소개글
이전 포스트에서 웹 크롤링으로 가져온 웹툰의 스토리를 토큰화하고 벡터화하는 것까지 해봤는데요, 오늘은 이렇게 벡터화된 데이터들을 비슷한 그룹으로 묶어보는 작업을 해보겠습니다.
개념 설명
구현에 앞서 개념들에 대해 간략하게만 설명하겠습니다.
만약 개념들에 대해 더 알아보고 싶다면, 해당 키워드들로 좀 더 검색해보시는 것을 추천합니다!
특이값 분해 (SVD)
우선 이 SVD를 쓰는 이유부터 말하자면 차원을 축소하기 위해서입니다.
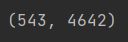
위 사진은 이전 포스트에서 구해낸 데이터의 행과 열인데요, 다르게 말하자면 4643 차원의 데이터가 543개 있는 것이라고 할 수 있습니다.
4642차원의 데이터끼리 비교하려면 계산량도 많고 시간도 오래 걸랄 수 있기 때문에, 차원을 축소하려는 것이죠!
다만 차원을 축소하되, 기존 데이터의 의미를 최대한 보존해야합니다.
의미를 보존한다는게 어떤 뜻인지 예를 들어서 설명해보겠습니다.
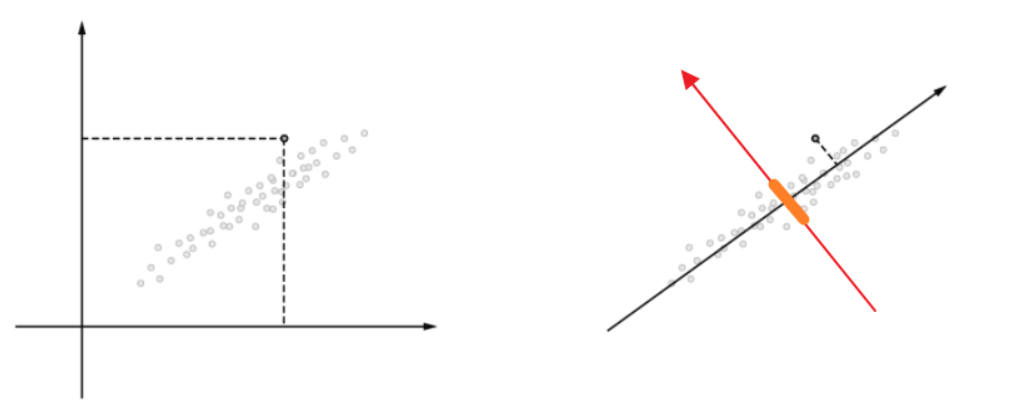
위 그림의 출처는 이곳이며, SVD에 대해 훨씬 자세하게 설명해놓으셨으니 참고하시면 좋을 것 같습니다!
왼쪽의 그림처럼 2차원 데이터가 있을 때 이것을 1차원으로 차원 축소를 하려 합니다.
차원 축소를 하기 위해서는 특정 축을 정해서 데이터들을 사영 시키면 됩니다.
오른쪽 그림에서 주황색 선을 축으로 정하는 경우와 검은색 선을 축으로 정하는 경우를 생각해봅시다.
주황색 선에 사영시키면 데이터들의 분산이 작아지게 되고 의미를 잃는 데이터가 많아집니다.
반면 검은색 선에 사영시키면 데이터들의 분산이 커지게 되고 완벽하게는 아니더라도 의미를 꽤 보존할 수 있죠.
이처럼 의미를 최대한 보존하려면 분산을 커지게 하는 축을 정해야하고, SVD가 이런 축을 정하는 작업에 도움을 줍니다.
SVD 계산에 대한 설명은 꽤 복잡하다고 생각되어 따로 말하지는 않겠습니다.
K-Means 클러스터링
K-Means 클러스터링은 머신러닝의 비지도 학습 중 한가지 방법입니다.
간단하게 말하자면 비슷한 데이터들끼리 그룹을 지어주는 작업을 해줍니다.
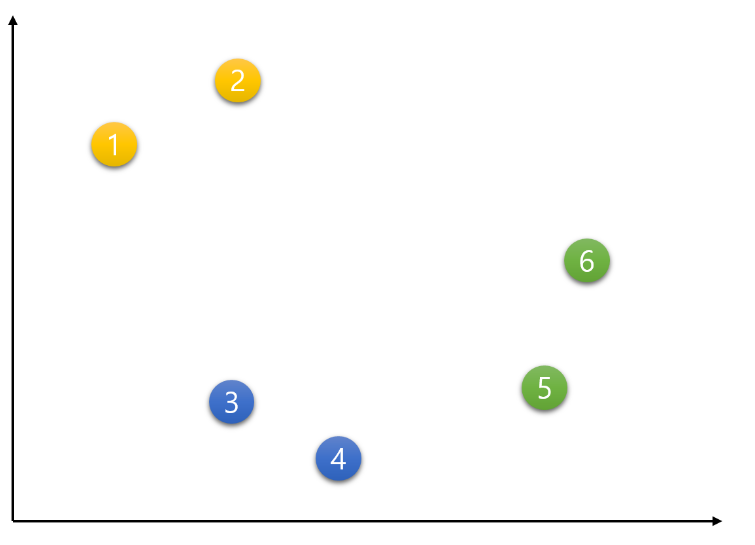
위 그림의 출처는 이곳이며, 마찬가지로 K-Means에 대해 훨씬 자세히 설명해놓으셨으니 참고하시면 좋을 듯 합니다!
K-Means를 쓰기 위해서는 먼저 K값, 즉 몇개의 그룹으로 나눌 것인지 정해야합니다.
위 그림같은 경우는 K를 3으로 설정했네요.
이렇게 K값이 정해지면 중심점이 K(3)개가 위치하게 되는데, 일종의 알고리즘을 통해 비슷한 데이터가 모여있는 곳으로 중심점이 이동하게 됩니다.
그러면 각각의 중심점을 기준으로 가까이 있는 데이터들이 비슷한 데이터라고 판단할 수 있는거죠!
추가적으로 K값으로 제일 적당한 숫자라는 것은 없습니다.
데이터마다 성격도, 양도 다르기 때문에 최적의 K값은 데이터마다 달라지죠.
최적의 K값을 찾기 위한 방법에는 여러가지가 있는데, 사람이 직접 K를 바꿔가면서 살펴봐도 되고, Elbow Method, Silhouette Score 같은 알고리즘도 존재합니다.
구현
차원 축소하기
앞에서 SVD를 이용한 차원 축소에 대해 장황하게 설명했지만, 사실 라이브러리에 다 계산해주는 함수가 있어서 코드는 매우 간단합니다!
저희는 4642차원의 데이터를 2차원의 데이터로 바꾸도록 하겠습니다.
from sklearn.decomposition import TruncatedSVD
# 2차원으로 차원 축소하는 SVD 함수 정의
svd = TruncatedSVD(n_components=2)
# 차원 축소하기
reduced_data = svd.fit_transform(vectorized_data)
print(reduced_data)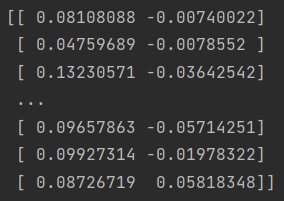
데이터를 출력해보면 2차원으로 잘 변했네요!
K-Means 클러스터링으로 비슷한 데이터 묶기
클러스터링 역시 라이브러리가 있기 때문에 편하게 코드를 짤 수 있습니다!
KMeans 에는 k값을 설정할 수 있는 'n_clusters' 외에도 다양한 파라미터들을 넣어서 설정할 수 있습니다.
저는 k값만 32로 정하고 코드를 돌려보겠습니다. (아까도 말했듯이 K값에 정답은 없습니다)
from sklearn.cluster import KMeans
# K-Means 알고리즘으로 비슷한 데이터끼리 묶기
kmeans = KMeans(n_clusters=32)
cluster_labels = kmeans.fit_predict(reduced_data)
print(cluster_labels)
결과로 반환되는 것은 위 사진과 같이 각각의 데이터가 속한 그룹의 라벨입니다.
0번째 데이터는 그룹 30, 1번째 데이터는 그룹 14, ... 이런식으로 되는 거죠.
결과 시각화하기
저렇게민 봐서는 잘 분류됐는지 확인하기가 어렵습니다.
그래서 이것을 그래프에 예쁘게 나타내보려 합니다.
그래프로 나타내기 위해 pyplot을 쓸텐데, pyplot 역시 여러 값들을 설정할 수 있으니 더 알아보고 쓰시는 것을 추천합니다.
import matplotlib.pyplot as plt
import numpy as np
# 결과를 시각화하기 위해 특정 색깔 배열 가져오기
colors = plt.cm.get_cmap('Spectral')
# 색깔 배열에서 그룹의 개수만큼 색깔 골라서 가져오기
selected_colors = colors(np.linspace(0, 1, len(set(cluster_labels))))
# 그래프에 데이터 표시하기
plt.figure(figsize=(8, 8))
for k, color in zip(range(len(selected_colors)), selected_colors):
my_members = (cluster_labels == k)
plt.plot(
reduced_data[my_members, 0],
reduced_data[my_members, 1],
'o',
markerfacecolor=color,
markersize=5,
markeredgecolor='black'
)
plt.show()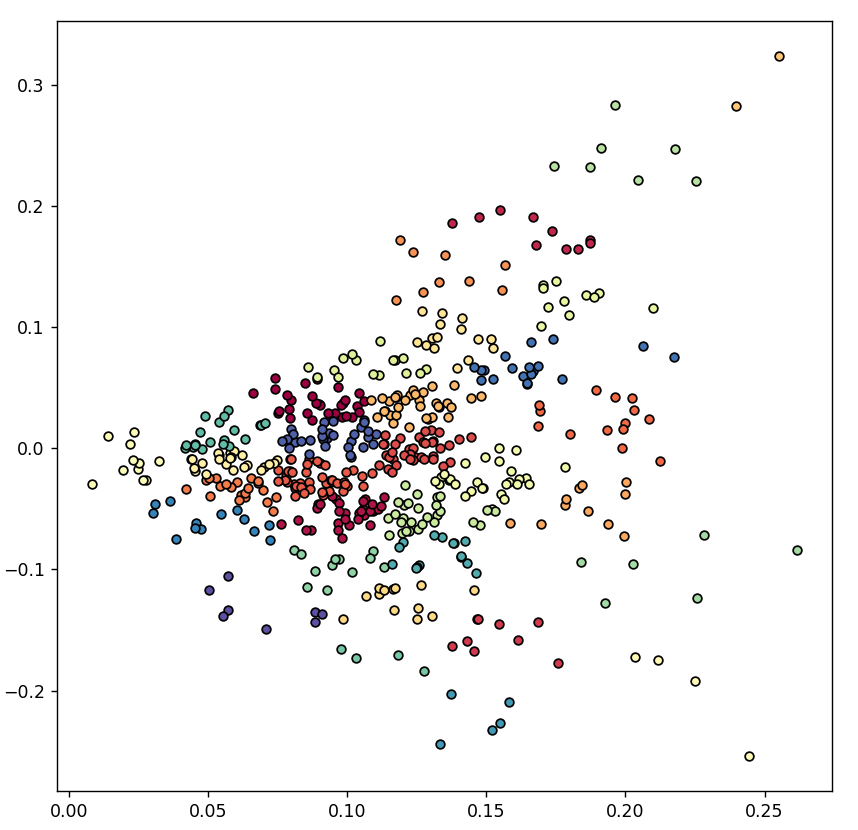
음.. 열심히 했지만 사실 잘 분류된 것 같지는 않아요.
같은 색깔의 점들만 인접한 경우가 제일 이상적인데, 지금 같은 경우는 다른 색깔의 점들도 많이들 인접해있네요.
'스토리'라는 데이터가 너무 애매했을 수도 있고, 여기까지 오는 과정에서 제가 놓친 부분이 있었을 수도 있습니다.
혹시 좀 더 괜찮은 방법이 있다면, 알려주시면 감사하겠습니다.
마지막으로 각각 그룹에 속해있는 웹툰 제목을 보고싶다면 아래 코드를 실행하면 됩니다.
for i in range(len(set(cluster_labels))):
print("[그룹" + str(i) + "]")
print(total_data['title'][cluster_labels == i])
print('--------------------------------')
전체 코드
이번에도 코드를 조금 함수화 시켰습니다.
from selenium import webdriver
from bs4 import BeautifulSoup as bs
from time import sleep
from selenium.webdriver.common.by import By
import pandas as pd
import os
from konlpy.tag import Kkma
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
def get_naver_webtoon_info():
# 네이버 웹툰 페이지 열기
nw_url = 'https://comic.naver.com/webtoon/weekday'
chromedriver_url = 'D:/Project/Pycharm/WebtoonRecommend/chromedriver'
driver = webdriver.Chrome(chromedriver_url)
driver.get(nw_url)
# 클릭할 수 있는 제목 리스트 가져오기
titles = driver.find_elements(By.CLASS_NAME, "title")
# 정보들을 담을 리스트 정의하기
infos = {}
id_list = []
title_list = []
author_list = []
day_list = []
genre_list = []
story_list = []
platform_list = []
webtoon_url_list = []
thumbnail_url_list = []
webtoon_id = 0
# 웹툰 개수만큼 반복하기
for i in range(len(titles)):
print("\rprocess: " + str(i + 1) + " / " + str(len(titles)), end="")
# 웹페이지가 로딩되기도 전에 코드가 실행되는 것을 방지하기 위한 기다림
sleep(0.5)
# 0번째 웹툰, 즉 월요일 첫번재 웹툰부터 클릭해서 해당 페이지로 이동하기
titles = driver.find_elements(By.CLASS_NAME, "title")
titles[i].click()
# 이동한 페이지의 html 코드 가져오기
html = driver.page_source
soup = bs(html, 'html.parser')
# 제목 정보 가져오기
title = soup.find('span', {'class': 'title'}).text
# 요일 정보 가져오기
day = soup.find('ul', {'class': 'category_tab'})
day = day.find('li', {'class': 'on'}).text[0:1]
# 만약 연재 요일이 2개 이상이라서 이미 저장했던 웹툰이라면 요일만 추가하고 넘어가기
if title in title_list:
day_list[title_list.index(title)] += ', ' + day
driver.back()
continue
# 나머지 정보 수집하기
thumbnail_url = soup.find('div', {'class': 'thumb'}).find('a').find('img')['src']
author = soup.find('span', {'class': 'wrt_nm'}).text[8:]
author = author.replace(' / ', ', ')
genre = soup.find('span', {'class': 'genre'}).text.split(", ")[1]
story = soup.find('div', {'class': 'detail'}).find('p').text
# 정보들을 리스트에 담기
id_list.append(webtoon_id)
title_list.append(title)
author_list.append(author)
day_list.append(day)
genre_list.append(genre)
story_list.append(story)
platform_list.append("네이버")
webtoon_url_list.append(driver.current_url)
thumbnail_url_list.append(thumbnail_url)
# 뒤로 가기
driver.back()
webtoon_id += 1
sleep(0.5)
# DataFrame 형태로 저장하기
total_data = pd.DataFrame()
total_data['id'] = id_list
total_data['title'] = title_list
total_data['author'] = author_list
total_data['day'] = day_list
total_data['genre'] = genre_list
total_data['story'] = story_list
total_data['platform'] = platform_list
total_data['webtoon_url'] = webtoon_url_list
total_data['thumbnail_url'] = thumbnail_url_list
# 따로 인덱스를 생성하지 않고 id를 인덱스로 정하기
total_data.set_index('id', inplace=True)
return total_data
def tokenizer(text):
# 내가 원하는 품사 (첫 알파벳)
my_tag = ("N", "V", "M", "XR")
# 형태소 분석기 정의
kkma = Kkma()
# 형태소 분석하기
words_with_tag = kkma.pos(text)
# 조건에 맞는 단어만 남겨놓기
words = [word for word, tag in words_with_tag if (len(word) > 1) and (tag.startswith(my_tag))]
return words
def show_result_in_graph(data, labels):
# 결과를 시각화하기 위해 특정 색깔 배열 가져오기
colors = plt.cm.get_cmap('Spectral')
# 색깔 배열에서 그룹의 개수만큼 색깔 골라서 가져오기
selected_colors = colors(np.linspace(0, 1, len(set(cluster_labels))))
# 그래프에 데이터 표시하기
plt.figure(figsize=(8, 8))
for k, color in zip(range(len(selected_colors)), selected_colors):
my_members = (labels == k)
plt.plot(
data[my_members, 0],
data[my_members, 1],
'o',
markerfacecolor=color,
markersize=5,
markeredgecolor='black'
)
plt.show()
def show_titles_in_group(data, labels):
for i in range(len(set(labels))):
print("[그룹" + str(i) + "]")
print(data['title'][labels == i])
print('--------------------------------')
# 웹 크롤링하기
naver_webtoon_filename = "네이버 웹툰 정보.csv"
if os.path.isfile(naver_webtoon_filename):
# 파일이 있다면 웹 크롤링 하지 않고 읽어오기
total_data = pd.read_csv(naver_webtoon_filename, encoding='utf-8-sig')
else:
# 파일이 없다면 웹 크롤링 하기
total_data = get_naver_webtoon_info()
# CSV 파일로 저장하기
total_data.to_csv("네이버 웹툰 정보.csv", encoding='utf-8-sig')
# TF-IDF 벡터화하기
vectorizer = TfidfVectorizer(tokenizer=tokenizer, min_df=1)
vectorized_data = vectorizer.fit_transform(total_data['story'])
# 2차원으로 차원 축소하기
svd = TruncatedSVD(n_components=2)
reduced_data = svd.fit_transform(vectorized_data)
# K-Means 알고리즘으로 비슷한 데이터끼리 묶기
kmeans = KMeans(n_clusters=32)
cluster_labels = kmeans.fit_predict(reduced_data)
show_result_in_graph(reduced_data, cluster_labels)
show_titles_in_group(total_data, cluster_labels)
마무리
이렇게 비슷한 스토리끼리 묶는 것까지 끝냈습니다. (비록 성능은 별로지만..)
혹시라도 내용 중에 틀린 부분이 있다면 언제든지 피드백 환영합니다!
