분류 알고리즘 성능 평가 방법
분류 알고리즘의 경우 일반적으로 정오분류표(Confusion Matrix)와 ROC Curve의 밑부분 넓이인 AUC를 이용해 성능을 평가한다.
정오분류표
실제 값과 예측값이 서로 얼마나 잘 맞아 떨어졌는지를 표로 나타낸 것이다. 수치형 데이터와 달리 범주형 데이터의 경우 실제 값과 예측값이 같은지 다른지를 진릿값(True or False)로 표현할 수 있기 때문에 이런 방법을 사용한다.
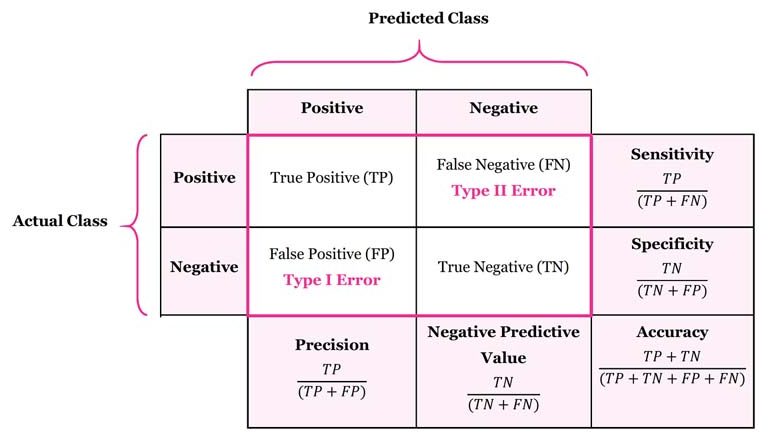
TP: 긍정으로 예측했는데 실제로 긍정TN: 부정으로 예측했는데 실제로 부정FP: 긍정으로 예측했는데 실제로 부정FN: 부정으로 예측했는데 실제로 긍정
민감도(Sensitivity):특이도(Specificity):정밀도(Precision):정확도(Accuracy):
민감도는 질병 진단 관점에서 질병이 있는 사람을 얼마나 잘 찾아내는지를 나타내는 지표이다. 즉, 질병이 있는 사람에게 질병이 있다고 진단하는 비율을 뜻한다.
민감도는 재현율(Recall)이라는 용어로 사용되기도 하며 계산하는 공식도 같다.
잘못 진단해서 손실이 막대한 경우에는 정확도보다 민감도를 더 중요한 지표로 사용한다.
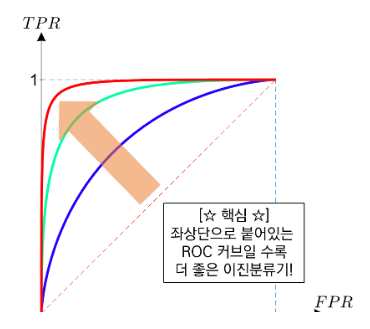
ROC Curve
ROC Curve는 정오분류표를 통해 도출해낼 수 있는 민감도를 y축으로, (1-특이도)를 x축으로 하는 커브이다. 커브의 밑부분 면적을 AUC라고 한다. AUC가 100%에 가까울수록 분류 모델의 성능이 뛰어나다고 판단한다.
로지스틱 회귀모델 성능 평가
앞서 진행했던 로지스틱 회귀모델을 사용하여 성능을 평가한다.
> df$pred <- df_glm$fitted.values
> head(df)
wing_length tail_length gender pred
1 44 9 m 0.9155791
2 42 9 m 0.9889042
3 43 8 m 0.9970495
4 40 10 m 0.9853766
5 44 8 m 0.9915881
6 43 8 m 0.9970495pred가 0.5보다 크면 m, 아니면 f로 판정한다.
> df$gender_pred <- ifelse(df$pred > 0.5, 'm', 'f')
> head(df)
wing_length tail_length gender pred gender_pred
1 44 9 m 0.9155791 m
2 42 9 m 0.9889042 m
3 43 8 m 0.9970495 m
4 40 10 m 0.9853766 m
5 44 8 m 0.9915881 m
6 43 8 m 0.9970495 m해당 데이터를 활용하여 정오분류표를 그려보자. table() 이라는 함수를 이용하면 쉽게 그릴 수 있다. table(예측값, 실제값)으로 사용한다.
> table(df$gender_pred, df$gender)
f m
f 29 2
m 1 28한눈에 봐도 정확도가 높아 보이지만, 민감도와 특이도도 계산해보기 위해 caret 패키지의 confusionMatrix() 함수를 사용하여 계산한다.
단, pred 값을 factor 형태로 변경해주어야 한다. 기존의 gender가 factor 형태이기 때문이다. 서로 형태가 맞아야만 confusionMatrix() 함수가 잘 작동한다.
# 패키지 설치 및 불러오기
> install.packages('caret')
> library(caret)# 형 변환
> df$gender_pred <- as.factor(df$gender_pred)
> confusionMatrix(df$gender_pred, df$gender)
Confusion Matrix and Statistics
Reference
Prediction f m
f 29 2
m 1 28
Accuracy : 0.95
95% CI : (0.8608, 0.9896)
No Information Rate : 0.5
P-Value [Acc > NIR] : 3.127e-14
Kappa : 0.9
Mcnemar's Test P-Value : 1
Sensitivity : 0.9667
Specificity : 0.9333
Pos Pred Value : 0.9355
Neg Pred Value : 0.9655
Prevalence : 0.5000
Detection Rate : 0.4833
Detection Prevalence : 0.5167
Balanced Accuracy : 0.9500
'Positive' Class : f- 정확도(Accuracy) : 0.95
- 민감도(Sensitivity) : 0.9667
- 특이도(Specificity) : 0.9333
ROC Curve를 그려 AUC 값을 확인해보자. Epi라는 패키지를 활용해 쉽게 그릴 수 있다. ROC(확률값, 실제 값)을 입력해준다. 예측값이 아닌 확률값을 입력함에 주의하자.
> install.packages('Epi')
> library(Epi)> ROC(df$pred, df$gender, main='ROC Curve')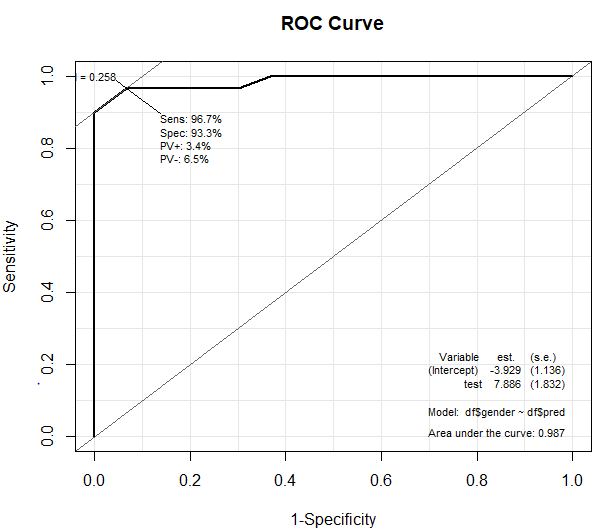
AUC 값이 0.987로 1엥 매우 가까운 값이 나타났다. 로지스틱 회귀모델의 성능은 매우 뛰어나다고 할 수 있다.
