
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltname = '전국평생학습강좌표준데이터.csv'
pd_data = pd.read_csv(name,encoding = 'cp949')
print(pd_data.head())
def df_check(df) :
for i, e in enumerate(pd_data.columns) :
print(i,e)
print('\t', pd_data[e].hasnans, pd_data[e].dtype)df_check(pd_data)
# 0 강좌명
# False object
# 1 강사명
# False object
# 2 교육시작일자
# False object
# 3 교육종료일자
# False object
# 4 교육시작시각
# True object
# 5 교육종료시각
# True object
# 6 강좌내용
# False object
# 7 교육대상구분
# False object
# 8 교육방법구분
# False object
# 9 운영요일
# True object
# 10 교육장소
# True object
# 11 강좌정원수
# False int64
# 12 수강료
# False int64
# 13 교육장도로명주소
# False object
# 14 운영기관명
# False object
# 15 운영기관전화번호
# False object
# 16 접수시작일자
# True object
# 17 접수종료일자
# True object
# 18 접수방법구분
# False object
# 19 선정방법구분
# True object
# 20 홈페이지주소
# True object
# 21 직업능력개발훈련비지원강좌여부
# False object
# 22 학점은행제평가(학점)인정여부
# False object
# 23 평생학습계좌제평가인정여부
# False object
# 24 데이터기준일자
# False object
# 25 제공기관코드
# False object
# 26 제공기관명
# False object1. 홈페이지 주소가 없는 강좌
homepage = pd_data.iloc[:, 20]
#print(homepage)
print(homepage.isna().value_counts())
# False 24916
# True 2194홈페이지 주소가 없는 강좌는 2194 개이다.
2. 지차체별(시도명 기준) 강좌개수
- 지자체 unique값 확인하기
ad = pd_data['교육장도로명주소']
list_ad = []
for i in ad :
list_ad.append(i.split()[0])
s1 = pd.Series(list_ad)
print(s1.unique())
# ['경기도' '서울특별시' '강원도' '경상남도' '포항시' '경상북도' '충청북도' '부산광역시' '대구광역시' '울산광역시'
# '광주광역시' '충청남도' '대전광역시' '전라북도' '전라남도' '경북' '인천광역시' '전라남도?진도군?진도읍?철마길12'
# '전라남도?진도군?진도읍?남산로?50-3' '전라남도?진도군?고군면?석현리' '세종특별자치시' '전북' '경남' '.'
# '해남군?해남읍?서성1길?33' '해남군?해남읍?교육청길?50' '해남군?해남읍?서성1길33'
# '전라남도?영암군?영암읍?서남역로?27-11' '전남?무안군?무안읍?공항로?75-9' '전남?무안군?운남면?운해로?266-1'
# '전남?무안군?청계면?월선길?263-1' '화순군?화순읍?도서관길15' '장흥군?장흥읍?중앙로?2길?33' '마산합포구' '전남'
# '광양시' '전남?곡성군?곡성읍?읍내7길?29' '전남?곡성군?곡성읍?읍매7길?29' '보성군?벌교읍?월곡길?13' '당진시'
# '제주특별자치도' 'zoom' '유튜브' '의령읍' '코로나로' '경남남도' '나주시' '고흥군' '장성군' '순천시?석현북길21'
# '순천시?중앙초등길?64' '순천시?생태배움길22' '화순군?화순읍?대교로11' '장흥군?장흥읍?건산리?흥성로37-24'
# '고흥군?남양면?망주리136' '여수시' '목포시' '중마청룡길' '인천' '충북' '철원군' '찾아가는' '온라인교육' '제천시'
# '강화읍' '서울특별시중랑구' '강화나들길' '온라인' '서울' '오포로859번길' '영양관내' '수복로' '거제시' '광주'
# '[46760]부산광역시' '[46762]부산광역시' '[46702]부산광역시' '[46759]부산광역시'
# '[46717]부산광역시' '[46700]부산광역시']- 이상치 수정하기
① ? / [ ] 있는 지자체 수정
def area_from_address(full_address_str) :
if '[' in full_address_str :
i = full_address_str.find('[') + 1
full_address_str = full_address_str[i:]
if '?' in full_address_str :
full_adress_str.split('?')[0]
return full_address_str.split()[0] print(pd_data['교육장도로명주소'].apply(area_from_address).unique())
# ['경기도' '서울특별시' '강원도' '경상남도' '포항시' '경상북도' '충청북도' '부산광역시' '대구광역시' '울산광역시'
# '광주광역시' '충청남도' '대전광역시' '전라북도' '전라남도' '경북' '인천광역시' '세종특별자치시' '전북' '경남' '.'
# '해남군' '전남' '화순군' '장흥군' '마산합포구' '광양시' '보성군' '당진시' '제주특별자치도' 'zoom' '유튜브'
# '의령읍' '코로나로' '경남남도' '나주시' '고흥군' '장성군' '순천시' '여수시' '목포시' '중마청룡길' '인천' '충북'
# '철원군' '찾아가는' '온라인교육' '제천시' '강화읍' '서울특별시중랑구' '강화나들길' '온라인' '서울' '오포로859번길'
# '영양관내' '수복로' '거제시' '광주']②
def rewrite(area_name) :
short_name = ['경남','경북','전남','전북','부산','광주','서울','인천','충북']
long_name = ['경상남도','경상북도','전라남도','전라북도','부산광역시','광주광역시','서울특별시','인천광역시','충청북도']
if area_name in short_name :
i = short_name.index(area_name)
return long_name[i]
else :
return area_namearea_name = pd_data['교육장도로명주소'].apply(area_from_address)
area_name2 = area_name.apply(rewrite)
print(area_name2.unique())
# ['경기도' '서울특별시' '강원도' '경상남도' '포항시' '경상북도' '충청북도' '부산광역시' '대구광역시' '울산광역시'
# '광주광역시' '충청남도' '대전광역시' '전라북도' '전라남도' '인천광역시' '세종특별자치시' '.' '해남군' '화순군'
# '장흥군' '마산합포구' '광양시' '보성군' '당진시' '제주특별자치도' 'zoom' '유튜브' '의령읍' '코로나로'
# '경남남도' '나주시' '고흥군' '장성군' '순천시' '여수시' '목포시' '중마청룡길' '철원군' '찾아가는' '온라인교육'
# '제천시' '강화읍' '서울특별시중랑구' '강화나들길' '온라인' '오포로859번길' '영양관내' '수복로' '거제시']③
def rewrite2(area_name) :
if area_name in ['마산합포구','거제시','의령읍','경남남도'] :
return '경상남도'
elif area_name in ['고흥군','광양시','장성군','목포시','광양군','화순군','여수시','나주시','보성군','순천시','장흥군','해남군','중마청룡길'] :
return '전라남도'
elif area_name == '당진시' :
return '충청남도'
elif area_name =='제천시' :
return '충청북도'
elif area_name in ['포항시','영양관내'] :
return '경상북도'
elif area_name in ['강화읍','강화나들길'] :
return '인천광역시'
elif area_name =='오포로859번길' :
return '광주광역시'
elif area_name in ['수복로','철원군'] :
return '강원도'
elif area_name =='서울특별시중랑구' :
return '서울특별시'
else :
return area_namearea_name3 = area_name2.apply(rewrite2)
print(area_name3.unique())
# ['경기도' '서울특별시' '강원도' '경상남도' '경상북도' '충청북도' '부산광역시' '대구광역시' '울산광역시' '광주광역시'
# '충청남도' '대전광역시' '전라북도' '전라남도' '인천광역시' '세종특별자치시' '.' '제주특별자치도' 'zoom' '유튜브'
# '코로나로' '찾아가는' '온라인교육' '온라인']cnt = area_name3.value_counts()
print(cnt)
# 경기도 8149
# 경상남도 2785
# 광주광역시 2250
# 서울특별시 1969
# 전라북도 1631
# 대구광역시 1627
# 인천광역시 1403
# 경상북도 1360
# 전라남도 1065
# 충청남도 1048
# 강원도 922
# 부산광역시 844
# 대전광역시 534
# 충청북도 471
# 제주특별자치도 467
# 울산광역시 296
# 세종특별자치시 146
# . 102
# zoom 20
# 유튜브 17
# 코로나로 1
# 찾아가는 1
# 온라인교육 1
# 온라인 1
# Name: 교육장도로명주소, dtype: int64④ 지자체가 아닌 ' . ' 이하는 '기타' 로 변경
ignore_names = list(cnt['.':].index) # . 이하 index
print(ignore_names)
# ['.', 'zoom', '유튜브', '코로나로', '찾아가는', '온라인교육', '온라인']for i,n in enumerate(area_name) :
if n in ignore_names :
area_name3[i] = '기타'
print(area_name3.unique())
# ['경기도' '서울특별시' '강원도' '경상남도' '경상북도' '충청북도' '부산광역시' '대구광역시' '울산광역시' '광주광역시'
# '충청남도' '대전광역시' '전라북도' '전라남도' '인천광역시' '세종특별자치시' '기타' '제주특별자치도']- 지자체별 강좌개수 확인하기
print(area_name3.value_counts())
# 경기도 8149
# 경상남도 2785
# 광주광역시 2250
# 서울특별시 1969
# 전라북도 1631
# 대구광역시 1627
# 인천광역시 1403
# 경상북도 1360
# 전라남도 1065
# 충청남도 1048
# 강원도 922
# 부산광역시 844
# 대전광역시 534
# 충청북도 471
# 제주특별자치도 467
# 울산광역시 296
# 세종특별자치시 146
# 기타 143
# Name: 교육장도로명주소, dtype: int64- pd_data 에 'area_name' column 추가하기
pd_data.insert(27, 'area_names', area_name3)
print(pd_data.iloc[:, -5:].tail() 마지막 column에 'area_name' column을 추가하였다.
마지막 column에 'area_name' column을 추가하였다.
3. 지자체별 온/오프라인 강좌 개수
delivery_types = pd_data['교육방법구분']
print(delivery_types.unique())
# ['혼합' '오프라인' '온라인' '방문교육' '온라인+오프라인' '오프라인+온라인' '오프라인+모바일+우편통신'
# '오프라인+방문교육' '온라인+모바일']① '혼합' 강좌 만들기
def delivery_rewrite(type_name) :
if '+' in type_name :
return '혼합'
else :
return type_namedelivery_types = delivery_types.apply(delivery_rewrite)
print(delivery_types.value_counts())
# 오프라인 21616
# 온라인 3852
# 혼합 1297
# 방문교육 345
# Name: 교육방법구분, dtype: int64② 'delivery_types' column 추가하기
pd_data.insert(28,'delivery_types',delivery_types)
print(pd_data.iloc[:, -5:].tail()) 마지막 column에 'delivery_types' column을 추가하였다.
마지막 column에 'delivery_types' column을 추가하였다.
③ 지자체별 온/오프라인 강좌 개수 : groupby
g1 = sub_df1.groupby(['area_names','delivery_types'])
g1.value_counts()④ 지자체별 / 교육방법별 / 수강료
sub_df = pd_data[['delivery_types','area_names','수강료']]
sub_df.head()
g1 = sub_df.groupby(['area_names','delivery_types'])
g1.agg([np.mean, np.max])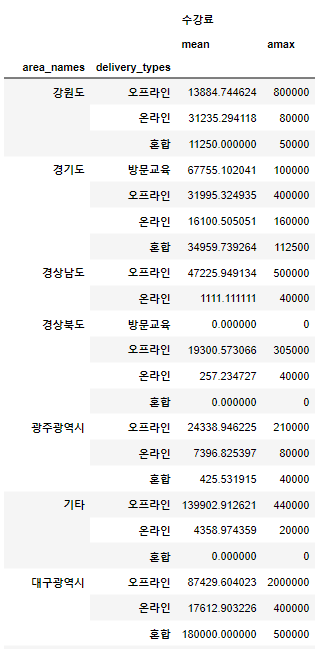

데이터 분석 / 데이터 사이언티스트 / AI 딥러닝
개발자로서 배울 점이 많은 글이었습니다. 감사합니다.