Tree
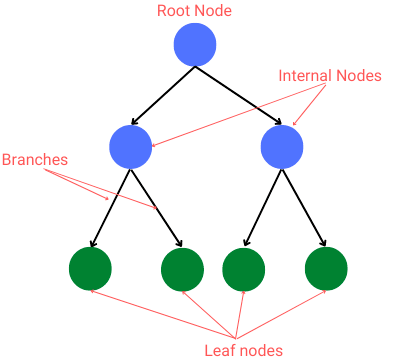
- 비선형, 계층적 구조
- 노드로 구성, 부모와 자식의 관계
- 2진 트리 : 부모 노드 - 2개의 자식 노드 (오른쪽 / 왼쪽)
- 리프(leaf) 노드 : 가장 마지막 노드
- 분류 & 회귀 가능
- 분류
- 각 노드에서 분할 조건 적용
- 최종 leaf 노드에서 분류 예측
- 회귀
- 특정한 값을 예측
- 특정한 값의 범위를 준 후 범위에 대한 분류로 회귀
- 머신러닝 :
- 학습 데이터로부터 tree 생성
- tree 를 이용하여 예측
- 분류
- 단점 : depth 가 깊을수록 overfit (과적합) 가능성 이 굉장히 높아짐
-> max depth 를 제한
.
.
.
가지분할의 방법 ( 알고리즘 )
: ID3, C4.5, C5.0, CART
ID3
- 정보이득 (엔트로피 / 지니계수 감소) 의 방향으로 데이터를 분할하여 트리 형성
- 주로 카테고리형 특성을 다루는 데 적합
- 과적합 경향 O : 처음부터 트리의 가지치기 X
entropy
_
값이 0 이거나 1일 때 (즉, 분류가 잘 될 수록) entropy값은 0이나 1이 됨 : 값이 최소
gini
_
어느 것 하나일 확률 ( )가 높다면, 분류가 잘 될수록, 지니계수는 0에 가까운 값을 반환함
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import r2_score, mean_squared_error
Iris Data : Decision Tree
1. X, y 의 train, test split
X, y = load_iris(return_X_y = True)
X_train, y_train, X_test, y_test = train_test_split(X, y, stratify = y, random_state = 120)2. Deicision Tree model 생성
model = DecisionTreeClassifier(criterion = 'entropy', max_depth = 3, min_samples_leaf = 3)
# mins_samples_leaf : leaf의 최소 샘플 개수
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(model.score(X_train, y_train)) # train score
print(model.score(X_test, y_test)) # test score
#train score 0.9642857142857143
#test score 1.03. Decision Tree 시각화
plot_tree(model)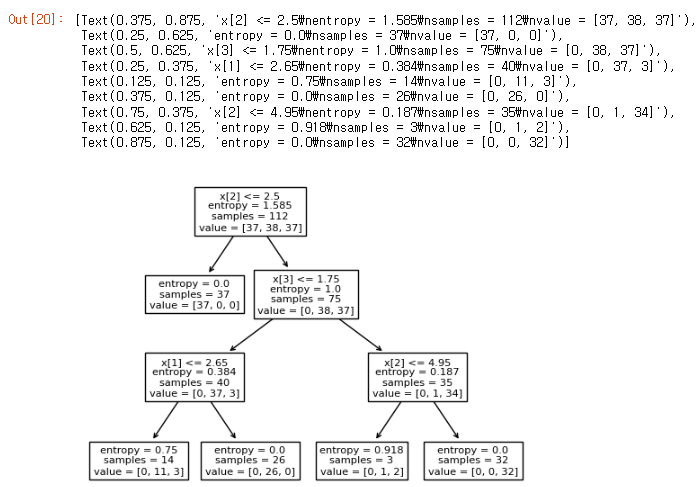
K-Fold Cross Validation
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html
머신러닝 모델의 성능을 평가하는 방법 중 하나로,
데이터셋을 K개의 폴드로 나누고, 각 폴드를 번갈아가며 모델의 학습과 검증을 수행
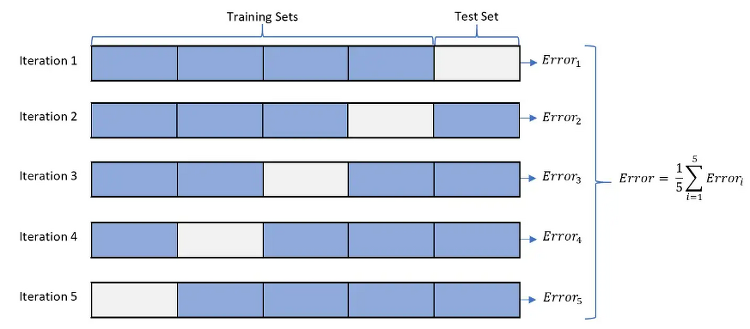
- 장점 : 데이터셋 전체를 학습과 검증에 사용할 수 있으며, 모델의 일반화 성능을 더 정확하게 평가할 수 있음
- 과적합 감지 or 하이퍼파라미터 튜닝에 유용하게 사용
< code >
from sklearn.model_selection import KFold
m = KFold(n_splits = 5)
#m.get_n_splits(X)
#print(m)
for train, test in m.split(X) :
print('----------------------')
#print('train' , train)
#print('test' , test)
#print(X[test], y[test])
d = DecisionTreeClassifier()
d.fit(X[train], y[train])
print('Train score', d.score(X[train], y[train]))
print('Test score', d.score(X[test], y[test]))< result >

KNN
KNN 은 분류 및 회귀에 사용되는 지도학습 알고리즘으로
새로운 데이터 포인트를 분류하거나 예측할 때, 주변에 가장 가까운 K개의 훈련데이터 포인트를 확인 하여 결정하는 방식
( * Clustering 에는 반지름 반경을 정해주는 option도 존재 )
- 분류 : K개의 이웃 중에서 가장 많은 클래스를 찾아 해당 클래스로 분류
- 회귀 : K개의 이웃의 평균 또는 가중 평균을 사용하여 예측
< code >
from sklearn.neighbors import KNeighborsClassifier
X, y = load_iris(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, random_state = 10)
m = KNeighborsClassifier(n_neighbors = 10)
m.fit(X_train, y_train)
print('test score', m.score(X_test, y_test))< result >
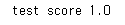

데이터 분석 / 데이터 사이언티스트 / AI 딥러닝
좋은 글 감사합니다. 자주 올게요 :)