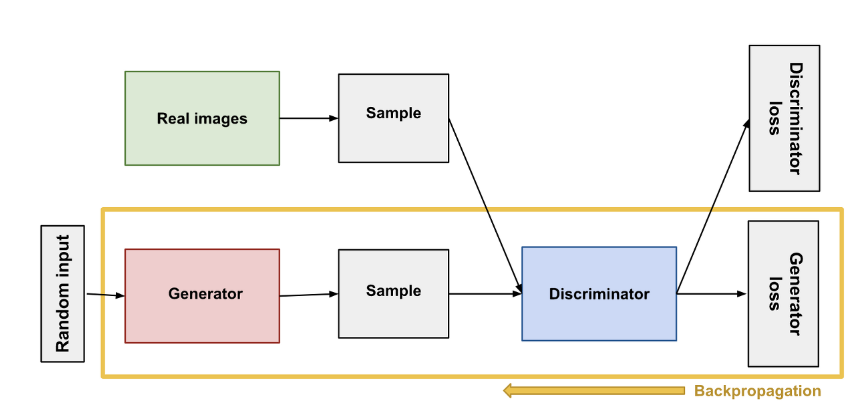
GAN(Generative Adversarial Network)에서 D(판별자)와 G(생성자)를 학습시키는 과정은 아래와 같이 진행됩니다.
D의 학습: GAN의 초기 단계에서는 D(판별자)를 먼저 학습시킵니다. 이때, D의 가중치(또는 파라미터)를 업데이트합니다. D의 업데이트는 실제 데이터와 가짜 데이터를 올바르게 구분하도록 하는 것을 목표로 합니다.
G의 학습: D가 학습되면 G(생성자)를 학습시킵니다. 이때, G의 가중치를 업데이트합니다. G의 업데이트는 D가 가짜 데이터를 실제 데이터로 오인하도록 하는 것을 목표로 합니다.
여기서 "G의 weight를 업데이트 시키려면 D에서부터 Back propagation 시켜야 한다"라는 말은 다음과 같은 의미입니다:
D에서부터 Backpropagation:
G의 가중치를 업데이트하기 위해서는 D에서부터 Backpropagation을 수행해야 합니다. 즉, G가 생성한 가짜 데이터와 실제 데이터를 D에 입력하여 D의 판별 결과를 얻고, 이를 기반으로 G의 손실을 계산합니다. 이후 G의 역전파(backpropagation)를 통해 G의 가중치를 업데이트합니다.
D의 weight를 업데이트하지 않음:
GAN의 학습 과정에서 D의 가중치는 G의 학습 시에는 업데이트하지 않습니다. D의 업데이트는 D의 학습 단계에서만 이루어지며, G의 학습 단계에서는 D의 가중치를 고정시켜 사용합니다. 이는 G의 학습 동안 D의 업데이트를 막아, G가 빠르게 학습되는 현상을 방지하고, D와 G의 균형을 유지하기 위한 것입니다.
요약하면, GAN에서는 D를 먼저 학습시킨 후 G를 학습시킵니다. G의 가중치를 업데이트하기 위해서는 D에서부터 Backpropagation을 수행하여 G의 손실을 계산합니다. 하지만 G의 학습 시에는 D의 가중치를 업데이트하지 않고 고정시켜 사용합니다. 이렇게 D와 G를 번갈아가며 학습시키는 과정을 통해 GAN은 점진적으로 실제 데이터와 유사한 가짜 데이터를 생성할 수 있게 됩니다.
D의 학습
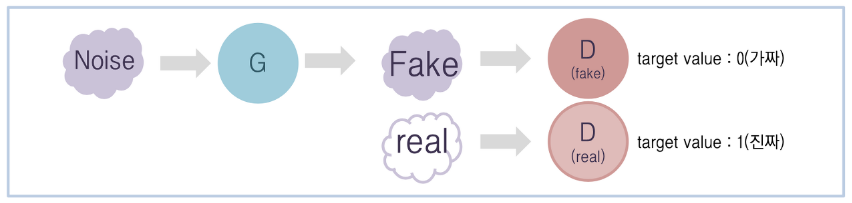
Fake data를 0, Real data를 1로 설정하고 discriminator를 학습시킨다.
G의 학습

Fake data를 1로 설정하고 discriminator를 학습시킨다. Generator 는 단순히 데이터를 생성함에 그치지 않고 D에 넣는 것까지가 G의 역할이다.
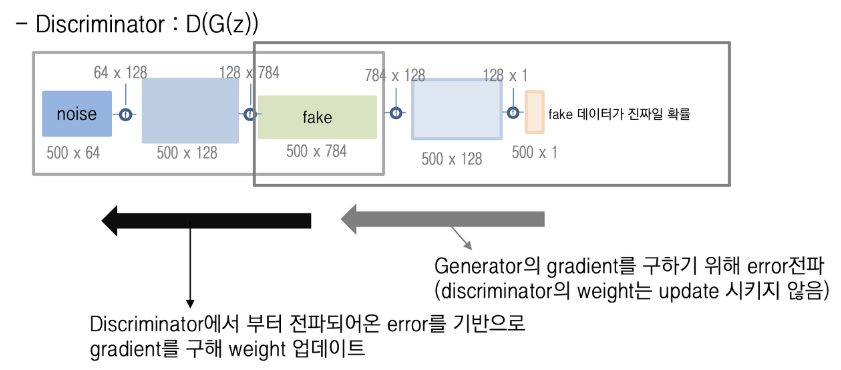
[D의 back propagation]GAN은 D를 학습시킨 후 G를 학습시킨다. G의 weight를 업데이트 시키려면 D에서부터 back propagation 시켜야한다 (G의 역할은 생성한 데이터를 D에 넣는 것 까지이니까).
이 말은 즉, D의 weight를 가져와서 학습시킨다는 것이다. 여기서 D의 weight는 업데이트 시키지 않는다. D가 구별을 못하도록 바보로 만드는 것이 아니라 D의 error를 가지고 전파시켜 G의 weight를 업데이트 하는 것이다.
G의 입장에서는 D가 고정되어 있지만 G의 weight를 업데이트 시키면 D가 fake data를 진짜로 판별할 것이다 라는 개념이다. 이것이 반복되면 G는 실제같은 데이터를 생성해 낼 수 있는 능력이 생긴다.
