Yolo1 논문에 대한 리뷰를 진행하도록 하겠습니다.
이는 Yolo1에 대한 논문을 분석한 것을 기반으로하여 이해하기 쉽게 정리된 글입니다.
What is Yolo?
Yolo는 You Only Look Once의 약자입니다. 말 그대로 이미지를 input하였을 때에 한번의 과정으로 객체에 대한 바운딩 박스 생성과 class 구분을 진행합니다. 이를 1 Stage Detection이라고 지칭하며 Yolo는 1 Stage Detection의 대표적인 탐지 모델입니다.
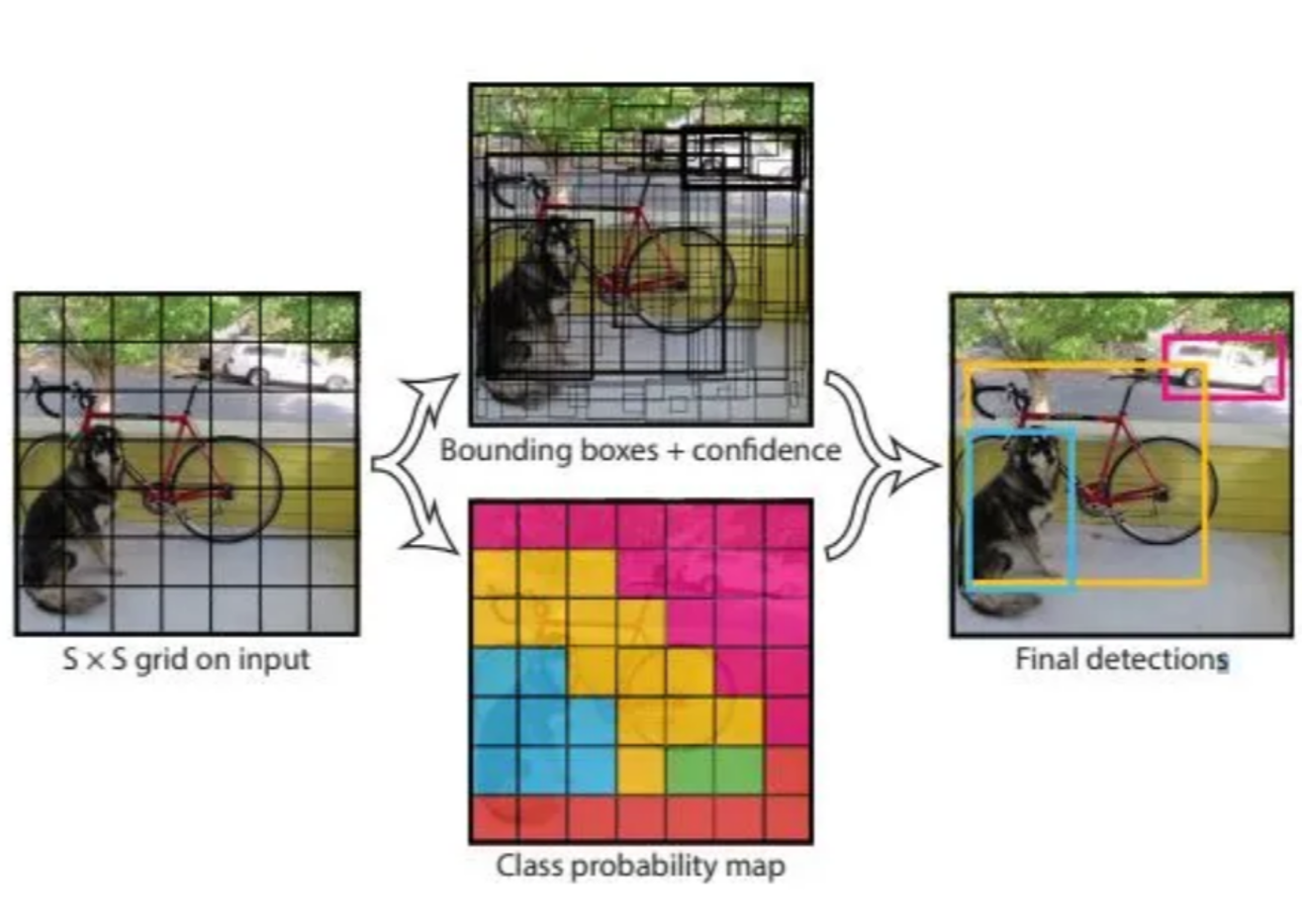
위의 그림은 yolo1 논문에서 제공하는 예시입니다.
yolo1 모델에 input된 이미지는 SxS grid cell로 나뉘어집니다.
나뉘어진 각 grid cell은 2개의 bounding box 즉 경계상자를 예측합니다.
또한 Class 예측합니다.
이 두 과정을 한번의 단계에서 예측하고 최종적으로 Final Detection이 도출됩니다.
Grid Cell
grid cell에 대하여 조금 면밀하게 살펴보겠습니다.
앞서 언급했던 것 처럼 각 grid cell은 2개의 bounding box를 예측합니다. 또한 박스에 대한 x좌표, y좌표, width(너비), height(높이), confidence score를 예측합니다.
이때 confidence score는 Pc * IOU로 bounding box에 객체가 실제로 존재할 확률 값입니다.
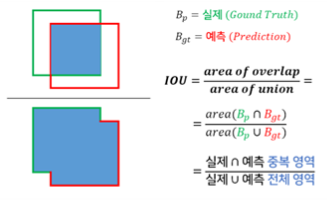
IOU
IOU는 두 개의 바운딩 박스가 겹치는 정도를 나타내는 지표로, 객체 검출 및 세그멘테이션 분야에서 자주 사용됩니다. 두 영역의 겹치는 정도를 수치화하여, 검출된 객체가 얼마나 정확하게 예측되었는지를 평가하는데 중요한 역할을 합니다.
Yolo에서 실제 bounding box와 각 grid cell에서 예측한 box의 교집합에 따라 점수를 부여하는 것입니다. 이를 수식으로 표현했을 때에 아래와 같습니다.
점수는 0~1의 사이에 위치하며 1에 가까울 수록 실제 bounding box와 유사하다는 것을 알 수 있습니다.
각 grid cell마다 2개의 bounding box가 예측된다면 총 47*2인 94개의 박스 중에서 어떤 박스를 선택하여 남기게 되는지 알아보도록 하겠습니다.
NMS(non-max supperession)
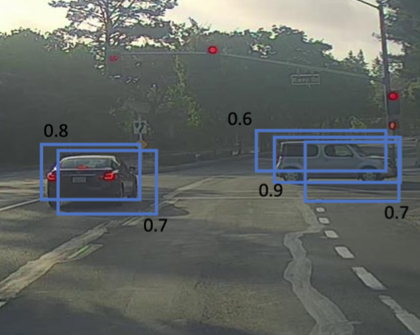
nms는 객체 검출(Object Detection) 알고리즘에서 중요한 후처리 기법입니다. NMS는 동일한 객체를 여러 번 검출하는 문제를 해결하기 위해 사용됩니다. 이 기법은 주로 YOLO, SSD, Faster R-CNN과 같은 객체 검출 모델에서 사용됩니다.
nms가 각 객체에 해당하는 바운딩 박스를 선택하는 과정에 대하여 아래와 같이 설명할 수 있습니다.
-
Grid Cell마다 생성된 2개의 Bounding box중 Pc 즉 Predict Confidence score가 0.6 미만인 박스를 제거합니다.
-
남아있는 박스들 중에서 Predict Confidence Score가 가장 큰 값을 선택하여 기준이 되는 box로 설정합니다.
-
선택한 박스와 IoU지수가 0.5 이상인 bounding box들을 모두 제거합니다.
-
최종적으로 한 객체에 대한 bounding box가 선택됩니다.
-
다른 객체에 대하여 같은 과정을 반복합니다.(다음으로 Pc가 높은 박스를 선택)
Network Construction
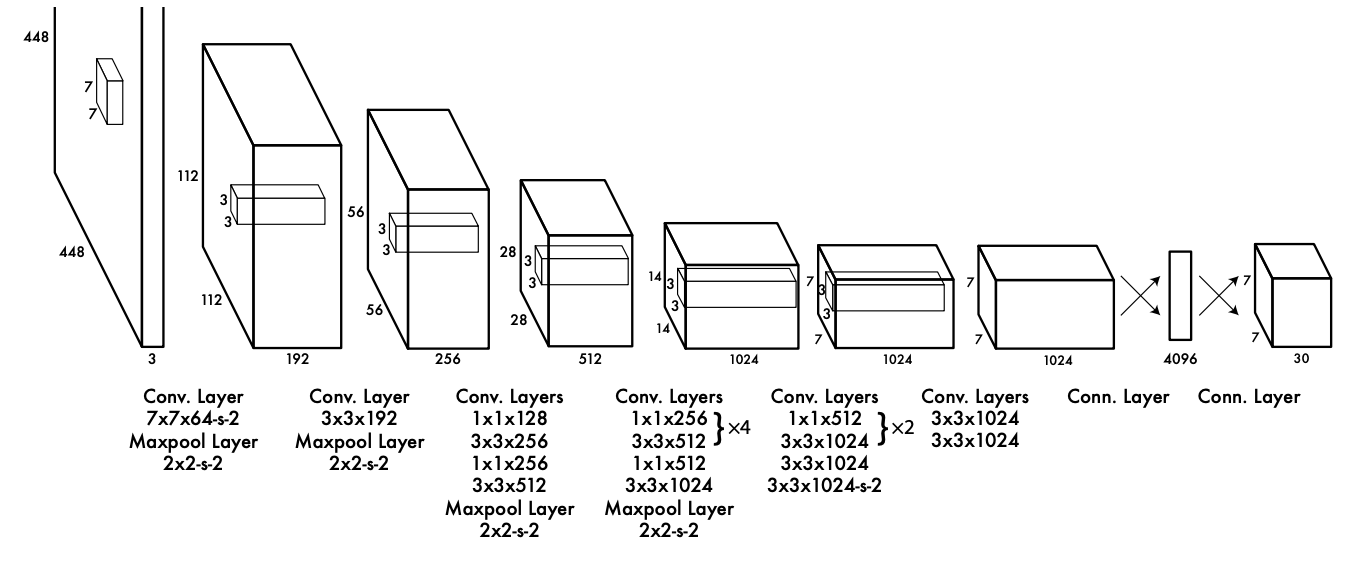
Yolo 모델의 아키텍쳐는 다음 사진과 같습니다.
-
yolo는 224x224x3의 이미지를 해상도를 증폭시키기 위하여 448x448x3의 이미지로 변환하여 input해줍니다.
-
yolo는 24개의 convolution layer와 2개의 fully connected layer로 구성되어있습니다.
-
convolution layer나 maxpooling layer에 -s-2는 stride=2와 같은 의미이며, 해당 layer를 통과할 때 input된 이미지의 사이즈가 1/2 사이즈로 줄어듭니다.
-
3x3 convolution layer는 일반적으로 이미지의 특성을 증폭 시킬 때에 그 성능이 좋은 것으로 알려져 있습니다. 다만 layer가 깊어질수록 연산량이 증가되어 모델의 성능이 떨어질 수 있습니다. 이에따라 1x1 convolution layer를 혼합하여 사용해줍니다. 이는 하나의 픽셀 단위로 특징화합니다. 따라서 직전 layer로 인하여 증폭되어 있는 특성을 줄여주는 역할을 하며 그 연산량을 줄여줄 수 있습니다. 이를 혼합하여 사용했을 때 모델의 성능이 향상되는 것을 확인할 수 있습니다.
-
모든 layer의 activation 함수로는 Leaky Relu를 사용하여줍니다. Leaky Relu를 사용하여 음수의 값을 살려줍니다. 다만 마지막 layer의 activation 함수는 Linear입니다.
-
Fully Connected Layer는 인공신경망에서 모든 입력 노드가 출력 노드에 연결되는 층을 의미합니다. 이미지 분류나 회귀 문제에서 자주 사용되며, 주로 네트워크의 마지막 단계에서 사용되어 특징 맵을 특정한 차원으로 변환하여 결과를 출력합니다.
-
yolo1 모델의 아키텍쳐 또한 Fully Connected Layer를 마지막 layer에 활용해주며 특정한 차원으로 변환해줍니다. 최종적으로 출력되는 차원은 아래와 같습니다.
왜 아웃풋이 7x7x30일까?
S x S x (B x 5 + C)
S x S 는 grid cell의 개수입니다. 즉 S x S는 7 x 7이 됩니다.
B는 grid cell이 예측할 바운딩 박스의 개수입니다. 즉 2가 됩니다.
5는 grid cell이 예측할 x좌표, y좌표, 너비, 높이, confidence score입니다.
C는 class의 총 개수입니다. yolo1에 훈련된 모델의 총 class의 개수는 20개로 C의 값은 20이 됩니다.
따라서 7 x 7 x 30 의 shape의 피처 맵을 추출해줍니다.
Loss Function

- 배경의 영역이 실제 객체의 영역보다 크기 때문에 0이 1을 압도하는 오류가 있습니다, 이를 해결하기 위하여 람다 상수를 부여합니다. 객체를 포함하는 셀에 상수를 곱해주고 논문에서는 그 값이 5입니다.
- i번째 grid cell에서 생성한 j번째 bounding box에 객체가 존재할 때에 1을 부여합니다.
-
grid cell의 개수입니다. 즉 7x7 = 49 가 됩니다.
-
B는 Bounding box를 의미합니다.
- 임의의 상수입니다. 배경이 실제 객체의 영역을 압도하는 것을 방지하기 위하여 0.5의 상수를 객체가 존재하지 않을 때의 값 즉 배경값에 곱해줍니다.
- i번째 grid cell에서 생성한 j번째 bounding box에 객체가 실제하지 않을 때 1을 부여합니다.
위의 값들을 종합하였을 때에
-
객체의 x, y좌표의 로스합 객체의 너비, 높이의 로스 합은 위치 손실이 됩니다.
-
객체의 객체가 바운딩 박스 안에 존재할 신뢰도 값 로스, 객체가 바운딩 박스 안에 존재하지 않을 신뢰도 값 로스의 합은 신뢰도 손실이 됩니다.
-
그리드 셀에 포함되는 객체가 20개의 클래스 중에 원 클래스에 잘 부합하는지 확인하는 클래스 확률 로스의 합은 분류 로스가 됩니다.
-
세 가지 로스를 모두 합했을 때에 yolo1에서 사용하는 전역적인 Loss Function이 계산됩니다.
Compare with Others
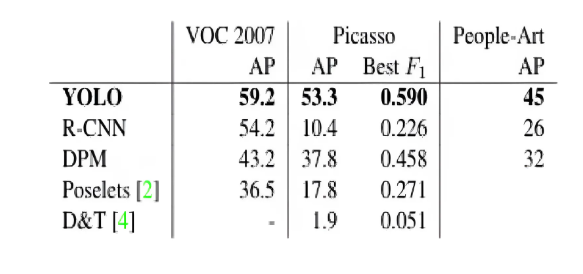
yolo는 Pascal Voc 2007 데이터를 기반으로 하여 훈련된 모델입니다.
해당 데이터를 통하여 yolo와 다른 모델들의 성능을 비교했을때 타 모델 또한 그 AP가 yolo와 비슷한 경향을 보입니다.
다만 Pascal Voc 2007데이터가 아닌 Picasso 데이터 혹은 People-Art 데이터를 사용했을 때에 yolo를 제외한 다른 모델들의 AP가 현저히 낮아지는 것을 확인할 수 있습니다.
Picasso와 같이 객체에 왜곡이 있는 데이터를 통해 성능을 평가할 때에 yolo는 이미지를 전역적으로 탐지하기 때문에 왜곡된 객체에 대한 탐지에도 적합하며, 부분적으로 탐지하는 R-CNN과 같은 모델에 비해 성능이 저하되지 않는 것을 확인할 수 있습니다.
Yolo1 limitation
Yolo1의 한계점은 다음과 같습니다.
-
경계 상자의 예측에 공간적 제약을 가한다.
-
Grid cell 당 하나의 클래스만 예측할 수 있다.
-
그룹으로 나타나는 작은 객체 탐지에 어려움을 겪는다.
Reference
