
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeCalssifier, plot_tree
#from sklearn.native_bayes import GaussianNB, BernoulliNB
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.metrics import r2_score, mean_sqaured_error
#from sklearn.model_selection import KFold
#from sklearn.neighbors import KNeighborsClassifierdata = pd.read_csv('C:/Users/ddi05/Class_05/abalone/abalone.data', header=None)
data.head()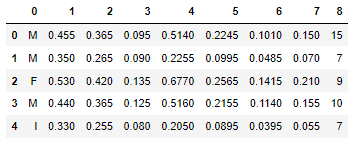
< column 1 ~ 7 을 이용하여, 성별 (M, F, I) 를 예측 >
1. column 별 결측치 확인
for i in data :
#print(i)
print(i, data[i].isnull().sum())
# 0 0
# 1 0
# 2 0
# 3 0
# 4 0
# 5 0
# 6 0
# 7 0
# 8 02. LabelEncoding
encoder = LabelEncoder()
data[0] = encoder.fit_transform(data[0])
data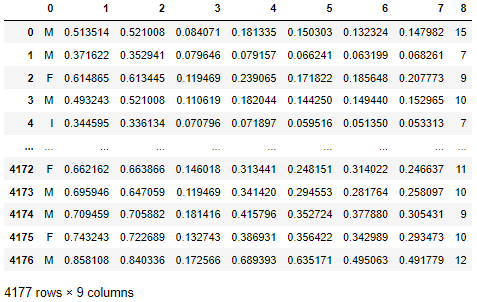
3. MinMaxScaling
print(data[8].unique())
# [15 7 9 10 8 20 16 19 14 11 12 18 13 5 4 6 21 17 22 1 3 26 23 29
# 2 27 25 24]scaler = MinMaxScaler()
labels = [[1,2,3,4,5,6,7]]
for i in labels :
data[i] = scaler.fit_transform(data[i])
data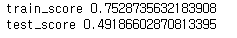
4. X, y split / DecisionTree model fit
y = data[0]
X = data[[1,2,3,4,5,6,7,8]]
X_train, y_train, X_test, y_test = train_test_split(X, y, stratify = y, random_state = 10)
dt = DecisionTreeClassifier(max_depth=10)
dt.fit(X_train, y_train)
pred_dt = dt.predict(X_test)
print('train score', dt.score(X_train, y_train))
print('test score', dt.score(X_test, y_test))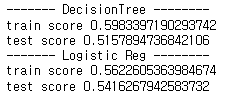
5. 여러 분류모델 적합 : DecisionTree, Logistic Reg
models = [DecisionTreeClassifier(max_depth=5), LogisticRegression(solver='liblinear')]
model_names = ['DecisionTree', 'Logistic Reg']
for model, model_name in zip(models, model_names) :
m = model
m.fit(X_train, y_train)
pred = m.predict(X_test)
print('-------', model_name, '--------')
print('train score', m.score(X_train, y_train))
print('test score', m.score(X_test, y_test))
데이터 분석 / 데이터 사이언티스트 / AI 딥러닝