REST API
REST API에서 REST는 “Representational State Transfer”의 약자로, 로이 필딩 (Roy Fielding)의 박사학위 논문에서 웹(http)의 장점을 최대한 활용할 수 있는 아키텍처로써 처음 소개되었다. REST API는 웹에서 사용되는 데이터나 자원(Resource)을 HTTP URI로 표현하고, HTTP 프로토콜을 통해 요청과 응답을 정의하는 방식이다.
API가 메뉴판과 같다고 했다. 그렇다면 메뉴판이 다음과 같이 되어있다고 생각해보자.

(하지만꽃이 생각나는 그래서 주...)
메뉴판(API)가 비정상이라면 주문(request)가 제대로 될 리 없고, 때문에 주문의 결과(response)도 정상일 리 없다. 때문에 REST와 같은 규칙을 지키는 것이다.
REST API는 일종의 가이드라인이다. 때문에 API를 만들 때 반드시 지켜야한다! 라는 것은 아니지만, 이미 업계에 표준처럼 자리잡았기에 지키는 것이 좋다(그냥 지키자).
REST가 의미하는 바는 무엇인가?
REpresentational State Transfer을 줄여서 REST라고 표현했다. 그렇다면 REpresentational State는 무슨 뜻일까? Represent는 대(신)표(현)한다는 뜻이 있다. 그렇다면 REpresentational State는 '대신 표현하는 상태'일 것이다. 여기서 무엇의 상태인가? 라고 한다면 서버가 가지고 있으며 클라이언트가 필요로하는 자원(리소스)의 상태라고 할 수 있다. 즉, 리소스가 표현된 상태를 교환하는 것이다.
'클라이언트는 자원을 달라고 했는데 왜 자원의 상태를 주지..?'라는 생각이 들어 매우 이해가 어려웠다. 찾아본 결과, API는 자원 그 자체를 교환해주는 것이 아니다.
일반적으로 GET 메서드를 통해 리소스를 요청하면 서버는 리소스를 응답에 담아준다. 일반적으로 이를 성공적으로 리소스를 담아왔다고는 표현하지만, 사실 해당 리소스 자체는 응답으로 받아온JSON데이터가 아니다. 서버에서 응답해준 JSON데이터는 단순히 리소스를 JSON데이터로 표현한 것일 뿐이다.(진짜 JSON데이터로 저장된 리소스일 수 있으나 그 가능성은 당연히 치우고 생각하자...)
그렇다면 다시한번 '대신 표현하는 상태'를 보자. 우리가 받아오는 데이터가 사실 원본이 아니라 원본의 설명이라고 생각하면 이를 '(원본 리소스) 대신 (JSON데이터로)표현한 상태'라고 볼 수 있다. 때문에 클라이언트는 사실 원본 리소스를 받은게 아니라 원본을 표현한 상태를 받아온 것이다.
REST API를 작성할 때 지켜야 할 규칙
로이 필딩의 논문에 더해, 좀 더 실용적인 제작을 위해 몇가지 규칙들이 만들어졌다.
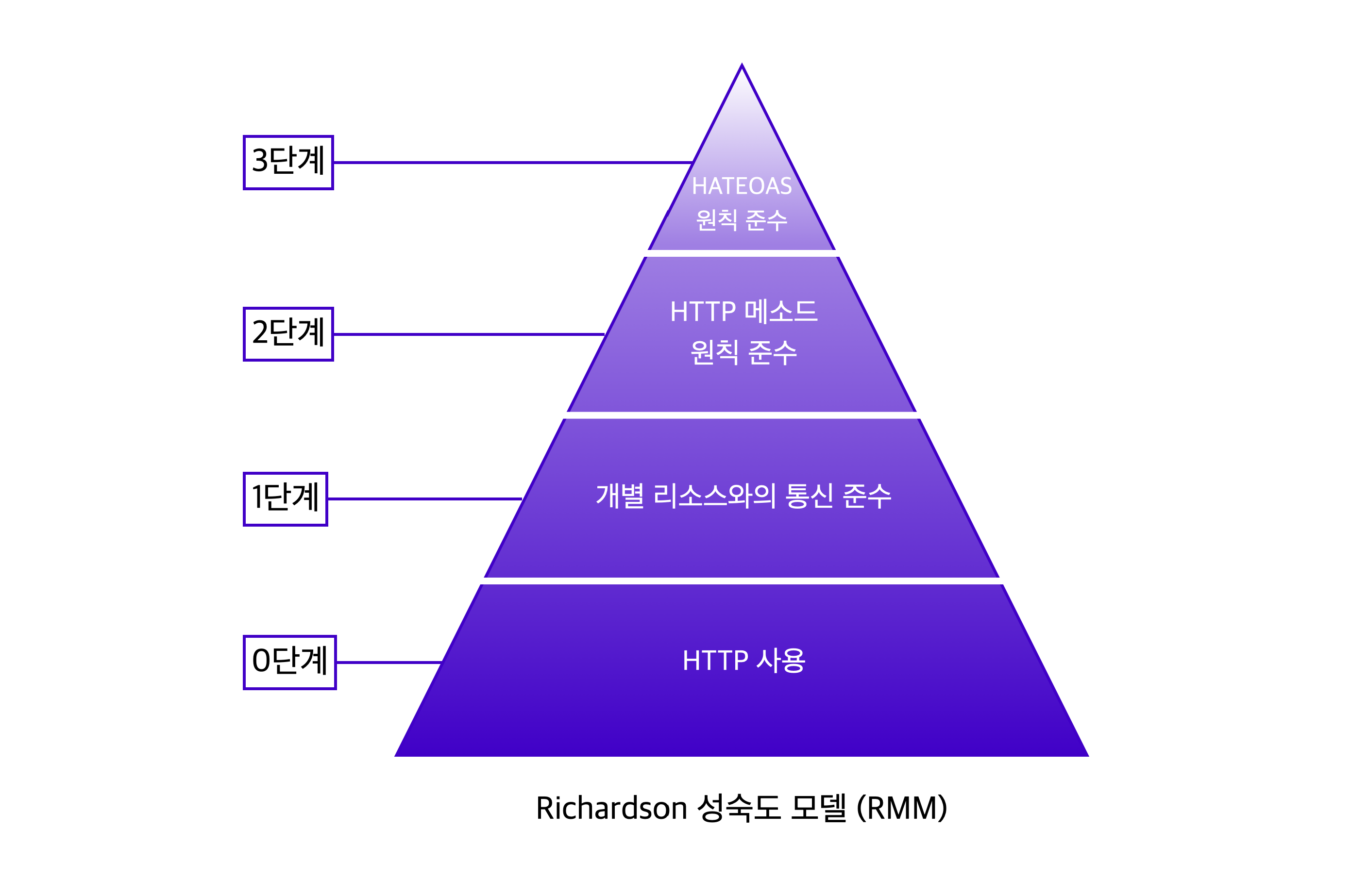
REST 성숙도 모델은 총 4단계(0~3단계)로 나누어진다. 로이 필딩은 이 모든 단계를 충족시켜야만 REST API라 할 수 있다고 주장한다. 다만, 3단계까지 충족하는 것은 매우 어렵기 때문에 2단계까지만 지켜도 좋은 API 디자인이라고 볼 수 있고, 이런 경우를 HTTP API라 부른다.
0단계: HTTP 사용

0단계에서는 단순히 HTTP 프로토콜을 사용하기만해도 된다. 단, 이 경우는 REST API라고 부를 수 없으며 REST API를 위한 가장 기초단계라고 생각하면 된다.
1단계: 개별 리소스와의 통신 준수

REST API는 웹에서 사용되는 모든 데이터나 자원(Resource)을 HTTP URI로 표현한다. 따라서 모든 자원은 개별 리소스에 맞는 엔드포인트(Endpoint)를 사용해야하며 요청하고 받는 자원에 대한 정보를 응답으로 전달해야 한다는 것이 1단계의 핵심이다. 어떤 리소스를 변화시키는지 혹은 어떤 응답이 제공되는지에 따라 각기 다른 엔드포인트를 사용하기 때문에, 적절한 엔드포인트를 작성하는 것이 중요하다.엔드포인트 작성 시에는 동사, HTTP 메서드, 혹은 어떤 행위에 대한 단어 사용은 지양하고, 리소스에 집중해 명사 형태의 단어로 작성하는 것이 바람직한 방법이다. 요청에 따른 응답으로 리소스를 전달할 때에도 사용한 리소스에 대한 정보와 함께 리소스 사용에 대한 성공/실패 여부를 반환해야 한다.
2단계: CRUD에 맞게 적절한 HTTP 메서드를 사용

단 5가지의 메서드로도 CRUD에 맞게 API를 만들 수 있다.
- GET - 리소스를 변화시키지 않는 단순한 조회
- PUT - 리소스를 교체한다.
- POST - 리소스를 생성한다.
- DELETE - 리소스를 삭제한다.
- PATCH - 리소스를 수정한다.
일반적으로 2단계까지 해도 잘 디자인 된 API라고 한다.
PUT vs PATCH
PUT은 리소스를 '요청에 있는 바디에 담긴 것'으로 교체하는 것이고 PATCH는 리소스의 일부분만을 수정하는 것이다. 즉, PUT은 수정하지 않을 부분까지 모두 보내야 한다.
PUT의 멱등성
멱등성이란 연산을 여러번 적용해도 결과가 같은 성질을 말한다. PUT은 만약 바디에 담은 리소스가 서버의 자원에 존재하지 않을 경우 새로운 리소스를 만든다. 하지만 한번 리소스가 만들어졌다면, 같은 요청을 보냈을 때 더이상 새로운 리소스가 만들어지지 않는다. 하지만 POST의 경우 같은 리소스를 계속해서 요청에 담아 보내면 서버에서는 계속해서 같은 자원이 만들어진다. PUT과 같이 계속해서 똑같은 리소스가 반환되는 경우, 멱등성을 가진다 라고 말한다.
4단계: HATEOAS(Hypertext As The Engine Of Application State) 적용

3단계의 요청은 2단계와 동일하지만, 응답에는 리소스의 URI를 포함한 링크 요소를 삽입하여 작성해야한다. 만약 병원 예약의 경우, 시간을 확인하는 요청을 받으면 그 시간대에 예약을 할 수 있는 링크를 넣거나, 예약을 완료한 경우 예약을 다시 확인할 수 있는 링크를 넣는 것이다. 이렇듯 3단계의 핵심은 응답에 새로운 기능에 접근할 수 있는 링크를 삽입하는 것이다.
OPEN API
오픈 API(Open Application Programming Interface, Open API, 공개 API) 또는 공개 API는 개발자라면 누구나 사용할 수 있도록 공개된 API를 말하며, 개발자는 이를 이용해 프로그램을 만들 수 있다. (반대는 프라이빗 API(Private API)) 다시 말해, 하나의 웹 사이트에서 자신이 가진 기능을 타인이 가져가 개인적으로 이용할 수 있도록 만들 것이다. 네이버, 구글에도 오픈API가 있으며, 우리나라 공공데이터 포털에도 오픈 API를 제공받을 수 있다. 그러나 '오픈'이라는 말은 누구에게나 열려있다는 뜻은 맞지만, '무한정'으로 이용할 수 있다는 말은 아니다. API마다 정해진 이용 수칙이 있고, 그 이용 수칙에 따라 제한사항(가격, 정보의 제한 등)이 있을 수 있다.
예를 들어 네이버의 오픈 API의 경우
이렇게 다양하게 제공하고 있으며, 다른 사이트에서 네이버로 로그인하는 기능 역시 네이버 로그인의 API를 이용한 것이다.
API KEY
API를 이용하기 위해서는 API Key가 필요하다. API key는 서버의 문을 여는 열쇠이자 식별방법이라 할 수 있다. 서버를 운용하는 데에 비용이 발생하기 때문에 서버 입장에서 아무런 조건 없이 익명의 클라이언트에게 데이터를 제공할 의무는 없다. (가끔 API key가 필요하지 않은 경우도 있다.)
API Key가 필요한 경우에는 로그인한 이용자에게 자원에 접근할 수 있는 권한을 API Key의 형태로 제공하고, 데이터를 요청할 때 API key를 같이 전달해야 원하는 응답을 받을 수 있다.
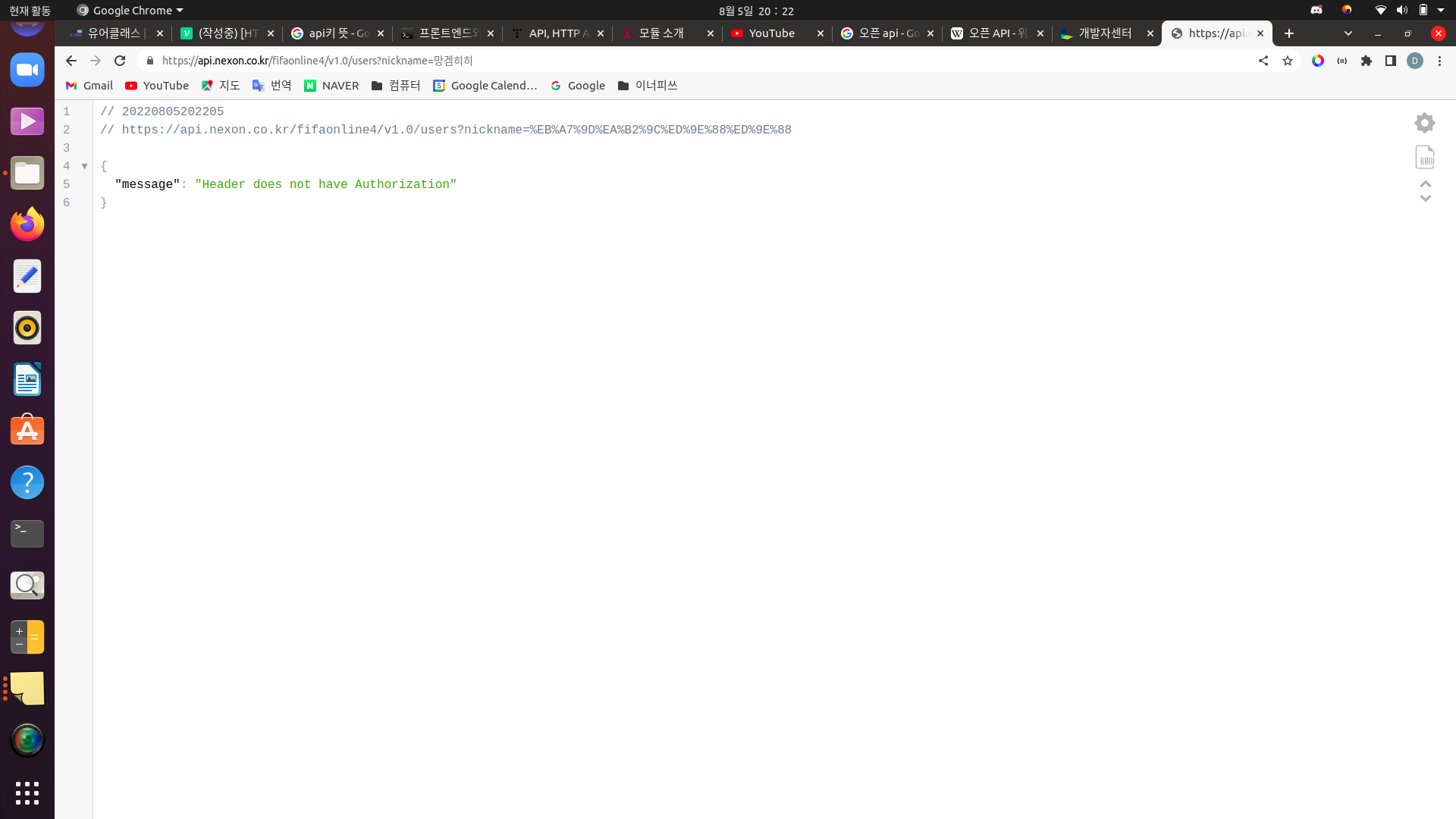
넥슨의 오픈 API에서는
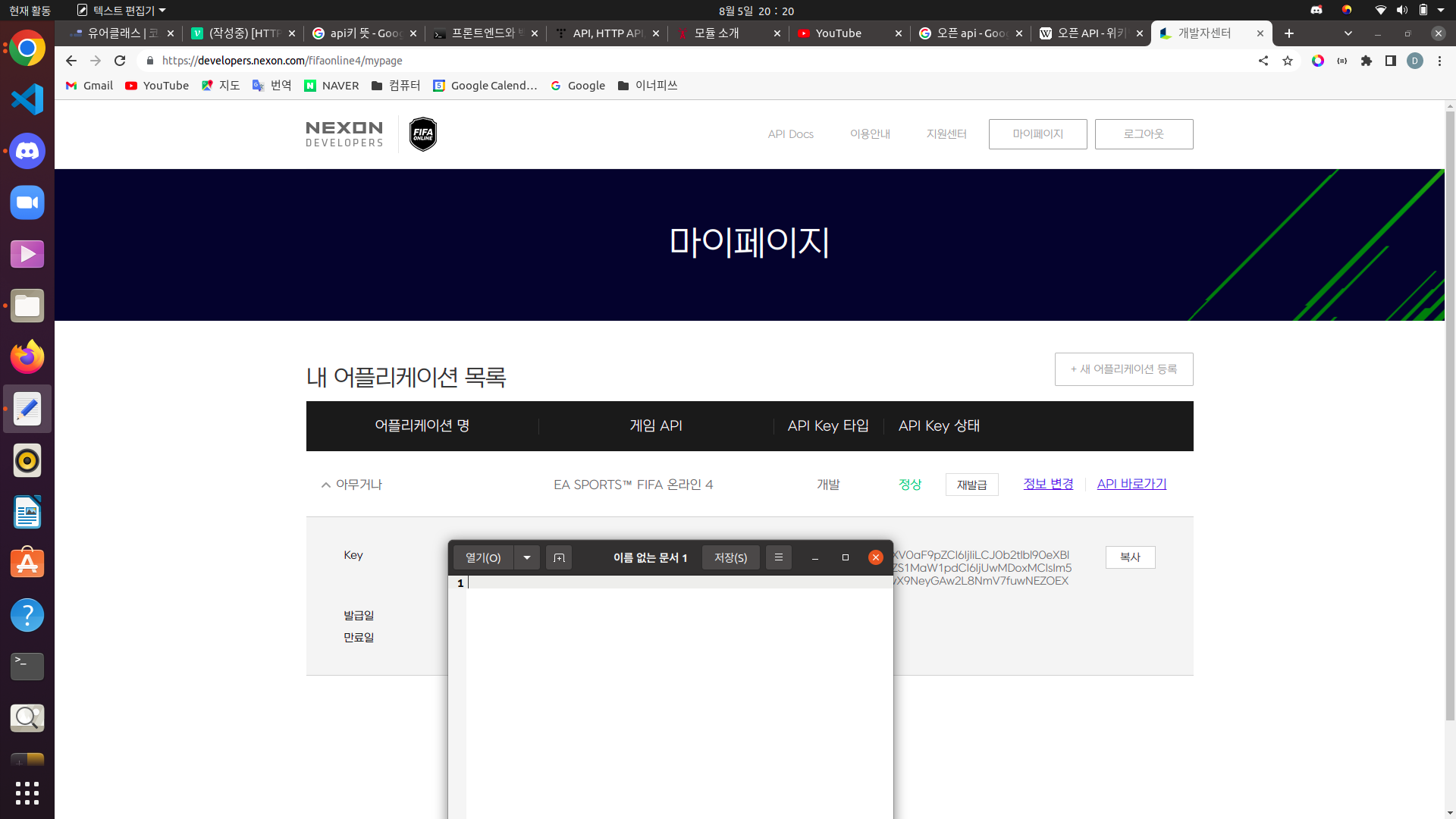
이런식으로 OPEN API를 이용하기 위한 키를 발급해준다. 이 키 없이 API를 이용하려는 경우, 권한이 없다는 메시지를 반환받게 된다.(메시지야 웹 사이트마다 차이가 있겠지만, API를 이용할 수 없다는 점에서는 똑같다.) 다음은 키를 요청의 header에 담지 않고 API를 이용하려 했을 때의 결과물이다.