🍒출처
https://s5unnyjjj.tistory.com/64
https://hleecaster.com/ml-svm-concept/#comment-1025
위 블로그를 왕왕 많이 참조했습니다.
서포트 벡터 머신(SVM) 이란?
: 두 클래스로부터 최대한 멀리 떨어져 있는 결정 경계를 찾는 분류기로 특정 조건을 만족하는 동시에 클래스 분류를 목표로 한다.
데이터 셋을 분류하는 방법에는 크게 선형(linear) 방법과 비선형(nonlinear) 방법이 있다. 대표적인 선형 방법에는 로지스틱 회귀 등이 있고 비선형 방법에는 SVM이 있다.
SVM은 결정 경계(Decision Boundary), 분류를 위한 기준선을 정의하는 모델이다. 결정 경계를 정의하면 분류되지 않은 새로운 점이 경계의 어느 쪽에 속하는지 판단하여 분류 할 수 있다.
이렇듯 분류기에서 결정 경계는 중요하게 작용한다.
위 그림을 보면 2차원 평면(2개의 속석)에서 결정 경계가 잘 그어진 것을 확인할 수 있다.
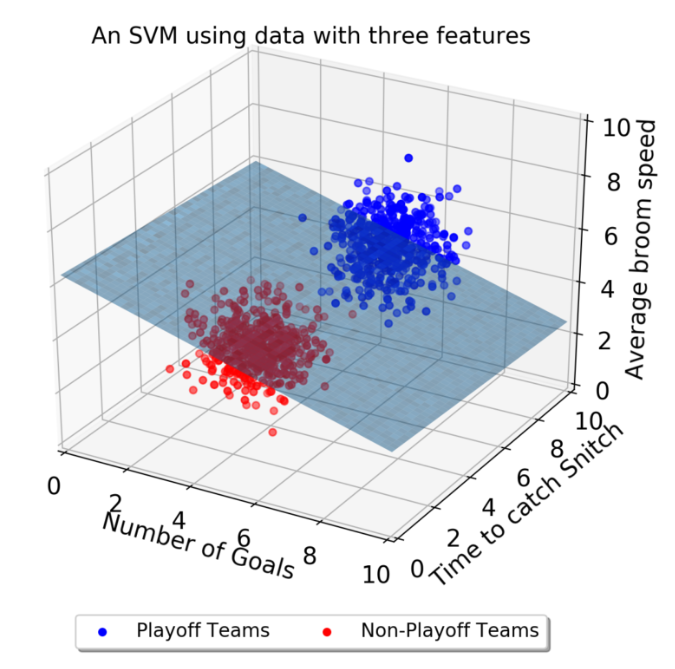
하지만 3차원(3개의 속성)에서는 어떻게 결정 경계를 정할 수 있을까?
위 그림에서는 결정 경계가 선이 아닌 평면 이 된다.
그 이상의 차원에서는 결정 경계도 고차원이 되는데 초평면(hyperplane)이라고 하며 시각적 표현이 어렵다.
결정 경계
분류에서는 결정 경계가 중요하다는 것을 알았다.
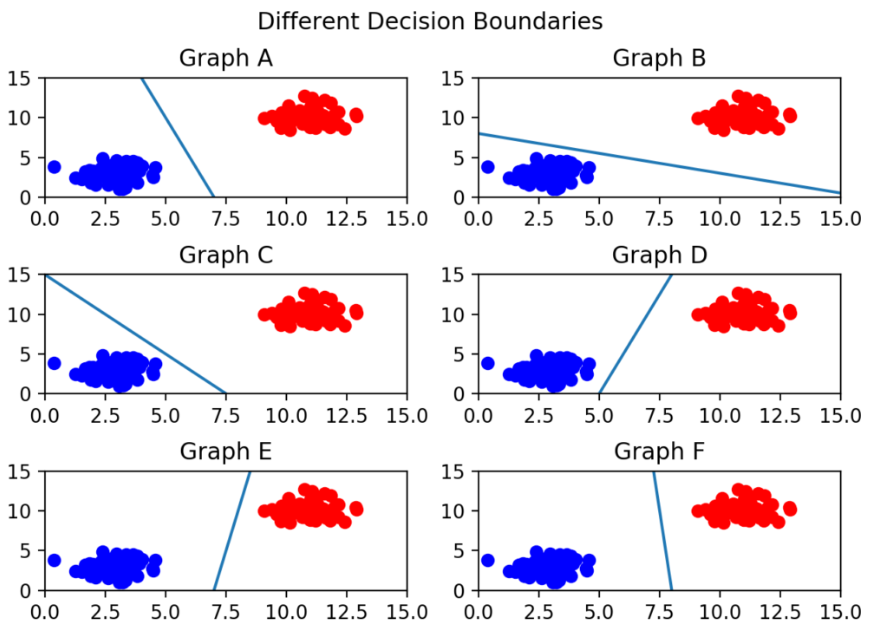
그렇다면 어떤 경계가 좋은 경계일까?
육안으로 확인하면 그래프 C는 파란 부류와 너무 가까워 잘못하면 경계를 넘어갈 수도 있을 것이다.
가장 좋은 경계는 그래프 F로 보이는데 두 부류(class)와 경계 사이의 거리가 가장 멀기 때문이다.
따라서 결정 경계는 데이터 군으로부터 최대한 멀리 떨어지는 것이 좋다.
Support Vector와 Margin
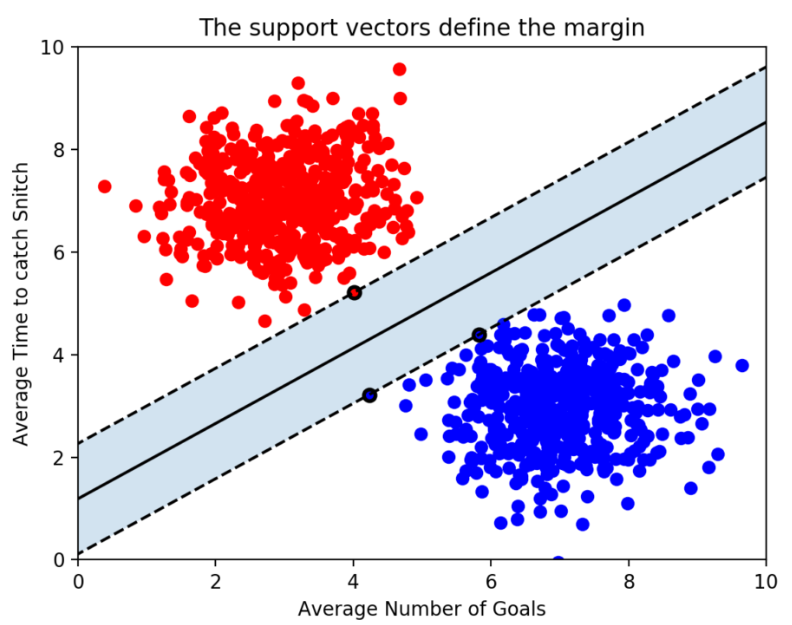
경계를 정의하는데에 있어 결정적인 역할을 하는 Support Vector는 결정 경계와 가장 가까이 있는 데이터 포인터를 의미한다.
가운데 보이는 실선이 결정 경계이고 실선부터 점선(Support Vector의 위치)까지의 거리가 Margin 이다.
가장 좋은 결정 경계는 Margin을 최대화하는 것이다.
위 그림을 보면 평면으로 2개의 속성을 분류하고 있다. 이때 점선과 맞닿은 점이 3개인데 이는 n개의 속성을 가진 데이터에서는 최소 n+1개의 support vector가 존재한다는 것을 알 수 있다.
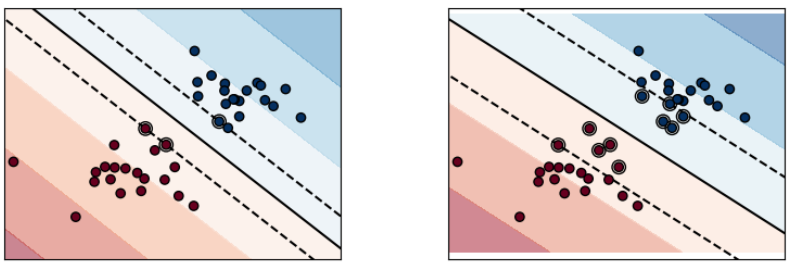
이상치(Outlier)
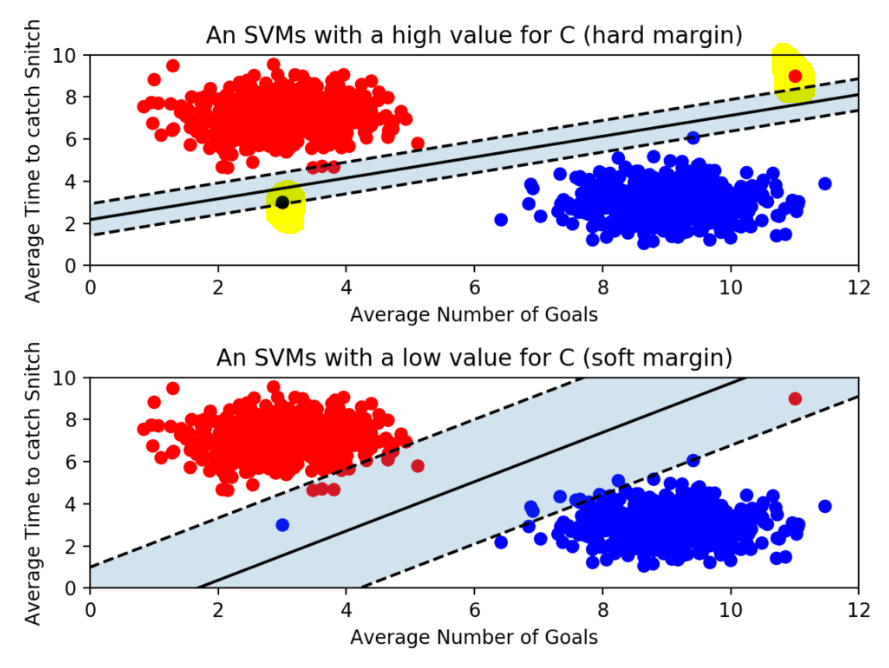
그림에서 형광펜으로 표시한 점이 outlier이고 SVM에서 Margin을 최대화 하기 위해서는 이 이상치(outlier)를 잘 다루는 것이 중요하다.
Margin에는 Hard Margin과 Soft Margin이 있다.
-
위 그림은
Hard Margin Classification으로 outliers에 민감하다. outlier에 민감하다는 것은 기준을 까다롭게 세운 것으로 그림과 같이 Margin이 좁아진다. 학습 데이터를 놓치지 않디 위해 Hard Margin으로 설정하면 오버피팅(Overfitting)이 발생할 수 있다. -
아래 그림은
Soft Margin Classification으로 outliers에 민감하지 않다. Hard Margin 보다 Margin이 넓으며 학습 데이터를 대충 분류하여 언더피팅(Underfitting)이 발생할 수 있다.
scikit-learn에서는 SVM 모델이 오류를 어느정도 허용할 것인지 파라미터 C를 통해 지정할 수 있다.
classifier = SVC(C = 0.01)C값이 클수록 Hard Margin(오류 허용 안 함), 작을수록 Soft Margin(오류를 허용함)이다.
Kernel
만약 선형(linear)하지 않다면 어떻게 경계를 정할 수 있을까?
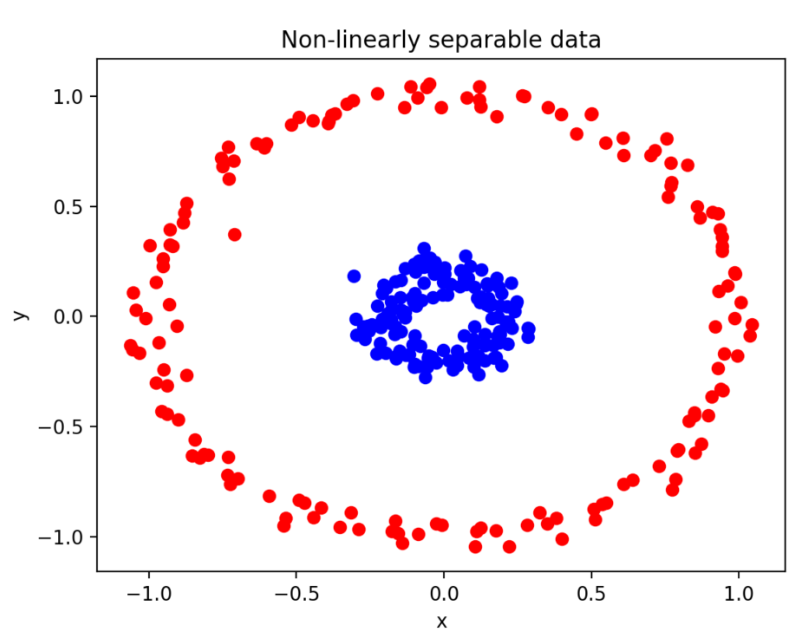
위 그림에서는 파란 부류와 빨간 부류를 구분할 수 있는 직선을 그릴 수 없다.
이러한 문제는 Kernel을 지정하여 해결할 수 있다.
from sklearn.svm import SVC
classifier = SVC(kernel = 'linear')scikit-learn에서 SVM 모델을 만들 때 kernel을 linear, poly 등으로 지정할 수 있다.
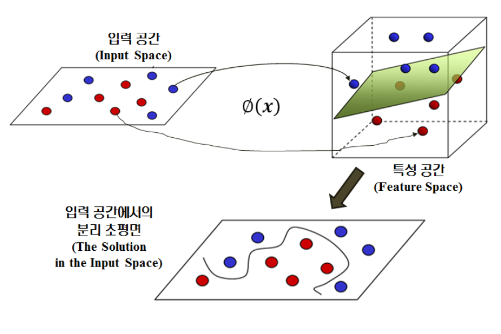
위 그림은 비선형 구조로 변형하여 선형 분류를 진행 할 수 있다. 아래 그림처럼 입력 공간(Input Space)을 학습 데이터의 선형 분리가 가능한 고차원 특성 공간(Feature Space)으로 mapping 할 수 있다. 즉, Kernel을 사용하여 특정한 방식으로 변수 공간을 확장한 것이다.
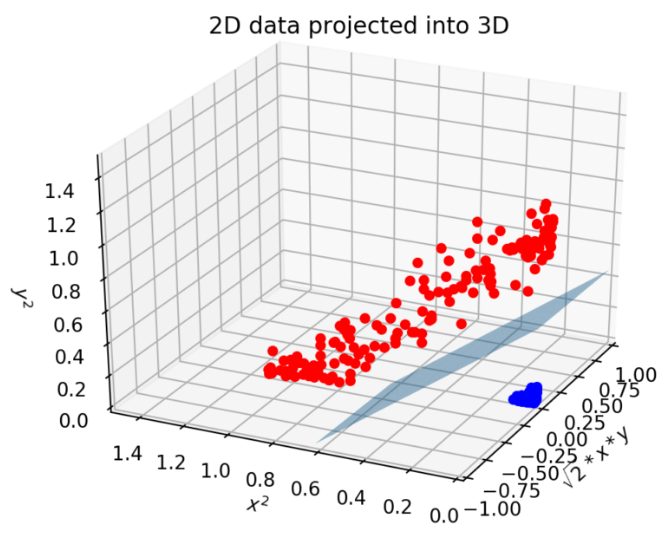
이렇게 Poly Kernel을 사용하면 데이터를 고차원으로 변형하여 나타냄으로써 초평면(hyperplane)의 결정 경계를 얻을 수 있다.
요약
- SVM은
support vectors를 사용해서결정 경계(Decision Boundary)를 정의한다. - 서포트 벡터와 결정 경계 사이의 거리를
Margin이라고 한다. Margin을 최대화하면 좋은결정 경계를 얻을 수 있다.- SVM에서는 선형으로 분리할 수 없는 점들을 분류하기 위해
커널(kernel)을 사용한다. kernel은 원래 가지고 있는 데이터를 더 높은 차원의 데이터로 변환한다. 2차원의 점으로 나타낼 수 있는 데이터를 Poly Kernel은 3차원으로 변환한다.
