1. Producer Ack, Batch, Page Cache, Flush
Producer는 메시지가 잘 도착했는지 어떻게 알까?
- Producer Ack를 통해 메시지 도착 여부 확인함
- acks 설정은 요청이 성공할 때를 정의하는데 사용되는 Producer에 설정하는 Parameter
- ack = 0 : ack가 필요하지 않음. 메시지 손실이 다소 있더라도 빨리 보낼 때 사용 (거의 안사용)
- ack = 1 (Default) : Leader가 메시지를 수신하면 ack 보냄. Leader가 Producer에게 ACK를 보낸 후 , Follower가 복제하기 전에 Leader에 장애가 발생하면 메시지 손실. (At most once 전송 보장)
- ack = -1, ack=all : 메시지가 Leader의 모든 Replica까지 Commit되면 ack 보냄. Leader를 잃어도 데이터가 살아남을 수 있도록 보장. 드러나 대기 시간이 더 길고 특정 실패 사례에서 반복되는 데이터 발생 가능성 있음 (At least once 전송 보장)
Producer Retry
- 재전송을 위한 Parameters
- retries : 메시지를 send하기 위해 재시도하는 횟수
- retry.backoff.ms : 재시도 사이에 추가되는 대기 시간
- request.timeout.ms : producer가 응답을 기다리는 최대 시간
- delivery.timeout.ms : send() 후 성공 또는 실패를 보고하는 시간의 상한 - retries를 조정하는 대신에 Delivery.timeout.ms 조정으로 재시도 동작을 제어
- ACK = 0 에서는 무의미
Producer Batch 처리
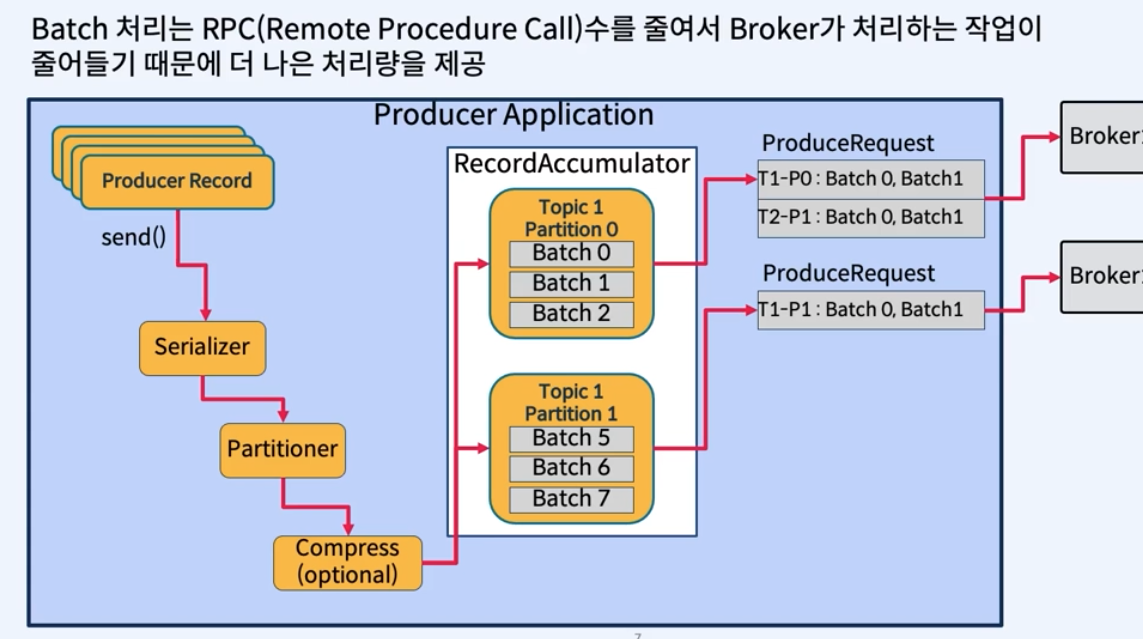
- 메시지를 모아서 한번에 전송
- Batch 처리는 RPC(Remote Procedure call) 수를 줄여서 Broker가 처리하는 작업이 줄어들기 때문에 더 나은 처리량을 제공.
- linger.ms(default : 0, 즉시 보냄) : 메시지가 함께 Batch 처리될 때까지 대기 시간
- batch.size(default : 16KB) : 보내기 전 Batch의 최대 크기
Producer Delivery Timeout
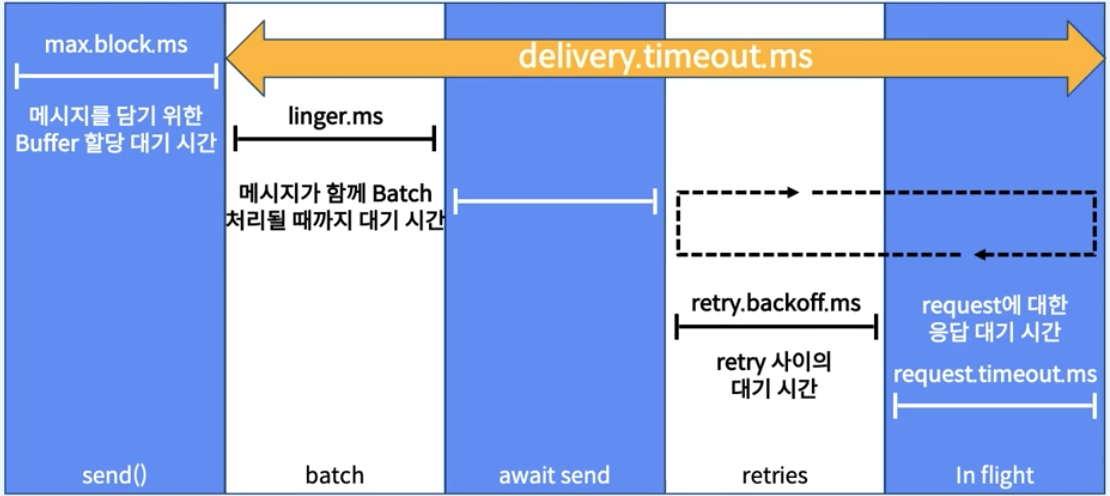
- send() 후 성공 또는 실패를 보고하는 시간의 상한
Message Send 순서 보장
- 진행중인 여러 요청을 재시도하면 순서가 변경될 수 있음.
- 메시지 순서를 보장하려면 Producer에서 enable.idempotence를 true로 설정.
- Multiple in-flight request 전송 (max.in.flight.requests.per.connection = 5 (default))
- Batch0가 실패했지만, Batch1은 성공하면 Batch1이 0보다 먼저 Commit Log에 추가되어 순서 달라짐.
- enable.idempotence를 사용하면, 하나의 Batch가 실패하면, 같은 Partition으로 들어오는 후속 Batch들도 함께 실패
Page Cache와 Flush

- 메시지는 Partition에 기록됨.
- Partition은 Log Segment file로 구성 (기본값 : 1GB마다 새로운 Segment 생성)
- 성능을 위해 Log Segment는 OS Page Cache에 기록됨.
- 로그 파일에 저장된 메시지의 데이터 형식은 Broker가 Producer로부터 수신한 것, 그리고 Consumer에게 보내는 것과 정확히 동일하므로, Zero-Copy가 가능
- Zero-Copy : 데이터가 User Space에 복사되지 않고, CPU 개입 없이 Page Cache와 Network Buffer 사이에서 직접 전송되는 것을 의미, 이것을 통해 Broker Heap 메모리를 절약하고 엄청난 처리량 제공 - Page Cache는 다음과 같은 경우 디스크로 Flush됨.
- Broker가 완전히 종료- OS Background flush Thread 실행
Flush 되기 전에 Broker 장애가 발생하면?
- 이를 위해 replication을 하는 것
- OS가 데이터를 디스크로 flush하기 전에 Broker의 시스템에 장애가 발생하면 해당 데이터는 손실됨.
- Partition이 Replication되어 있다면, Broker가 다시 온라인 상태가 되면 필요시 Leader Replica에서 데이터가 복구됨.
- Replication이 없다면, 데이터는 영구적으로 손실될 수 있음.
Kafka Flush 정책
- 마지막 Flush 이후의 메시지 수 또는 시간으로 Flush를 트리거하도록 설정 가능.
- Kafkasms 운영 체제의 플러쉬 기능을 효율적으로 사용하는 것을 선호하기 때문에 기본값 사용 권장
2. Replica Failure
ISR은 Leader가 관리
- 메시지가 ISR 리스트의 모든 Replica에서 수신되면 Commit된 것으로 간주
- Kafka Cluster의 Controller가 모니터링하는 Zookeeper의 ISR 리스트에 대한 변경 사항은 Leader가 유지
- N개의 Replica가 있는 경우 N-1개의 장애를 허용할 수 있음.
1. Follower가 실패하는 경우
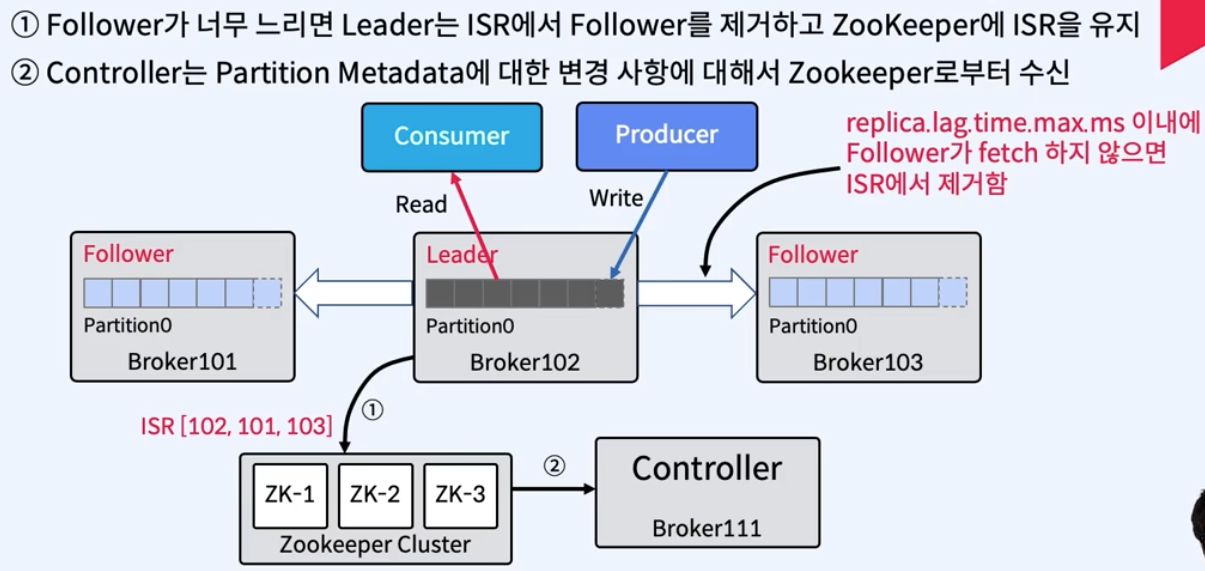
- Leader에 의해 ISR 리스트에서 삭제됨.
- Leader는 새로운 ISR을 사용하여 Commit함.
2. Leader가 실패하는 경우
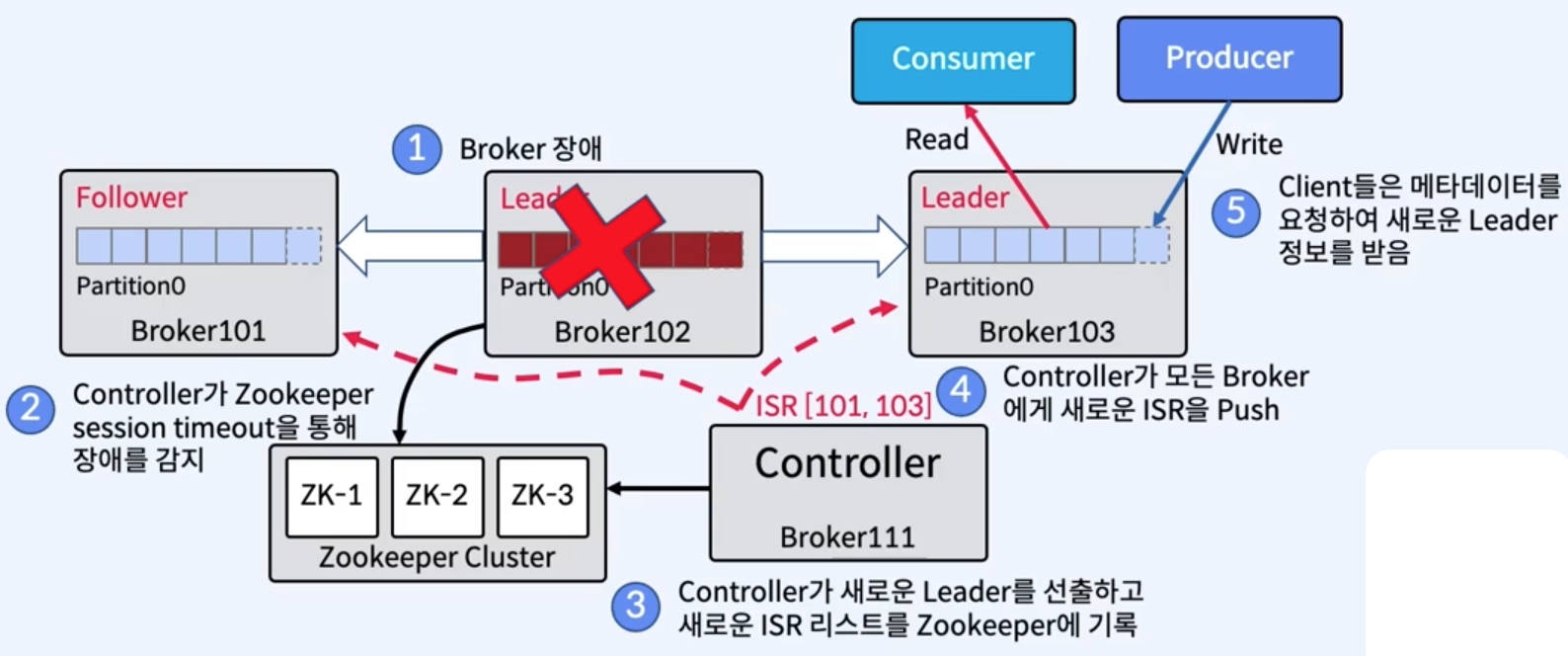
- Controller는 Follower 중에서 새로운 Leader를 선출
- Controller는 새 Leader의 ISR 정보를 먼저 ZooKeeper에 Push한 다음 로컬 캐싱을 위해 Broker에 Push 함.

안녕하세요 글 잘봤습니다! 혹시 해당 글의 도식화는 직접 그리신걸까요?