💎 Reference
https://hleecaster.com/ml-accuracy-recall-precision-f1/
https://white-joy.tistory.com/9?category=1015070
https://driip.me/3ef36050-f5a3-41ea-9f23-874afe665342
Confusion Matrix(오차 행렬)

T(True): 예측한 것이 정답F(False): 예측한 것이 오답P(Positive): 모델이 positive라고 예측N(Negative): 모델이 negative라고 예측
TP(True Positive): 모델이 positive라고 예측했는데 실제로 정답이 positive (정답)TN(True Negative): 모델이 negative라고 예측했는데 실제로 정답이 negative (정답)FP(False Positive): 모델이 positive라고 예측했는데 실제로 정답이 negative (오답)FN(False Negative): 모델이 negative라고 예측했는데 실제로 정답이 positive (오답)
Accuracy(정확도)
모델이 예측한 것 중 정답
0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
하지만 데이터가 불균형할 때( ex) positive : negative = 9 : 1)는 Accuracy만으로 제대로 분류했는지는 알 수 없기 때문에 Recall과 Precision을 사용한다.
Precision(정밀도) = PPV(Positive Predictive Value)
모델이 positive라고 예측한 것들 중에서 실제로 정답이 positive인 비율
(진짜라고 한 것 중 진짜)
-
실제 정답이 negative인 데이터를 positive라고 잘못 예측하면 안 되는 경우에 중요한 지표가 될 수 있다.
-
Precision을 높이기 위해선 FP(모델이 positive라고 예측했는데 정답은 negative인 경우)를 낮추는 것이 중요하다.
-
0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
Recall(재현율) = Sensitivity(민감도) = TPR(True Positive Rate)
실제로 정답이 positive인 것들 중에서 모델이 positive라고 예측한 비율
(진짜 중 진짜라고 한 것)
-
실제 정답이 positive인 데이터를 negative라고 잘못 예측하면 안 되는 경우에 중요한 지표가 될 수 있다.
-
Recall를 높이기 위해선 FN(모델이 negative라고 예측했는데 정답이 positive인 경우)을 낮추는 것이 중요하다.
-
0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
Precision/Recall Trade-off
Precision과 Recall은 상호 보완적인 평가 지표이기 때문에 어느 한 쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉽다. 이를 Precision/Recall Trade-off라고 부른다.
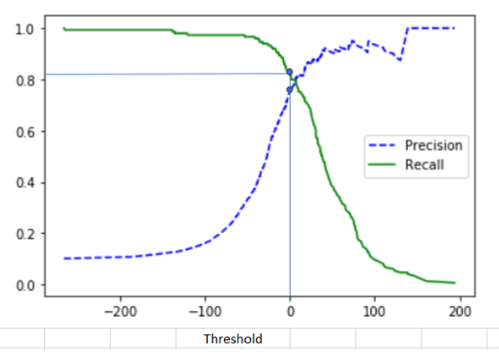
Precision과 Recall의 Trade-off를 결정하는 수치는 분류 결정 Threshold이다. Threshold는 Positive 예측값을 결정하는 확률의 기준이 되며 보통 이진 분류의 경우 확률이 0.5 초과면 Positive로, 0.5 이하면 Negative로 예측하는데, 이 0.5 값이 바로 Threshold이다.
F1 score
Recall과 Precision의 조화평균
- Precision과 Recall이 어느 한 쪽으로 치우치지 않을 때 상대적으로 높은 값을 가진다.
예를 들어 recall, precision이 각각 1과 0.01이라는 값을 가지고 있다고 하자.
산술평균을 구하면 (1 + 0.01) / 2 = 0.505, 즉 절반은 맞히는 것처럼 보인다.
그러나 조화평균을 구해보면 2 (1 0.01) / (1 + 0.01) = 0.019가 된다. 굳
-
Precision과 Recall이 한쪽으로 치우쳐지지 않고 모두 클 때 큰 값을 가진다.
-
0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
Error Rate (ERR)
Error Rate는 Accuracy와 반대로, 전체 데이터 중에서 잘못 예측한 비율을 나타낸다.
FAR == FRR의 포인트를 EER이라 한다.
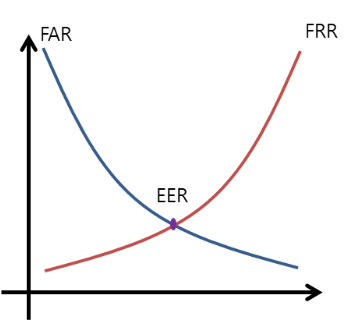
-
FAR(False Acceptance Rate) = FPR는 암이 아닌데 암이라고 한 것이다.
-
FRR(False Rejection Rate)는 암인데 암이 아니라고 한 것이다.
-
FAR, FRR 두 지표 모두 낮을수록 좋지만 서로는TRADE-OFF 관계에 있다.
🐕 요약
-
Accuracy는 모델이 예측한 것 중 정답인 비율이다. -
하지만 데이터가 불균형할 때 Accuracy만으로 제대로 분류했는지는 알 수 없기 때문에
Recall과Precision을 사용한다. -
recision은 모델이 positive라고 예측한 것들 중에서 실제로 정답이 positive인 비율이다. -
Recall은 실제로 정답이 positive인 것들 중에서 모델이 positive라고 예측한 비율이다. -
Precision과 Recall 모두 TP를 높이는 데 동일하게 초점을 맞추지만, Precision은 FP(실제는 0인데 예측은 1)을 낮추는 데에 초점을, Recall은 FN(실제는 1인데 예측 0)을 낮추는 데에 초점을 맞춘다.
-
Precision과 Recall이 어느 한 쪽으로 치우치지 않을 때 상대적으로 높은 값을 가지기에
F1 Score를 사용한다. -
FAR == FRR의 포인트를
EER이라 한다.
