
- Iris Data Classifier
- Dry bean Data Classifier
■ Iris Data Classifier (분류기)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow import keras1. 데이터 로딩
: iris data를 불러온 뒤, X,y를 train/test set으로 split 한다
X, y = load_iris(return_X_y =True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=10)2. 데이터 확인
print(X_train.shape)
# (112, 4)print(X_train[:5])
# [[4.8 3.4 1.9 0.2]
# [6.4 2.7 5.3 1.9]
# [5.7 2.6 3.5 1. ]
# [4.6 3.6 1. 0.2]
# [5.6 3. 4.1 1.3]]
print(y_train)
# [0 2 1 0 1 1 2 1 1 1 2 0 2 2 1 2 0 2 0 2 0 1 1 1 0 1 0 2 2 1 1 2 0 0 0 1 0
# 0 0 1 1 2 0 2 1 0 2 1 0 0 2 0 2 0 0 0 1 2 1 0 1 2 1 0 1 1 2 1 1 0 1 2 1 0
# 2 2 2 1 0 2 2 1 1 2 1 2 1 2 0 0 0 0 0 2 1 2 2 2 0 0 1 0 1 2 2 2 0 2 0 2 0
# 1]3. 분류 모델 생성 & 적합
model = keras.Sequential([
keras.layers.InputLayer(input_shape=[4,]),
keras.layers.Dense(64, activation ='relu'),
keras.layers.Dense(32, activation ='relu'),
keras.layers.Dense(3) # iris는 3개로 분류해야하기 떄문에, 예측해야하는 category 개수만큼 output함
])
model.compile(optimizer = 'adam', # learning_rate는 defalut 값
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
h=model.fit(X_train,y_train,epochs=50)
4. 정확도 & loss값 시각화
_,axe = plt.subplots()
axe.plot(h.history['accuracy'])
axe.plot(h.history['loss'])
■ DryBean Data Classifier (분류기)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow import keras1. 데이터 로딩
data = pd.read_csv('Dry_Bean_Dataset.csv')
data.head() X : ShapeFactor1, ShapeFactor2, ShapeFactor3, ShapeFactor4
X : ShapeFactor1, ShapeFactor2, ShapeFactor3, ShapeFactor4
y : Class
# X
X = data.iloc[:,12:16]
# y
encoder = LabelEncoder()
y = encoder.fit_transform(data['Class'])
# y = data['Class'].astype('category').cat.codes
# train, test set split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=10)2. 데이터 확인
print(X_train.shape)
# (10208, 4)print(X_train.head())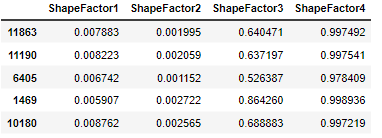
print(np.unique(y))
# [0 1 2 3 4 5 6]y 는 label encoding 이 제대로 되었고, X 는 따로 scaling 은 하지 않겠다.
3. 모델 생성 & fit
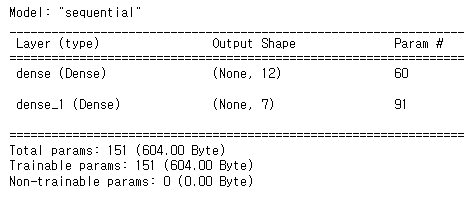
model = keras.Sequential([
keras.layers.InputLayer(input_shape=[4,]),
keras.layers.Dense(12, activation = 'relu'),
keras.layers.Dense(7) #output layer, activation X, 7 가지로 분류.
])
model.compile(optimizer = keras.optimizers.Adam(learning_rate=0.01),
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics =['accuracy']
model.summary() ( 똑같은 정확도라면, parameter 개수가 적은 것이 더 좋은 모델이다 )
h = model.fit(X_train, y_train, epochs = 150)4. 정확도 & loss값 시각화
_, axe = plt.subplots()
axe.plot(h.history['accuracy'])
axe.plot(h.history['loss'])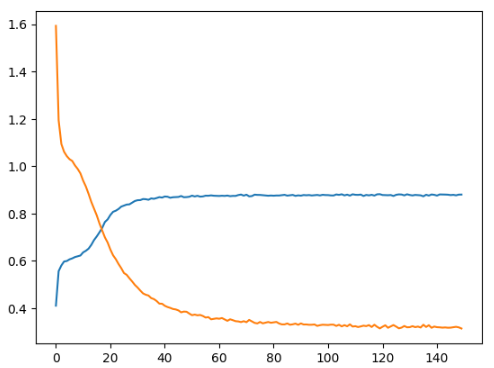
5. model evaluate
model.evaluate(X_test, y_test)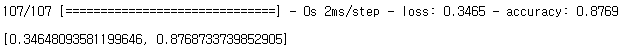 test data 에 대해서도 87% 의 정확도를 보이는 모델이다.
test data 에 대해서도 87% 의 정확도를 보이는 모델이다.

데이터 분석 / 데이터 사이언티스트 / AI 딥러닝