소개글
이전 포스트에서 웹 크롤링을 통해 웹툰 정보를 가져오는 것까지 해봤는데요, 오늘은 이 정보들 중 스토리를 토큰화하고 벡터화하는 것까지 해보겠습니다.
개념 설명
구현에 앞서 개념들에 대해 간략하게만 설명하겠습니다.
만약 개념들에 대해 더 알아보고 싶다면, 해당 키워드들로 좀 더 검색해보시는 것을 추천합니다!
토큰화
토큰화는 문장을 단어별로 나누는 것을 말하는데, 한글에서는 형태소를 분석하고 나누는 것이라고 할 수 있습니다.
예를 들면 아래 사진과 같습니다. (출처)

토큰화는 여러 용도로 쓰일 수 있겠지만, 여기서는 조사 같이 크게 의미 없는 토큰들을 제외시키기 위해서 사용합니다.
벡터화(TF-IDF)
"벡터화" 라고 표현은 했지만 사실 애매한 단어긴 합니다.
여기서 저는 벡터화를 TF-IDF 란 것을 의미하며, 문장에서 중요한 단어들을 추출하고 이를 수치화 시키는 과정으로 정의하겠습니다.
TF는 1개의 문서 안에서 특정 단어의 등장 빈도를 의미합니다.
DF는 특정 단어가 나타나는 문서 수를 의미하고, IDF는 DF를 역수변환 해준 값입니다.
이렇게 나온 TF와 IDF를 곱한 값이 바로 TF-IDF 입니다.
복잡할 수 있지만 어쨋든 핵심은 TF-IDF는 문서 내에서 비중이 높은 단어를 추출해준다는 것입니다.
구현
문장 토큰화하기
한글을 토큰화할 수 있도록 해주는 라이브러리는 다양하게 제공되고 있습니다.
Okt, Komoran, Kkma, .. 등 다양하게 있는데, 어떤 것을 사용하든 정답은 없고 자신의 데이터에 맞는 라이브러리를 쓰면 됩니다!
각 라이브러리를 잘 비교해주신 분이 있어서 링크 남겨두겠습니다.
저는 이 중에서 Kkma를 사용해보도록 하겠습니다.
Kkma 웹사이트를 보면 아래 그림처럼 각 품사에 대한 태그가 나옵니다.

개인적으로 의미있는 품사는 체언(N..), 용언(V..), 관형사(MM), 부사(MAG, MAJ), 어근(XR) 이라고 생각했습니다.
그러니 토큰화를 하고 이 5개의 품사들만 골라내도록 해봅시다.
참고로 만약
"jpype._jvmfinder.JVMNotFoundException: No JVM shared library file (jvm.dll) found. Try setting up the JAVA_HOME environment variable properly."
이런 에러가 뜬다면, jdk를 설치를 안했거나 재설치할 필요가 있을 수도 있습니다.
저같은 경우는 이 사이트를 참고했고, 현재 쓰고 있는 IDE인 Pycharm을 껐다 키니 해결됐습니다.
from konlpy.tag import Kkma
def tokenizer(text):
# 내가 원하는 품사 (첫 알파벳)
my_tag = ("N", "V", "M", "XR")
# 형태소 분석기 정의
kkma = Kkma()
# 형태소 분석하기
words_with_tag = kkma.pos(text)
# 조건에 맞는 단어만 남겨놓기
words = [word for word, tag in words_with_tag if (len(word) > 1) and (tag.startswith(my_tag))]
print("원래 문장: " + text)
print("토큰화: " + str(words))
return words
# 테스트 출력용
temp = tokenizer(total_data['story'][3])
이 코드를 실행시켜보니 위 사진처럼 나옵니다.
엄청 완벽하진 않더라도 나름 토큰화가 잘 진행된 것 같군요!
TF-IDF 벡터화하기
이제 벡터화를 할 차례입니다.
Kkma와 마찬가지로 TF-IDF도 라이브러리를 쓰면 간단한 코드로 표현 가능합니다.
from konlpy.tag import Kkma
from sklearn.feature_extraction.text import TfidfVectorizer
def tokenizer(text):
# 내가 원하는 품사 (첫 알파벳)
my_tag = ("N", "V", "M", "XR")
# 형태소 분석기 정의
kkma = Kkma()
# 형태소 분석하기
words_with_tag = kkma.pos(text)
# 조건에 맞는 단어만 남겨놓기
words = [word for word, tag in words_with_tag if (len(word) > 1) and (tag.startswith(my_tag))]
return words
# TF-IDF 벡터라이저 정의
vectorizer = TfidfVectorizer(tokenizer=tokenizer, min_df=1)
# 벡터화하기
vectorized_data = vectorizer.fit_transform(total_data['story'])
print(vectorized_data)
print()
print(vectorized_data.toarray())
print()
print(vectorized_data.shape)TfidfVectorizer에 들어갈 수 있는 인자는 상당히 많지만, 저는 토큰화한 데이터를 쓸 것이기 때문에 tokenizer 인자와, 단어가 포함된 최소 문서 수인 min_df만 설정했습니다.
다른 인자들을 사용하고 싶다면 여기를 참고하시면 될 것 같습니다.
코드의 맨 밑을 보면 3가지 변수를 print 했는데요, 일단 이걸 순서대로 보여드리겠습니다.
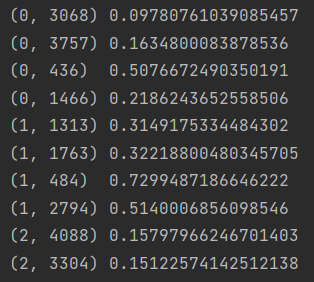
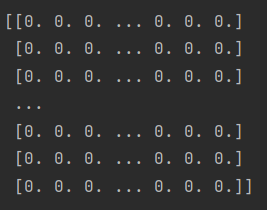
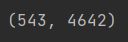
이 데이터의 행은 각각의 웹툰 스토리를 의미하고, 열은 단어들을 의미합니다.
다시 말하자면 세번째 사진처럼 543개의 스토리가 있고 4642개의 단어들이 있는거죠.
그래서 첫번째 사진처럼 Tf-IDF 값들이 모두 계산돼서 저장됐으나, 너무 데이터 양이 많다보니 두번째 사진에서는 안나오고 ... 으로 생략됐네요.

이런 느낌으로 정리된거죠! (출처)
전체 코드
저번 시간에 한것과 합친 전체 코드입니다.
함수들은 다 위로 빼놨습니다.
from selenium import webdriver
from bs4 import BeautifulSoup as bs
from time import sleep
from selenium.webdriver.common.by import By
import pandas as pd
import os
from konlpy.tag import Kkma
from sklearn.feature_extraction.text import TfidfVectorizer
def get_naver_webtoon_info():
# 네이버 웹툰 페이지 열기
nw_url = 'https://comic.naver.com/webtoon/weekday'
chromedriver_url = 'D:/Project/Pycharm/WebtoonRecommend/chromedriver'
driver = webdriver.Chrome(chromedriver_url)
driver.get(nw_url)
# 클릭할 수 있는 제목 리스트 가져오기
titles = driver.find_elements(By.CLASS_NAME, "title")
# 정보들을 담을 리스트 정의하기
infos = {}
id_list = []
title_list = []
author_list = []
day_list = []
genre_list = []
story_list = []
platform_list = []
webtoon_url_list = []
thumbnail_url_list = []
webtoon_id = 0
# 웹툰 개수만큼 반복하기
for i in range(len(titles)):
print("\rprocess: " + str(i + 1) + " / " + str(len(titles)), end="")
# 웹페이지가 로딩되기도 전에 코드가 실행되는 것을 방지하기 위한 기다림
sleep(0.5)
# 0번째 웹툰, 즉 월요일 첫번재 웹툰부터 클릭해서 해당 페이지로 이동하기
titles = driver.find_elements(By.CLASS_NAME, "title")
titles[i].click()
# 이동한 페이지의 html 코드 가져오기
html = driver.page_source
soup = bs(html, 'html.parser')
# 제목 정보 가져오기
title = soup.find('span', {'class': 'title'}).text
# 요일 정보 가져오기
day = soup.find('ul', {'class': 'category_tab'})
day = day.find('li', {'class': 'on'}).text[0:1]
# 만약 연재 요일이 2개 이상이라서 이미 저장했던 웹툰이라면 요일만 추가하고 넘어가기
if title in title_list:
day_list[title_list.index(title)] += ', ' + day
driver.back()
continue
# 나머지 정보 수집하기
thumbnail_url = soup.find('div', {'class': 'thumb'}).find('a').find('img')['src']
author = soup.find('span', {'class': 'wrt_nm'}).text[8:]
author = author.replace(' / ', ', ')
genre = soup.find('span', {'class': 'genre'}).text.split(", ")[1]
story = soup.find('div', {'class': 'detail'}).find('p').text
# 정보들을 리스트에 담기
id_list.append(webtoon_id)
title_list.append(title)
author_list.append(author)
day_list.append(day)
genre_list.append(genre)
story_list.append(story)
platform_list.append("네이버")
webtoon_url_list.append(driver.current_url)
thumbnail_url_list.append(thumbnail_url)
# 뒤로 가기
driver.back()
webtoon_id += 1
sleep(0.5)
# DataFrame 형태로 저장하기
total_data = pd.DataFrame()
total_data['id'] = id_list
total_data['title'] = title_list
total_data['author'] = author_list
total_data['day'] = day_list
total_data['genre'] = genre_list
total_data['story'] = story_list
total_data['platform'] = platform_list
total_data['webtoon_url'] = webtoon_url_list
total_data['thumbnail_url'] = thumbnail_url_list
# 따로 인덱스를 생성하지 않고 id를 인덱스로 정하기
total_data.set_index('id', inplace=True)
return total_data
def tokenizer(text):
# 내가 원하는 품사 (첫 알파벳)
my_tag = ("N", "V", "M", "XR")
# 형태소 분석기 정의
kkma = Kkma()
# 형태소 분석하기
words_with_tag = kkma.pos(text)
# 조건에 맞는 단어만 남겨놓기
words = [word for word, tag in words_with_tag if (len(word) > 1) and (tag.startswith(my_tag))]
return words
naver_webtoon_filename = "네이버 웹툰 정보.csv"
if os.path.isfile(naver_webtoon_filename):
# 파일이 있다면 웹 크롤링 하지 않고 읽어오기
total_data = pd.read_csv(naver_webtoon_filename, encoding='utf-8-sig')
else:
# 파일이 없다면 웹 크롤링 하기
total_data = get_naver_webtoon_info()
# CSV 파일로 저장하기
total_data.to_csv("네이버 웹툰 정보.csv", encoding='utf-8-sig')
# TF-IDF 벡터라이저 정의
vectorizer = TfidfVectorizer(tokenizer=tokenizer, min_df=1)
# 벡터화하기
vectorized_data = vectorizer.fit_transform(total_data['story'])마무리
이렇게 스토리를 토큰화하고 벡터화하는 것까지 끝냈습니다.
다음은 비지도 학습을 통해 비슷한 스토리 데이터끼리 묶어보겠습니다.
