안녕하세요, 이번 시간에는 SAM 모델에 대한 논문 리뷰를 진행하도록 하겠습니다.
*1~2파트는 도입부로써 이후 전개될 내용과 다소 겹치는 점이 있어 생략하겠습니다.
3. SAM
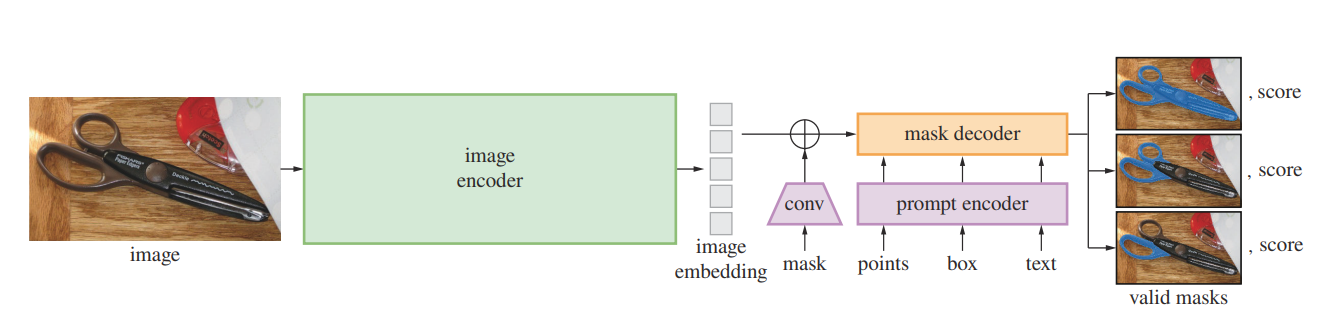
(1) Image Encoder :
MAE로 사전훈련된 Vision Transformer(VIT)를 기반으로하여 고해상도 모델을 처리하도록 최소한으로 수정된 모델을 채택하였습니다. 이미지당 1번 실행되며 프롬프트 전에 적용됩니다. 이미지 인코더의 단계는 하기와 같습니다.
-
이미지 패치 분할
입력 이미지를 여러 개의 작은 패치로 분할합니다. -
패치 임베딩
각 패치는 고정된 크기의 벡터로 변환됩니다.
패치의 특징을 요약하며 트랜스포머 계층에서 활용됩니다. -
포지셔널 임베딩 추가
트랜스포머 아키텍쳐의 특성 상 순서 정보가 필요합니다.
패치 임베딩에 위치 정보 포함시킵니다. -
self attetion 메커니즘
모든 패치 간의 상호작용을 고려하여 각 패치가 이미지 내에서 중요한 정보인지 학습시킵니다. -
최종 feature map 생성
인코더의 출력은 이미지의 특징 맵입니다.
이 맵은 이미지의 구조, 모양, 색상 등과 같은 시각적 정보를 포함합니다.
이 특징 맵은 SAM의 마스크 디코더에 전달되어 특정 객체의 위치나 형태에 대한 정보를 분할하는 데 사용됩니다.
(2) Prompt Encoder :
프롬프트 인코더는 희소 프롬프트와 밀집 프롬프트로 나뉘어집니다.
- 희소 프롬프트는 포인트 박스, 텍스트
- 밀집 프롬프트는 마스크
희소 프롬프트(포인트, 박스)는 학습된 임베딩과 위치 인코딩을 합하여 나타냅니다.
텍스트는 Clip의 기본 텍스트 인코더로 처리합니다.
밀집 프롬프트(마스크)는 Convolution을 사용하여 임베딩한다. 이미지 임베딩과 요소별로 합쳐집니다.
알아가기, 프롬프트 임베딩이란?
어떠한 입력된 단어를 고유한 숫자배열로 변환하는 것이다.
알아가기, 이미지 임베딩이란?
이미지를 고차원의 벡터 공간의 점으로 변환하는 것이다.
- 이미지를 고차원의 벡터공간의 점으로 변환한다.
- 이미지는 2차원의 배열, 임베딩시 1차원의 벡터로 변환한다.
- 특징추출한다. 중요한 특징 추출, 백터로 표현
- 의미보존, 비슷한 의미의 이미지들이 벡터 공간에서 가까운 위치에 배치되도록 설계한다.
(3) Mask Decoder:
마스크 디코더는 이미지 임베딩, 프롬프트 임베딩 및 출력 토큰을 마스크로 매핑합니다.
마스크 매핑의 단계는 하기와 같습니다.
-
입력 이미지 : 이미지를 인풋
-
특징 추출 : 모델이 이미지에서 객체 특징 추출
-
마스크 생성 : 디코딩 단계에서 추출된 특징 기반으로 픽셀이 특정 객체에 속하는지 판단, 객체에 해당하면 1, 아니면 0 -> 이진형태
-
업샘플링 : 특징맵을 다시 이미지 크기로 확장
(4) 모호성 해결 :
단일 출력 모델은 모호한 prompot를 받으면 여러가지의 유효한 마스크를 평균화합니다.
이를 해결하기 위해 단일 프롬프트에 대해 여러 개의 출력마스크를 예측하도록 수정합니다.
일반적으로 3개의 마스크 출력이 충분합니다.
마스크의 순위를 매기기 위해 모델은 각 마스크에 대해 신뢰도 점수(즉, IOU 추정치)를 예측합니다.
(5) 손실함수 및 훈련 :
선형 결합된 focal loss와 dice loss로 마스크 예측을 지도 학습합니다.
4. 세그먼트 애니띵 데이터 엔진
10억개의 마스크 데이터셋 SA-1B를 수집할 수 있도록 데이터 엔진 구축
데이터 엔진은 세 가지 단계로 이뤄집니다.
(1) 모델 지원 수동, 주석 단계
주석자가 브라우저 기반 인터렉티브 세그멘테이션 도구를 사용하여 전경/배경 객체 포인트를 클릭함으로써 마스크를 주석합니다.
주석자는 물건과 사물을 자유롭게 주석할 수 있습니다.
마스크가 더 수집됨에 따라 이미지당 평균 마스크는 20개에서 44개로 증가되었습니다. 이 단계에서 총 12만장의 이미지에서 430만개의 마스크 수집했습니다.
(2) 자동으로 예측된 마스크와 모델 지원 주석을 혼합, 반자동 단계
모든 객체를 세그멘테이션하기 위하여 마스크의 다양성 증대하고자 진행한 단계입니다. 신뢰할 수 있는 마스크 자동으로 감지 후 이런 마스크로 미리 채워진 이미지를 주석자에게 제공하였습니다. 추가로 주석되지 않은 객체를 주석하도록 요청하였습니다.
(3) 주석자 입력 없이 모델이 마스크를 생성, 완전 자동 단계
마지막 단계에는 주석이 완전히 자동으로 이뤄졌습니다.
모델에 두가지 주요 개선 사항이 있었기에 가능했습니다.
1) 충분한 마스크를 수집해서 모델을 크게 개선
2) 모호성을 인식하는 모델을 개발
구체적인 과정
- 모델의 32x32의 규칙적인 그리드의 포인트를 제공
- 각 포인트에서 유효한 객체 마스크 세트 예측
- iou를 통해서 신뢰할 수 있는 마스크 선택 그리고 비최대 억제 적용
- 작은 마스크의 품질 향상을 위해 겹치는 여러 확대 이미지 크롭 처리
위와 같은 방법으로 10억개 이상의 고품질 마스크 생성
5. 세그먼트애니띵 데이터셋
SA-1B는 1.1억 개의 고해상도, 라이선스가 부여된, 프라이버시를 보호하는 이미지와 10억개 이상의 고품질 세그멘테이션 마스크로 구성된 이미지 데이터셋입니다. 해당 데이터 셋에 대하여 조금 면밀하게 살펴보겠습니다.
이미지 :
마스크 :
데이터 엔진은 10억개 이상의 마스크를 생성, 그중 99.1%는 완전 자동 생성합니다.따라서 자동 마스크의 품질이 중요합니다. 분석 결과 고품질이며 모델 훈련에 효과적이었습니다. 이 결과를 바탕으로 SA-1B에는 자동으로 생성된 마스크만 포함하도록 했습니다.
마스크 품질 :
마스크 전문가가 수정한 마스크와 자동마스크의 쌍을 생성하여 iou를 비교하였을 때에 쌍의 94%가 90% 이상의 iou, 97%가 75% 이상의 iou를 보였습니다.
따라서 자동마스크로 모델 훈련하는 것이 모든 마스크로 사용하는 것과 거의 동등하게 좋았습니다.
6. 세그먼트 애니띵 책임있는 AI(RAI) 분석
우리는 SA-1B와 SAM을 사용할 때에 발생할 수 있는 잠재적 공정성 문제와 편향에 대해 조사하였습니다.
SA-1B의 지리적 및 소득 분포 SAM이 보호 속성에 걸쳐 공정하게 작동하는지 중점을 두었습니다.
지리적 및 소득 대표성
SA-1B의 이미지 수 자체는 중간 소득 국가에세 이미지 비율이 크게 높습니다.
이미지당 평균 마스크 수는 지역 소득에 관계없이 비교적 일관된 수준을 보였습니다.
7. 제로샷 전이 실험
알아가기, 제로샷 전이란 무엇인가?
제로샷 전이란 모델이 학습된 데이터셋에 없는 새로운 작업이나 클래스에 별도의 추가 학습 없이도 예측을 수행할 수 있는 능력을 말합니다.
제로샷 전이 실험
이 섹션에서는 SAM 모델을 사용한 제로샷 전이 실험을 제시합니다.
다섯가지 작업을 고려하였고 그 중 네가지는 SAM을 훈련시킨 프롬프트 가능한 세분화 작업과 다른 점을 보입니다.
이 실험들은 SAM이 훈련 중에 보지 못한 데이터 셋과 작업에서의 성능을 평가합니다.
프롬프트에서 유효한 마스크를 생성하는 것을 작업으로 시작합니다.
단일 전경 프롬프트와 같은 더 모호한 시나리오를 강조합니다.
단일전경프롬프트로 인하여 특별한 지시 없이도 다양한 객체를 인식하고 segmentation 할 수 있도록 설계합니다.
모호성 시나리오를 강조하는 이유는 여러 가능성을 고려하도록 훈련시키기 위함입니다.
SAM은 다음과 같은 작업에 프롬프트 합니다.
(1) 엣지 감지 수행
(2) 모든 객체 세분화
(3) 탐지된 객체 세분화
(4) 개념 증명으로 자유형식 텍스트에서 객체 세분화
구현
별도의 명시가 없는 한 SAM 모델은 MAE로 사전훈련된 VIT-H 이미지 인코더를 사용합니다.
SAM은 데이터 엔진의 마지막 단계에서 자동으로 생성된 마스크 만을 포함하는 SA-1B 데이터로 훈련되었습니다.
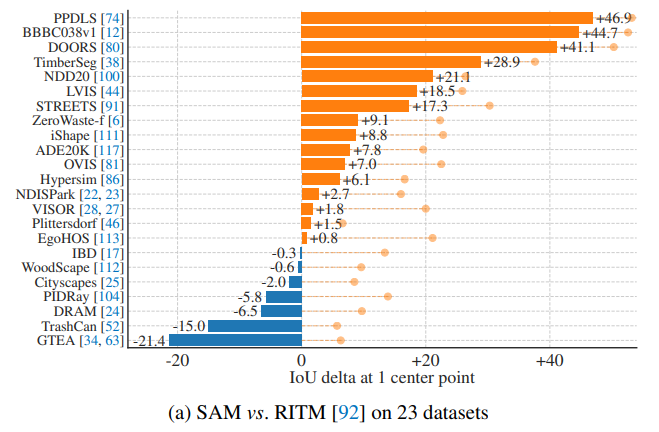
7-1 제로샷 단일 포인트 유효 마스크 평가
작업 : 단일 전경 포인트 객체 세분화하는 작업을 평가
하나의 포인트가 여러 객체를 나타낼 수 있기 때문에 명확하지 않습니다.
대부분의 데이터 셋에서 가능한 모든 마스크를 열거하지 않기 때문에 자동 측정 지표는 신뢰할 수 없습니다. 추가로 mIoU를 지표에 더 했습니다.
RITM보다 성능이 뛰어나거나 떨어지는 데이터 셋이 모두 포함됩니다.
알아가기, RITM이란?
Rethinking Image-Text Matching
이미지와 text의 matching을 재고하는 접근 방식을 나타냅니다.
이는 RITM은 이미지와 텍스트 간의 관계를 이해하고 이를 바탕으로 정교한 분할 및 인식 기능을 제공합니다.
이는 이미지 내의 객체와 그것에 관련된 Text를 효과적으로 매칭하여 모델이 보다 정확하게 객체를 인식하고 분할하도록 돕습니다.

위의 이미지는 데이터셋에 대한 예시입니다.
데이터 셋은 다양한 이미지 분포를 가진 23개의 데이터 셋 모음을 사용합니다. 데이터 셋에 속해있는 목록과 각 데이터의 샘플을 나타냅니다.
23개의 데이터셋 전체에 대하여 mIoU 평가를 수행하였습니다.
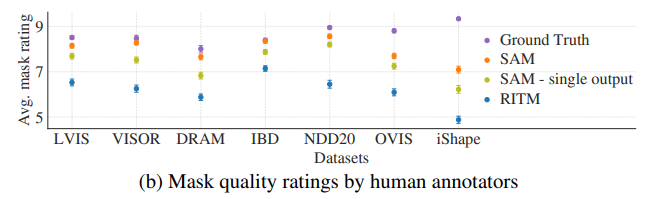
인간 연구를 위해 그림 9-(b)에 나열된 하위 집합의 데이터를 사용하였습니다.
하위 집합에는 SAM이 자동측정하였을 때에 RITM보다 성능이 높거나 낮은 데이터를 모두 포함합니다.
7-3 제로샷 객체 제안
접근방법 :
- 객체 제안 생성을 평가합니다.
- 마스크 생성 파이프라인의 다소 수정된 version을 실행합니다.
- 마스크를 제안하여 출력합니다.
ViTDet-H 모델과 SAM 모델 비교
모델의 비교는 LVIS 데이터를 통하여 진행하였습니다.
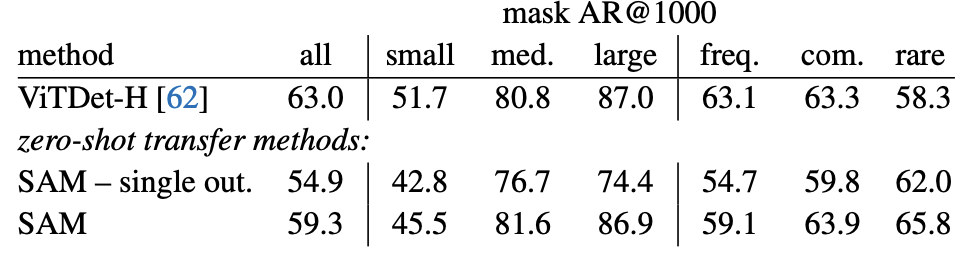
<표 4> 에서 보이는 것 처럼 전체 평균 점수는 VITDET-H가 좋은 점수를 보입니다. 다만 'med', 'large', 'common', 'rare'의 부분에서는 SAM이 좋은 점수를 나타내는 것을 확인할 수 있습니다.
VitDet-H 이미지인코더가 'small' 객체와 'freq' 객체에서 낮은 성능을 보이는 이유는 해당 인코더는 이미 LVIS로 훈련된 모델이기 때문에 특정 주석 편향을 쉽게 학습 할 수 있었기 때문입니다.
7-4 제로샷 인스턴스 세분화
접근 방법 :
더 높은 수준의 vision을 다르며 SAM을 인스턴스 세분화 모듈로 사용합니다.
알아가기, instance segmentaion이란 ?
이미지 내의 객체를 개별적으로 식별하고 그 경계를 분할하는 작업입니다.
구현 :
객체 탐지기 VITDET을 실행하여 출력상자를 SAM의 프롬프트로 사용합니다.
결과 :
표5를 확인할 때에 ViTDeT-H은 SAM보다 지표상 더 높은 점수를 가지는 것을 확인할 수 있습니다. 그러나 출력을 시각화했을 때에 SAM의 마스크가 VITDet보다 경계가 더 선명하게 출력되는 경우가 잦았습니다.
SAM과 VIT에서 생성된 Mask를 주석자들에게 요청하여 비교할 시 SAM이 더 좋은 성능을 보이는 것을 확인할 수 있었습니다.
SAM은 zeroshot이기때문에 편향을 활용할 수 없습니다. 따라서 특정 데이터셋에 매몰되지 않고 더 유용한 것을 확인할 수 있습니다.

7-5 제로샷 텍스트에서 마스크로 전이
알아가기, Clip은 무엇인가?
CLIP(Contrasive Language-Image Pretraining)은 OpenAI에서 개발한 모델로, 이미지와 텍스트를 같은 의미 공간에서 학습하도록 설계한 멀티모달 AI입니다. CLIP의 목적은 텍스트 설명에 맞는 이미지를 찾거나, 반대로 이미지에 해당하는 텍스트 설명을 찾을 수 있도록 학습하는 것입니다. CLIP의 주요 특징은 텍스트와 이미지를 쌍으로 학습하여 두 가지 간의 의미적 관계를 이해할 수 있다는 점입니다.
제로샷 텍스트에서 마스크로 전이
자유형식 텍스트 → 객체를 세분화하는 작업을 고려합니다.
이는 SAM이 Text prompt를 처리할 수 있는지 능력을 증명하는 것입니다.
각 수집된 마스크가 면적이 1002보다 큰 경우에 clip 이미지 임베딩을 추출합니다.
그리고나서 SAM Clip 이미지 임베딩을 첫번째 상호작용으로 Prompt Clip의 이미지 임베딩이 Text 임베딩과 일치하도록 훈련됩니다.
이미지 임베딩으로 훈련하면서도 추론시에는 Text 임베딩을 사용할 수 있는 것입니다. 즉 추론시에는 Text를 Clip의 Text Encoder에 통과시킨 후 고차원 벡터 형태의 text 임베딩으로 변환됩니다. 해당 text 임베딩을 SAM의 Prompt로 제공하여 프롬프트를 조금 더 이미지와 유사한 의미를 가진 프롬프트로 사용하게 하는 것입니다.
결과 :
<그림12> 처럼 text prompt로 구체 적 구분을 기반으로 객체 세분화를 가능하게 합니다.
text가 segmetation을 잘 하지 못한다면 point를 주었을 때에 예측을 개선할 수 있습니다.

7-6 절삭연구(Ablations)
단일중심 point prompt를 사용하여 23개의 데이터 셋에 대해 여러 절삭 연구를 수행하였습니다.
단일 point는 모호할 수 있으며 모호성은 실제 값에 반영되지 않을 수 있습니다. 실제 값에는 Point당 단일 마스크만 포함되기 때문입니다. SAM은 제로샷 전이 환경에서 작동합니다. 따라서 SAM의 최상위 마스크와 데이터 추정 가이드라인에 따른 마스크간 체계적인 편향이 있을 수 있습니다. 실제 값에 대한 최상의 마스크도 추가로 보고합니다.
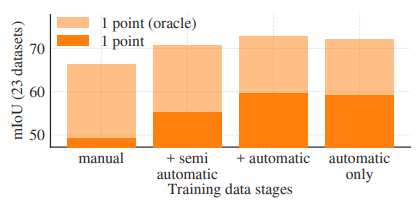
<그림13-1>
데이터 엔진 단계별 누적 데이터를 사용합니다. 훈련된 SAM의 성능을 나타냅니다.
그림 13-1에 표기된 세가지 단계를 사용했을 때, 자동생성 마스크는 수동, 반자동 마스크보다 훨씬 많았습니다. 이를 해결하기 위해 수동 혹은 반자동 마스크를 10배 더 샘플링 했습니다. 그러나 이 과정은 복잡하니다. 따라서 마지막 단계 즉 자동으로 생성된 마스크만을 사용하는 훈련을 진행하였습니다. 이는 모든 데이터의 사용보다 0.5 mIoU가 낮은 성능을 보입니다. 결론적으로 훈련의 단순화를 위해 마지막 단계를 사용합니다.
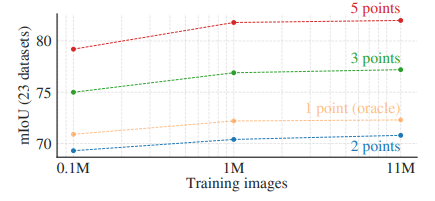
<그림13-2>
데이터의 양이 성능에 미치는 영향을 나타냅니다.
SA-1B 데이터셋은 1100만개 이미지를 포함합니다. 이는 100만 및 10만개로 서브샘플링하여 테스트를 진행합니다.
테스트 결과는 그림 13-2처럼 10만개보다 100만개로 서브샘플링이 더 좋은 지표를 보였습니다.
알아가기, 서브샘플링이란?
데이터셋에서 일부 샘플을 선택하여 전체 데이터셋을 대표합니다. 그 예로 train_test_split 함수를 들 수 있습니다.
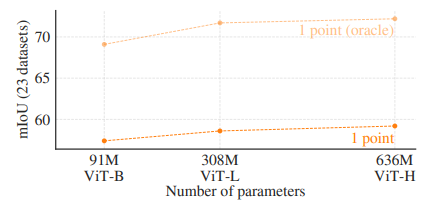
<그림 13-3>
VIT-B, VIT-L, VIT-H 이미지 인코더 사용결과는 다음과 같습니다.
VIT-H는 VIT-B에 비해 크게 향상된 결과를 보였습니다.
VIT-L에 비해서 이득이 미미했습니다. 결론적으로 VIT-H가 가장 좋은 성능을 보입니다. 다만 그 연산량이 많은 것을 유의해야합니다.
7-8 논의
한계
-
작은 세부사항 세분화의 어려움 :
SAM은 분리된 작은 구성 요소를 잘못 예측하거나 미세한 구조를 놓칠 수 있습니다.계산집약적인 방법들만큼 더 세밀한 경계를 선명하게 생성하지 못하는 경우가 있습니다.더 많은 point를 제공하는 경우 이러한 상호작용세분화 방법들이 SAM보다 더 높은 성능을 발휘할 것입니다. 하지만 SAM은 상호작용 세분화를 추구하지 않고 다양한 용도를 포괄하는 일반성을 추구합니다.
-
실시간 성능의 한계 :
Prompt를 실시간으로 처리할 수 있지만 *무거운 이미지 인코더를 사용하는 경우 연산을 완료하는 것에 시간이 많이 소요되어 전반적인 성능은 실시간이 아닙니다.
