회귀분석이란?
회귀분석(Regression Analysis)은 연속형 변수들에 대해 두 변수 간의 상관관계를 수식으로 나타내는 분석 방법이다. x라는 독립변수와 y라는 종속변수가 존재할 때 두 변수 간의 관계를 y = ax + b와 같은 수식으로 나타낼 수 있다.
회귀분석 5가지 가정
선형성: 독립변수와 종속변수의 관계가 선형관계가 있다.독립성: 잔차(residual)와 독립변수의 값이 관련 없어야 한다.등분산성: 독립변수의 모든 값에 대한 오차들의 분선이 일정해야 한다.비상관성: 관측치들의 잔차들끼리 상관이 없어야 한다.정상성: 잔차항이 정규분포를 이뤄야 한다.
단순 선형 회귀분석
단순 선형 회귀분석은 종속변수와 독립변수가 각각 하나씩 존재하며 서로 선형적인 관계를 가질 때 사용하는 방법이다. 회귀모델은 y = ax + b 형태의 수식으로 나타낼 수 있다.
앞서 상관분석에서 병아리의 몸무게가 종란의 무게와 가장 큰 상관관계를 갖고 있었기 때문에 병아리 무게(y)를 종란의 무게(x)로 어떻게 수식화할 수 있는지 알아보자.
회귀분석은 lm() 함수를 이용해 사용할 수 있다.
# chick_nm 변수를 제외한 데이터 셋 생성
> df_lm <- lm(weight ~ egg_weight, data=df_n)
> summary(df_lm)
Call:
lm(formula = weight ~ egg_weight, data = df_n)
Residuals:
Min 1Q Median 3Q Max
-3.0177 -1.7148 0.1394 1.8080 2.9594
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -14.5475 8.7055 -1.671 0.106
egg_weight 2.3371 0.1336 17.493 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.055 on 28 degrees of freedom
Multiple R-squared: 0.9162, Adjusted R-squared: 0.9132
F-statistic: 306 on 1 and 28 DF, p-value: < 2.2e-16회귀모델의 유의성
- 귀무가설 : 추정된 회귀모델이 유의하다.
- 대립가설 : 추정된 회귀모델이 유의하지 않다.
p-value: < 2.2e-16 : 유의수준 0.05보다 작으므로 추정된 회귀모델이 통계적으로 유의하다.
개별 독립변수의 통계적 유의성
- 귀무가설 : 개별 독립변수가 종속변수의 변화에 영향을 미치지 않는다.
- 대립가설 : 개별 독립변수가 종속변수의 변화에 영향을 미친다.
<2e-16 *** : 유의수준 0.05보다 작으므로 독립변수가 통계적으로 유의하다.
결정계수
1에 가까울수록 회귀모델의 성능이 뛰어나다고 판단한다.
Multiple R-squared: 0.9162 : 0.9162로 1에 가까운 값이므로 회귀모델의 성능이 뛰어나다.
추정된 회귀식
weight = -14.5475 + (2.3371 * egg_weight)
회귀분석 결과를 해석한 뒤 산점도를 그려 그 위에 회귀직선을 표시해 모델이 데이터를 잘 설명하고 있는지 확인하는 것이 좋다.
> plot(df_n$egg_weight, df_n$weight)
> lines(df_n$egg_weight, df_lm$fitted.values, col='blue')
> text(x=66, y=132, label='Y = -14.5475 + 2.3371X')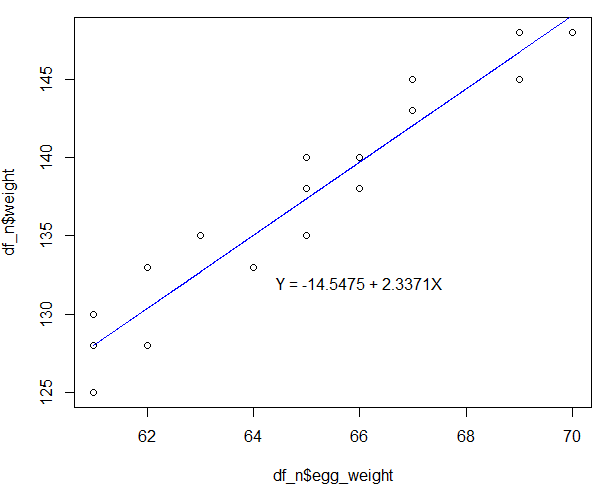
fitted.values에는 독립변수를 이용해 종속변수를 맞춰본 값이 들어 있다. 따라서 lines() 함수로 회귀선을 그릴 때 y에 df_n$weight를 넣지 않은 것이다. names() 함수를 이용해 객체의 이름을 확인할 수 있다.
> names(df_lm)
[1] "coefficients" "residuals" "effects" "rank"
[5] "fitted.values" "assign" "qr" "df.residual"
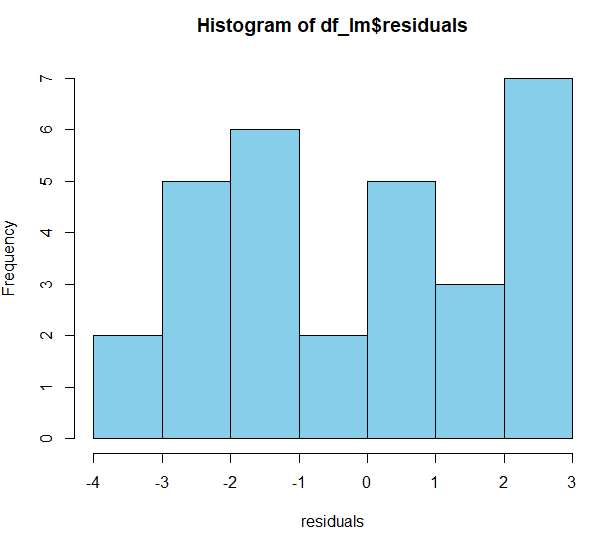
[9] "xlevels" "call" "terms" "model" fitted.values 외에도 coefficients(계수), residuals(잔차) 등 다양한 항목들이 존재한다. residuals는 실제 값과 회귀분석을 통해 예측한 값 사이의 편차(실제값 - 계산된 값)를 의미한다. 이 잔차를 이용해 히스토그램을 그려보는 것도 모델 성능을 판단할 때 중요한 지표로 사용된다.
> hist(df_lm$residuals, col='skyblue', xlab='residuals')