지식++1
1.SVM(Support Vector Machine)을 이해해보자
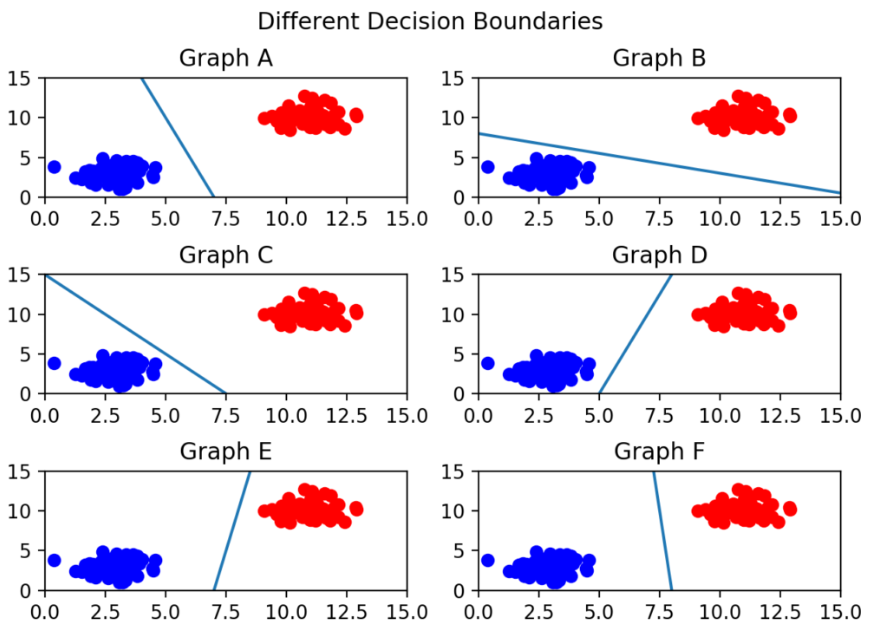
: 두 클래스로부터 최대한 멀리 떨어져 있는 결정 경계를 찾는 분류기로 특정 조건을 만족하는 동시에 클래스 분류를 목표로 한다. 데이터 셋을 분류하는 방법에는 크게 선형(linear) 방법과 비선형(nonlinear) 방법이 있다. 대표적인 선형 방법에는 로지스틱 회귀
2.📝 RNN (Recurrent Neural Network)을 이해해보자
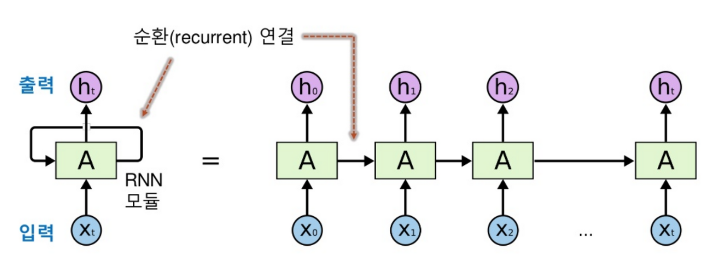
RNN은 순환 신경망으로 입력과 출력을 시퀀스 단위로 처리한다.Sequential(연속형) 데이터를 잘 처리하기 위해 고안된 신경망으로 주로 자연어 처리와 같은, 의미를 찾아내는 분석에서 강점을 가진다.시퀀스란? 문장같이 단어가 나열된 것을 의미한다. 기존 신경망에서는
3.📔 LSTM (Long Short-Term Memory)을 이해해보자 !
💎 Reference http://www.incodom.kr/LSTMhttps://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-krLSTM (Long Short Ter
4.💫 분류 모델(Classifier) 성능 평가 지표

💎 Referencehttps://hleecaster.com/ml-accuracy-recall-precision-f1/https://white-joy.tistory.com/9?category=1015070T(True): 예측한 것이 정답F(False
5.약물 효과 평가 resistant/sensitive
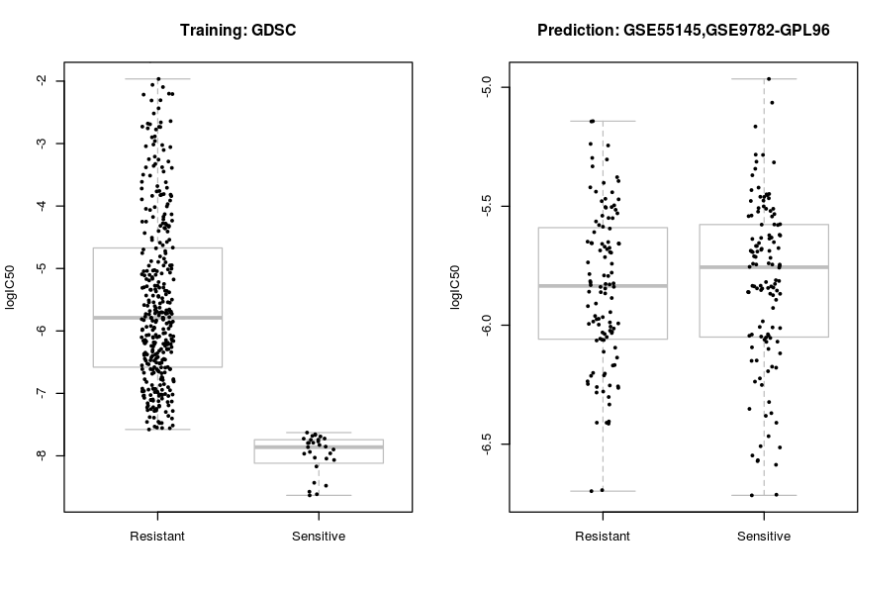
resistant"Resistant"는 저항성이라는 뜻으로, 특정 약물 또는 환경에 대한 저항성을 나타내는 용어로 사용됩니다. 예를 들어, 항생제에 대한 저항성인 항생제 내성이나 암 치료에 대한 저항성인 약물 내성 등이 있습니다.sensitive"Sensitive"는
6.python rdkit install

https://study-grow.tistory.com/entry/rdkit-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0
7.GAN 학습 방법
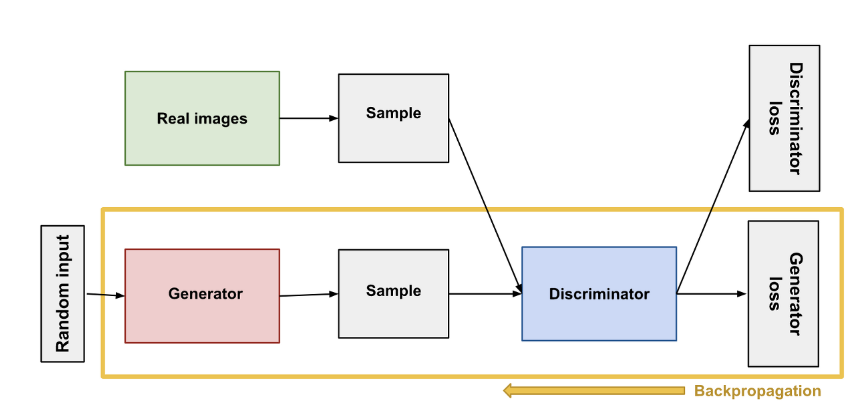
GAN(Generative Adversarial Network)에서 D(판별자)와 G(생성자)를 학습시키는 과정은 아래와 같이 진행됩니다.D의 학습: GAN의 초기 단계에서는 D(판별자)를 먼저 학습시킵니다. 이때, D의 가중치(또는 파라미터)를 업데이트합니다. D의
8.itertools.chain python
https://emilkwak.github.io/itertools-chain-list-concatenation-append
9.PageRank
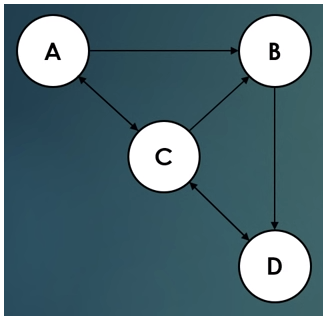
출처 : https://eyeballs.tistory.com/36https://wooono.tistory.com/189PageRank : Google 검색 엔진의 기반 알고리즘으로 하이퍼링크를 이용해 웹 페이지 중요도를 측정한다.각 A, B, C, D
10.loss와 accuracy
loss는 예측값과 정답의 차이 를 말하고accuracy는 올바르게 예측된 데이터의 수 / 전체 데이터의 수 를 말한다.loss가 작다고 해서 항상 acc가 높은 것이 아니고반대로 loss가 높다고 해서 acc가 낮은 것은 아니다.acc의 경우 0.5 이면 구분을 못하
11.[python] Seaborn 행렬 데이터 분포 시각화
업로드중..두 데이터의 분포가 다름을 확인할 수 있다.
12.GAN 학습 방법
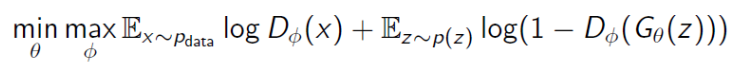
Generator는 실제처럼 보이는 가짜 데이터를 생성하여 Discriminator 를 속이려 하고Discriminator는 실제 데이터와 Generator가 만든 가짜 데이터를 구분하는 역할을 한다.이 둘이 결쟁하면서 학습을 진행함으로 Discriminator는 실제
13.single cell heterogeneity
세포 집단 내 개별 세포 간에 발생하는 다양성을 나타낸다. 모든 세포가 동일한 특징이나 기능을 가지는 것이 아니라 각 세포마다 개별 특성 및 기능을 가지고 있다.이는 유전, 환경 등 여러 요인에 의해 결정된다.단일 세포 RNA 시퀀싱(single-cell RNA seq
14.Maximum Mean Discrepancy
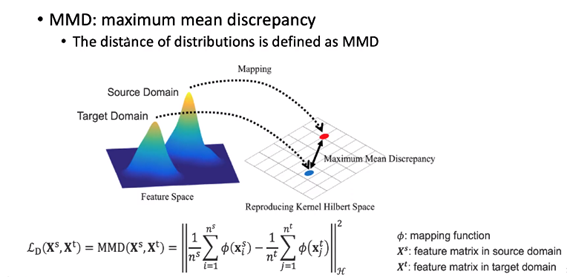
Maximum Mean Discrepancy는 RKHS(Reproducing Kernel Hilbert Space)에서 분포의 평균 임베딩 거리를 계산하여 두 확률 분포 간 차이를 구한다.MMD를 위해서는 데이터를 고차원 공간으로 매핑해야 하는데, 고차원 공간으로 매핑
15.[Python] sklearn 라이브러리 classification_report, auc
y_true : binary y_pred : binary; sensitive > resistance : 1, s<r : 0y_pred_origin : 원시 예측값왜 classification_report 을 사용할 땐 binary로 된 pred 값을 쓰는데 auc