
영화진흥위원회 API 홈페이지에서 영화목록 API를 들고와보자.
사이트 링크 : https://www.kobis.or.kr/kobisopenapi/homepg/apiservice/searchServiceInfo.do
.
.
.
JSON 파일로 불러오기
1. 'curpage' : 1 로 첫번째 페이지만 먼저 불러와보자
url = 'http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json?key=0f567ff53f5fda21ef9524647bc6225d'
params = {
'curPage' : 1,
'itemPerPage': 100
}
df_b = pd.DataFrame()
response = requests.get(url, params = params)
#contents = response.text
data = json.loads(response.text)
data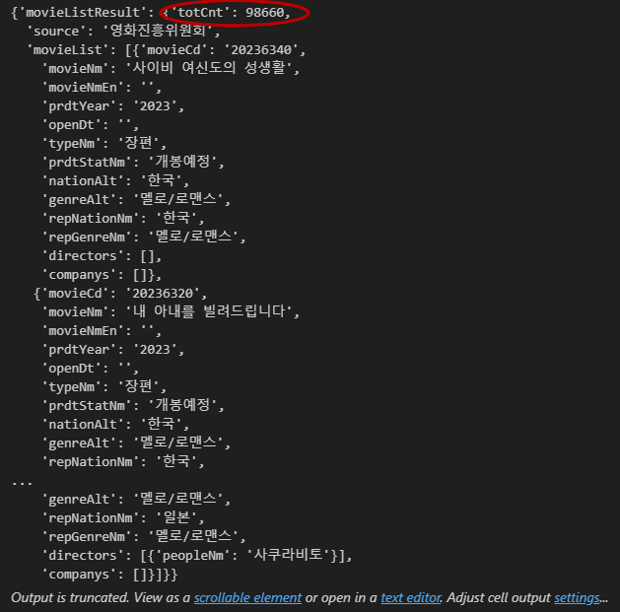
2. 영진위 API를 첫번째 페이지 뿐만 아니라 모든 페이지를 다 불러와보자.
먼저 첫번째 페이지를 불러왔을 때 보였던 'totCnt'가 전체 영화의 수인 것 같으니, 한 페이지당 100개씩 출력 -> 'totCnt' //100 + 1 만큼 for 구문을 돌아주면 된다.
해당 숫자를 length에 넣어주겠다. ( 매일매일 저 숫자가 바껴서 length에 넣어주는걸로,,, )
url = 'http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json?key=0f567ff53f5fda21ef9524647bc6225d'
params = {
'curPage' : 1,
'itemPerPage': 100
}
df_b = pd.DataFrame()
response = requests.get(url, params = params)
#contents = response.text
data = json.loads(response.text)
length = json.loads(response.text)['movieListResult']['totCnt']//100+1json_normalize를 사용하여, JSON형식의 데이터를 DataFrame 형식으로 바꿔주면서 concat을 통해 페이지별 영화데이터셋을 붙혀 나가자.
# 영진위에서 영화목록 API 불러오기
url = 'http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json?key=0f567ff53f5fda21ef9524647bc6225d'
df_b = pd.DataFrame()
for i in range(length) :
params = {
'curPage' : i,
'itemPerPage': 100
}
response = requests.get(url, params = params)
data = json.loads(response.text)
df_a = pd.json_normalize(data['movieListResult']['movieList'])
df_b = pd.concat([df_a, df_b])
df_b 를 출력해보면, 이렇게 데이터프레임 형식으로 각 변수들이 불러와진 것을 볼 수 있다.
3. 추가로, directors (감독) 컬럼과 companys (참여회사)가 딕셔너리 형태로 들어가있으므로, 딕셔너리를 풀어주자.
# 'companys' column 삭제
df_b.drop('companys', axis=1, inplace=True)
# direcotrs 딕셔너리 해제
director_names = []
for x in df_b['directors']:
if x:
names = [item['peopleNm'] for item in x]
else:
names = []
director_names.append(names)
df_b['directors'] = director_names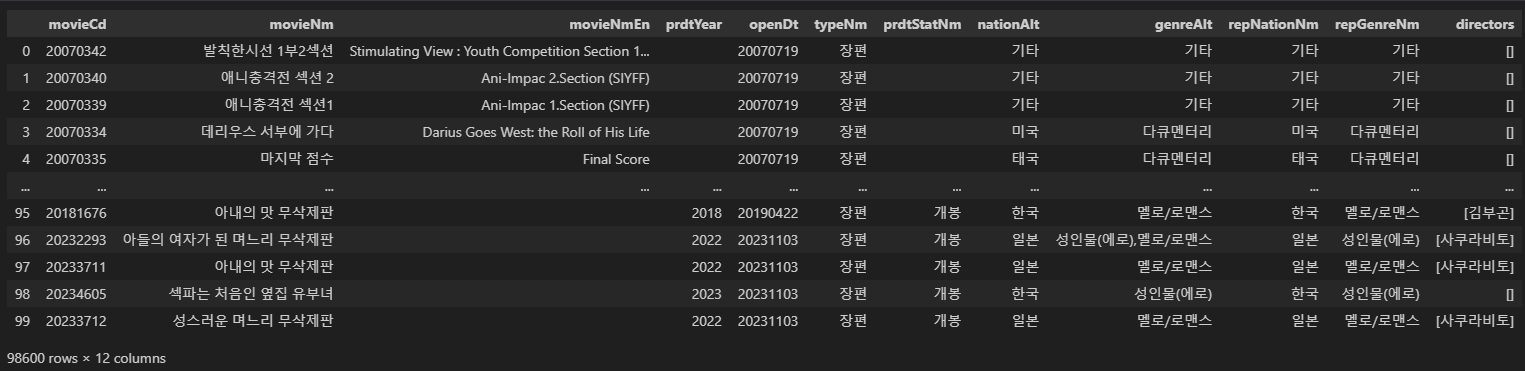

데이터 분석 / 데이터 사이언티스트 / AI 딥러닝