1. Replica Recovery
ack=all의 중요성
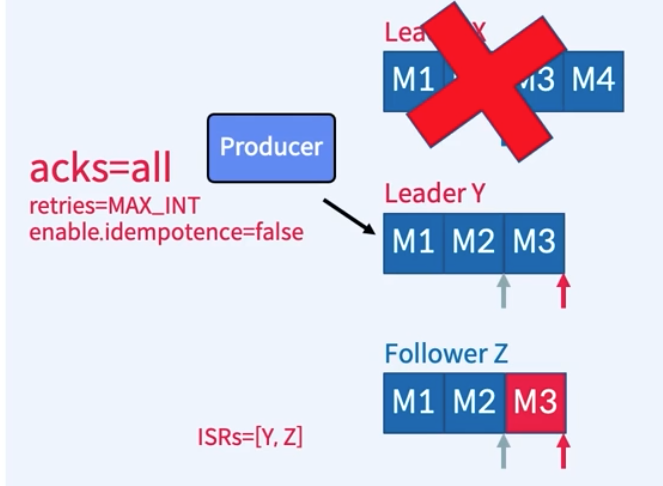
- acks = all인 상황
1. 3개의 Replica(X, Y, Z)로 구성된 하나의 Partition, Producer가 메시지 4개 (M1, M2, M3, M4)를 보낸 상황
2. 메시지 M1, M2가 ISR 리스트 전체에 복제되었고 Commit되었음.
3. Y는 M3를 복제했지만 Commit은 못한 상태, Z는 M2까지만 복제
4. Leader X가 장애가 나고 ISR 중에 Y가 Leader로 선출
5. Z는 M3를 Fetch, Y는 High Water Mark 진행, Z는 다시 fetch 수행 후 High Water Mark 수신하고 진행
6. Broker는 M3, M4에 대한 ack를 Producer에게 보내지 못함. Producer는 재시도에 의해 M3, M4 다시 보냄
7. Y에는 M3(중복), M4 수신, Z는 해당 데이터 다시 Fetch
8. (X가 복구되면) Zookeeper에 연결되어 Leader가 변경된 시점(M2)까지 데이터 두고 나머지 버림(M3, M4)
9. X는 Leader(Y)로부터 복제해옴. - acks = 1인 상황
1. 위의 5까지 동일한 상태
2. Broker는 M3, M4까지 ack를 Producer에게 보냄
3. Producer가 M4 송신을 재시도하지 않게 되므로, M4는 영원히 잃어버리는 결과 초래.가용성과 내구성 중 선택
- Topic 파라미터 - unclean.leader.election.enable
- ISR 리스트에 없는 Replica를 leader로 선출할 것인지에 대한 옵션 (default : false)- ISR 리스트에 Replica가 하나도 없으면 Leader 선출 안함
- ISR 리스트에 없는 Replica Leader로 선출함 - 데이터 유실
- Topic 파라미터 - min.insync.replicas
- 최소 요구되는 ISR 개수에 대한 옵션 (default:1)- ISR이 해당값보다 적은경우 Producer는 예외 수신
- Producer에서 acks=all과 함께 사용할때 더 강력한 보장 + min.insync.replicas = 2
- n개의 replica가 있고, 해당값이 2인경우 n-2개의 장애를 허용할 수 있음.
- 데이터 유실이 없게 하려면??
- replication.factor 3이상- acks = all
- min.insync.replicas 2이상
- 데이터 유실이 다소 있더라도 가용성을 높이려면?
- unclean.leader.election.enable = true
2. Consumer Rebalance
Partition Assignment
- Partition을 Consumer에게 할당할때
- 하나의 Partition은 지정된 Consumer Group 내의 하나의 Consumer만 사용- 동일한 Key를 가진 메시지는 동일한 Consumer 사용 (Partition 수를 변경하지 않는 한)\
- Consumer 파라미터 중에서 partition.assignment.strategy로 할당 방식 조정
- Consumer Group은 Group Coordinator라는 프로세스에 의해 관리됨.
Consumer Group Coordination
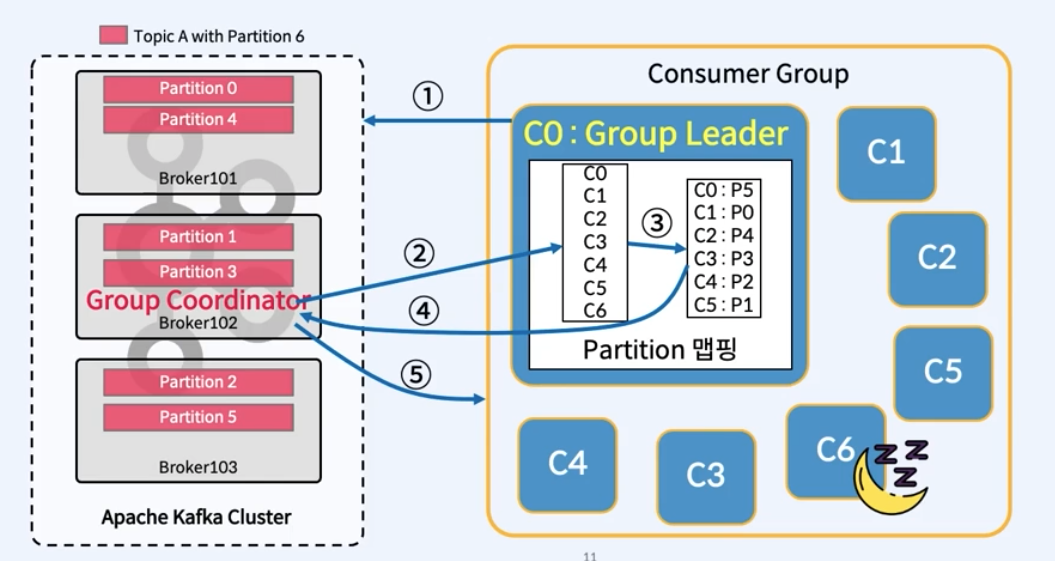
- Group Coordinator와 Group Leader가 상호작용
-
Consumer 등록 및 Group Coordinator 선택
- 각 Consumer는 group.id로 Kafka 클러스터에 자신을 등록
- kafka는 Consumer Group을 만들고 Consumer의 모든 offset은 __consumer_offsets Topic의 하나의 Partition에 저장
- 이 Partition의 Leader Broker는 Consumer Group의 Group Coordinator로 선택
- hash(group.id) % offsets.topic.num.partitions 수식을 사용하여 id가 저장될 __consumer_offsets의 Partitions를 결정
-
JoinGroup 요청 순서에 따라 Consumer 나열
- Group Coordinator는 Group의 Consumers 카탈로그를 생성하기 전에 Consumers의 JoinGroup 요청에 대해 group.initial.rebalance.delay.ms(기본값 3초)를 대기 Consumer들이 Consume할 최대 partition 수까지 JoinGroup 요청을 수신하는 순서대로 Consumers를 나열
-
Group Leader 결정 및 Partition 할당
- JoinGroup 요청을 보내는 최초 Consumer는 Group Leader로 지정되며, Group Coordinator로 부터 Consumer 목록을 받음
- Group Leader는 구성된 partition.assginment.strategy를 사용하여 각 Consumer에게 partition을 할당
-
"Consumer -> Partition" 매핑 정보를 Group Coordinator에게 전송
-
각 Consumer에게 할당된 Partition 정보를 보냄
왜 Group Coordinator(Broker)가 직접 Partition을 할당하지 않는가?
- Kafka의 한 가지 원칙은 가능한 한 많은 계산을 클라이언트에 수행하도록 하며, Broker 부담을 줄이는 것
- 많은 Consumer Group 과 Consumer가 있고 하나의 Broker가 있다고 하면 너무 부담이 큼..
Consumer Rebalanceing Trigger
- Rebalancing 이뤄지는 경우
- Consumer가 그룹에서 탈퇴- 신규 Consumer가 그룹에 합류
- Consumer가 Topic 구독을 변경
- Consumer Group은 Topic 메타데이터의 변경 사항을 인지
- Rebalancing 과정
1. Group Coordinator는 heartbeats 플래그를 사용하여 Consumer에게 Rebalance신호를 보냄- consumer가 모두 일시 중지하고 Offset을 Commit
- Consumer는 Consumer Group의 새로운 합류
- Partition 재할당
- Consumer는 새 Partition에서 다시 Consume 시작
- Consumer Rebalancing 시 Consumer들은 일시 중지함 --> 불필요한 Rebalancing은 피하자!!
과도한 Rebalancing 피하는 방법
- Consumer Group 멤버 고정
- Group의 각 Consumer에게 고유한 group.instance.id를 할당한다.
- Consumer는 LeaveGroupRequest를 사용하지 않아야 함.
- Rejoin은 알려진 group.instance.id에 대한 Rebalance를 trigger하지 않음.
- session.timeout.ms 튜닝
- heartbeat.interval.ms를 session.timeout.ms의 1/3fh tjfwjd
- group.min.session.timeout.ms와 group.max.session.timeout.ms의 사이값
- 장점 : Consumer가 더 많은 재가입 할수있는 시간 제공
- 단점 : Consumer 장애를 감지하는데 더 오래 걸림
- max.poll.interval.ms 튜닝
- Consumer에게 poll()한 데이터를 처리할 수 있는 충분한 시간 제공
- 너무 크면 안됨
