소개글
각종 컨퍼런스에 나온 강연들을 정리해보면서 공부해보고 있습니다.
이번 포스팅은 if(kakao) 2022에서 변민우님께서 강연해주신 내용을 정리했습니다.
제목은 "초거대모델 학습을 위한 이미지-텍스트 데이터셋"이며 카카오 브레인에서 직접 제작한 이미지-텍스트 데이터셋에 대한 내용입니다.
말투는 편한 말투로 작성하니 양해 부탁드립니다.
발표내용
데이터셋을 만들게 된 계기

- 여러가지 Large-scale Image-Text Model들이 만들어져있음
- CLIP(OpenAI), DALLE(OpenAI), ALIGN(Google), Florence(Microsoft) 등이 있음
- 다만 기술에 대한 논문은 공개되어있지만, 학습에 사용된 데이터셋은 공개되지 않은 상태
- 그래서 많은 연구자들이 해당 기술을 재현하기가 어려웠음
-> 카카오 브레인은 학습에 기반이 되는 데이터를 직접 수집하기로 함
AI 모델에 대한 기술이 공개되어있어도 데이터셋이 없어서 구현하기가 어려운 경우가 많습니다.
카카오 브레인은 감사하게도 직접 데이터셋을 구현해주시고 공개까지 해주셨습니다.
데이터 수집 방법
이미지-텍스트 쌍 확보 방법
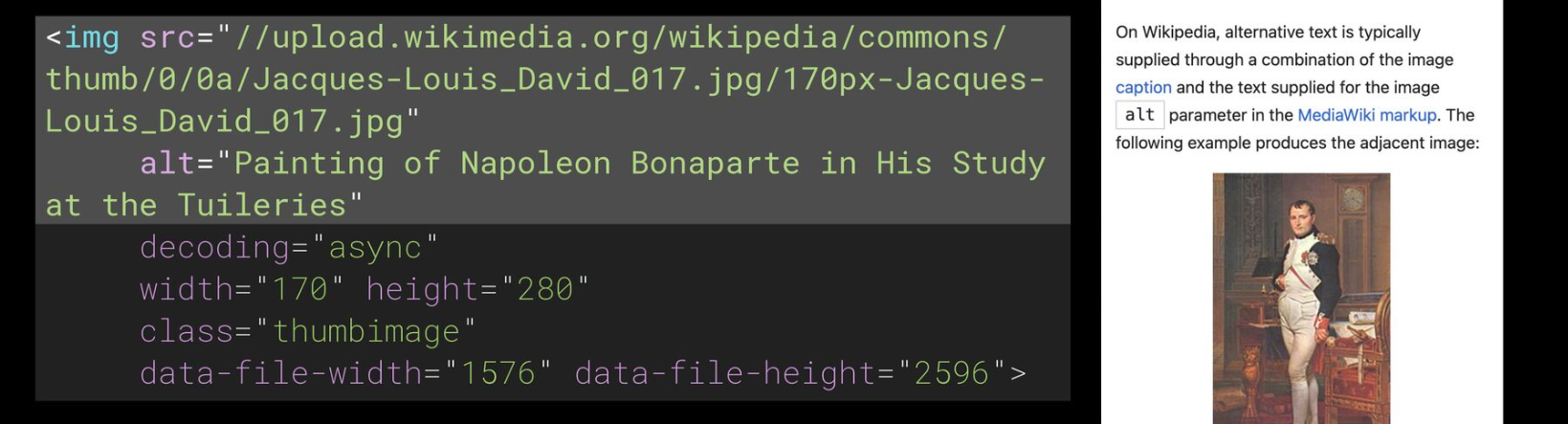
- 웹페이지에 이미지 태그에 포함된 대체 텍스트를 활용
- 대체 텍스트는 이미지에 대한 설명으로, 이미지를 볼 수 없는 상황에서 스크린리더를 통해 정보를 확인할 수 있도록 함
웹페이지 확보 방법

- Common Crawl 데이터 활용
- Common Craw은 지난 10년간 2300억개의 데이터를 수집함

- 이 중에서도 2020년 10월 ~ 2021년 8월 데이터를 활용하기로 함
데이터 필터링

부적절한 데이터는 제외할 수 있도록 필터링이 필요함
Image Filtering
- JPEG, PNG, BMP, WEBP 등을 위주로 수집
- 크기가 5KB 이상, 픽셀 수가 200개 이상, 가로 세로 비율이 3.0 미만인 이미지만
- 그 외의 이미지는 저품질 이미지로 판단하여 수집하지 않음
Text Filtering
- 언어 분석을 통해 영어로 된 텍스트만
- 길이가 5 이상, 1000 이하
- 단어 개수가 3개 이상, 256개 이하
- 형태소 분석을 통해 명사를 1개 이상 포함하는 텍스트만
Deduplication
- Perceptual Image Hash를 기반으로, 동일한 이미지 해시값과 텍스트 쌍은 한개만 남기고 제거
- 공정한 데이터셋 평가를 위해 외부 공개 이미지 데이터셋과 해시값이 동일한 이미지는 제거
- ImageNet-1K/21K
- Flickr-30K
- MS-COCO
- CC-3M / CC-12M
- 10번 이상 등장하는 텍스트는 기계적으로 생성되는 것으로 판단하여 제거
- "Image of", "photo of", "jpef" 등
NSFW Filtering
- 안전한 데이터셋을 만들어야함
- 포르노 이미지를 분류하는 모델을 사용하여 해당 이미지가 포함된 데이터 제거
- 욕설, 비속어 및 포르노 단어를 포함하는 데이터 제거
- 그럼에도 불구하고 완전한 제거는 힘들어서 적합하지 않은 데이터가 포함되어 있을 가능성이 있음
메타데이터 추가
데이터셋을 다양하게 활용할 수 있도록, 이미지와 텍스트에 대한 여러가지 메타데이터 추가
이미지와 텍스트의 유사도
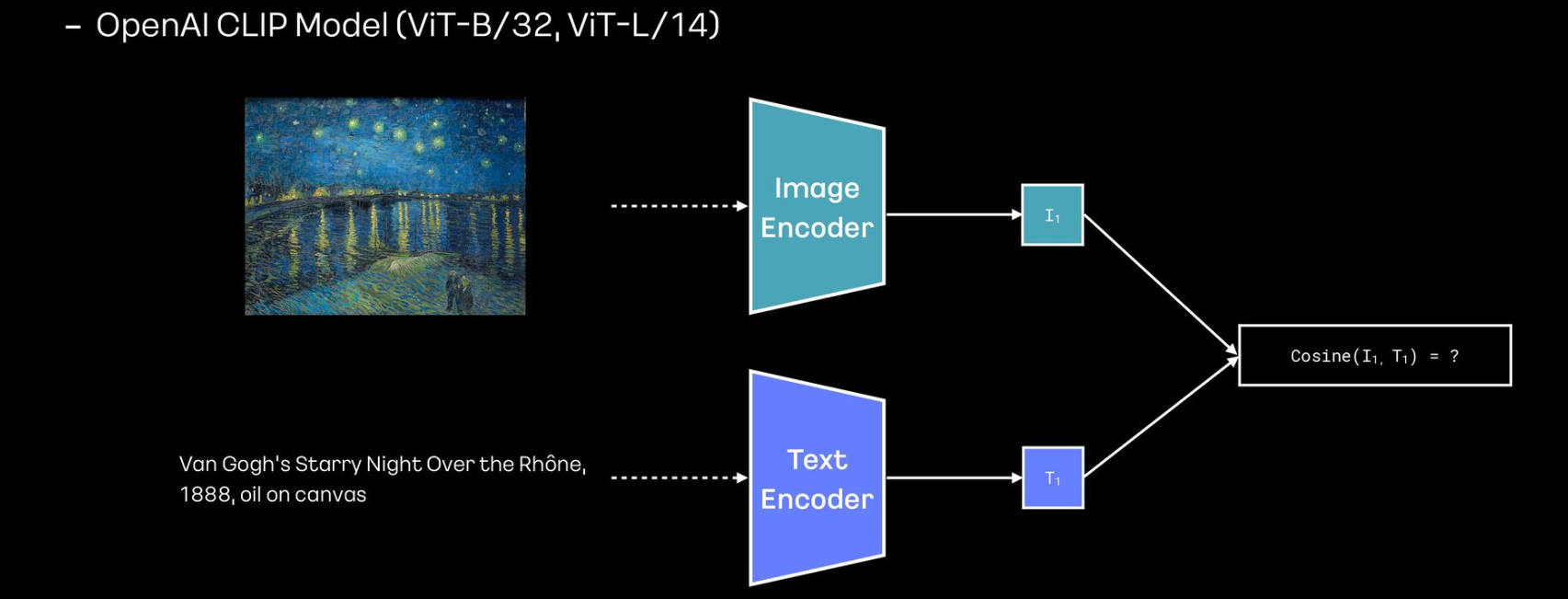
- OpenAI에서 공개한 CLIP 모델을 사용하면 이미지와 텍스트의 연관성을 계산할 수 있음
- 해당 점수를 이용하면 연관성이 높은 고품질 데이터를 활용할 수 있음
워터마크

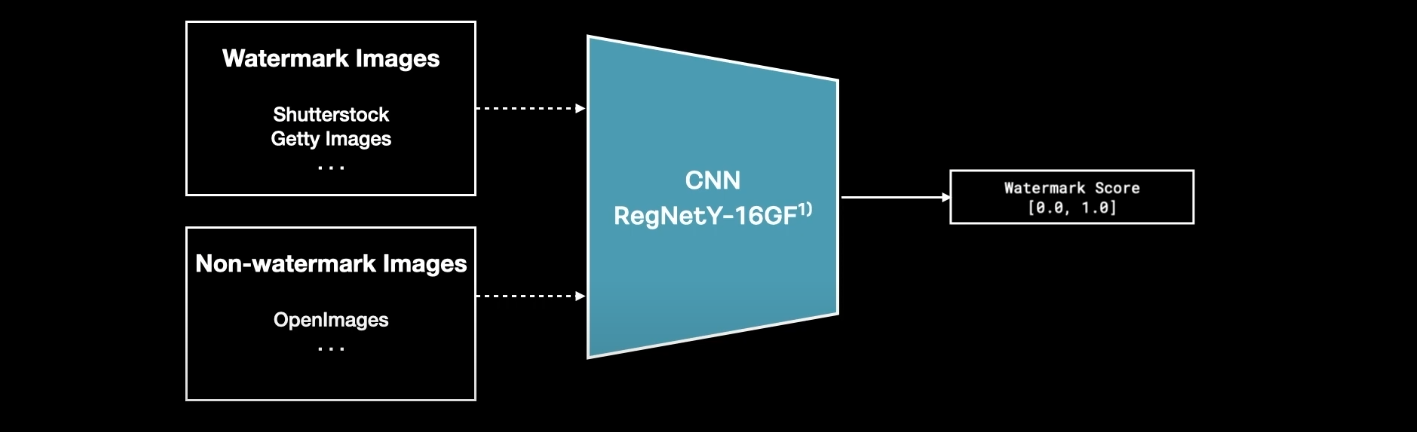
- 수집한 이미지 중에는 워터마크가 포함된 이미지도 많음
- 학습시킨 워터마크 분류 모델을 통해 워터마크가 포함됐는지에 대한 점수도 추가함
Aesthetic 점수
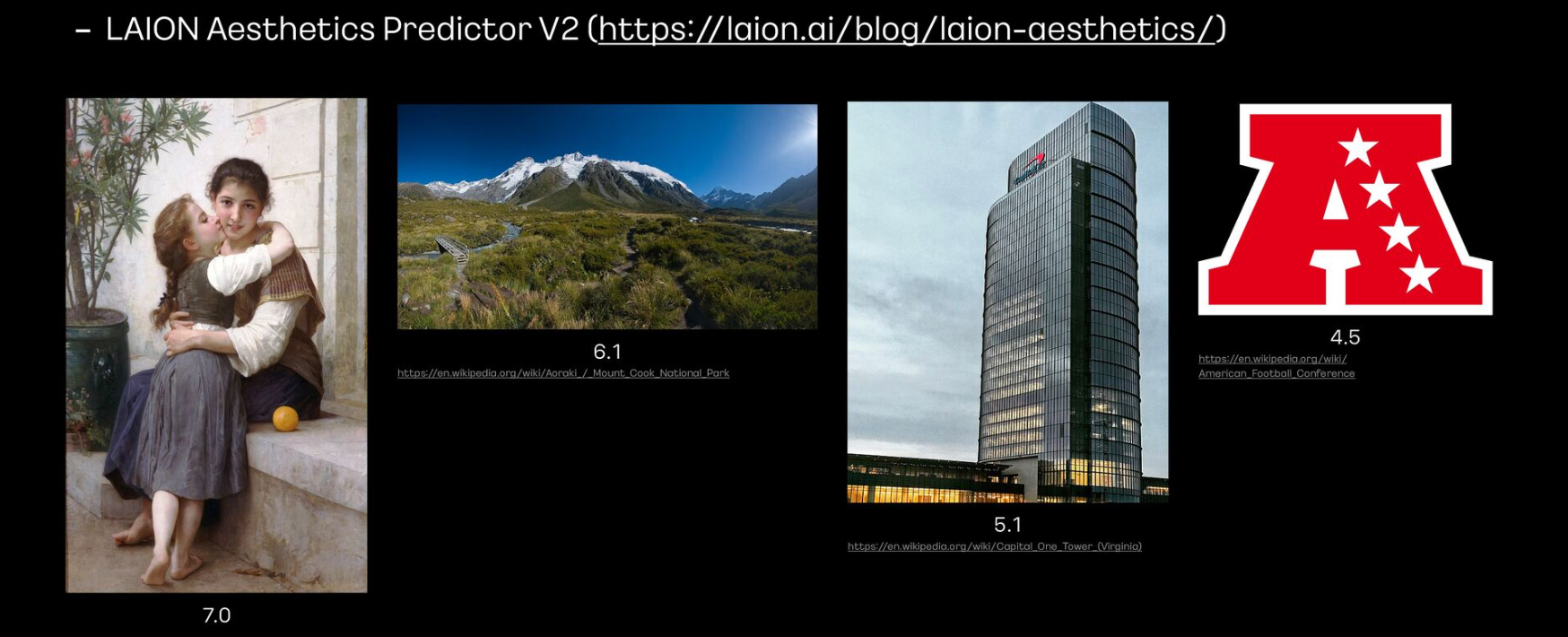
- Aesthetic 점수는 아름다운 이미지일 수록 높음
- LAION에서 공개한 모델을 사용해서 이미지마다 Aesthetic 점수를 매김
얼굴 개수

- SCRFD를 활용하여 얼굴 개수를 탐지
- 사람이 있거나 없는 데이터를 사용하고 싶을 떄 활용 가능
토큰

- 글자 및 토큰 개수 정보도 추가
- 긴 텍스트만 학습하고 싶을 때 활용 가능
데이터셋 하나를 만드는데에도 여러가지 AI 기술들이 쓰인다는 것을 알 수 있습니다.
결과물


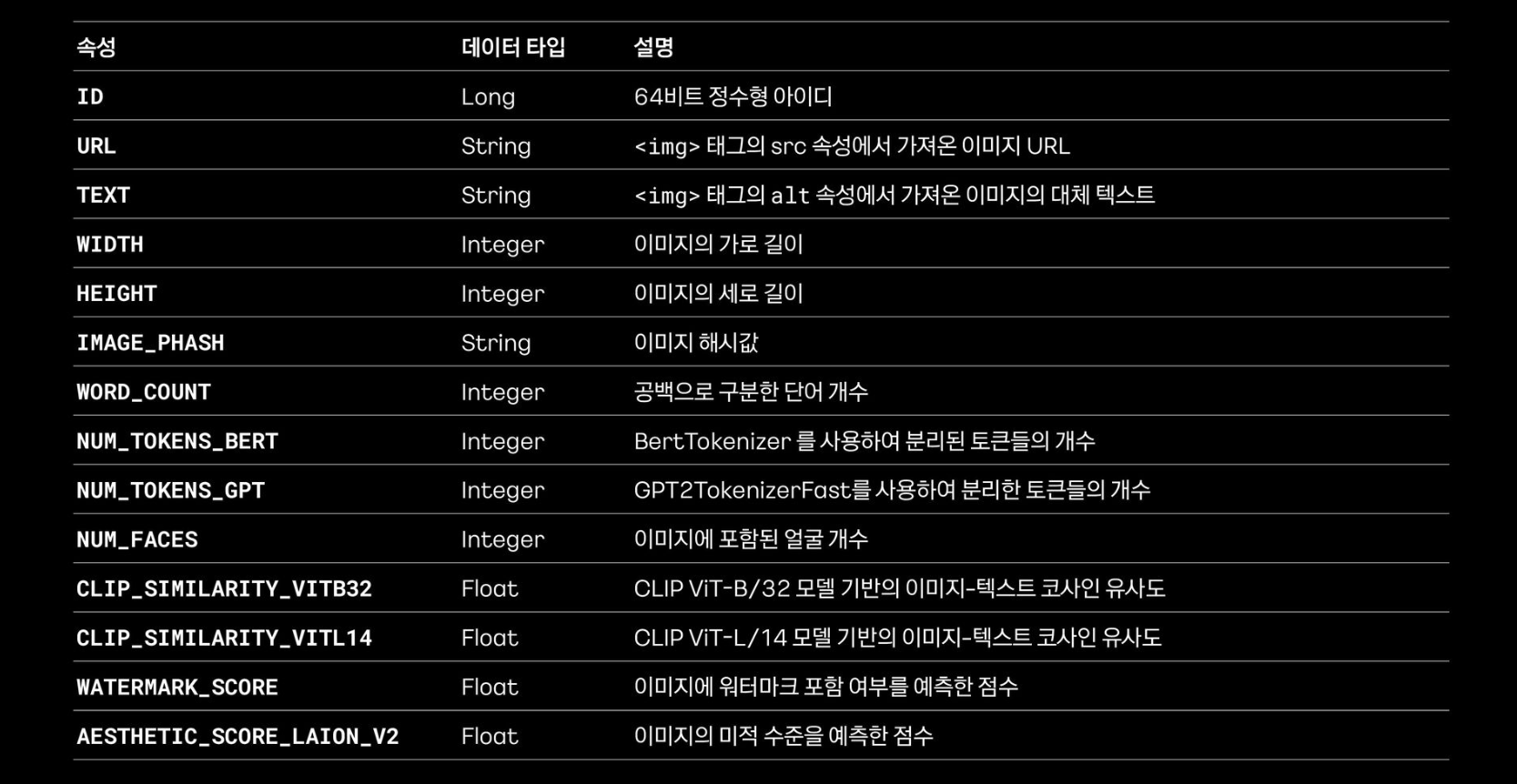
- 다양한 메타 데이터를 포함
- Parquet 형식으로 저장되어있기 때문에 Parquet, pandas, Spark 등 다양한 데이터 분석 프레임워크에서 사용 가능
테스트
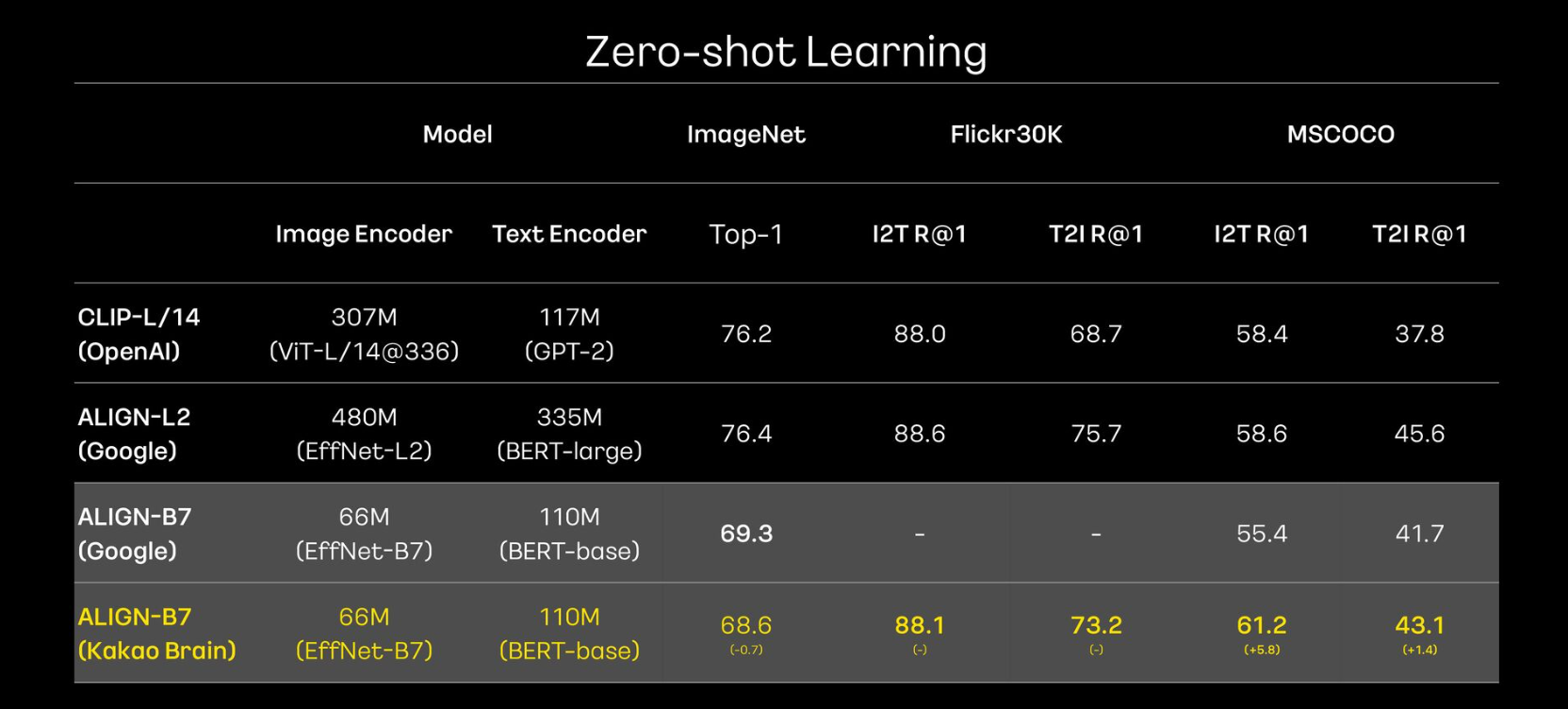
- ALIGN 모델을 자체 데이터로 학습
- 데이터 테스트 결과 중 일부분에서는 Google 및 OpenAI보다 높게 나온 부분도 있음
남은 테스크
- 안전한 학습 데이터
- 고품질 학습 데이터

개발을 하며 경험한 것들을 이것저것 작성해보고 있습니다!