Trie란?
일반적인 이진트리에서 검색시에 O(logN)의 시간 복잡도를 가지게 된다.
하지만 이진트리 형태이더라도 문자열을 저장하고 있다면 문자열 최대 길이가 M일 때, O(M*logN)의 시간 복잡도를 가지게 된다.
이러한 문제를 해결하기 위해 O(M)의 시간복잡도를 가지는 Trie 자료구조를 사용하게 된다.
상세 구조
Trie는 문자열 전체를 하나의 노드에 저장하는게 아니라, 한 단어씩 노드에 저장하는 트리이다.
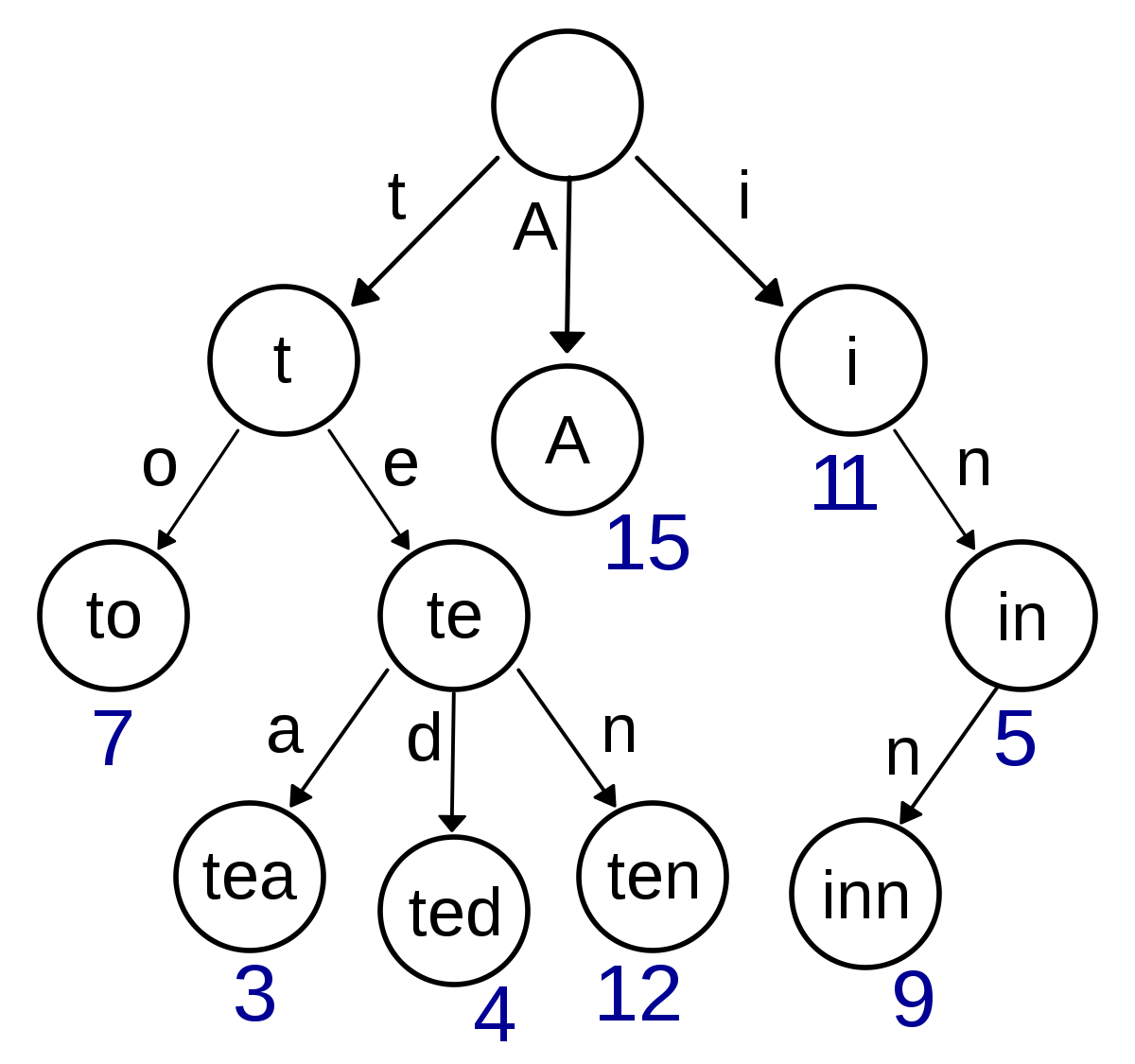
Trie의 루트 노드는 비어있고 첫번째 자식 노드부터 문자열의 첫 단어가 저장된다.
위 그림에 저장된 문자는 A, inn, to, tea, ted, ten이다.
Trie 자료구조는 문자열의 한단어씩 자식 노드와 비교하며 검색을 진행할 수 있다. (O(M))
Java 구현
Node 구현
Trie 자료구조의 각 노드를 의미하는 클래스
public static class Node {
Map<Character, Node> child = new HashMap<>();
Boolean isEnd = false;
}Trie 자료구조 클래스 구현
- insert(String input) : 자료구조에 특정 String을 넣어주는 메서드
- search(String input) : 특정 String이 Trie에 존재하는지 판별하는 메서드 (O(M), 문제 구현에 따라 달라짐)
public static class Trie {
Node root = new Node();
public void insert(String input) {
Node node = this.root;
//자식 노드 존재하면 해당 노드 리턴, 없으면 map에 해당 char을 key로 추가하여 새로운 노드 생성
for (int i = 0; i < input.length(); i++)
node = node.child.computeIfAbsent(input.charAt(i), k -> new Node());
node.isEnd = true;
}
public boolean search(String input) {
Node node = this.root;
//해당 char 노드 존재하면 이동, 없으면 false 리턴
for (int i = 0; i < input.length(); i++) {
node = node.child.getOrDefault(input.charAt(i), null);
if (Objects.isNull(node))
return false;
}
//마지막 글자가 노드에 도달하더라도 해당 문자열의 마지막 단어가 아닐 수 있음
//마지막인지 여부를 가지고 String 존재하는지 판별
return node.isEnd;
}
}