Hive
Hive는 hadoop ecosystem에서 데이터를 모델링하고 프로세싱 하는 경우 가장 많이 사용하는 data warehouse solution이다.
cf) data warehouse란?
-
사용자의 의사 결정에 도움을 주기 위하여, 기간시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리하는 데이터베이스를 의미한다.
-
HDFS에 저장된 데이터 구조를 정의하는 방법을 제공하며, 이 데이터를 대상으로 SQL과 유사한 HiveQL 쿼리를 이용하여 데이터를 조회하는 방법을 제공한다.
구성요소
- UI
- 사용자가 쿼리 및 기타 작업을 시스템에 제출하는 UI
- CLI JDBC 등
- Driver
- 쿼리를 입력받고 작업을 처리
- 사용자 세션을 구현하고, JDBC/ODBC 인터페이스 API제공
- Compiler
- 메타 스토어를 참고하여 쿼리 구문을 분석하고 실행계획을 생성
- Metascore
- 디비, 테이블, 파티션의 정보를 저장
- Execution Engine
- 컴파일러에 의해 생성된 실행 계획을 실행
동작원리
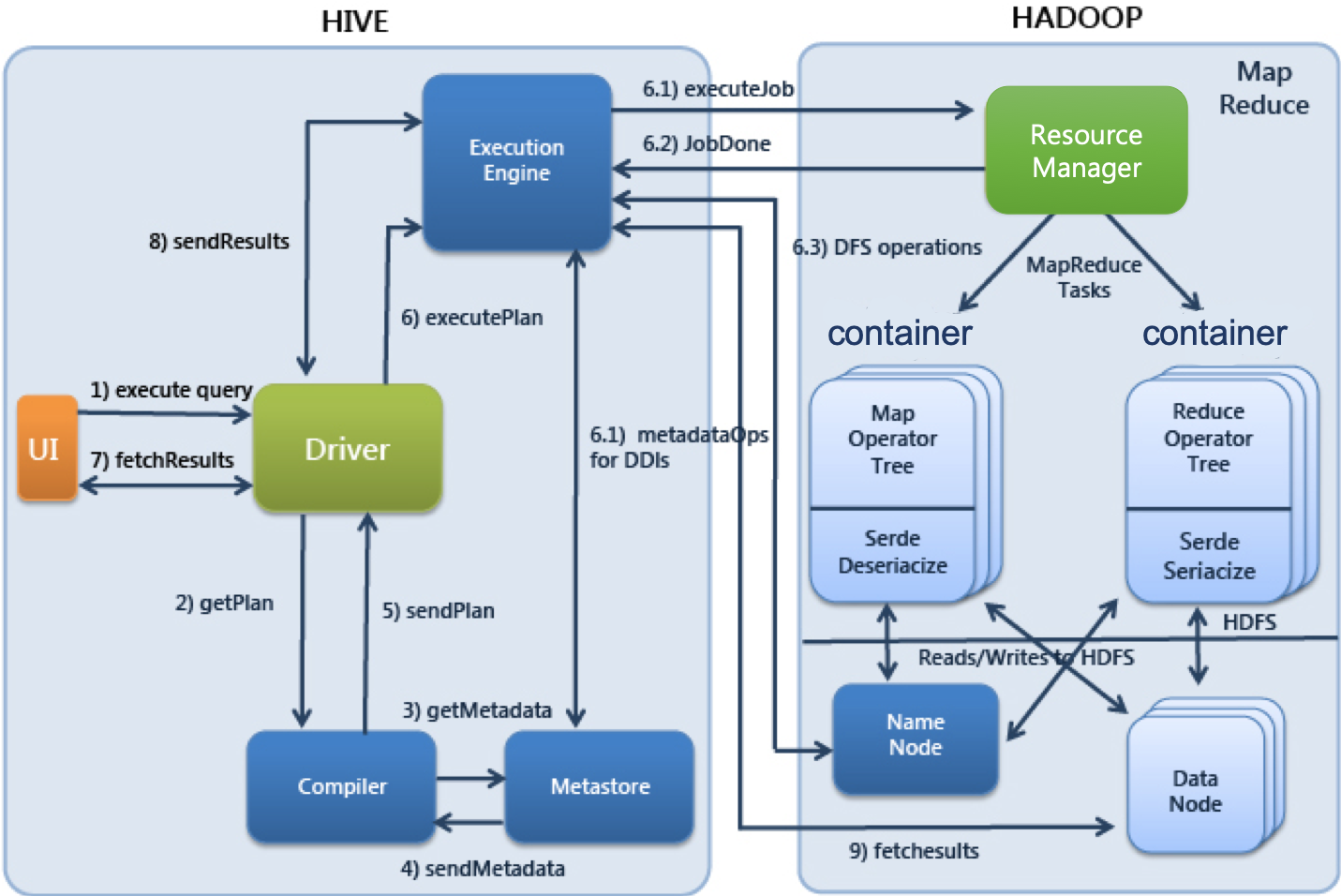
1. 사용자가 제출한 SQL문을 드라이버가 컴파일러에 요청하여 메타스토어의 정보를 이용해 처리에 적합한 형태로 컴파일한다.
2. 컴파일된 SQL을 execution engine으로 실행
3. 리소스 매니저가 클러스터의 자원을 적절히 활용하여 실행한다.
4. 실행 중 사용하는 원천데이터는 HDFS등의 저장장치를 이용한다.
5. 실행결과를 사용자에게 반환한다.

Github - https://github.com/dddwsd