
🌞크롤링이란 ?
웹페이지를 그대로 가져와 데이터를 추출해 내는 행위 !
.
.
.
.
.
먼저, lxml이 깔려있지 않다면 깔아준다.
!pip install lxml.
.
.
🛻 실제 웹사이트를 크롤링하기 전에 연습해보자.
from lxml import etree
sample_xml = '''
<AAA>
<BBB id = "a">
<XXX />
<yyy></yyy>
</BBB>
<CCC id = "a">
<yyy>mystring</yyy>
</CCC>
<BBB id = "b">
<zzz></zzz>
</BBB>
<BBB></BBB>
</AAA>
'''
et = etree.fromstring(sample_xml)- 태그 찾기
'/', '//', '///'를 적절히 활용하여 해당 태그를 찾는다.
r = et.xpath('/AAA') # 맨 상위 루트 바로 아래에 있는 AAA라는 태그 찾기
r = et.xpath('/AAA/BBB') # 맨 상위 루트 바로 아래에 있는 AAA태그 밑의 BBB태그 모두 찾기
r = et.xpath('//yyy') # 어디에서 시작하든 상관 없이 yyy라는 태그 찾기
r = et.xpath('//BBB/XXX') # BBB태그 바로 밑의 XXX 태그 찾기
r= et.xpath('//*/yyy') # 전체 중에서 yyy 태그 찾기
r = et.xpath('//BBB[@*]') # atribute가 있는 모든 BBB찾기
r= et.xpath('//BBB[not(@*)]') # atribute가 없는 모든 BBB찾기
print(r)
print(etree.tostring(r[0]))
print(etree.tostring(r[1]))r = et.xpath('//@id') #모든 id를 찾기
r = et.xpath('//BBB[@id]') # id가 있는 BBB태그 찾기
r = et.xpath('//BBB[@id="a"]') # id=a 인 BBB태그 찾기
r = et.xpath('//*[@id="a]') # 모든 태그들 중 id=a 인 태그 찾기..
.
.
.
🛻 "실제 웹사이트로 크롤링"
아래의 네이버 '별자리 운세'를 크롤링해보겠다.


import requests
p = requests.get('https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query=%EB%B3%84%EC%9E%90%EB%A6%AC+%EC%9A%B4%EC%84%B8&oquery=%EB%B3%84%EC%9E%90%EB%A6%AC+%E3%85%9C%E3%85%87%E3%84%B4%EC%84%B8&tqi=ivRbIdprvTossOsM4D8ssssstvC-143699')p2 = etree.fromstring(p.text, parser = etree.HTMLParser())
r = p2.xpath('//li[@class="1st_r]/p')
for i,v in enumerate(r) :
print(i,v.text)- 결과

.
.
.
.
.
🛻 "네이버 야구 팀순위 & 승률" 추출
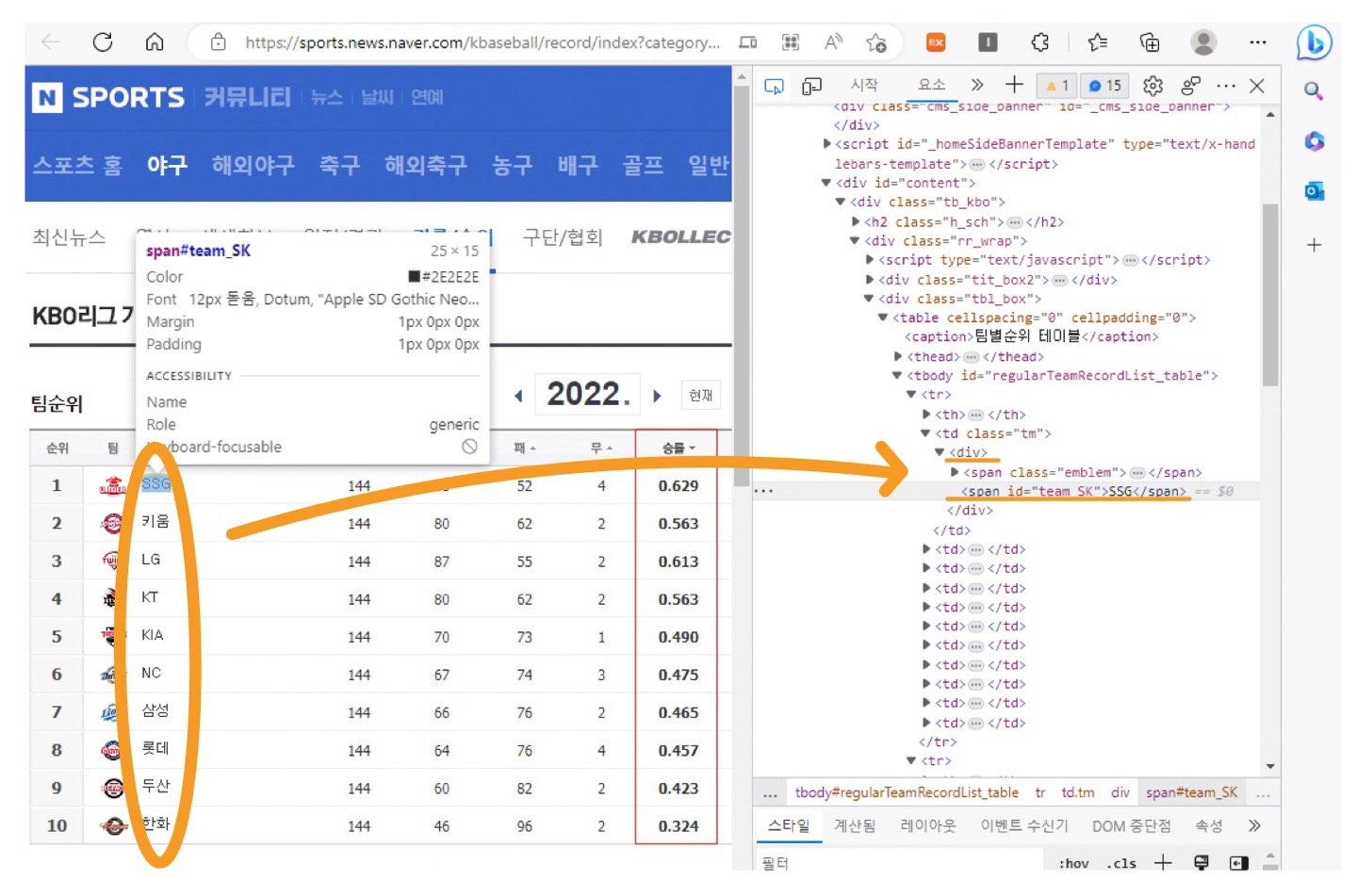
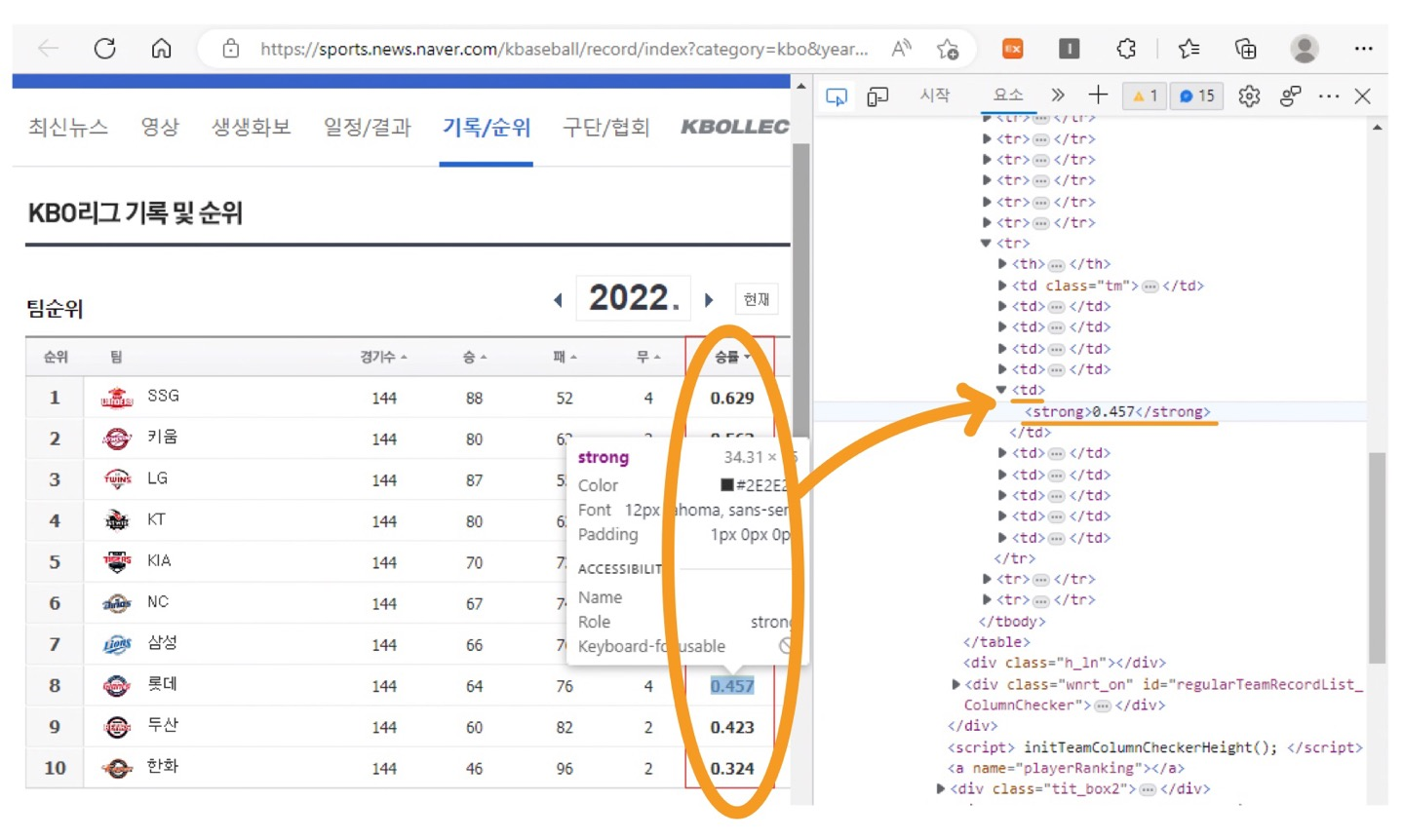
먼저 페이지를 불러온 후,
from lxml import etree
import requests
page = requests.get('https://sports.news.naver.com/kbaseball/record/index?category=kbo&year=2022')
p2 = etree.fromstring(page.text, parser=etree.HTMLParser())r1 변수에 순위순 팀 이름을 담은 후, team list 에 옮겨담는다.
r1 = p2.xpath('//div/span[@id]')
team_list = []
for i in r1 :
team_list.append(i.text)
print(team_list)
# print :
# ['SSG', '키움', 'LG', 'KT', 'KIA', 'NC', '삼성', '롯데', '두산', '한화']r2 변수에는 팀 별 승률을 담은 후, prob_list에 옮겨담는다.
r2 = p2.xpath('//td/strong')
prob_list = []
for i in r2 :
prob_list.append(i.text)
print(prob_list)
# print :
# ['0.629', '0.563', '0.613', '0.563', '0.490', '0.475', '0.465', '0.457', '0.423', '0.324']⌨️ dictionary { } 로 합치기
final = dict(zip(team_list, prob_list))
print(final)- 결과
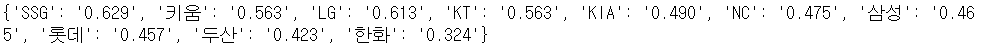
⌨️ list ( ) 로 합치기
final = []
for i in zip(team_list, prob_list) :
final.append(i)
print(final)- 결과
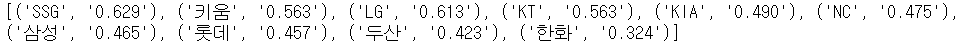
⌨️ tuple [ ] 로 합치기
final = []
for n,s in zip(team_list, prob_list) :
final.append([n, float(s)])
print(final)- 결과
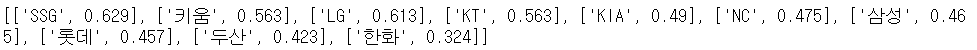

데이터 분석 / 데이터 사이언티스트 / AI 딥러닝