RFM 분석이란?
- 매출 기여도의 분산을 최대화 하는 가중치를 계산한다.
- 가중치와 RFM 점수를 이용하여 고객별로 등급을 부여한다.
- 등급별 매출 기여도를 확인한다.
RFM 분석은 CRM(고객 관계 관리) 분야에서 고객의 가치를 분석하는데 사용되는 분석방법이다.
Recency: 얼마나 최근에 구매하였는가? (최근성)Frequency: 얼마나 자주 구매(방문)하였는가? (행동 빈도)Monetary: 얼마나 많이 구매하였는가? (구매 금액)
RFM 분석 그룹화 하는 방법
- 백분위수
- Pareto 80/20 cut
- 사용자 정의 - 비즈니스 지식 기반
Import Library
import numpy as np
import pandas as pd
import datetime as dt
# 시각화
import matplotlib.pyplot as plt
import seaborn as sns
# ML 알고리즘
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
# 오류 무시
import warnings
warnings.filterwarnings('ignore')Data Load
import pandas as pd
df = pd.read_excel('Online Retail.xlsx')
print(df.shape)
df.head()
결측값, 중복값, 이상치 처리
데이터 정보, 기술통계, 결측값, 중복값 등을 살펴보고 처리해준다.
# 결측치 있는 행 제거
df = df.dropna(subset=['CustomerID'])
# 중복값 제거
df = df.drop_duplicates()
# 음수 값과 0원 제거
df = df[(df['Quantity'] > 0) & (df['UnitPrice'] > 0)]
df.describe() Monetary & 날짜 최대, 최소 확인
# 총 금액을 나타내는 Total Sum Column
df['TotalSum'] = df['UnitPrice'] * df['Quantity']
# Data Preparation Steps
print('Min Invoice Date : ', df.InvoiceDate.dt.date.min())
print('Max Invoice Date : ', df.InvoiceDate.dt.date.max())
df.head()Min Invoice Date : 2010-12-01
Max Invoice Date : 2011-12-09
snapshot_date = df['InvoiceDate'].max() + dt.timedelta(days=1)
snapshot_dateTimestamp('2011-12-10 12:50:00')
RFM 계산
# RFM 계산
rfm = df.groupby(['CustomerID']).agg({'InvoiceDate': lambda x : (snapshot_date - x.max()).days,
'InvoiceNo':'count',
'TotalSum': 'sum'})
rfm = rfm.rename(columns={'InvoiceDate':'Recency','InvoiceNo':'Frequency','TotalSum':'MonetaryValue'})
rfm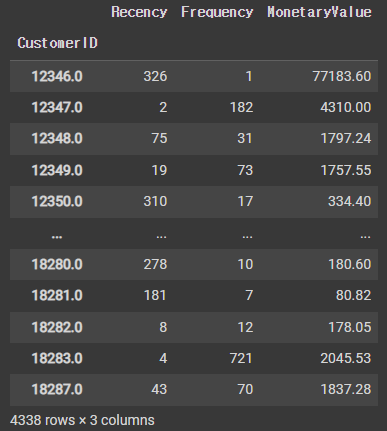
<참고>
위의 InvoiceDate의 lambda 계산식은 groupby를 통해 전체 중 마지막 주문 날짜+1을 한 것과 고객별 가장 최근 주문 날짜와의 차이를 구해 day만 추출해내기 위함이다. 아래 결과 이미지를 보면 dtype이 timedelta 형식이므로 row마다 계산하여 일수만을 추출한다.
snapshot_date - df['InvoiceDate']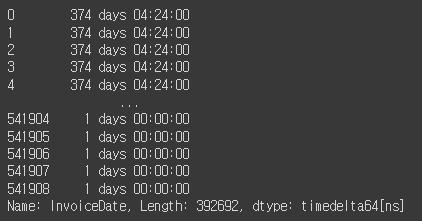
# RFM 세그먼트 구축
r_labels = range(4, 0, -1) # 4, 3, 2, 1
f_labels = range(1, 5) # 1, 2, 3, 4
m_labels = range(1, 5) # 1, 2, 3, 4
r_quartiles = pd.qcut(rfm['Recency'], q=4, labels=r_labels)
f_quartiles = pd.qcut(rfm['Frequency'], q=4, labels=f_labels)
m_quartiles = pd.qcut(rfm['MonetaryValue'], q=4, labels=m_labels)
# assign() 함수를 통해 한 번에 여러 번수를 만들 수 있음
rfm = rfm.assign(R=r_quartiles, F=f_quartiles, M=m_quartiles)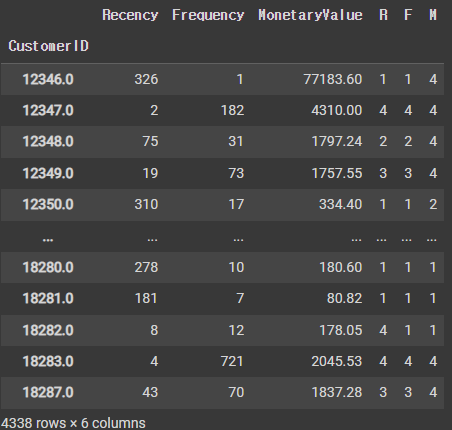
def add_rfm(x):
return str(str(x['R']) + str(x['F']) + str(x['M']))
rfm['RFM_Segment'] = rfm.apply(add_rfm,axis=1 )
rfm['RFM_Score'] = rfm[['R','F','M']].sum(axis=1)
rfm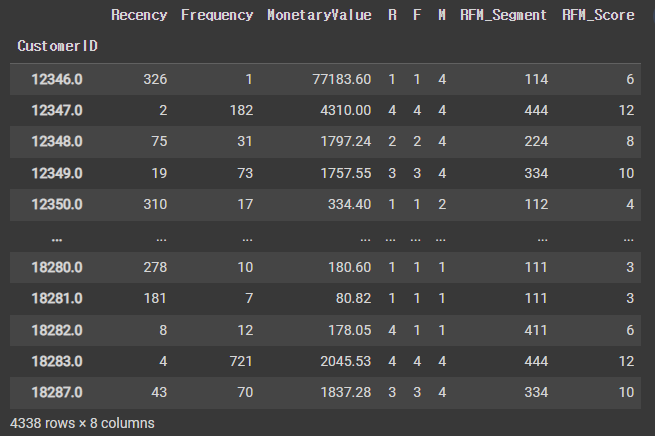
RFM 세그먼트 분석
각 세그먼트별 빈도수를 파악한다.
rfm.groupby(['RFM_Segment']).size().sort_values(ascending=False)하단 세그먼트인 '111'인 경우의 데이터를 확인한다.
rfm[rfm['RFM_Segment'] == '111'].head()RFM Score별로 Recency, Frequency, Monetary의 통계량을 확인한다.
# RFM Score Summary
rfm.groupby('RFM_Score').agg({'Recency':'mean',
'Frequency':'mean',
'MonetaryValue':['mean', 'count']}).round(1)RFM 점수를 사용하여 고객을 골드, 실버, 브론즈 세그먼트로 분류한다.
def segments(df):
if df['RFM_Score'] > 9:
return 'Gold'
elif df['RFM_Score'] <= 5:
return 'Bronze'
else:
return 'Silver'rfm['General_Segment'] = rfm.apply(segments, axis=1)
rfm.groupby('General_Segment').agg({'Recency':'mean',
'Frequency':'mean',
'MonetaryValue':['mean', 'count']}).round(1)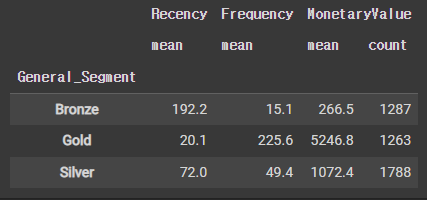
클러스터링을 위한 데이터 사전 처리
K-means를 사용하기 전 다음과 같은 가정을 확인해야 한다.
- 변수의 대칭 분포(편향되지 않음)
- 평균 값이 동일한 변수
- 분산이 동일한 변수
평균과 분산이 동일하지 않다는 문제점을 발견하였다.
Scikit-learn 라이브러리의 Scaler를 사용하여 변수 크기 조정한다.
rfm_rfm = rfm[['Recency','Frequency','MonetaryValue']]
print(rfm_rfm.describe())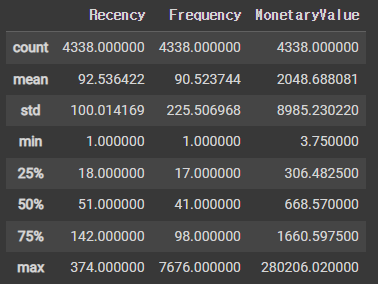
데이터 분포를 시각화한다.
fig, ax = plt.subplots(figsize=(10, 12))
plt.subplot(3, 1, 1);
sns.distplot(rfm['Recency'], label='Recency')
plt.subplot(3, 1, 2);
sns.distplot(rfm['Frequency'], label='Frequency')
plt.subplot(3, 1, 3);
sns.distplot(rfm['MonetaryValue'], label='Monetary')
plt.style.use('fivethirtyeight')
plt.tight_layout()
plt.show()변수의 비대칭 분포(데이터 치우침)라는 문제점도 있다.
이를 해결하기 위해 로그 변환(양의 값만 해당)은 왜도를 관리한다.
다음과 같은 일련의 구조화 사전 처리 단계를 사용한다.
- 데이터 왜곡 해제 - 로그 변환
- 동일한 평균값으로 표준화
- 동일한 표준 편차로 조정
- 클러스터링에 사용할 별도의 어레이로 저장
rfm_log = rfm[['Recency', 'Frequency', 'MonetaryValue']].apply(np.log, axis=1).round(3) # 또는 rfm_log = np.log(rfm2)
# 시각화
f,ax = plt.subplots(figsize=(10, 12))
plt.subplot(3, 1, 1); sns.distplot(rfm_log['Recency'], label = 'Recency')
plt.subplot(3, 1, 2); sns.distplot(rfm_log['Frequency'], label = 'Frequency')
plt.subplot(3, 1, 3); sns.distplot(rfm_log['MonetaryValue'], label = 'Monetary Value')
plt.style.use('fivethirtyeight')
plt.tight_layout()
plt.show()K-평균 균집화 구현
과정은 다음과 같다.
- 데이터 전처리
- 군집 수 선택
- 사전 처리된 데이터에서 k-평균 군집화 실행
- 각 클러스터의 평균 RFM 값 분석
1. 데이터 전처리
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(rfm_log)
rfm_scaled = scaler.transform(rfm_log)2. k값 결정
군집의 수를 정하는 방법은 다음과 같다.
- 시각적 방법 - 팔꿈치 기준
- 수학적 방법 - 실루엣 계수
- 실험 및 해석
from sklearn.cluster import KMeans
ks = range(1, 8)
inertias = []
for k in ks:
# Create a KMeans Clusters
kc = KMeans(n_clusters=k, random_state=42)
kc.fit(rfm_scaled)
inertias.append(kc.inertia_)
# Plot ks vs inertias
fig, ax = plt.subplots(figsize=(15, 8))
plt.plot(ks, inertias, '-o')
plt.xlabel('Number of Clusters, k')
plt.ylabel('Inertia')
plt.xticks(ks)
plt.style.use('ggplot')
plt.title('What is the Best Number for KMeans?')
plt.show()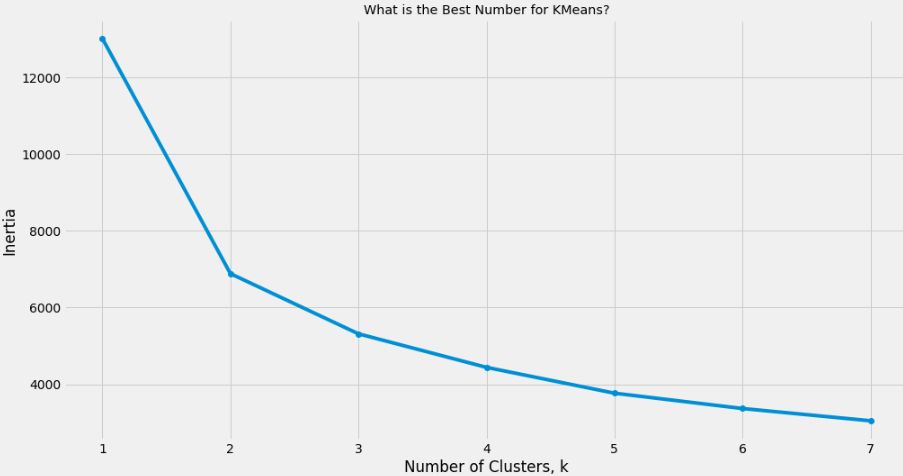
KMeans = 3으로 결정한다.
3. 클러스터링 수행
# 클러스터링
kc = KMeans(n_clusters=3, random_state=1)
kc.fit(rfm_scaled)
# 군집 Label 컬럼 생성
cluster_labels = kc.labels_ # 0, 1, 2
# 각 클러스터의 평균 RFM 값 및 크기 계산:
rfm_k3 = rfm2.assign(K_Cluster=cluster_labels)
rfm_k3.groupby('K_Cluster').agg({'Recency':'mean',
'Frequency':'mean',
'MonetaryValue':['mean', 'count']}).round(0)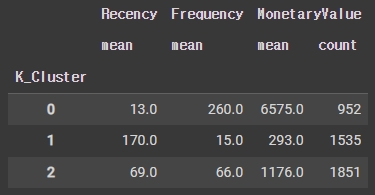
4. 각 클러스터의 평균 RFM 값 분석
rfm_normalized = pd.DataFrame(rfm_scaled, index=rfm2.index, columns=rfm2.columns)
rfm_normalized['K_Cluster'] = kc.labels_
rfm_normalized['General_Segment'] = rfm['General_Segment']
rfm_normalized = rfm_normalized.reset_index()
rfm_normalizedrfm_melt = pd.melt(rfm_normalized,
id_vars=['CustomerID','General_Segment','K_Cluster'],
value_vars=['Recency', 'Frequency', 'MonetaryValue'],
var_name='Metric',value_name='Value')
rfm_melt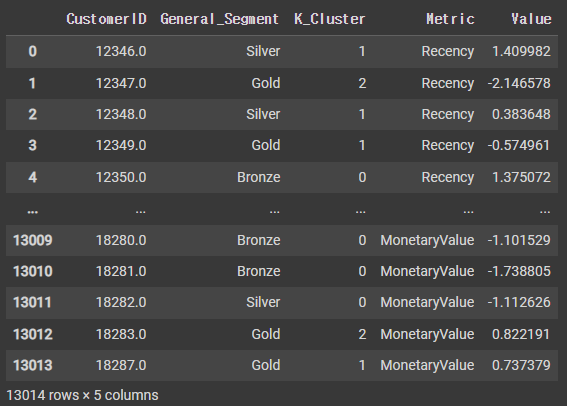
# 시각화
f, (ax1, ax2) = plt.subplots(1,2, figsize=(15, 8))
sns.lineplot(x='Metric', y='Value', hue='General_Segment', data=rfm_melt, ax=ax1)
sns.lineplot(x='Metric', y='Value', hue='K_Cluster', data=rfm_melt, ax=ax2)
plt.suptitle("Snake Plot of RFM",fontsize=24)
plt.show()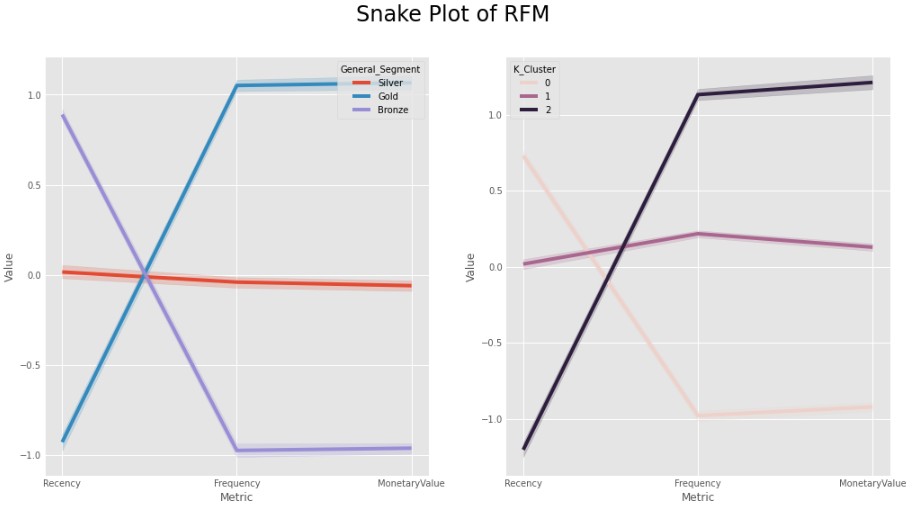
세그먼트 속성의 상대적 중요도
- 각 세그먼트 속성의 상대적 중요성을 식별하는 유용한 기술
- 각 클러스터의 평균 값 계산
- 모집단의 평균 값 계산
- 중요도 점수를 나누고 1을 빼서 계산합니다(클러스터 평균이 모집단 평균과 동일한 경우 0이 반환됨)
# 비율이 0에서 멀어질수록 총 모집단에 상대적인 세그먼트에 대한 속성이 더 중요하다.
cluster_avg = rfm_k3.groupby(['K_Cluster']).mean()
population_avg = rfm2.mean()
relative_imp = cluster_avg / population_avg - 1
relative_imp.round(2)
# 총 평균을 사용하여 비례 차이를 계산한다.
cluster_avg = rfm.groupby('General_Segment').mean().iloc[:, 0:3]
total_avg = rfm.iloc[:, 0:3].mean()
prop_rfm = cluster_avg / total_avg - 1
prop_rfm.round(2)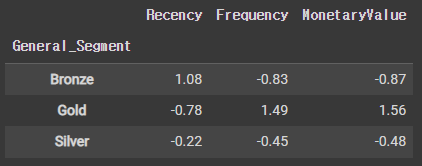
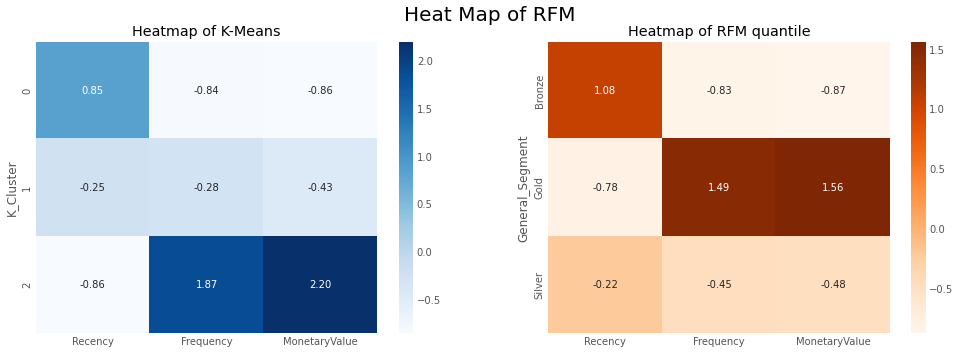
RFM 분위수와 K-Means 클러스터링 방법으로 두 가지 종류의 세분화를 만들었다.
# heatmap with RFM
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
sns.heatmap(data=relative_imp, annot=True, fmt='.2f', cmap='Blues',ax=ax1)
ax1.set(title = "Heatmap of K-Means")
# a snake plot with K-Means
sns.heatmap(prop_rfm, cmap= 'Oranges', fmt= '.2f', annot = True,ax=ax2)
ax2.set(title = "Heatmap of RFM quantile")
plt.suptitle("Heat Map of RFM",fontsize=20) #make title fontsize subtitle
plt.show()