GAN은 Generator와 Discriminator로 구성되어 있다.
Generator는 실제처럼 보이는 가짜 데이터를 생성하여 Discriminator 를 속이려 하고
Discriminator는 실제 데이터와 Generator가 만든 가짜 데이터를 구분하는 역할을 한다.
이 둘이 결쟁하면서 학습을 진행함으로 Discriminator는 실제 데이터와 가짜 데이터를 잘 구분하게 되고 Generator는 Discriminator 를 더 잘 속이기 위해 진짜 같은 가짜 데이터를 생성해낸다.
학습 과정
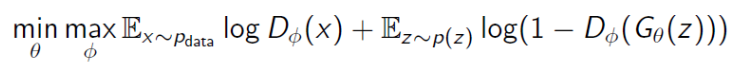
G : Generator
D : Discriminator
1 : 실제 데이터
0 : 가짜 데이터
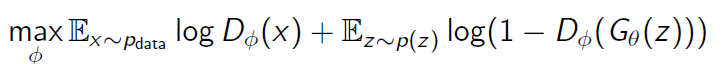
Discriminator를 진짜 데이터를 진짜로 분류하게 학습시킨 후Generator가 생성한 가짜 데이터를 가짜로 분류하도록 학습시킨다.
이는 D(x)를 최대한 1에 가깝게 하고 D(G(z))를 최대한 0에 가깝게 함으로 object function을 maximize 하는 것을 목표로 한다.
여기서 D(x)는 실제 데이터 x를Discriminator에 넣은 것이고 D(G(z))는 noise z를Generator에 넣어 가짜 데이터를 생성하고 가짜 데이터 G(z) 를Discriminator에 넣은 것이다.
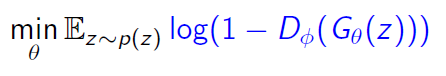
-
Generator는 D(G(z))를 최대한 1에 가깝게 하여 object function을 minimize 하는 것을 목표로 한다.
D(G(z))를 최대한 1에 가깝게 한다는 것은 G(z)를 실제 데이터처럼 만들어Discriminator가 G(z)가 진짜 데이터인지 가짜 데이터인지 구분을 못하게 만든다는 것이다.Discriminator가 G(z)를 1로 분류하면 가짜 데이터를 진짜 데이터라고 구분 ->Discriminator바보
아주아주 쉽게 말하자면
먼저 Discriminator 가 진짜->진짜, 가짜->가짜 로 분류하도록 학습을 시키고
Generator 는 z를 가지고 가짜 데이터를 만드는데 Discriminator 를 속일 수 있도록 진짜처럼 만든다.
그러다보면 Discriminator가 바보가 되어 가짜->진짜라고 분류하게 될 때 쯤이면 Generator 가 제 역할을 다 하고 있는 것이다.

ddochi