능하다.(각 spark application이 별도의 JVM process에서 동작하므로)
spark driver (= master node)
- driver는 한 개의 node(=master node)에서 실행되며, spark 전체의 main 함수를 실행한다.
- apllication 내의 정보의 유지 관리
- executor의 실행 및 실행 분석, 배포 등의 역할을 수행한다.
- user가 구성한 job을 task 단위로 변환하여, executor에 전달한다.
executor
- 다수의 worker node에서 실행되는 process
- spark driver가 할당한 task를 수행하여 결과를 반환한다.
- block manager를 통해 cache하는 RDD를 저장한다.
cluster manager
- 클러스터 내의 worker resource를 관리하고 task를 배치하는 역할.
- spark는 데이터 분산처리를 위해 하나의 cluster내에 여러 worker가 존재
- 하나의 job이 여러 worker에 분산되어 처리하기 위해 여러 task로 나눈 다음, 여러 서버에 분산해서 배치해야 함.
- 클러스터 내의 worker 들도 관리해야함.
- cluster manager의 종류는 Standalone, Yarn, Mesos, Kubernetes가 있다
- Standalone
- 하나의 머신 내에서 spark를 운영하는 방식으로 로컬 개발 환경에 적합.
- spark driver와 executor는 각각 thread로 동작한다.
- worker node 하나당 한개 씩 동작한다.
- Yarn, Mesos, k8s
- worker node에 여러개의 executor를 실행시킬 수 있다.
storage
- in-memory로 데이터를 처리하지만 external storage를 포함하고 있지 않기 때문에 따로 사용해야 한다.
- cloud의 경우 hadoop의 HDFS, AWS S3, GCP GCS등이 있다
- DB의 경우 분산 노드에서 데이터를 동시에 읽어야 하기 때문에 분산 처리를 잘 지원하는 HBase(NoSQL)이 널리 사용된다.
File format
- csv, json
- text 기반으로, 사람이 읽을 수 있지만 압축되지 않아 용량이 크다
- Parquet(Column base)
- binary format이다.
- data, column, data type 등의 메타 데이터를 포함한다.
- 압축 알고리즘을 사용하고 snappy와 같은 압축 방식을 사용했을때, 원본 데이터 대비 75%까지 압축이 가능하다.
- WORM(Write Once Read Many)라는 특성이 있어, 쓰는 속도는 느리지만, 읽는 속도가 빠르다. 그리고 column 단위로 저장하기 때문에, 전체 테이블에서 특정 column만 query할 때 빠르다.
- Avro(Row base)
- binary format이다.
- binary로 데이터를 저장하고 schema는 json에 별도로 저장한다.
- 그래서 binary 파일을 이해할 필요가 없고, json으로 전체적인 데이터 포맷에 대한 이해가 가능하다.
- write가 많은 workload에 적합
Spark application flow
- user가 spark-submit을 통해 application을 실행한다.
- driver가 main()을 실행하며, SparkContext를 생성한다.
- SparkContext가 cluster manager와 연결된다.
- driver가 cluster manager로부터 executor 실행을 위한 resource를 요청한다.
- SparkContext는 작업 내용을 task 단위로 분할하여 executor에 보낸다.
- executor는 각각 작업을 수행하고, 결과를 저장한다.
in-memory
- spark는 in-memory
- in-memory(디스크에 저장되어 있는 데이터를 메모리로 읽어와서 처리) 기반의 데이터 처리로 빠르다
- spark는 데이터의 읽기/쓰기 속도는 빠르지만, 메모리 용량만큼의 데이터를 한번에 처리할 수 있다.
- hadoop은 디스크로부터 데이터를 불러오고 결과를 디스크에 쓴다. 따라서, 데이터의 읽기/쓰기 속도는 느리지만 디스크 용량만큼의 데이터를 한번에 처리할 수 있다
- spark는 hadoop대비 처리속도가 최소 10배에서 100배 빠르다.
- apllication 형태의 bigdata 통합환경 제공(데이터 추출, 정제, 통계분석 및 적제를 한번에)
- micro batch를 통해 실시간에 근접한 응답성 제공.
- 최초 데이터 로드와 최종 결과 저장시에만 disk 사용
- 메모리에 분산 저장하고, 병렬 처리 구조.
- 다양한 언어 지원(Java, Scala, Python, R)
Spark component
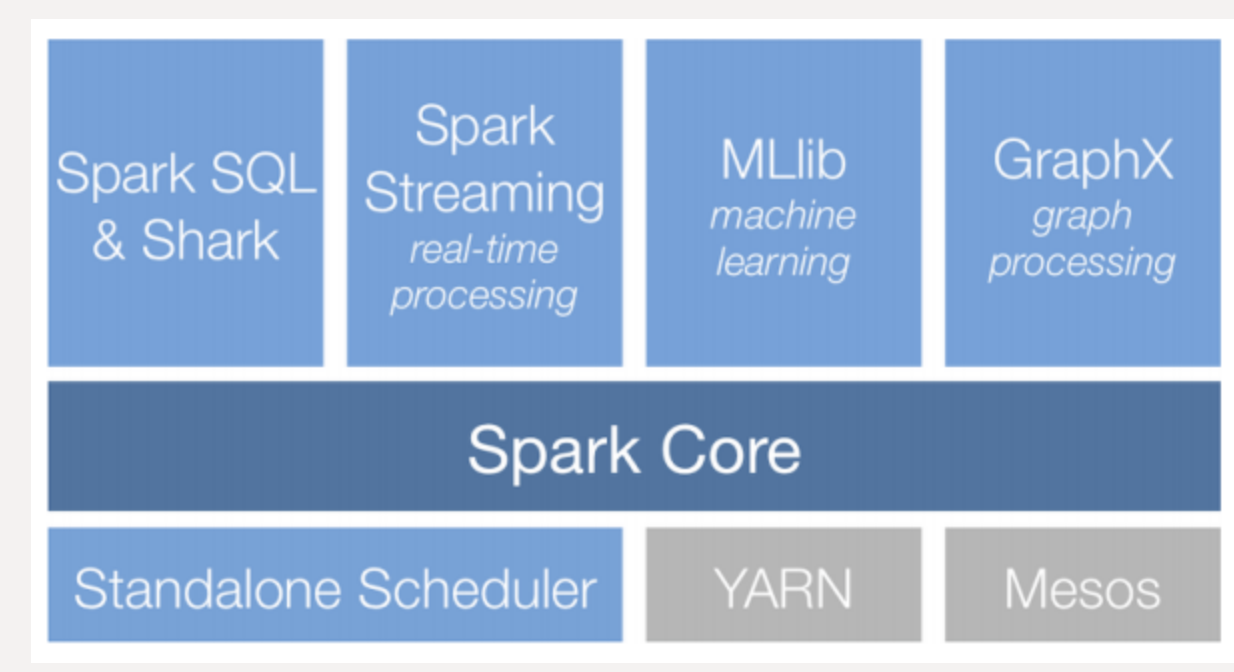
- Spark Core
- 스케줄링, 메모리 관리, 장애복구와 같은 기본적인 기능과 RDD, DataFrame, DataSet을 이용한 스파크 연산 처리를 담당
- Spark SQL
- RDD, Dataset, DataFrame 작업을 생성하고 처리하며, Hive 메타스토어와 연결하여 Hive의 메타정보를 이용하여 SQL 작업을 처리할 수 있음.
- Spark Streaming
- 실시간 데이터 스트림을 처리하는 컴포넌트
- MLlib
- classification, regression, clustering, collaborative filtering 및 모델 평가 등이 가능한 ml library
- GraphX
- 분산형 그래프 프로세싱을 지원하는 컴포넌트

Github - https://github.com/dddwsd