Spark API
RDD
- RDD = Resilient Distributed Datasets
- Resilient = 회복력 있는 = 데이터 처리 과정에서 문제 발생- 해도 스스로 복구할 수 있음을 의미
- RDD는 파티션 단위로 나뉘고, 여러 머신에서 파티션들을 분산처리하므로 대용량 데이터를 다룰 수 있다. = 병렬처리가 가능하다.
immutable
- RDD는 read only이기 때문에 immutable 하다.
lineage & fault tolerance
- 따라서 transformation이나 action을 위해서는 새로운 RDD가 생성된다. 이렇게 생성되는 RDD순서를 lineage라고 한다.
- RDD lineage는 DAG 형태(노드간의 cycle이 없으며, 방향성이 일정)를 가진다.
- Lineage에 모든 RDD 생성 과정이 기록되어 있기 때문에 메모리에서 데이터가 유실되면 기록에 따라 유실되었던 RDD를 다시 생성할 수 있다.
transformation & action
- RDD가 제공하는 method는 크게 transformation과 action으로 나뉜다.
- transformation은 RDD의 변형을 일으키는 연산이지만, 실제로 동작이 수행되지는 않는다.
- transformation은 크게 두가지로 나뉜다.
- transformation 전의 RDD가 가지는 요소를 같은 RDD의 다른 요소들과 관계없이 처리할 수 있는 방식.
- filter
- map
- flatmap
- zip
- transformation 전의 RDD 요소를, 같은 RDD의 다른 요소와 함께 처리하는 방식.
- 같은 키를 가지는 요소들을 한 곳에 모아 처리하는데, 이 때 같은 키를 가지는 요소가 전부 같은 파티션에 있도록 요소의 자리를 바꾸는 것을 shuffle이라고 한다.
- reduceByKey - 같은 키를 가지는 요소를 aggregation
- join - 두 RDD의 같은 키를 가지는 요소끼리 join
- transformation 전의 RDD가 가지는 요소를 같은 RDD의 다른 요소들과 관계없이 처리할 수 있는 방식.
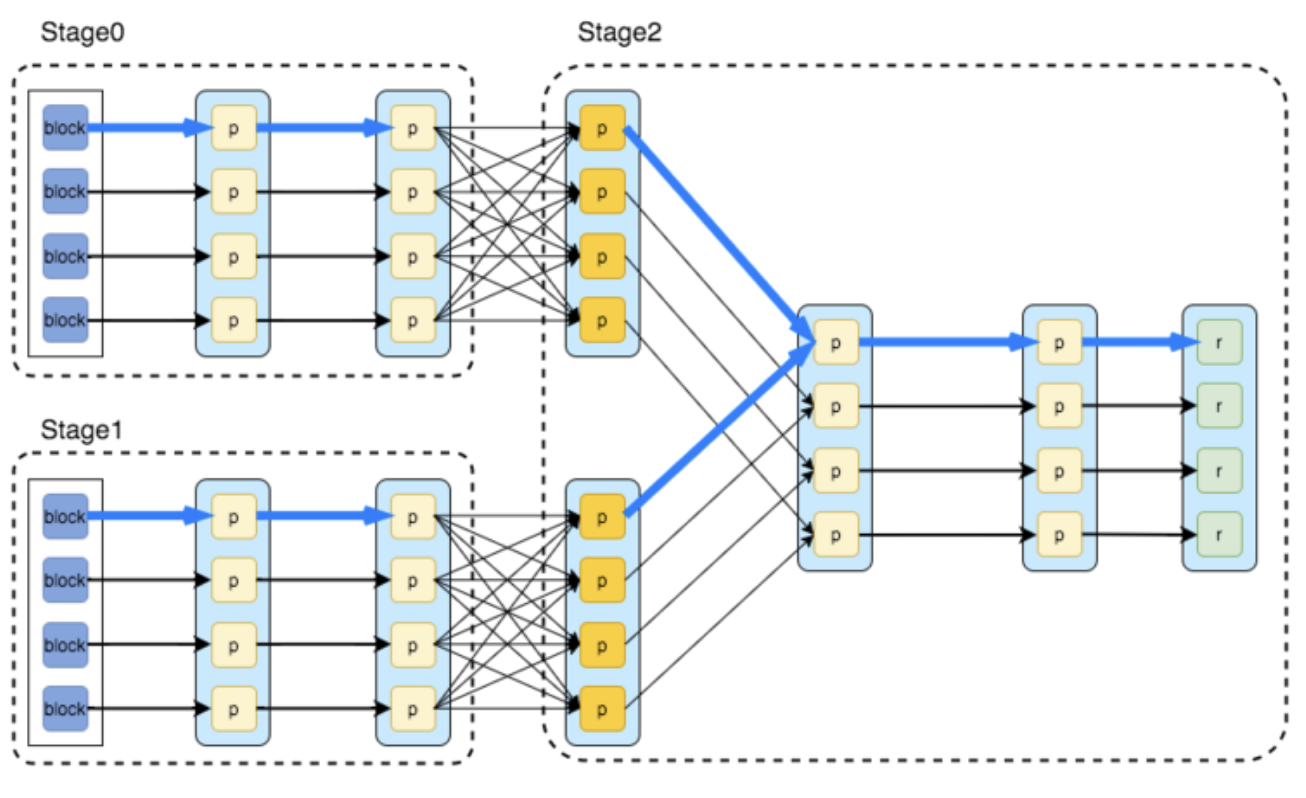
- action은 lineage에 기록된 RDD 생성과정을 실제로 생성하는 명령어다.
- spark에서 작업이 시작되면 stage 단위로 분할되고 이것은 다시 여러개의 task로 나누어 실행된다.
- 사용하는 함수가 RDD를 return하면 transformation, RDD외의 다른 데이터 타입을 return하면 action이다.
- RDD는 action이 실행되어야 연산을 시작하는 것을 lazy evaluation이라 한다.
- lazy evaluation을 통해 transformation간의 RDD 생성경로를 최적화 한다.
- 최적의 RDD 생성경로는 각 노드에 저장된 데이터의 셔플이 최소한으로 일어나는 것을 의미한다.
- action은 결과값을 계산하며 그 값을 driver에 되돌려주거나 external storage에 저장가능하다.
cache & persist
-
cache() = persist(MEMORY_ONLY)
-
동일한 RDD에 action이 여러번 일어나게 되면(RDD를 재사용하게 되면) lineage에 기록된 연산들을 여러번 진행하게 된다.
-
이럴 경우 persist()를 사용하게 되면 해당 지점까지 RDD를 계산한 node들은 partition을 저장하고, action이 일어날 경우 persist()된 지점에서 파티션을 가져오기 때문에 재연산이 일어나지 않는다.
-
persist()가 일어나는 조건
- shuffle이 발생하는 transformation을 실행하기 직전의 RDD
- 사용자가 선언한 경우
- 사용자가 driver에서 선언하면 executor는 해당 RDD에 포함된 partition의 persistance를 시도한다.
-
RDD의 partition이 하나도 persist되지 않았으면 전체가 persist 되지 않은 것이다.
-
RDD의 partition이 전부 persist되면 RDD 자체가 persist 된 것이고, 해당 RDD의 instance를 다시 만들기위해 연산을 할 필요가 없다.
-
excecutor가 고장나서 shuffle 실행시 partition persist에 실패하거나, persist선언시 일부 executor가 실패했을 경우, partition이 부분적으로 persist되고, 재연산시 persist에 실패한 partition만 다시 스케줄링되며 executor는 다시 persist에 시도한다.
-
메모리가 부족할 경우 LRU에 따라 사용한지 가장 오래된 파티션을 제거한다.
RDD 단점
- 메모리나 디스크가 충분해야 한다.
- schema 개념이 없다.
- 구조화된 데이터와 비구조화된 데이터를 함께 저장하여 효율성이 떨어진다.
- serialization(데이터를 배포하거나 디스크에 데이터를 기록할때마다 JAVA serialization사용)과 garbage collection(사용하지 않는 객체를 자동으로 메모리 해제)를 사용하기 때문에, memory overhead 증가
- 사용자가 직접 optimize 해야함.
DataFrame (Spark 1.3)
- 구조화된 데이터를 다루기 쉽게 만들어졌고 데이터를 스키마 형태로 추상화하여 테이블로 다룰 수 있다.
- catalyst optimizer가 쿼리를 최적화하여 처리.
- 데이터를 off-heap(RAM 영역 - garbage collection의 영향을 받지 않음)에 저장하기 때문에, garbage collection의 overhead를 감소시켰다.
- off-heap memory를 사용한 serialization을 통해 overhead 감소
- 다양한 형태의 데이터를 지원하여 효율성이 뛰어남.
DataSet (Spark 1.6)
- spark 2.0부터 spark SQL의 메인 API로 지정되었으며, 데이터의 타입체크, 데이터 직렬화를 위한 인코더, 카탈리스트 옵티마이저를 지원하여 데이터 처리 속도를 더욱 증가시킴.

Github - https://github.com/dddwsd