docs - https://docs.feast.dev/
Feast란 무엇인가?
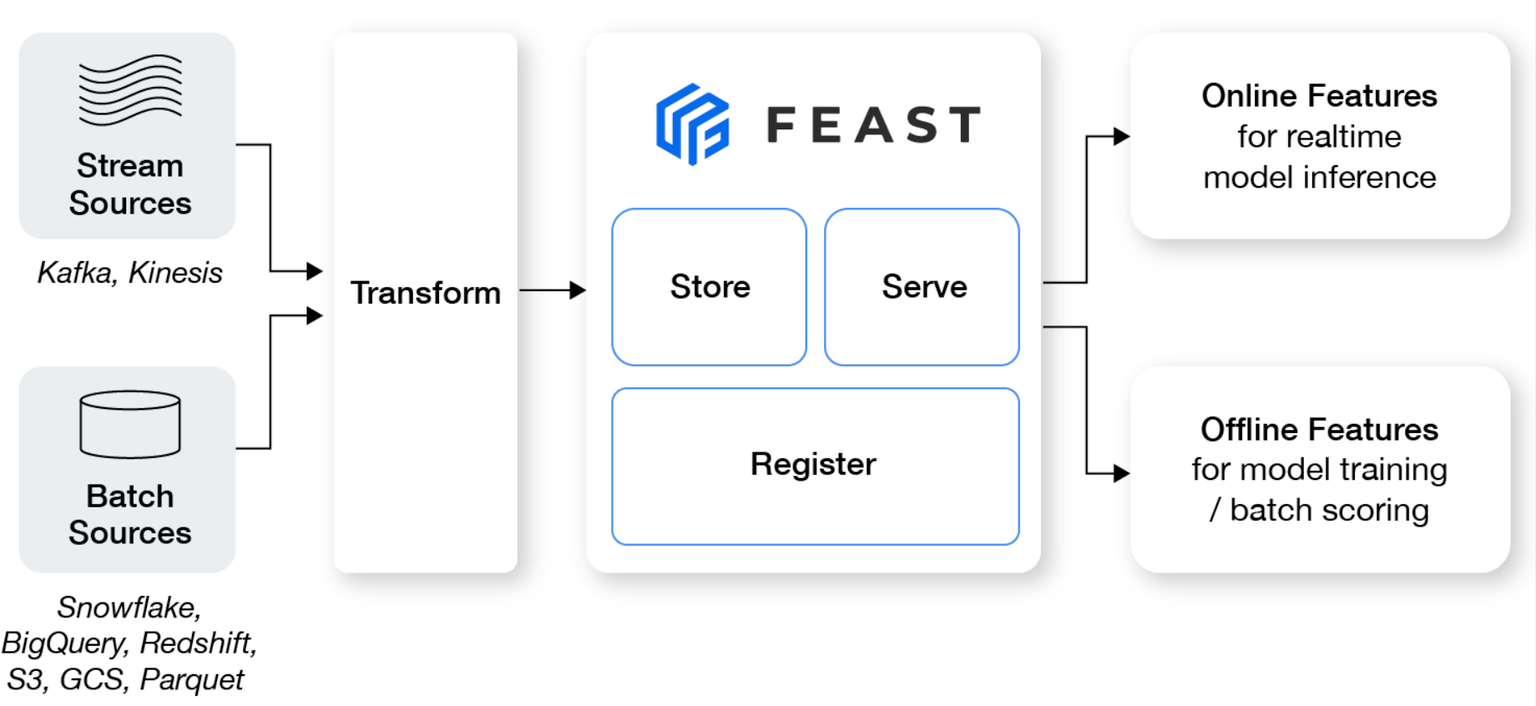
Feast는 Feature Store를 의미하며, 존재하는 인프라를 재사용하여 머신러닝 feature들을 realtime model들로 관리하고 제공하는 시스템이다.
주요 기능
- offline and online store를 관리하고, 검증된 feature server를 통해 사전 계산된 기능을 online으로 제공하여 학습과 서비스에 일관된 feature를 사용할 수 있도록 한다.
- 데이터 유출 방지를 통해 특정 시점에 올바른 feature를 생성함으로써 dataset join 로직 디버깅보다 feature engineering에 집중할 수 있게 해준다
- feature storage와 검색을 추상화하는 single data access layer를 제공함으로써 ML과 데이터 인프라를 분리한다. 이를 통해 모델의 휴대성을 보장할 수 있다.
제공하지 않는 것들
- ETL/ELT 시스템: Feast는 일반적인 데이터 변환 또는 파이프라인 시스템이 아님.
- 데이터 오케스트레이션 도구: 복잡한 워크플로우를 관리하거나 오케스트레이션을 하지 않음. 대신 상위 데이터 파이프라인에 의존하여 기능 값을 생성하고, Airflow와 같은 도구와의 통합을 통해 feautre를 일관되게 사용할 수 있게 한다.
- 데이터 웨어하우스: Feast는 데이터 웨어하우스를 대처하거나 조직 내 모든 변환된 데이터의 신뢰 가능한 출처 역할을 하지 않는다. 대신 기존 데이터 웨어하우스에서 데이터를 가져와 production에서 모델에 제공하는 경량 하위 계층이다.
- 데이터베이스: Feast는 데이터베이스가 아니며, 다른 시스템(BigQuery, Snowflake, Redis 등)에 저장된 데이터를 관리하여 학습 및 서빙 시 일관된 feature를 제공하는데 도움을 준다.
fully 해결할 수 없는 것들
- 재생할 수 있는 모델 학습 / 모델 백테스팅 / 실험 관리: Feast는 feature와 model metadata를 캡쳐하지만, 데이터셋/레이블의 버전 관리나 학습/테스트 분할을 지원하지 않는다. 이런 작업들은 DVC, MLflow, Kubeflow가 더 적합하다
- batch + streaming feature engineering: 주로 이미 변환된 feature를 처리하고 있고 batch나 streaming 변환을 지원하기 위해 노력하고 있음
- native streaming feature integration: streaming feature를 유저가 직접 push할 수 있게 하지만, streaming source(kafka, kinesis)에서 pull하거나 streaming pipeline(Flink와 같은 스트리밍 프레음워크를 사용하여 파이프라인을 구서앟고, 이 데이터를 직접 push해야 한다.)을 관리할 수는 없다.
- feature sharing: feature metadata 검색 및 카탈로그화를 위해 web ui를 통해 실험적으로 제공하고 있다.
- lineage: feature를 모델 버전과 연결하는데 도움을 주지만, raw data에서 모델 버전까지의 e2e lineage를 캡쳐하는 솔루션은 아니다.
- 데이터 품질 / 드리프트 감지: 데이터 드리프트나 데이터 품질 문제를 해결하기 위해 설계된 도구는 아니며, 이러한 문제는 데이터 파이프라인, 제공된 feature 값, 모델 버전 전반에 걸친 정교한 모니터링으로 해결할 수 있다.
Use cases
- 사전 계산된 이력 사용자 또는 아이템 feature를 활용하여 온라인 추천 개인화
- 사전 계산된 이력 거래 패턴과 비교하는 feature를 사용하여 온라인 사기 감지
- 정해진 주기마다 모든 사용자에 대해 배치로 feature를 생성하는 오프라인 이탈 예측 모델
- 사전 계산된 이력 feature를 사용하여 default 확률을 계산하는 신용 점수 산정
결론
Feast는 다양한 feature를 관리하고 제공하는데 중점을 두고 있어, 사전 계산된 feature를 활용하여 모델 학습과 서빙을 효율적으로 수행할 수 있는 경우나 대규모 사용자 데이터, 실시간 데이터, 정기적인 feature 생성이 필요한 ML 시스템에서 유용하게 사용될 수 있다.
쉽게 말해 전처리된 feature를 관리, 저장, 제공하여 재사용성과 일관성을 높인다.
cf)
1. Data Lake: 모든 유형의 raw data를 저장하는 유연한 저장소로 빅데이터 처리 및 분석에 사용된다.
2. Data Warehouse: 구조화된 데이터를 사전에 정의된 스키마로 저장, 관리, 분석하는 고성능 데이터 저장소.
3. Data Catalog: 조직 내 데이터 자산의 메타데이터를 관리하여 데이터 검색, 이해, 거버넌스를 지원하는 도구.

Github - https://github.com/dddwsd