
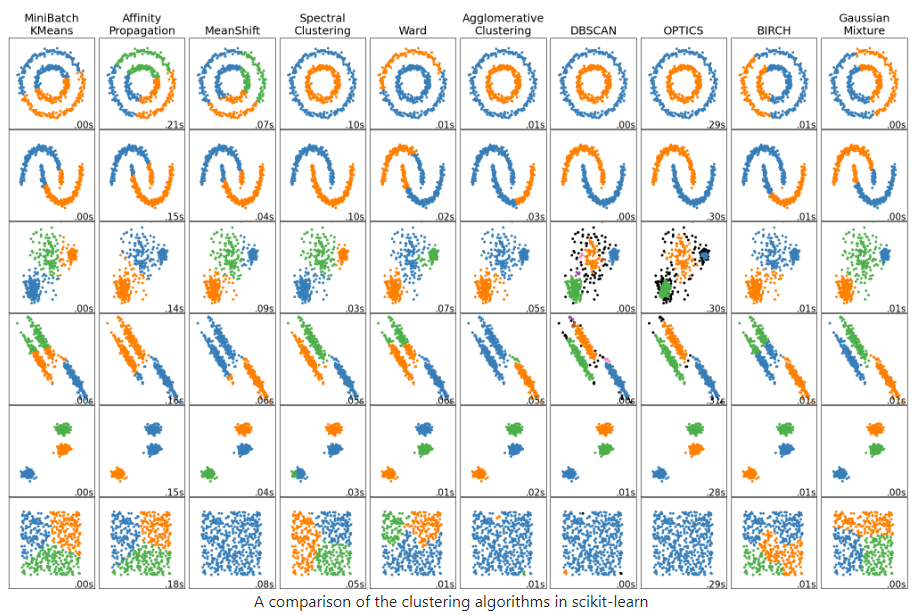
https://scikit-learn.org/stable/modules/clustering.html
- 비지도학습 -> 타깃값이 없는 데이터로 학습
- 여러가지 알고르즘으로 군집화
K-Means
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
- 가장 기본 알고리즘
- 기본 알고리즘은 KNN과 동일
- 군집 개수를 정해주어야 함
- 정해진 군집 개수만큼 랜덤 샘플로 시작
- 데이터를 더해가면서 평균값(centroid, 중심점) 과 가까운 것들끼리 군집화
- 평균값 지속적 업데이트
- 특징 : 군집 크기 비슷, 군집 모양 원형
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
from sklearn import metricsX,y = load_iris(return_X_y = True)
m = KMeans(n_clusters=3, n_init = 'auto')
m.fit(X)
print(m.labels_)
# [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
# 1 1 1 1 1 1 1 1 1 1 1 1 1 2 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 2 2 2 0 2 2 2 2
# 2 2 0 0 2 2 2 2 0 2 0 2 0 2 2 0 0 2 2 2 2 2 0 2 2 2 2 0 2 2 2 0 2 2 2 0 2
# 2 0]# 성능평가
metrics.homogeneity_score(y, m.labels_)
# 0.7364192881252849MiniBatch K-Means
- Batch : 하나의 묶음
- K-Means 알고르즘에서, 데이터의 개수가 많으면 군집화가 오래 걸리므로 데이터를 batch로 묶어서 K-Means 알고리즘 처리
Affinity Propagation
- preference : 기준 데이터 허용 개수
- damping : 기준 데이터 적합성 점수 영향력 조절
(얼마나 가까워야 같은 군집으로 묶어줄 것인가 ?) - 기준 데이터(exampler) 로부터 가까운 것들끼리 군집화 (KMeans는 평균값을 기준으로 !)
- 데이터를 더해가면서 기준 데이터의 적합성 검토, 업데이트
Mean Shift
- bandwidth : 검사영역 설정
- 미리 군집의 개수를 정해주지 않음
- 평균값(centroid)에서 bandwidth 만큼의 범위 내외 값으로 군집화
Spectral Clustering
- 군집의 갯수를 입력 (KMeans와 유사)
- 근접행렬(affinity matrix) 을 만들어 K-Means와 같은 방식을 적용
Agglomerate Clustering
- 계층화된 방식(tree) 을 이용하여 군집형성, 상향식
- BIRCH
- 처음 데이터를 제각각의 군집으로 인식, 점점 비슷한 데이터들끼리 군집형성
DBSCAN
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html#sklearn.cluster.DBSCAN
- min_samples : 밀집의 정도를 결정
- eps : 데이터 사이의 거리를 조절하는 수치 (얼마나 떨어지면 다른 군집으로 분리되는가 ?, eps가 크면 같은 같은 군집으로 분류될 수도 !)
- 데이터의 밀집도 (Density)에 따라 군집 형성
- 다양한 군집 형태
- 밀집도가 낮은 부분을 구분선으로 봄
- OPTICS : eps 범주화 (range) , eps 를 범위로 줌.
Clustering performance evaluation _ sklearn.metrics
- Homogeneity : 하나의 군집(Cluster)에 하나의 분류(Class, Label)가 들어있음.
- Completeness : 하나의 분류(Class, Label)에 속하는 데이터가 하나의 군집(Cluster)에 속함.
- 0.0 ~ 1.0
- 높을수록 좋은 점수

데이터 분석 / 데이터 사이언티스트 / AI 딥러닝