1. 서론
생략
2. Better
Fast R-CNN과 비교했을 때, YOLO는 위치 예측에서 상당한 오류를 범하며 지역 제안 기반 방법들에 비해 상대적으로 낮은 재현율을 보입니다. 따라서 재현율과 위치 정확성을 개선하면서 분류 정확도를 유지한 것에 중점들 두었습니다.
개선에 사용된 기법들은 하기와 같습니다.
Batch Normalization
Batch Normalization에 대한 설명은 아래 링크를 참고하세요.
Batch Normalization vs Layer Normalization
고해상도 분류기
모든 최첨단 탐지 방법은 ImageNet으로 사전 학습된 분류기를 사용합니다. 대부분의 분류기들은 256x256보다 작은 입력 이미지로 작동합니다. 원래 Yolo는 224x224 분류 네트워크를 훈련하고 해상도를 448로 증가시켜 훈련했습니다. 다만 Yolov2는 먼저 분류 네트워크를 전체 448x448 해상도에서 ImageNet으로 10 epoch 동안 미세 조정합니다. 이를 통해 네트워크가 더 높은 해상도 입력에 적합하도록 필터를 조정할 수 있는 시간을 줍니다. 그런 다음 탐지 작업을 위해 네트워크를 미세 조정합니다.
앵커 박스를 사용한 합성곱
YOLO는 합성곱 피처 추출기의 최상단에 fully connected layer를 사용하여 바운딩 박스의 좌표를 예측했습니다. 반면 Faster R-CNN은 직접 좌표를 예측하는 대신, 미리 선택된 앵커 박스를 사용하여 예측합니다. Faster R-CNN의 RPN(Region Proposal Network)은 Conv layer만 사용하여 앵커박스의 오프셋과 신뢰도를 예측합니다. 좌표 대신 오프셋을 예측하는 것은 문제를 단순화하고 네트워크가 학습하기 쉽게 만듭니다.
YOLO의 Fully connected layer를 제거하고 앵커박스를 사용하여 경계상자를 예측합니다. 먼저 출력 해상도를 높이기 위해 한 개의 풀링층을 제거합니다. 또한 입력 이미지를 448x448에서 416x416으로 축소합니다.
이는 피쳐 맵에서 중앙 셀이 하나만 있는 홀수 개의 위치를 가지게 하기 위함입니다. 이렇게 했을 때 좋은 이유로서 큰 객체들은 중앙에 위치하는 경향이 있는데 객체의 중심은 4개의 셀로 예측하는 것 보단 하나의 셀로 예측할 때에 성능이 더 좋습니다. 중심에 위치하는 셀이 여러개일 경우 셀들의 경쟁이 있을 수 있습니다.
Yolo의 Conv layer는 이미지를 32배 축소합니다. 따라서 416의 이미지를 사용하면 13x13의 출력 피처맵을 얻을 수 있습니다.
앵커박스를 사용하여 각 앵커박스에 대해 기존의 YOLOv1과 마찬가지로 객체가 존재할 가능성과 박스 안에 객체의 Class 확률을 예측합니다.
- 앵커박스를 사용하게 되면 정확도가 다소 감소합니다.
- Yolov1는 이미지당 98개의 상자만 예측하지만 앵커박스를 사용한 Yolov2는 1000개 이상의 상자를 예측합니다.
차원 클러스터
Yolov2에서 앵커박스를 사용할 때 발생되는 문제점 두 가지가 있습니다.
- 박스의 차원이 수작업으로 선택된다.
이를 해결하기 위하여 훈련 셋의 경계 상자에 대해 k-평균 클러스트링을 진행하여 더 나은 앵커박스를 자동으로 찾게 했습니다.유클리드 거리를 사용할 시에 큰 상자가 더 많은 오류를 발생시킵니다. 박스의 크기와 관계 없이 더 나은 iou 점수를 제공하는 앵커박스를 위하여 거리를 다음과 같이 정의합니다.
- d(box,centroid) = 1 - IOU(box,centroid)
이는 1 - 박스의 iou로써 예측한 박스와 실제 박스의 중심점에 대한 loss 값입니다.
k-클러스트링으로 앵커박스 생성하는 과정에 대해서 조금 더 살펴보겠습니다.
- 훈련 데이터의 객체의 실제 Bounding box를 기반으로 k개의 앵커박스를 생성합니다.
- 이때 d = 1 - iou를 사용하여 적합한 앵커박스의 비율과 크기를 자동으로 찾아 생성후 고정합니다. 즉 이미지마다 고정된 앵커박스는 k개 입니다.
유클리드 거리란?
유클리드 거리(Euclidean distance)는 두 점 사이의 "직선 거리"를 측정하는 방법입니다. 이는 기하학에서 가장 일반적인 거리 측정 방법으로, 우리가 일상에서 생각하는 두 지점 간의 거리와 비슷합니다.
다양한 k 값에 대해 k-평균을 실행하고 가장 가까운 중심점과의 평균 IOU를 계산합니다. k=5를 사용하여 모델 복잡성과 높은 재현율 사이의 좋은 균형을 얻을 수 있습니다.
k 평균 클러스트링 작업으로 선택된 앵커 박스와 수작업으로 선택된 앵커 박스의 평균 IOU를 비교했을 때 5개의 클러스터 중심만 사용해도 9개의 앵커 박스와 비슷한 성능을 보여줍니다. 그 성능에 대한 예시는 아래 그림을 참고할 수 있습니다.
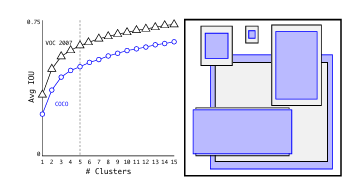
<그림2> VOC 및 COCO에서 박스 크기 클러스트링
그림에서 확인할 수 있듯이 5개에서 적정 성능을 보이는 것을 확인할 수 있습니다.
직접 위치 예측
앵커박스를 사용할 때 나타날 수 있는 두 번째 문제
- 모델의 불안정성
불안정성은 (x,y) 위치 예측에서 기인합니다. RPN에서는 네트워크가 tx와 ty 값을 예측하고 (x,y) 중심 좌표는 다음과 같이 계산됩니다.
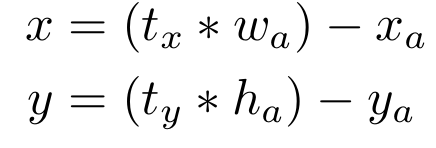
예를 들어
- tx = 1이라는 예측은 상자를 앵커박스의 너비만큼 오른 쪽으로 이동시킵니다.
- tx = -1이라는 예측은 상자를 앵커박스의 너비만큼 왼쪽으로 이동시킵니다.
YOLO의 접근방식은 grid cell의 위치에 상대적인 좌표를 예측합니다. 이는 실제 값이 0과 1사이에 있도록 제한합니다. 이 제한을 위해 사용되는 활성화는 sigmoid입니다.
네트워크의 출력 feature map의 각 셀에서 5개의 경계상자를 예측합니다. 각 경계 상자에 대해 네트워크는 tx, ty, tw, th, to의 5가지 좌표를 예측합니다.
- to에서 o는 objectness score로 0과 1사이의 값을 가집니다. 이는 그리드셀에 객체가 존재할 확률을 의미합니다.
만일 cell이 image 좌상단에서 (cx,cy) 만큼 오프셋되어 있고, 경계 상자의 너비와 높이가 pw, ph라면 예측은 다음과 같이 계산됩니다.
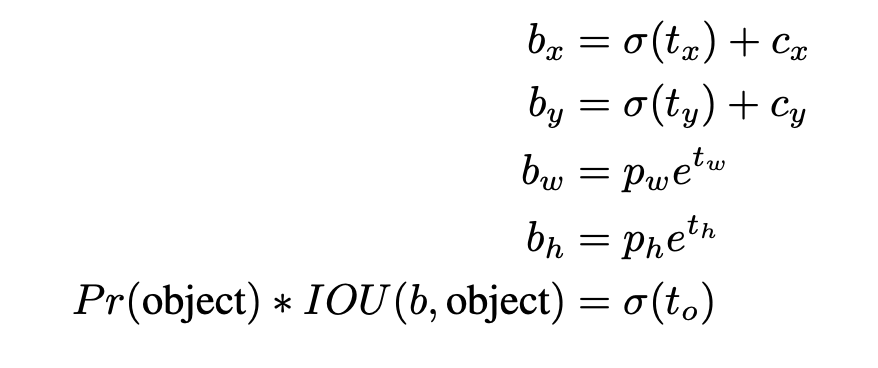
- bx는 네트워크가 예측한 tx값을 sigmoid 함수로 0과 1사이로 스케일링한 값에 그리드셀에서 오프셋 거리 cx를 더해준 값으로 boundig box의 중심 x좌표가 됩니다.
- by는 네트워크가 예측한 ty값을 sigmoid 함수로 0과 1사이 값으로 스케일링된 값에 그리드셀에서 오프셋 거리 cy를 더해준 값으로 bounding box의 중심 y좌표가 됩니다.
- bw는 기존 앵커박스의 너비, Pw와 상수 e에 tw승 해준 값을 곱해준 값으로 bounding box의 너비 값이 됩니다. 이때 tw는 음수가 될 수 있기에 e의 지수로 사용해줍니다. 따라서 다음 값은 음수가 될 수 없습니다.
- by는 기존 앵커박스의 높이, Py와 상수 e에 ty승 해준 값을 곱해준 값으로 bounding box의 높이 값이 됩니다.
위의 수식은 아래의 이미지를 통해 확인할 수 있습니다.
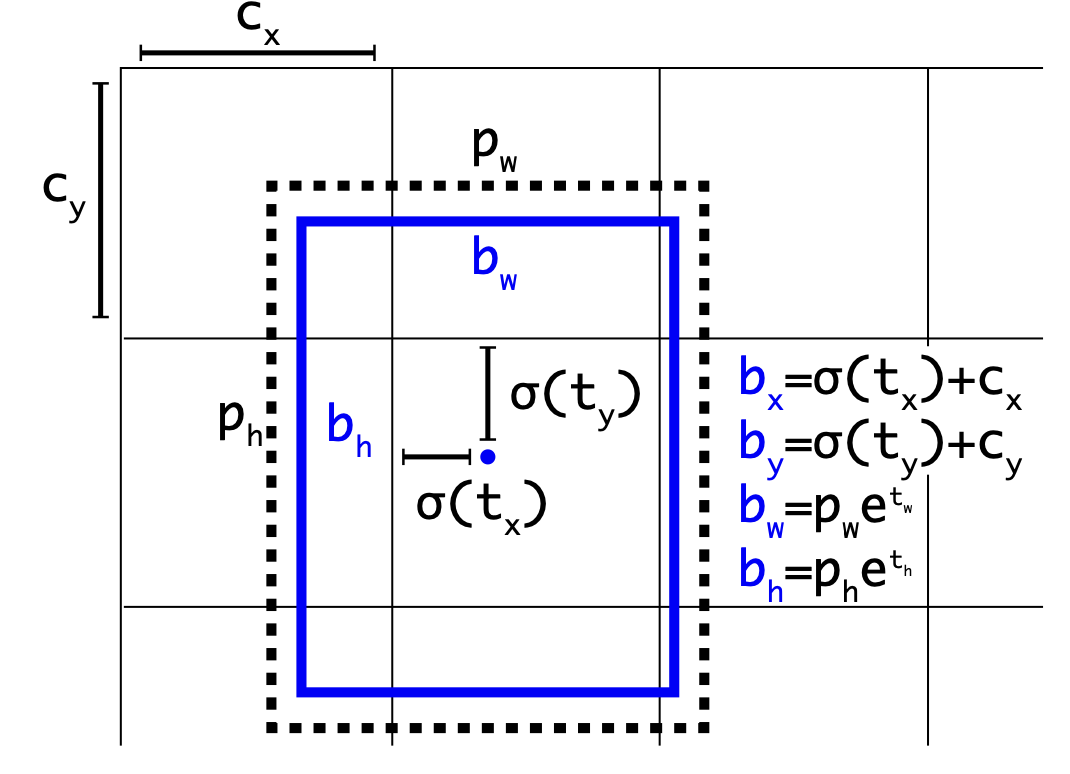
<그림3 : 차원 기준 및 위치 예측을 사용한 경계상자>
미세한 특징들(Fine-Grained Features)
Yolov2는 13x13 사이즈의 feature map에서의 탐지를 예측합니다.
큰 객체에 대해서는 충분하지만 작은 객체를 더 잘 위치시키기 위해서는 더. 세밀한 특징이 필요할 수 있습니다.
Faster-RCNN과 SSD는 다양한 feature map에서 제안된 네트워크를 실행하여 여러 해상도의 결과를 얻습니다. 반면에 Yolov2는 다른 접근 방식을 사용하여 26x26 해상도 측의 특징을 가져오는 Passthrough layer를 추가합니다.
Passthrough layer
- 고해상도 특징을 저해상도 특징과 결합합니다.
- 공간적인 위치 대신 인접한 특징들을 서로 다른 채널로 쌓는 방식으로 작동합니다.
- 26x26x512의 feature map을 13x13x2048 featuremap으로 변환 즉 reshape 해줍니다. 이를 원래의 feature map 13x13과 연결하여 사용합니다.
Paththrough layer를 사용하는 이유
- 소실방지 : layer가 깊어짐에 따라 정보가 소실되는 문제가 발생할 수 있습니다. 입력과 출력을 동일하게 함으로써 소실을 방지합니다.
- 연산효율성 : 단순히 입력을 출력으로 전달하기에 연산복잡도가 낮아지고 효율성이 증가합니다.
다중스케일학습(Multi-Scale Training)
Yolov1은 448x448x3의 입력 해상도를 사용합니다. 그러나 Yolov2는 앵커박스를 추가해주면서 해상도를 416x416으로 변경합니다. 따라서 fully connected layer를 사용하지 않아 실시간으로 크기를 조정할 수 있습니다.
Yolov2는 다양한 크기의 이미지에서 견고하게 작동할 수 있기를 원했고 이를 모델에 학습시켰습니다.
- 입력이미지 크기를 고정하는 대신, 매 10번째 batch마다 네트워크는 무작위로 새로운 이미지 차원을 선택합니다.
- 모델은 32배 축소시키므로 32의 배수 중에서 이미지 차원을 선택합니다.
- 그 예로 320, 352, 608 등이 있습니다.
- 320x320이 가장 작은 옵션이고 가장 큰 옵션으로 608x608이 됩니다.
이 방법은 네트워크가 다양한 입력 차원에서도 잘 예측할 수 있도록 합니다. 즉 동일한 네트워크가 다른 해상도에서 탐지를 예측할 수 있는 것을 의미합니다.
- 모델의 크기의 조정이 없어 속도는 빠른속도를 유지합니다. 다만 input되는 image size를 다중으로 줄 수 있어 정확도를 높일 수 있습니다.
추가실험
Yolov2에 대하여 타 모델과 비교했을때 나타나는 성능에 대한 비교입니다.
전반적으로 Yolov2는 향상된 성능을 나타냅니다.
이 부분은 생략하겠습니다.
3. Faster
VGG-16
Yolov2는 속도의 성능을 위해 모델을 빠르게 설계했습니다.
대부분의 탐지 Framework는 VGG-16을 기본 feature 추출기로 사용합니다.
하지만 VGG-16은 정확한 분류 네트워크이지만 꽤나 복잡합니다.
VGG-16의 Conv layer는 224x224 해상도에서 단일 이미지를 처리하는데 306억개의 부동 소수점 연산이 필요합니다.
Yolo의 Framework는 GoogleNet 아키텍쳐를 기반으로하여 맞춤형 네트워크를 사용합니다.
이는 VGG-16보다 빠르며, 단일 전방 전달에서 85억 2000만개의 연산만을 사용합니다. 그러나 정확도는 VGG-16보다 다소 떨어집니다.
224x224 해상도에서 단일 크롭으로 상위 5개의 이미지에 평가했을 때 대해 정확도는 Yolo는 88%, VGG-16은 90.0%인 것을 확인할 수 있습니다.
Darknet-19
논문은 Yolov2의 기본으로 사용할 새로운 분류 모델을 제안합니다.
- VGG 모델과 유사하게 대부분의 conv layer에 3x3 filter를 사용합니다.
- 각 pooling 단계 후 채널 수를 두배로 늘립니다.
- 1x1 filter를 사용하여 3x3 conv layer 사이의 feature 표현을 압축합니다.
- batch normalization을 사용하여 학습을 안정화, 수렴 속도를 높이며 모델 정규화합니다.
- 19개의 conv layer와 5개의 Maxpooling layer로 구성됩니다.
Image 처리에 55억 8000만 개의 연산이 필요하지만 상위 1개에 대하여 acc 72.9%, 상위 5개에 대해 acc 91.2%를 달성합니다.
분류를 위한 학습
표준 ImageNet 1000개의 클래스 분류 데이터셋에서 네트워크를 160 epochs 동안 학습시키며 SGD(확률 경사 하강법)을 사용합니다.
learning rate는 0.1, 지수 감소율은 4의 지수, 가중치 감소는 0.00005, momentum은 0.9가 됩니다.
학습 중에 랜덤크롭, 회전, 색조, 채도, 노출 변화 등 표준 데이터 증강 기법을 사용합니다.
224x224 해상도 이미지로 초기 학습을 마친 후, 더 큰 해상도인 448 해상도에서 네트워크를 미세조정합니다. 미세 조정을 위한 매개변수는 아래와 같습니다.
- epochs = 10, learning rate = 0.001
224 해상도에서 448 해상도로 미세 조정하여 평가 했을 때
상위 1개에 대한 acc 76.5%, 상위 5개에 대한 acc 93.5%를 달성합니다.
탐지를 위한 학습
위 Network를 탐지 작업을 위해 수정합니다.
- 마지막 Conv layer를 제거하고 대신 1024개의 filter를 갖는 세개의 3x3 conv layer를 추가합니다. 즉 3x3x1024
- 마지막으로 탐지에 필요한 출력 개수만큼 출력을 가진 1x1 conv layer를 추가합니다.
VOC 데이터셋의 경우 우리는 각 상자에 대해 5개의 좌표와 20개의 class를 예측하므로 앵커박스의 생성 수 만큼 곱하여 총 125개의 필터가 필요합니다. - 모델이 세밀한 feature를 사용할 수 있도록 3x3x512 층에서 두 번째 마지막 합성곱 층으로 passthrough layer를 추가합니다.
- 위 모델에 대한 learning rate = 0.001, epochs = 160이며
60 epoch와 90 epoch에서 learning rate를 1/10로 감소시킵니다.
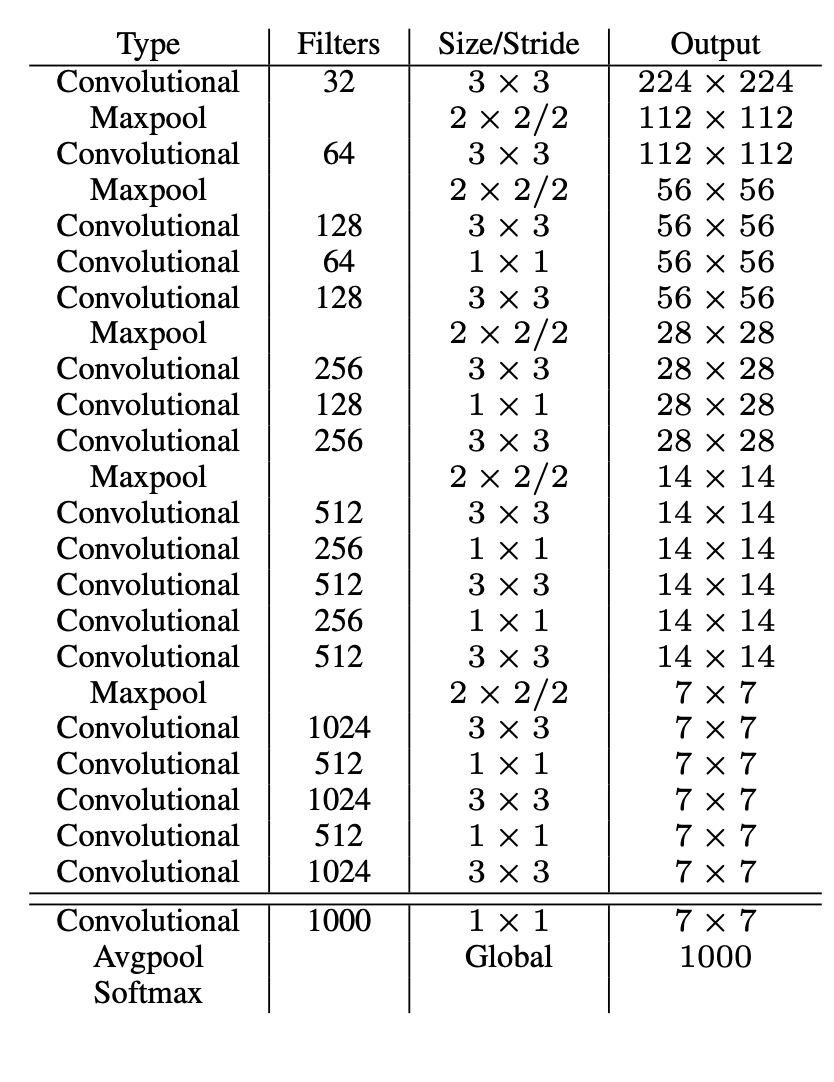
<표 6 : Darknet-19>
4. Stronger
분류 데이터와 탐지 데이터를 함께 학습하는 메커니즘을 제안합니다.
이 방법은 탐지에 대해 라벨링된 이미지를 사용하여 경계 상자 좌표 예측과 객체성과 같은 탐지 관련 정보를 학습하는 동시에, 공통 객체를 분류하는 방법을 학습합니다. 또한 클래스 라벨만 있는 이미지를 사용하여 탐지할 수 있는 범주의 수를 확장합니다.
탐지를 위한 라벨링된 이미지를 볼 때에는 Yolov2 손실 함수 전체를 기반으로 역전파를 수행합니다.
반면 분류 이미지를 볼 때는 네트워크 구조의 분류 관련 부분에서만 손실을 역전파 합니다.
탐지 데이터 셋은 '개'와 '보트'와 같은 공통 객체 및 일반적인 라벨만 포함합니다.
분류 데이터셋은 훨씬 더 넓고 깊은 라벨 범위를 가지고 있습니다.
예를 들어, ImageNet에는 '노퍽 테리어', '요크셔 테리어', '베들링턴 테리어'
과 같은 100종 이상의 개 품종이 있습니다. 두 데이터셋을 함께 학습하려면 이러한 라벨을 일관된 방식으로 병합해야 합니다.
대부분의 분류 방식은 softmax를 활용하여 최종 확률 분포를 계산합니다. 다만 softmax를 사용하기 위해 class들이 상호 배타적이어야하는데 위의 예시처럼 탐지 데이터셋과 분류 데이터셋이 연관성을 가지고 있어 ImageNet과 COCO 같은 데이터 셋을 결합하는 것에 문제가 발생될 수 있습니다.
계층적 분류
ImageNet 라벨은 개념과 그들 간의 관계를 구조화한 언어 데이터 베이스인 WordNet에서 가져옵니다. WordNet에서 '노퍽 테리어'와 '요크셔 테리어'가 둘 다 하위개념이며 '테리어'는 '사냥개', '사냥개'는 '개', '개'는 '개과 동물'입니다. 대부분의 분류 접근 방식은 라벨의 평면적인 구조를 가정하지만, 데이터셋을 결합하려면 바로 이러한 구조가 필요합니다.
이를 위해 계층적 트리를 구축하는데 ImageNet의 시각적 명사를 살펴보고, 그것들이 WordNet 그래프에서 '물리적 객체'라는 루트 노드까지 가는 경로를 조사합니다. 많은 동의어 집합은 그래프를 통해 하나의 경로만 가지고 있기 때문에 이 경로들을 모두 트리에 추가합니다. 그런 다음 남아있는 개념들을 반복적으로 검사하여 트리에 최소한의 변화를 주는 경로를 추가합니다. 예를 들어 개념이 두 개의 경로를 가지고 있고, 하나의 경로가 트리에 3개의 엣지를 추가하고 다른 경로가 1개의 엣지를 추가할 경우, 우리는 더 짧은 경로를 선택합니다.
최종 결과는 WordTree로 시각적 개념의 계층적 모델입니다.
WordTree를 사용하여 분류를 수행할 때, 우리는 해당 동의어 집합의 하위 개념에 대한 조건부 확률을 각 노드에서 예측합니다.
- 동의어 집합 하위 개념에 대한 조건부 확률 예측

예를 들어, '테리어' 노드에서 우리는 '테리어'에 해당하는 하위 개념들의 확률을 예측합니다.
- 특정 노드에 대한 절대확률 계산

트리를 특정 루트의 노드까지 따라가면서 조건부 확률을 곱해줍니다.
이 접근 방식을 검증하기 위해, 1000개의 클래스 ImageNet을 사용하여 구축한 WordTree에서 Darknet-19 모델을 학습시켰습니다.
WordTree1K를 구축하기 위해 중간 노드를 추가하여 라벨을 1369으로 확장합니다. 이를 통해 학습 중에 실제 라벨을 상위 노드로 전파하여 만약 이미지가 노퍽테리어로 라벨링 되면 개와 포유로로도 라벨링 되록 합니다.
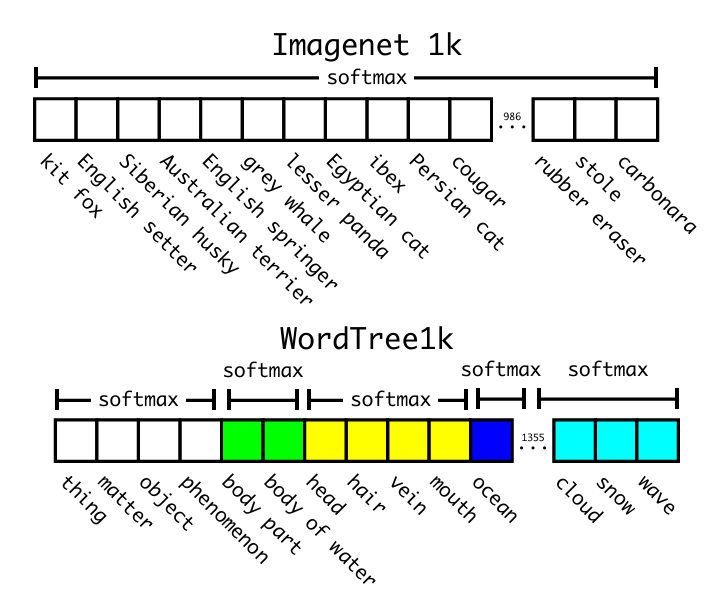
<그림 5 : ImageNet과 WordTree에서의 예측>
대부분의 ImageNet의 모델은 하나의 소프트 맥스를 사용하여 확률 분포를 예측합니다. 그러나 WordTree를 사용하면 여러 소프트맥스 연산을 동일한 하위 개념들에 대해 수행합니다.
계층적 분류의 장점
-
새로운 객체나 알려지지 않은 객체 범주에 대해 성능이 점진적으로 저하됩니다.
-
예를들어 개의 사진을 보고 어떤 종류의 개인지 확신할 수 없더라도 개를 높은 확률로 예측하게 됩니다.
이 공식을 탐지에도 적용합니다. Pr(physical object)의 값을 계산합니다.
트리를 따라 내려가면서 각 분기 점에서 가장 높은 확률의 경로를 따라가며 일정 임계값에 도달하면 각 객체 클래스를 예측합니다.
데이터셋 결합과 WordTree
WordTree를 활용하여 여러 데이터셋을 합리적으로 결합할 수 있습니다.
데이터셋의 범주를 Tree 안의 동의어 집합에 매핑하면 됩니다.
공동 분류 및 탐지(Joint classification and detection)
WordTree를 사용하여 여러 데이터셋을 결합할 수 있습니다.
COCO 탐지 데이터셋과 전체 ImageNET에서 상위 9000개의 클래스를 사용하여 결합된 데이터셋을 생성합니다.
또한 평가를 위해 ImageNet 탐지 챌린지에서 포함되지 않은 클래스를 추가합니다.
이 데이터셋에 해당하는 WordTree에는 9418개의 클래스가 포함됩니다.
ImageNet은 큰 데이터셋이기 때문에, COCO를 과대 샘플링하여 ImageNet이 COCO보다 4:1 비율로 크도록 균형을 맞춥니다.
이 데이터셋을 활용하여 YOLO9000을 학습시킵니다.
Yolov2 아키텍쳐를 기반으로 하되, 출력 크기를 제한하기 위해 5개의 앵커박스가 아닌 3개의 앵커박스를 사용합니다. 네트워크가 탐지 이미지를 볼 때는 일반적인 방식으로 손실을 역전파 합니다. 분류 손실의 경우, 해당 라벨 수준 또는 그 이상에서만 손실을 역전파합니다.
라벨이 개 인경우 트리에서 그보다 하위에 있는 저먼 셰퍼드와 골든 리트리버와 같은 세부 예측에 대해서는 오류를 할당하지 않습니다.
이는 그 정보를 가지고 있지 않기 때문입니다.
분류 이미지를 볼 때는 분류 손실만 역전파 합니다. 이를 위해 해당 클래스에 대해 가장 높은 확률을 예측하는 경계 상자를 찾아 그 상자에서 예측된 트리에서만 손실을 계산합니다. 또한 예측된 상자가 실제 라벨과 3 이상 IOU로 겹친다고 가정하고 이 가정을 바탕으로 객체성 손실을 역전파 합니다.
Yolo9000을 ImageNet의 탐지 작업에서 평가했습니다. ImageNet의 탐지 작업은 COCO와 44개의 객체 범주를 공유하고 있습니다. 이는 Yolo9000이 테스트 이미지의 대다수에 대해 탐지 데이터를 본 적이 없고, 분류 데이터만 봤다는 것을 의미합니다.
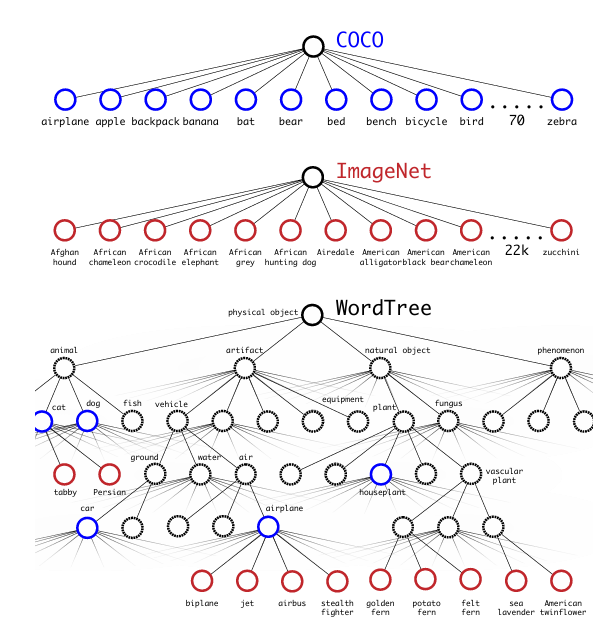
<그림6 : WordTree 계층 구조를 사용한 데이터셋 결합>
Yolov2의 한계
-
새로운 동물 종을 잘 학습하지만 의류나 장비와 같은 카테고리에서는 학습에 어려움을 겪는다는 점이 있습니다.
-
예를 들어 YOLO 9000은 '선글라스'나 '수영복'과 같은 카테고리에서 모델링을 하는 것에 어려움을 겪습니다.

< 표 7 : ImageNet에서 YOLO9000의 최고 및 최저 성능 클래스>
