소개글
안녕하세요! 본론에 앞서 제가 프로젝트를 시작하게 된 배경을 말하고자 합니다.
저는 평소에 웹툰 보는 것을 좋아하는데요, 지금 보는 웹툰이랑 비슷한 스토리를 가진 다른 웹툰을 보고싶다는 생각이 많이 들더라고요!
다만 대부분의 웹툰 플랫폼에서는 장르별로만 웹툰을 나누고 비슷한 스토리로 묶어주는 기능은 없는 것 같더라고요..
그래서 직접 구현해보자는 생각을 갖고 프로젝트를 시작하게 됐습니다.
우선 웹툰으로 뭔가를 하기 위해서는 데이터가 필요하겠죠?
그래서 파이썬을 이용해 웹크롤링부터 시작해보려 합니다.
(각종 라이브러리를 설치하는 과정은 스킵하도록 하겠습니다)
구현
웹툰 페이지 열기
우선 Chrome Driver를 이용해서 네이버 웹툰 페이지를 열어봅시다.
Chrome Driver는 여기에 들어가서 자신의 크롬 버전과 맞는 버전을 다운 받고 원하는 곳에 저장하면 됩니다.
from selenium import webdriver
# 네이버 웹툰 페이지 열기
nw_url = 'https://comic.naver.com/webtoon/weekday'
chromedriver_url = '다운받은 폴더/chromedriver'
driver = webdriver.Chrome(chromedriver_url)
driver.get(nw_url)웹툰 개수 파악하기
페이지가 열어졌으면 일단 전체 웹툰 개수가 몇개인지 파악하기 위해 제목들을 가져와봅시다.
Chrome에서 마우스 오른쪽 클릭 후 "검사"를 누르면 html 코드가 나오는데, class 이름 등을 보고 원하는 요소를 가져오면 됩니다.
beautifulSoup를 이용하는 방법도 있고 driver를 이용하는 방법도 있는데, 쓰임새가 좀 다르긴 합니다.
일단은 driver를 사용해보겠습니다.
예를 들면, 지금같은 경우는 제목들을 가져오고 싶은데 코드를 확인해보면 제목은 class가 title인 구문 안에 있습니다.
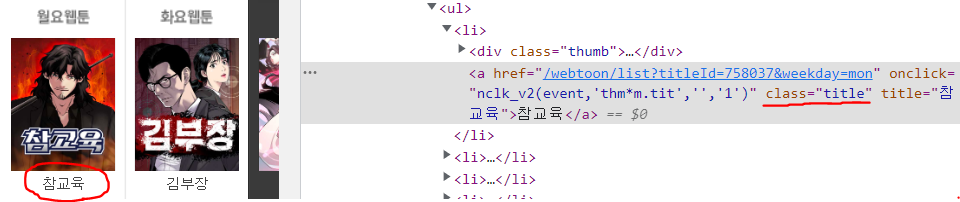
따라서 코드는 아래와 같이 작성하시면 됩니다.
단 이것은 제목 글자를 가져오기 위함이 아니라 제목을 클릭해서 해당 웹툰으로 들어가기 위한 코드입니다.
from selenium import webdriver
# 네이버 웹툰 페이지 열기
nw_url = 'https://comic.naver.com/webtoon/weekday'
chromedriver_url = '다운받은 폴더/chromedriver'
driver = webdriver.Chrome(chromedriver_url)
driver.get(nw_url)
# 클릭할 수 있는 제목 리스트 가져오기
titles = driver.find_elements(By.CLASS_NAME, "title")웹툰 정보 가져오기
이제 본격적으로 웹툰 정보를 가져올 차례입니다.
전체적인 흐름은 아래 과정을 반복하는 것입니다.
웹툰을 클릭하고 -> 정보를 가져오고 -> 뒤로 가기
잠깐 코드로 들어가기 전에 beatifulSoup로 정보를 가져오는 것에 대한 예시를 들기 위해 요일 정보를 가져와 보겠습니다.
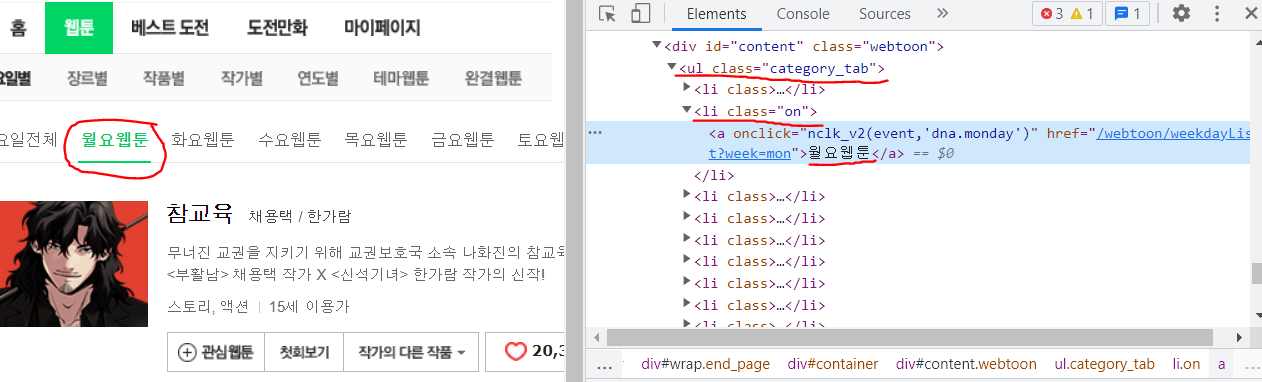
요일 탭에서 정보를 가져오려 하는데, 사진에서 보이듯이 요일 탭은 ul 태그 안에서 class가 category_tab인 구문입니다.
따라서 요일 탭의 정보를 가져오려 한다면 아래 코드를 작성하면 됩니다.
day = soup.find('ul', {'class': 'category_tab'})그리고 나서 현재 초록색을 되어있는 월요일 탭의 구문을 찾아야 하는데 친절하게도 해당 구문은 li 태그 안에서 class가 on으로 되어있습니다.
따라서 "월"이란 글자를 가져오기 위해서는 아래 코드를 작성하면 됩니다.
day = soup.find('ul', {'class': 'category_tab'})
day = day.find('li', {'class': 'on'}).text[0:1]나머지 정보를 가져오는 법과 자세한 설명은 코드 상에서 주석으로 써놓겠습니다.
from selenium import webdriver
from bs4 import BeautifulSoup as bs
from time import sleep
from selenium.webdriver.common.by import By
# 네이버 웹툰 페이지 열기
nw_url = 'https://comic.naver.com/webtoon/weekday'
chromedriver_url = '다운받은 폴더/chromedriver'
driver = webdriver.Chrome(chromedriver_url)
driver.get(nw_url)
# 클릭할 수 있는 제목 리스트 가져오기
titles = driver.find_elements(By.CLASS_NAME, "title")
# 정보들을 담을 리스트 정의하기
id_list = []
title_list = []
author_list = []
day_list = []
genre_list = []
story_list = []
platform_list = []
webtoon_url_list = []
thumbnail_url_list = []
webtoon_id = 0
# 웹툰 개수만큼 반복하기
for i in range(len(titles)):
print("\rprocess: " + str(i + 1) + " / " + str(len(titles)), end="")
# 웹페이지가 로딩되기도 전에 코드가 실행되는 것을 방지하기 위한 기다림
sleep(0.5)
# 0번째 웹툰, 즉 월요일 첫번재 웹툰부터 클릭해서 해당 페이지로 이동하기
titles = driver.find_elements(By.CLASS_NAME, "title")
titles[i].click()
# 이동한 페이지의 html 코드 가져오기
html = driver.page_source
soup = bs(html, 'html.parser')
# 제목 정보 가져오기
title = soup.find('span', {'class': 'title'}).text
# 요일 정보 가져오기
day = soup.find('ul', {'class': 'category_tab'})
day = day.find('li', {'class': 'on'}).text[0:1]
# 만약 연재 요일이 2개 이상이라서 이미 저장했던 웹툰이라면 요일만 추가하고 넘어가기
if title in title_list:
day_list[title_list.index(title)] += ', ' + day
driver.back()
continue
# 나머지 정보 수집하기
thumbnail_url = soup.find('div', {'class': 'thumb'}).find('a').find('img')['src']
author = soup.find('span', {'class': 'wrt_nm'}).text[8:]
author = author.replace(' / ', ', ')
genre = soup.find('span', {'class': 'genre'}).text.split(", ")[1]
story = soup.find('div', {'class': 'detail'}).find('p').text
# 정보들을 리스트에 담기
id_list.append(webtoon_id)
title_list.append(title)
author_list.append(author)
day_list.append(day)
genre_list.append(genre)
story_list.append(story)
platform_list.append("네이버")
webtoon_url_list.append(driver.current_url)
thumbnail_url_list.append(thumbnail_url)
# 뒤로 가기
driver.back()
webtoon_id += 1
sleep(0.5)
CSV 파일로 정보 저장하기
좀 시간이 지나면 모든 웹툰이 크롤링 되고 각 리스트에는 웹툰 정보들이 담기게 됩니다!
이제 이 정보들을 먼저 Pandas의 Dataframe 형태로 저장하고 CSV 형태로 변환해서 저장하면 됩니다.
import pandas as pd
total_data = pd.DataFrame()
total_data['id'] = id_list
total_data['title'] = title_list
total_data['author'] = author_list
total_data['day'] = day_list
total_data['genre'] = genre_list
total_data['story'] = story_list
total_data['platform'] = platform_list
total_data['webtoon_url'] = webtoon_url_list
total_data['thumbnail_url'] = thumbnail_url_list
# 따로 인덱스를 생성하지 않고 id를 인덱스로 정하기
total_data.set_index('id', inplace=True)
# CSV 파일로 저장하기
total_data.to_csv("네이버 웹툰 정보.csv", encoding='utf-8-sig')그러면 아래 사진 처럼 현재 프로젝트와 같은 폴더 내에 CSV 파일이 생성 됩니다!
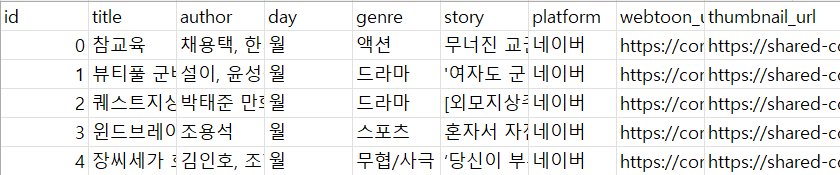
전체 코드
아래는 전체 코드입니다. (나중을 위해 함수화 시키고 맨 마지막에 코드를 살짝 추가했습니다.)
from selenium import webdriver
from bs4 import BeautifulSoup as bs
from time import sleep
from selenium.webdriver.common.by import By
import pandas as pd
import os
def get_naver_webtoon_info():
# 네이버 웹툰 페이지 열기
nw_url = 'https://comic.naver.com/webtoon/weekday'
chromedriver_url = 'D:/Project/Pycharm/WebtoonRecommend/chromedriver'
driver = webdriver.Chrome(chromedriver_url)
driver.get(nw_url)
# 클릭할 수 있는 제목 리스트 가져오기
titles = driver.find_elements(By.CLASS_NAME, "title")
# 정보들을 담을 리스트 정의하기
infos = {}
id_list = []
title_list = []
author_list = []
day_list = []
genre_list = []
story_list = []
platform_list = []
webtoon_url_list = []
thumbnail_url_list = []
webtoon_id = 0
# 웹툰 개수만큼 반복하기
for i in range(len(titles)):
print("\rprocess: " + str(i + 1) + " / " + str(len(titles)), end="")
# 웹페이지가 로딩되기도 전에 코드가 실행되는 것을 방지하기 위한 기다림
sleep(0.5)
# 0번째 웹툰, 즉 월요일 첫번재 웹툰부터 클릭해서 해당 페이지로 이동하기
titles = driver.find_elements(By.CLASS_NAME, "title")
titles[i].click()
# 이동한 페이지의 html 코드 가져오기
html = driver.page_source
soup = bs(html, 'html.parser')
# 제목 정보 가져오기
title = soup.find('span', {'class': 'title'}).text
# 요일 정보 가져오기
day = soup.find('ul', {'class': 'category_tab'})
day = day.find('li', {'class': 'on'}).text[0:1]
# 만약 연재 요일이 2개 이상이라서 이미 저장했던 웹툰이라면 요일만 추가하고 넘어가기
if title in title_list:
day_list[title_list.index(title)] += ', ' + day
driver.back()
continue
# 나머지 정보 수집하기
thumbnail_url = soup.find('div', {'class': 'thumb'}).find('a').find('img')['src']
author = soup.find('span', {'class': 'wrt_nm'}).text[8:]
author = author.replace(' / ', ', ')
genre = soup.find('span', {'class': 'genre'}).text.split(", ")[1]
story = soup.find('div', {'class': 'detail'}).find('p').text
# 정보들을 리스트에 담기
id_list.append(webtoon_id)
title_list.append(title)
author_list.append(author)
day_list.append(day)
genre_list.append(genre)
story_list.append(story)
platform_list.append("네이버")
webtoon_url_list.append(driver.current_url)
thumbnail_url_list.append(thumbnail_url)
# 뒤로 가기
driver.back()
webtoon_id += 1
sleep(0.5)
# DataFrame 형태로 저장하기
total_data = pd.DataFrame()
total_data['id'] = id_list
total_data['title'] = title_list
total_data['author'] = author_list
total_data['day'] = day_list
total_data['genre'] = genre_list
total_data['story'] = story_list
total_data['platform'] = platform_list
total_data['webtoon_url'] = webtoon_url_list
total_data['thumbnail_url'] = thumbnail_url_list
# 따로 인덱스를 생성하지 않고 id를 인덱스로 정하기
total_data.set_index('id', inplace=True)
return total_data
naver_webtoon_filename = "네이버 웹툰 정보.csv"
if os.path.isfile(naver_webtoon_filename):
# 파일이 있다면 웹 크롤링 하지 않고 읽어오기
total_data = pd.read_csv(naver_webtoon_filename, encoding='utf-8-sig')
else:
# 파일이 없다면 웹 크롤링 하기
total_data = get_naver_webtoon_info()
# CSV 파일로 저장하기
total_data.to_csv("네이버 웹툰 정보.csv", encoding='utf-8-sig')마무리
이렇게 네이버 웹 크롤링은 마무리 됐습니다.
다음은 이렇게 가져온 정보들 중 스토리에 대해 토큰화 및 벡터화라는 것을 해보겠습니다.
